CREATE TABLE AS SELECT
Se aplica a:![]() Sistema de plataforma de Análisis de Azure Synapse Analytics
Sistema de plataforma de Análisis de Azure Synapse Analytics ![]() (PDW)
(PDW)
CREATE TABLE AS SELECT (CTAS) es una de las características más importantes de T-SQL disponibles. Se trata de una operación completamente en paralelo que crea una nueva tabla basada en la salida de una instrucción SELECT. CTAS es la forma más sencilla y rápida de crear una copia de una tabla.
Por ejemplo, use CTAS para lo siguiente:
- Volver a crear una tabla con una columna de distribución de hash diferente.
- Volver a crear una tabla como replicada.
- Crear un índice de almacén de columnas en solo algunas columnas de la tabla.
- Consultar o importar datos externos.
Nota:
Dado que CTAS se agrega a las funcionalidades para crear tablas, en este tema se procura no repetir el tema CREATE TABLE. En su lugar, se describen las diferencias entre las instrucciones CTAS y CREATE TABLE. Para obtener todos los detalles sobre CREATE TABLE, vea la instrucción CREATE TABLE (Azure Synapse Analytics).
- El grupo de SQL sin servidor no admite esta sintaxis en Azure Synapse Analytics.
- CTAS se admite en el almacenamiento de Microsoft Fabric.
![]() Convenciones de sintaxis de Transact-SQL
Convenciones de sintaxis de Transact-SQL
Sintaxis
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Argumentos
Para más información, vea la sección Argumentos de CREATE TABLE.
Opciones de columna
column_name [ ,...n ]
Los nombres de columna no permiten las opciones de columna mencionadas en CREATE TABLE. En su lugar, puede proporcionar una lista opcional de uno o más nombres de columna para la nueva tabla. Las columnas de la nueva tabla usan los nombres que especifique. Al especificar nombres de columna, el número de columnas de la lista de columnas debe coincidir con el número de columnas de los resultados de selección. Si no especifica nombres de columna, la nueva tabla de destino usa los nombres de columna de los resultados de la instrucción de selección.
No se pueden especificar otras opciones de columna, como tipos de datos, intercalación o la nulabilidad. Cada uno de estos atributos se deriva de los resultados de la instrucción SELECT. Aun así, puede usar la instrucción SELECT para cambiar los atributos. Para obtener un ejemplo, vea Usar CTAS para cambiar los atributos de columna.
Opciones de distribución de tabla
Para obtener más información y entender cómo elegir la mejor columna de distribución, vea la sección Opciones de distribución de tabla en CREATE TABLE. Para obtener recomendaciones sobre qué distribución elegir para una tabla en función del uso real o las consultas de ejemplo, consulte Asesor de distribución de Azure Synapse SQL.
DISTRIBUTION = HASH ( distribution_column_name ) | ROUND_ROBIN | REPLICATE La instrucción CTAS requiere una opción de distribución y no tiene valores predeterminados. Es diferente de CREATE TABLE, que tiene valores predeterminados.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] ) Distribuye las filas basadas en los valores hash de hasta ocho columnas, lo que permite una distribución más uniforme de los datos de la tabla base, reduce la asimetría de datos en el tiempo y mejora el rendimiento de las consultas.
Nota:
- Para habilitar la característica, cambie el nivel de compatibilidad de la base de datos a 50 mediante este comando. Para obtener más información sobre cómo establecer el nivel de compatibilidad de la base de datos, consulte ALTER DATABASE SCOPED CONFIGURATION. Por ejemplo:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - Para deshabilitar la función de distribución de varias columnas (MCD), ejecute este comando para cambiar el nivel de compatibilidad de la base de datos a AUTO. Por ejemplo:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;Las tablas MCD existentes se conservarán pero se volverán ilegibles. Las consultas sobre tablas de MCD devolverán este error:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- Para recuperar el acceso a las tablas MCD, habilite la característica de nuevo.
- Para cargar datos en una tabla MCD, use la instrucción CTAS y el origen de datos deben ser tablas de Synapse SQL.
- No se admite CTAS en las tablas de destino de MCD HEAP. En su lugar, use INSERT SELECT como solución alternativa para cargar datos en tablas de MCD HEAP.
- Actualmente se admite el uso de SSMS (versiones superiores a la 19) para generar un script para crear tablas de MCD.
Para obtener más información y entender cómo elegir la mejor columna de distribución, vea la sección Opciones de distribución de tabla en CREATE TABLE.
Para obtener recomendaciones sobre la mejor distribución que se puede usar en función de las cargas de trabajo, consulte Asesor de distribución de Azure Synapse SQL.
Opciones de partición de tabla
La instrucción CTAS crea una tabla sin particiones de forma predeterminada, incluso si la tabla de origen tiene particiones. Para crear una tabla con particiones con la instrucción CTAS, debe especificar la opción de partición.
Para más información, vea la sección Opciones de partición de tabla en CREATE TABLE.
Instrucción SELECT
La instrucción SELECT es la diferencia fundamental entre CTAS y CREATE TABLE.
WITH common_table_expression
Especifica un conjunto de resultados temporal con nombre, conocido como expresión de tabla común (CTE). Para más información, consulte WITH common_table_expression (Transact-SQL).
SELECT select_criteria
Rellena la nueva tabla con los resultados de una instrucción SELECT. select_criteria es el cuerpo de la instrucción SELECT que determina qué datos se copian en la nueva tabla. Para más información sobre las instrucciones SELECT, consulte SELECT (Transact-SQL).
Sugerencia de consulta
Los usuarios pueden establecer MAXDOP en un valor entero para controlar el grado máximo de paralelismo. Cuando MAXDOP se establece en 1, la consulta se ejecuta en un único subproceso.
Permisos
CTAS requiere el permiso SELECT en todos los objetos a los que hace referencia en select_criteria.
Para conocer los permisos para crear una tabla, vea Permisos en CREATE TABLE.
Observaciones
Para más información, vea Notas generales en CREATE TABLE.
Limitaciones y restricciones
Para obtener más información sobre las limitaciones y restricciones, consulte Limitaciones y restricciones en CREATE TABLE.
Se puede crear un índice de almacén de columnas agrupado y ordenado en columnas de cualquier tipo de datos que se admita en Azure Synapse Analytics, excepto en columnas de cadena.
SET ROWCOUNT (Transact-SQL) no tiene ningún efecto en CTAS. Para lograr un comportamiento similar, use TOP (Transact-SQL).
CTAS no admite la
OPENJSONfunción como parte de laSELECTinstrucción . Como alternativa, useINSERT INTO ... SELECT. Por ejemplo:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
Comportamiento de bloqueo
Para más información, vea Comportamiento de bloqueo en CREATE TABLE.
Rendimiento
Para una tabla distribuida de hash, puede usar CTAS para seleccionar una columna de distribución diferente a fin de obtener un mejor rendimiento de las combinaciones y las agregaciones. Si su objetivo no es seleccionar una columna de distribución diferente, tendrá el mejor rendimiento de CTAS si especifica la misma columna de distribución, ya que de este modo evitará que se redistribuyan las filas.
Si usa CTAS para crear una tabla y el rendimiento no es un factor importante, puede especificar ROUND_ROBIN para evitar tener que elegir una columna de distribución.
Para evitar el movimiento de datos en las consultas posteriores, puede especificar REPLICATE a costa de que aumente el almacenamiento para cargar una copia completa de la tabla en cada nodo de ejecución.
Ejemplos para copiar una tabla
A. Uso de CTAS para copiar una tabla
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
Quizás uno de los usos más comunes de CTAS es crear una copia de una tabla para poder cambiar el DDL. Si, por ejemplo, creó la tabla inicialmente como ROUND_ROBIN y ahora quiere cambiarla a una tabla distribuida en una columna, cambiaría la columna de distribución con CTAS. CTAS también se puede usar para cambiar los tipos de particiones, indexación o columna.
Supongamos que creó esta tabla especificando HEAP y usando el tipo de distribución predeterminado de ROUND_ROBIN.
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Ahora quiere crear una copia de esta tabla con un índice de almacén de columnas agrupado para poder aprovechar el rendimiento de las tablas del almacén de columnas agrupado. También quiere distribuir esta tabla en ProductKey, ya que prevé combinaciones en esta columna y quiere evitar el movimiento de datos durante las mismas en ProductKey. Por último, también quiere agregar la creación de particiones en OrderDateKey, para eliminar rápidamente datos antiguos mediante la anulación de particiones anteriores. A continuación, se muestra la instrucción CTAS que copiaría la tabla antigua en una tabla nueva:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Por último, puede cambiar el nombre de las tablas para intercambiar la tabla nueva y, después, anular la tabla antigua.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Ejemplos de opciones de columna
B. Usar CTAS para cambiar los atributos de columna
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
En este ejemplo se usa CTAS para cambiar los tipos de datos, la nulabilidad y la intercalación de varias columnas en la tabla DimCustomer2.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
Como paso final, puede usar RENAME (Transact-SQL) para cambiar los nombres de tabla. Esto hace que DimCustomer2 sea la nueva tabla.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Ejemplos de distribución de la tabla
C. Usar CTAS para cambiar el método de distribución de una tabla
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
En este sencillo ejemplo se muestra cómo cambiar el método de distribución de una tabla. Para mostrar la mecánica de cómo se hace, cambia una tabla distribuida de hash a round robin y, después, cambia la tabla round robin de nuevo a distribuida de hash. La tabla final coincide con la tabla original.
En la mayoría de los casos no es necesario convertir una tabla distribuida de hash en una tabla round robin. A menudo, deberá cambiar una tabla round robin a una tabla distribuida de hash. Por ejemplo, es posible que cargue inicialmente una tabla nueva como round robin y, después, la mueva a una tabla distribuida de hash para obtener un mejor rendimiento de combinación.
En este ejemplo se usa la base de datos de ejemplo AdventureWorksDW. Para cargar la versión de Azure Synapse Analytics, consulte Inicio rápido: Creación y consulta de un grupo de SQL dedicado (anteriormente SQL DW) en Azure Synapse Analytics mediante Azure Portal.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Después, cámbiela de nuevo a una tabla distribuida de hash.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. Usar CTAS para convertir una tabla en una tabla replicada
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
En este ejemplo se convierten tablas round robin o distribuidas de hash en una tabla replicada. En este ejemplo en concreto, el método anterior de cambiar el tipo de distribución va un paso más allá. Dado que DimSalesTerritory es una dimensión y es probable que sea una tabla más pequeña, puede volver a crear la tabla como replicada para evitar el movimiento de datos al combinarla con otras tablas.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. Usar CTAS para crear una tabla con menos columnas
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
En el ejemplo siguiente se crea una tabla distribuida round robin denominada myTable (c, ln). La nueva tabla solo tiene dos columnas. Usa los alias de columna en la instrucción SELECT para los nombres de las columnas.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Ejemplos de sugerencias de consulta
F. Usar una sugerencia de consulta con CREATE TABLE AS SELECT (CTAS)
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
Esta consulta muestra la sintaxis básica para usar una sugerencia de combinación de consulta con la instrucción CTAS. Una vez enviada la consulta, Azure Synapse Analytics aplica la estrategia de combinación hash al generar el plan de consulta para cada distribución individual. Para obtener más información sobre la sugerencia de consulta de combinación hash, vea OPTION Clause (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Ejemplos de tablas externas
G. Usar CTAS para importar datos de Azure Blob Storage
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
Para importar datos de una tabla externa, use CREATE TABLE AS SELECT para hacer una selección en la tabla externa. La sintaxis para seleccionar datos de una tabla externa en Azure Synapse Analytics es igual que la sintaxis para seleccionar datos de una tabla normal.
En el ejemplo siguiente se define una tabla externa en los datos de una cuenta de Azure Blob Storage. Después, se usa CREATE TABLE AS SELECT para hacer una selección en la tabla externa. De este modo se importan los datos de los archivos delimitados por texto de Azure Blob Storage y se almacenan en una nueva tabla de Azure Synapse Analytics.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Usar CTAS para importar datos de Hadoop de una tabla externa
Se aplica a: Sistema de la plataforma de análisis (PDW)
Para importar datos de una tabla externa, basta con que use CREATE TABLE AS SELECT para hacer una selección en la tabla externa. La sintaxis para seleccionar datos de una tabla externa en Sistema de la plataforma de análisis (PDW) es igual que la sintaxis para seleccionar datos de una tabla normal.
En el ejemplo siguiente se define una tabla externa en un clúster de Hadoop. Después, se usa CREATE TABLE AS SELECT para hacer una selección en la tabla externa. De este modo se importan los datos de los archivos delimitados de texto de Hadoop y se almacenan los datos en una nueva tabla de Sistema de la plataforma de análisis (PDW).
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Ejemplos del uso de CTAS para reemplazar código de SQL Server
Use CTAS para hallar soluciones temporales para algunas características no admitidas. Además de permitirle ejecutar el código en el almacén de datos, la reescritura del código existente para usar CTAS suele mejorar el rendimiento. Esto se debe a su diseño totalmente paralelizado.
Nota:
Intente dar prioridad a CTAS. Lo más recomendable es resolver los problemas mediante CTAS, incluso si como resultado debe escribir más datos.
I. Usar CTAS en lugar de SELECT..EN
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
El código de SQL Server suele usar SELECT..INTO para rellenar una tabla con los resultados de una instrucción SELECT. Este es un ejemplo de una instrucción SELECT..INTO de SQL Server.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Esta sintaxis no se admite en Azure Synapse Analytics y en el almacenamiento de datos paralelos. En este ejemplo se muestra cómo reescribir la anterior instrucción SELECT..INTO como una instrucción CTAS. Puede elegir cualquiera de las opciones DISTRIBUTION que se describen en la sintaxis CTAS. En este ejemplo se usa el método de distribución ROUND_ROBIN.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Usar CTAS para simplificar las instrucciones de fusión
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
Las instrucciones de fusión se pueden sustituir, al menos en parte, mediante CTAS. Es posible consolidar INSERT y UPDATE en una única instrucción. Los registros eliminados deben cerrarse en una segunda instrucción.
A continuación se muestra un ejemplo de UPSERT:
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. establezca explícitamente el tipo de datos y la nulabilidad de salida
Se aplica a: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
Al migrar código de SQL Server a Azure Synapse Analytics, puede encontrarse con este tipo de patrón de codificación:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Instintivamente pensará que debe migrar este código a una instrucción CTAS, y tendría razón. Sin embargo, existe un problema oculto aquí.
El código siguiente NO produce el mismo resultado:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
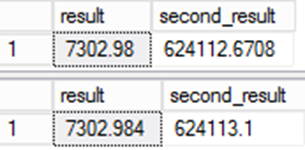
Observe que la columna "result" traslada el tipo de datos y los valores de nulabilidad de la expresión. Esto puede provocar sutiles variaciones en los valores si no tiene cuidado.
Pruebe por ejemplo lo siguiente:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
El valor almacenado para el resultado es diferente. Dado que el valor almacenado en la columna de resultados se usa en otras expresiones, el error es todavía mayor.
Esto es importante para las migraciones de datos. Aunque se puede decir que la segunda consulta es más precisa, hay un problema. Los datos serían diferentes en comparación con el sistema de origen, lo que produce problemas de integridad en la migración. Este es uno de los pocos casos en los que la respuesta "incorrecta" es en realidad la correcta.
El motivo por el que vemos esta discrepancia entre los dos resultados se debe a la conversión de tipos implícita. En el primer ejemplo, la tabla define la definición de columna. Cuando se inserta la fila, se realiza una conversión de tipos implícita. En el segundo ejemplo no hay ninguna conversión de tipos implícita, ya que la expresión define el tipo de datos de la columna. Observe también que la columna del segundo ejemplo se ha definido como una columna que acepta valores NULL mientras que en el primer ejemplo no. Al crear la tabla en el primer ejemplo, se definió explícitamente la nulabilidad de la columna. En el segundo ejemplo, esto le correspondía a la expresión, lo que conllevaba una definición NULL de forma predeterminada.
Para resolver estos problemas, debe establecer explícitamente la conversión de tipos y la nulabilidad en la parte SELECT de la instrucción CTAS. No puede establecer estas propiedades en la parte de creación de la tabla.
En este ejemplo se muestra cómo corregir el código:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Tenga en cuenta lo siguiente en el ejemplo:
- Podían haberse usado CAST o CONVERT.
- Se usa ISNULL para forzar la nulabilidad, no COALESCE.
- ISNULL es la función más externa.
- La segunda parte de ISNULL es una constante, es decir,
0.
Nota:
Para que la nulabilidad se establezca correctamente, es fundamental usar ISNULL, no COALESCE. COALESCE no es una función determinista, por lo que el resultado de la expresión siempre aceptará valores NULL. ISNULL es diferente, ya que es determinista. Por lo tanto, cuando la segunda parte de la función ISNULL es una constante o un literal, el valor resultante será NOT NULL.
Esta sugerencia no solo es útil para garantizar la integridad de los cálculos, sino que también es importante para la modificación de particiones de tabla. Imagine que ha definido como hecho esta tabla:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
Pero el campo de valor es una expresión calculada, no forma parte del origen de datos.
Para crear el conjunto de datos con particiones, tenga en cuenta el ejemplo siguiente:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
La consulta se ejecutaría perfectamente. El problema se produce al intentar realizar la modificación de particiones. Las definiciones de la tabla no coinciden. Para que las definiciones de tabla coincidan, es necesario modificar la instrucción CTAS.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Por lo tanto, puede ver que la coherencia de los tipos y el mantenimiento de las propiedades de nulabilidad en una instrucción CTAS es un procedimiento recomendado de ingeniería. Ayuda a mantener la integridad de los cálculos y también garantiza que la modificación de particiones sea posible.
L. Creación de un índice ordenado de almacén de columnas agrupado con MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Pasos siguientes
- CREATE EXTERNAL DATA SOURCE (Transact-SQL)
- CREATE EXTERNAL FILE FORMAT (Transact-SQL)
- CREATE EXTERNAL TABLE (Transact-SQL)
- CREATE EXTERNAL TABLE AS SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP TABLE (Transact-SQL)
- DROP EXTERNAL TABLE (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- ALTER EXTERNAL TABLE (Transact-SQL)
Se aplica a: ![]() Warehouse en Microsoft Fabric
Warehouse en Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) es una de las características más importantes de T-SQL disponibles. Se trata de una operación completamente en paralelo que crea una nueva tabla basada en la salida de una instrucción SELECT. CTAS es la forma más sencilla y rápida de crear una copia de una tabla.
Por ejemplo, use CTAS en el almacenamiento de Microsoft Fabric para:
- Crear una copia de una tabla con algunas de las columnas de la tabla de origen.
- Crear una tabla que sea el resultado de una consulta que combina otras tablas.
Para más información sobre el uso de CTAS en el almacén de Microsoft Fabric, consulte Ingesta de datos en el almacén mediante Transact-SQL.
Nota:
Dado que CTAS se agrega a las funcionalidades para crear tablas, en este tema se procura no repetir el tema CREATE TABLE. En su lugar, se describen las diferencias entre las instrucciones CTAS y CREATE TABLE. Para obtener todos los detalles sobre CREATE TABLE, consulte la instrucción CREATE TABLE.
![]() Convenciones de sintaxis de Transact-SQL
Convenciones de sintaxis de Transact-SQL
Sintaxis
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Argumentos
Para más información, consulte Los argumentos de CREATE TABLE para Microsoft Fabric.
Opciones de columna
column_name [ ,...n ]
Los nombres de columna no permiten las opciones de columna mencionadas en CREATE TABLE. En su lugar, puede proporcionar una lista opcional de uno o más nombres de columna para la nueva tabla. Las columnas de la nueva tabla usan los nombres que especifique. Al especificar nombres de columna, el número de columnas de la lista de columnas debe coincidir con el número de columnas de los resultados de selección. Si no especifica nombres de columna, la nueva tabla de destino usa los nombres de columna de los resultados de la instrucción de selección.
No se pueden especificar otras opciones de columna, como tipos de datos, intercalación o la nulabilidad. Cada uno de estos atributos se deriva de los resultados de la instrucción SELECT. Aun así, puede usar la instrucción SELECT para cambiar los atributos.
Instrucción SELECT
La instrucción SELECT es la diferencia fundamental entre CTAS y CREATE TABLE.
SELECT select_criteria
Rellena la nueva tabla con los resultados de una instrucción SELECT. select_criteria es el cuerpo de la instrucción SELECT que determina qué datos se copian en la nueva tabla. Para más información sobre las instrucciones SELECT, consulte SELECT (Transact-SQL).
Nota:
En Microsoft Fabric, no se permite el uso de variables en CTAS.
Permisos
CTAS requiere el permiso SELECT en todos los objetos a los que hace referencia en select_criteria.
Para conocer los permisos para crear una tabla, vea Permisos en CREATE TABLE.
Observaciones
Para más información, vea Notas generales en CREATE TABLE.
Limitaciones y restricciones
SET ROWCOUNT (Transact-SQL) no tiene ningún efecto en CTAS. Para lograr un comportamiento similar, use TOP (Transact-SQL).
Para más información, vea Limitaciones y restricciones en CREATE TABLE.
Comportamiento de bloqueo
Para más información, vea Comportamiento de bloqueo en CREATE TABLE.
Ejemplos para copiar una tabla
Para más información sobre el uso de CTAS en el almacén de Microsoft Fabric, consulte Ingesta de datos en el almacén mediante Transact-SQL.
A Usar CTAS para cambiar los atributos de columna
En este ejemplo se usa CTAS para cambiar los tipos de datos y la nulabilidad de varias columnas en la tabla DimCustomer2.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Usar CTAS para crear una tabla con menos columnas
En el ejemplo siguiente se crea una tabla denominada myTable (c, ln). La nueva tabla solo tiene dos columnas. Usa los alias de columna en la instrucción SELECT para los nombres de las columnas.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Usar CTAS en lugar de SELECT..EN
El código de SQL Server suele usar SELECT..INTO para rellenar una tabla con los resultados de una instrucción SELECT. Este es un ejemplo de una instrucción SELECT..INTO de SQL Server.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
En este ejemplo se muestra cómo reescribir la anterior instrucción SELECT..INTO como una instrucción CTAS.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. Usar CTAS para simplificar las instrucciones de fusión
Las instrucciones de fusión se pueden sustituir, al menos en parte, mediante CTAS. Es posible consolidar INSERT y UPDATE en una única instrucción. Los registros eliminados deben cerrarse en una segunda instrucción.
A continuación se muestra un ejemplo de UPSERT:
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;