Configuración de la alta disponibilidad y recuperación ante desastres
Una parte importante de la configuración de soluciones de recuperación ante desastres y alta disponibilidad en SQL Server sigue siendo la misma cuando se ejecuta en una máquina virtual de Azure. La solución de alta disponibilidad está diseñada para garantizar que los datos confirmados nunca se pierden debido a errores, que las operaciones de mantenimiento no afectan a la carga de trabajo y que la base de datos no será un único punto de error en la arquitectura de software.
La mayoría de los niveles de servicio de Azure SQL ofrecen una variedad de opciones de alta disponibilidad, desde redundancia local hasta modelos de redundancia de zona.
A continuación, se explorarán las soluciones específicas para la recuperación ante desastres y la alta disponibilidad de las ofertas de PaaS de Azure.
Copia de seguridad continua
Azure SQL Database garantiza copias de seguridad continuas y periódicas de las bases de datos, que luego se replican en un almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS).
Las copias de seguridad completas semanales, las copias de seguridad diferenciales cada 12 a 24 horas y las copias de seguridad del registro de transacciones cada 5 a 10 minutos forman parte de la estrategia de copia de seguridad automatizada. Para la disponibilidad de copia de seguridad extendida (hasta 10 años), se puede configurar la retención a largo plazo (LTR) para bases de datos únicas y agrupadas.
Retención a largo plazo (LTR)
Azure ofrece una directiva de retención que puede establecer más allá de los límites habituales, lo que resulta útil para escenarios en los que se necesita retención a largo plazo. Puede establecer una directiva de retención durante un máximo de 10 años y esta opción está deshabilitada de forma predeterminada.

En la imagen se muestra cómo configurar directivas de retención a largo plazo en Azure Portal. Después de elegir una base de datos, aparecerá un panel en la parte derecha de la pantalla, donde puede cambiar los valores predeterminados.
Para más información sobre la retención a largo plazo, vea Retención a largo plazo: Azure SQL Database y Azure SQL Managed Instance.
Geo-restore
Las copias de seguridad de SQL Database y SQL Managed Instance son con redundancia geográfica de forma predeterminada. Esto le permite restaurar fácilmente las bases de datos en otra región geográfica, una característica que resulta útil para escenarios de recuperación ante desastres menos estrictos.
El almacenamiento de copia de seguridad se factura de forma independiente al almacenamiento normal de archivos de base de datos. Pero al aprovisionar una instancia de SQL Database, el almacenamiento de copia de seguridad se crea con el tamaño máximo de la capa de datos seleccionada para la base de datos sin costo adicional.
La duración de una operación de restauración geográfica puede verse afectada por varios componentes subyacentes, como el tamaño de la base de datos, el número de registros de transacciones implicados en una operación de restauración y la cantidad de solicitudes de restauración simultáneas que se procesan en la región de destino.
Restauración a un momento dado
Puede restaurar las bases de datos a un momento específico en el tiempo según la retención definida, pero PITR solo se admite si va a restaurar una base de datos en el mismo servidor en el que se ha originado la copia de seguridad. Puede usar Azure Portal, Azure PowerShell, la CLI de Azure o la API REST para restaurar una instancia de SQL Database.
Replicación geográfica activa
Un método para aumentar la disponibilidad de Azure SQL Database consiste en usar la replicación geográfica activa. La replicación geográfica activa crea una réplica secundaria de la base de datos en otra región que se mantiene actualizada de forma asincrónica.
Esta réplica es legible, similar a un grupo de disponibilidad Always On en SQL Server. Bajo la superficie, Azure usa grupos de disponibilidad para mantener esta funcionalidad, por lo que algunas de las terminologías son similares.
La replicación geográfica activa proporciona continuidad empresarial al permitir a los clientes conmutar por error las bases de datos principales en regiones secundarias durante un desastre importante, ya sea mediante programación o de forma manual.
Nota:
Azure SQL Managed Instance no admite la replicación geográfica activa. En su lugar, debe usar grupos de conmutación por error automática, un tema que se explorará más adelante en esta unidad.
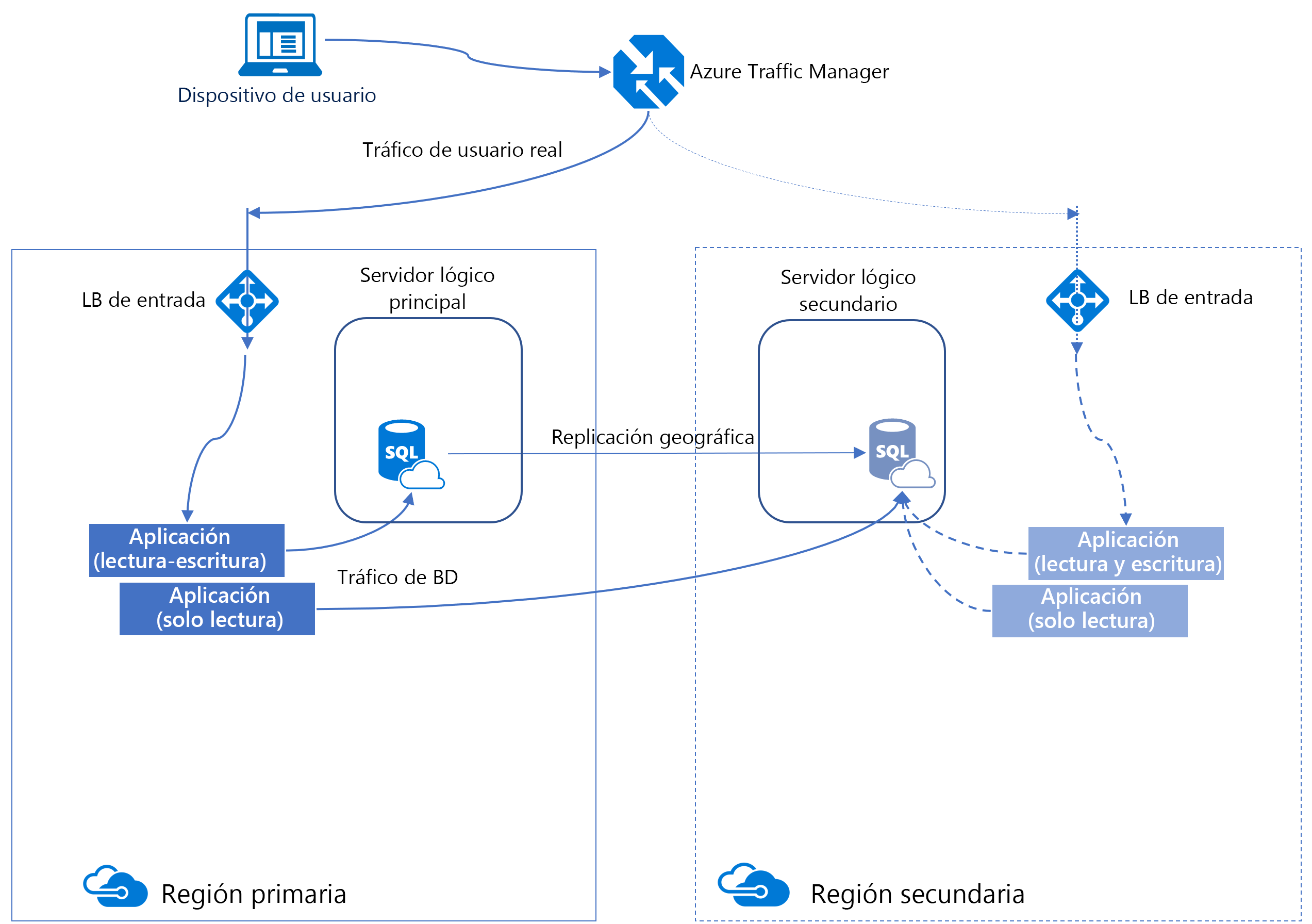
Todas las bases de datos implicadas en una relación de replicación geográfica deben tener el mismo nivel de servicio. Además, para evitar problemas de rendimiento de replicación debido a una carga de trabajo de escritura intensiva, se recomienda configurar la réplica secundaria con el mismo tamaño de proceso que la principal.

Puede configurar manualmente la replicación geográfica para Azure SQL Database al acceder al panel de la base de datos, en la sección Administración de datos y seleccionar Réplicas y, después, + Crear réplica.

Una vez que se establezca la réplica secundaria, tiene la opción de iniciar manualmente una conmutación por error. En este proceso, los roles se invierten: la réplica secundaria asume el rol de la principal, mientras que la principal original se convierte en la secundaria.
Replicación geográfica entre suscripciones
En algunos escenarios es posible que tenga que configurar una réplica secundaria en una suscripción distinta a la de la base de datos principal. Aquí es donde entra en juego la característica de replicación geográfica entre suscripciones.
Nota:
La replicación geográfica entre suscripciones solo está disponible mediante programación.
Para más información sobre los pasos necesarios para configurar una replicación geográfica entre suscripciones, vea Replicación geográfica entre suscripciones.
Grupos de conmutación por error automática
Un agrupo de conmutación por error automática es una característica de alta disponibilidad que admiten tanto Azure SQL Database como Azure SQL Managed Instance. Los grupos de conmutación por error automática le permiten administrar cómo se replican la bases de datos en otra región y cómo se debe producir la conmutación por error. El nombre asignado al grupo de conmutación por error automática debe ser único en el dominio *.database.windows.net.
Un grupo de conmutación por error automática puede incluir varias bases de datos. Tanto la base de datos principal como la secundaria tienen el mismo tamaño.
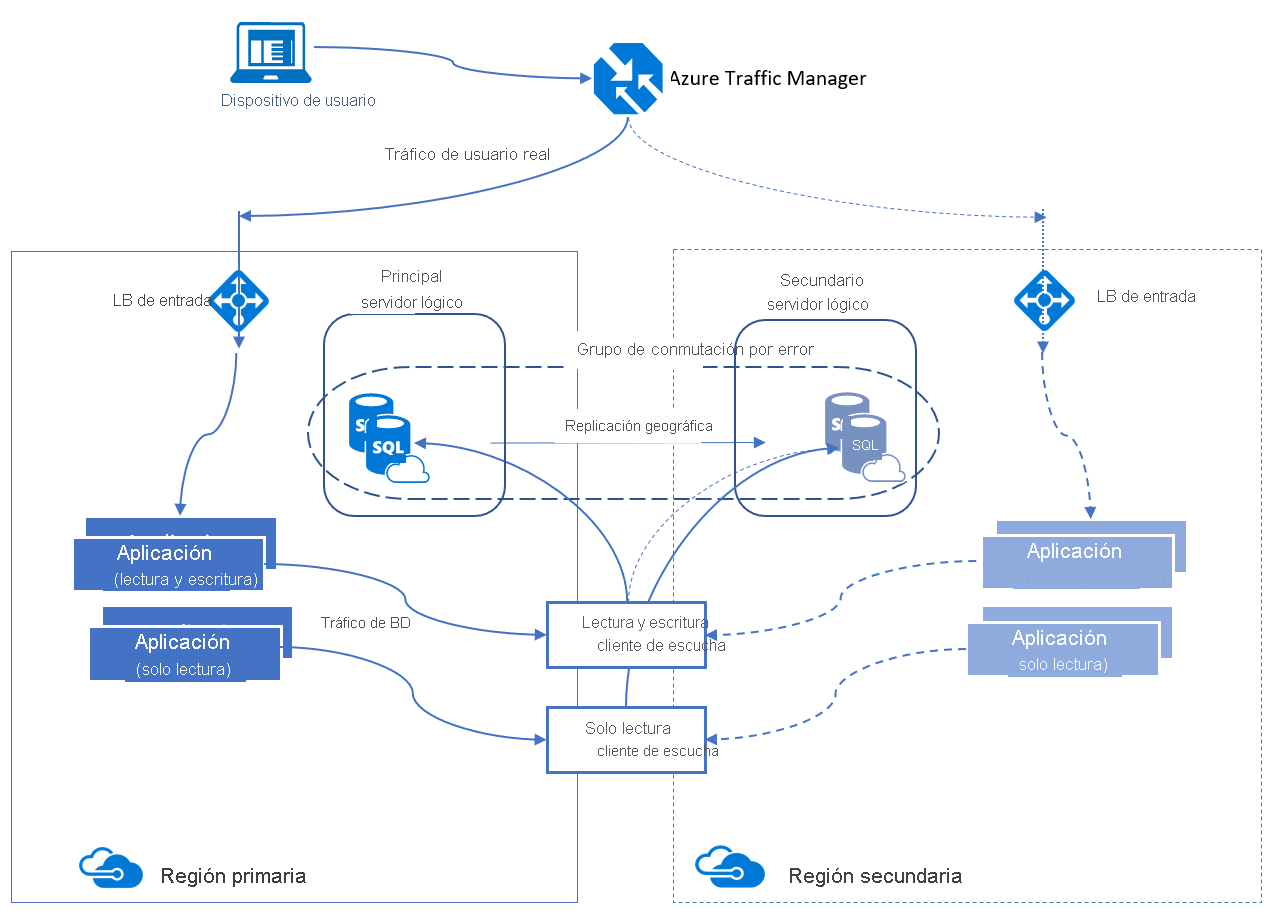
Los grupos de conmutación por error automática proporcionan una funcionalidad de tipo AG denominada "cliente de escucha", que permite realizar actividades de lectura y escritura y de solo lectura. Existen dos tipos diferentes de clientes de escucha: uno para el tráfico de lectura y escritura y otro para el de solo lectura. En el segundo plano de una operación de conmutación por error, el Sistema de nombres de dominio se actualiza para que los clientes puedan señalar el nombre del cliente de escucha abstraído y no tengan que saber nada más. El servidor de base de datos que contiene las copias de lectura y escritura es el servidor principal, y el servidor que recibe las transacciones del principal es de tipo secundario.
Hay dos directivas diferentes para los grupos de conmutación por error automática.
| Tipo de directiva | Descripción |
|---|---|
| Automático | Cuando se detecta un error, el sistema desencadena automáticamente una conmutación por error. Pero si es necesario, puede deshabilitar la conmutación automática por error. |
| Solo lectura | Durante una conmutación por error, el motor deshabilita el cliente de escucha de solo lectura de forma predeterminada para mantener el rendimiento de la nueva base de datos principal cuando la secundaria está inactiva. Pero puede cambiar este comportamiento para permitir ambos tipos de tráfico después de una conmutación por error. |
La conmutación por error es un proceso que se puede iniciar manualmente, incluso cuando está habilitada la conmutación automática por error. Pero el tipo de conmutación por error puede influir en si se produce pérdida de datos. Por ejemplo, una conmutación por error no planeada podría provocar pérdida de datos si se fuerza y la base de datos secundaria no se ha sincronizado completamente con la principal.
GracePeriodWithDataLossHours determina cuánto tiempo espera Azure antes de iniciar una conmutación por error; el valor predeterminado se establece en una hora. Si el objetivo de punto de recuperación (RPO) es estricto y la pérdida de datos no es una opción, puede establecer un valor más alto. Aunque esto significa que Azure espera más tiempo antes de iniciar una conmutación por error, podría reducir potencialmente la pérdida de datos, ya que proporciona más tiempo para que la base de datos secundaria se sincronice completamente con la principal.
Nota:
La base de datos secundaria se crea automáticamente mediante un proceso conocido como inicialización, que puede tardar tiempo en función del tamaño de la base de datos. Por tanto, es importante planear con antelación, y tener en cuenta factores como la velocidad de la red.
Para más información sobre la alta disponibilidad y la recuperación ante desastres para Azure SQL Database, vea Lista de comprobación de alta disponibilidad y recuperación ante desastres de Azure SQL Database.