Solución de problemas de conmutación por error de grupos de disponibilidad de Always On
Nota:
Para automatizar el análisis manual descrito en este artículo, consulte Uso de AGDiag para diagnosticar eventos de estado del grupo de disponibilidad.
En este artículo se proporcionan pasos de solución de problemas para ayudarle a determinar por qué se produjo una conmutación por error del grupo de disponibilidad.
Síntomas y efectos de Always On problema de salud o conmutación por error
Always On implementa una supervisión de estado sólida a través de diferentes mecanismos para garantizar el estado de la instancia de Microsoft SQL Server que hospeda la réplica principal, el clúster subyacente y el estado del sistema. La carga de trabajo de producción se interrumpe momentáneamente cuando se identifica un clúster de Windows o Always On problema de mantenimiento.
Cuando se detecta una condición de mantenimiento, normalmente se produce la siguiente secuencia de eventos. A lo largo de este solucionador de problemas, los eventos de estado se mencionan en referencia a los siguientes eventos:
Las réplicas y bases de datos del grupo de disponibilidad pasan del rol principal al rol de resolución.
Las bases de datos del grupo de disponibilidad pasan a estar sin conexión y ya no son accesibles.
El clúster de Windows marca el recurso clúster del grupo de disponibilidad como erróneo.
El clúster de Windows intenta poner de nuevo en línea el rol de grupo de disponibilidad (en la réplica de asociado de conmutación por error original o automática).
El rol de grupo de disponibilidad se conecta correctamente si se detecta que está en buen estado por Always On y la supervisión del estado del clúster de Windows.
Si se ejecuta correctamente, las réplicas y bases de datos del grupo de disponibilidad pasan al rol principal y las bases de datos del grupo de disponibilidad se conectan y la aplicación puede acceder a ellas.
Las aplicaciones no pueden acceder a las bases de datos del grupo de disponibilidad
Cuando se detecta una condición de mantenimiento, la réplica del grupo de disponibilidad y las bases de datos pasan al rol Resolving y las bases de datos del grupo de disponibilidad se desconectan. Una vez que la réplica está en línea en el rol principal (en el servidor de réplica original o en el servidor de réplica de asociado de conmutación por error), la réplica y las bases de datos vuelven a realizar la transición a en línea. Mientras la réplica y las bases de datos se resuelven y están sin conexión, las aplicaciones que intentan acceder a esas bases de datos de grupo de disponibilidad producen un error y generan un mensaje de "Error 983": Unable to access availability database.... Este error también se registra en el registro de errores de Microsoft SQL Server si SQL Server está configurado para registrar intentos de inicio de sesión erróneos:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
El período durante el cual el grupo de disponibilidad está en el rol Resolving antes de que vuelva a estar en línea en el rol principal suele durar solo unos segundos o incluso menos de un segundo.
Identificar y diagnosticar Always On eventos de mantenimiento del grupo de disponibilidad o conmutación por error
1. Identificar tendencias de estado de Always On
Es posible que investigue un único evento de estado de Always On o que haya una tendencia reciente o continua de problemas de mantenimiento que interrumpan de forma intermitente la producción. Las siguientes preguntas pueden ayudarle a restringir y correlacionar los cambios recientes en el entorno de producción que podrían estar relacionados con estos problemas de mantenimiento:
- ¿Cuándo comenzó la tendencia de eventos de estado de Always On o clúster?
- ¿Los eventos de mantenimiento se producen en un día determinado?
- ¿Los eventos de mantenimiento se producen a una hora determinada del día?
- ¿Los eventos de mantenimiento se producen en un día o semana determinados del mes?
Si detecta una tendencia, compruebe el mantenimiento programado en el sistema (el sistema host en un entorno virtual), los lotes ETL y otros trabajos que podrían correlacionarse con estos eventos de mantenimiento. Si el sistema es una máquina virtual, investigue el sistema host en busca de cambios que posiblemente se introdujeron en el momento de las interrupciones.
Considere la posibilidad de tener cargas de trabajo de producción ad hoc ocupadas que podrían correlacionarse con el momento de los problemas de mantenimiento (por ejemplo, cuando los usuarios inician sesión por primera vez en el sistema o después de que los usuarios vuelvan del almuerzo).
Nota:
Este es un buen momento para considerar un plan para recopilar datos de rendimiento a lo largo de la semana y el mes. Para comprender mejor cuándo está más ocupado el sistema, puede medir los contadores del monitor de rendimiento de Windows, como Processor Information::% Processor Time, Memory::Available MBytesy MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Revisión del registro del clúster
El registro de clúster de Windows es el registro más completo que se debe usar para identificar el tipo de evento de estado de Always On o clúster y también la condición de mantenimiento detectada que provocó el evento. Para generar y abrir el registro del clúster, siga estos pasos:
Use Windows PowerShell para generar el registro de clúster de Windows en el nodo de clúster que hospeda la réplica principal en el momento del evento de mantenimiento. Por ejemplo, ejecute el siguiente cmdlet en una ventana de PowerShell con privilegios elevados mediante "sql19agn1" como nombre de servidor basado en SQL Server:
get-clusterlog -Node sql19agn1 -UseLocalTime

Nota:
De forma predeterminada, el archivo de registro se crea en %WINDIR%\cluster\reports.
3. Busque el evento de mantenimiento en el registro del clúster.
Always On usa varios mecanismos de supervisión de estado para supervisar el estado del grupo de disponibilidad. Además de un evento de estado de clúster de Windows (en el que el clúster de Windows detecta un problema de mantenimiento entre los nodos del clúster), Always On tiene cuatro tipos diferentes de comprobaciones de estado:
- El servicio SQL Server no se está ejecutando
- Tiempo de espera de una concesión de SQL Server
- Tiempo de espera de una comprobación de estado de SQL Server
- Un problema de mantenimiento interno SQL Server
Para localizar cualquiera de estos Always On eventos de mantenimiento específicos, busque en el registro del clúster la cadena . [hadrag] Resource Alive result 0 Esta cadena se guarda en el registro del clúster cuando se detecta alguno de estos eventos. Por ejemplo:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
Puede usar una herramienta para buscar todos los eventos de estado en el registro del clúster, de modo que pueda generar un informe de resumen de Always On problemas de mantenimiento. Esto puede ser útil para identificar tendencias cronológicas y determinar si un tipo determinado de Always On condición de mantenimiento es recurrente. En la captura de pantalla siguiente se muestra cómo usar un editor de texto (NotePad++, en este caso) para buscar todas las líneas del registro del clúster que contienen la [hadrag] Resource Alive result 0 cadena:

Determinar el tipo de problema de mantenimiento que desencadenó la conmutación por error
Para determinar el tipo de problemas de mantenimiento que encuentra en el registro de clúster de la réplica principal, compárelos con los problemas que se describen en las secciones siguientes.
Evento de estado de clúster
El clúster de Microsoft Windows supervisa el estado de los servidores miembros del clúster. Si se detecta un problema de mantenimiento, es posible que se quite un servidor miembro del clúster del clúster. Además, los recursos del clúster (incluido el rol de grupo de disponibilidad hospedado en el servidor miembro del clúster quitado) se moverán a la réplica del asociado de conmutación por error del grupo de disponibilidad si está configurado para la conmutación por error automática.
Síntomas de eventos de estado de clúster
Este es un ejemplo de un evento de estado de clúster en el registro del clúster. Para encontrarlo, puede buscar Lost quorum o Cluster service has terminated porque puede estar presente durante el cambio de rol del grupo de disponibilidad o la conmutación por error.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Otra manera de identificar este evento es buscar en el registro de eventos del sistema de Windows:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Diagnóstico de un evento de estado de clúster
Los errores del registro de eventos de Windows (eventos 1135 y 1177) sugieren que la conectividad de red es una causa del evento. Esta es la razón más común por la que se detecta un problema de mantenimiento del clúster. En el ejemplo siguiente se muestra que otros servidores miembros del clúster no se pudieron comunicar con este servidor que hospeda la réplica principal del grupo de disponibilidad y que este problema desencadenó la eliminación del nodo de clúster del clúster:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Puede buscar en el registro del clúster pruebas de un error de conexión en el nodo. Desde la ubicación del registro de clúster donde encontró Lost quorum, busque cadenas como Failed to connect to remote endpoint, unreachabley is broken.
Resolución de un evento de estado de clúster
Asegúrese de que la supervisión del estado del clúster es adecuada para el entorno de host. Para obtener más información sobre SQL Server Always On grupos de disponibilidad hospedados en Microsoft Azure, consulte Introducción al clúster de conmutación por error de Windows Server: SQL Server en máquinas virtuales de Azure.
Si es necesario, considere la posibilidad de ponerse en contacto con el soporte técnico de alta disponibilidad de Microsoft Windows para abrir un incidente de soporte técnico.
SQL Server servicio está inactivo: un evento de estado de Always On
Always On supervisión de estado puede detectar si el servicio de SQL Server que hospeda la réplica principal del grupo de disponibilidad ya no se está ejecutando.
Síntomas del cierre del servicio SQL Server
Este es un ejemplo del informe de registro del clúster para el rol de grupo de disponibilidad "ag" que indica un error porque QueryServiceStatusEx devolvió un identificador 0de proceso:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Diagnóstico y resolución de eventos de cierre del servicio SQL
Compruebe el registro de eventos del sistema windows y SQL Server registro de errores para ver si hay un cierre inesperado SQL Server.
Si SQL Server se apagara mediante un apagado del sistema o un cierre administrativo, verá la siguiente entrada en el registro de errores de SQL Server:
2023-03-10 09:38:46.73 spid9s SQL Server termina en respuesta a una solicitud de "detención" de Service Control Manager. Solo se trata de un mensaje informativo. No requiere la intervención del usuario.
El registro de eventos del sistema windows mostraría la siguiente entrada de error:
Información 10/3/2023 9:41:06 AM Service Control Manager 7036 None El servicio SQL Server (MSSQLSERVER) entró en estado detenido.
El registro de eventos del sistema windows muestra la siguiente entrada de error si SQL Server se cierra inesperadamente:
Error 10/3/2023 8:37:46 AM Service Control Manager 7034 None El servicio SQL Server (MSSQLSERVER) finalizó inesperadamente. Lo ha hecho 1 vez.
Compruebe el final del registro de errores de SQL Server para obtener pistas. Si el registro de errores finaliza abruptamente, esto significa que se cerró por la fuerza. Por ejemplo, si SQL Server terminara mediante el Administrador de tareas, el informe de errores de SQL Server no revelaría ninguna información sobre los problemas internos que podrían haber provocado el cierre del proceso.
Si un problema de estado interno de SQL Server hizo que SQL Server finalizara inesperadamente, podría haber pistas de una posible excepción irrecuperable (incluido un diagnóstico de archivo de volcado que se genera) al final del registro de errores de SQL. Revise las pistas y tome las medidas necesarias. Si encuentra un archivo de volcado de memoria, considere la posibilidad de abrir contacto con el soporte técnico de Microsoft SQL Server y proporcionar el registro de errores de SQL Server y el contenido del archivo de volcado para una investigación más detallada.
Tiempo de espera de concesión: un evento de estado de Always On
Always On usa un mecanismo de "concesión" para supervisar el estado del equipo en el que está instalado SQL Server. El tiempo de espera de concesión predeterminado es de 20 segundos.
Síntomas de Always On eventos de tiempo de espera de concesión
Esta es una salida de ejemplo de un tiempo de espera de concesión de Always On del registro del clúster. Puede buscar estas cadenas para buscar un tiempo de espera de concesión en el registro del clúster.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Para obtener más información sobre el tiempo de espera de concesión, consulte la sección Mecanismo de concesión en Mecánica y directrices de tiempos de espera de concesión, clúster y comprobación de estado para grupos de disponibilidad de Always On.
Diagnóstico y resolución Always On eventos de tiempo de espera de concesión
Hay dos problemas principales que pueden desencadenar un tiempo de espera de concesión:
SQL Server diagnóstico del archivo de volcado: cuando SQL Server detecta determinados eventos de mantenimiento internos, como una infracción de acceso, una aserción o un interbloqueo del programador, genera un archivo de volcado de diagnóstico (.mdmp) en la carpeta SQL Server \LOG.
Un problema de rendimiento en todo el sistema: un tiempo de espera de concesión no indica necesariamente un problema de mantenimiento de SQL Server. En su lugar, podría indicar un problema de mantenimiento en todo el sistema que también afecta al estado del servidor basado en SQL Server. Para obtener pasos de solución de problemas más detallados, consulte MSSQLSERVER_19407.
1. diagnóstico de archivos de volcado de memoria SQL Server
SQL Server puede detectar un problema de mantenimiento interno, como una infracción de acceso, una aserción o programadores interbloqueados. En esta situación, el programa genera un archivo de mini volcado (.mdmp) en la carpeta SQL Server \LOG del proceso de SQL Server para el diagnóstico. El proceso de SQL Server se inmoviliza durante varios segundos mientras el archivo de mini volcado se escribe en el disco. Durante este tiempo, todos los subprocesos dentro del proceso de SQL Server están en un estado inmovilizado. Esto incluye el subproceso de concesión supervisado por Always On supervisión de estado. Por lo tanto, Always On podría detectar un tiempo de espera de concesión.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Para resolver este problema, se debe investigar el diagnóstico del archivo de volcado de memoria para determinar la causa principal. Considere la posibilidad de ponerse en contacto con el soporte técnico de Microsoft SQL Server para proporcionar el registro de errores de SQL Server y el contenido del archivo de volcado para una investigación más detallada.
2. Uso elevado de CPU u otro problema de rendimiento del sistema
Un tiempo de espera de concesión indica un problema de rendimiento que afecta a todo el sistema, incluidos los SQL Server. Para diagnosticar el problema del sistema, Always On diagnóstico de estado notifica los datos de supervisión del rendimiento en el registro del clúster e incluye el evento de tiempo de espera de concesión. Los datos de rendimiento abarcan aproximadamente 50 segundos antes del evento de tiempo de espera de concesión, informando sobre el uso de cpu, la memoria libre y la latencia de disco.
Este es un ejemplo de los datos de rendimiento notificados que muestran un tiempo de espera de concesión en el registro del clúster. En esta salida de ejemplo, un uso general elevado de la CPU que podría estar relacionado con el tiempo de espera de concesión.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Si los datos de rendimiento muestran un uso elevado de la CPU, una condición de memoria baja o una latencia de disco alta en el momento de un tiempo de espera de concesión, empiece a recopilar Monitor de rendimiento datos durante todo el día en la réplica principal para investigar estos síntomas. Al capturar datos del monitor de rendimiento durante un período más largo, puede identificar mejor los valores de línea base y máximo de estos recursos y supervisar los cambios en estos recursos cuando se produce un tiempo de espera de concesión. A medida que recopile estos datos, considere si hay ciertas cargas de trabajo programadas o ad hoc en SQL Server que se correlacionan con el tiempo de estos problemas de recursos y eventos de mantenimiento.
También debe capturar contadores que informen del mismo uso de recursos del sistema, incluidos los siguientes:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Tiempo de espera de comprobación de estado: un evento de estado de Always On
Cuando una réplica de grupo de disponibilidad pasa al rol principal, Always On supervisión de estado establece una conexión ODBC local a la instancia de SQL Server. Mientras Always On está conectado y supervisando, si SQL Server no responde a través de la conexión ODBC dentro del período establecido para el tiempo de espera de comprobación de estado del grupo de disponibilidad (el valor predeterminado es 30 segundos), se desencadena un evento de tiempo de espera de comprobación de estado. En esta situación, el grupo de disponibilidad pasa del rol principal al rol Resolving e inicia la conmutación por error, si está configurado para hacerlo.
Para obtener más información sobre los tiempos de espera de comprobación de estado, consulte la sección "Operación de tiempo de espera de comprobación de estado" en Mecánicas y directrices de tiempos de espera de concesión, clúster y comprobación de estado para grupos de disponibilidad de Always On.
Este es un Always On tiempo de espera de comprobación de estado como se indica en el registro del clúster:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Diagnóstico y resolución de Always On evento de tiempo de espera de comprobación de estado
La sección siguiente le ayuda a revisar los registros de SQL Server para los eventos de "miga de pan" que puede encontrar y que se correlacionan con Always On tiempos de espera de comprobación de estado que se detectan y notifican. Los registros que se revisan aquí incluyen el registro del clúster (donde se confirma el tiempo de espera de comprobación de estado), los system_health registros de eventos extendidos y los registros de errores de SQL Server (ambos se encuentran en la carpeta SQL Server \LOG) y el registro de eventos del sistema Windows. Use estos y otros registros para buscar eventos de correlación que puedan ayudarle a limitar la causa del tiempo de espera de la comprobación de estado.
1. Comprobar si hay eventos de programador que no son de rendimiento
El tiempo de espera de la comprobación de estado de Always On suele deberse a eventos de "no rendimiento" en SQL Server. Cuando SQL Server detecta que un subproceso no se ha producido en un programador, notificará que se ha producido un evento de programador que no produce resultados. Si ve otras tareas en el mismo programador que no reciben tiempo de CPU, este es el signo principal de un programador que no produce rendimiento. Este comportamiento puede provocar una ejecución diferida de esas tareas y cargas de trabajo "de hambre" asignadas a un programador determinado de tiempo de CPU.
Para comprobar si hay eventos de programador que no producen rendimiento, siga estos pasos:
Compruebe el SQL Server
system_healthregistros de eventos extendidos para determinar si se notificó algún tipo de evento del programador que no produce rendimiento en el momento del evento de tiempo de espera de Always On comprobación de estado. Entre los eventos que no producen rendimiento que puede encontrar se incluyen los siguientes:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Abra el SQL Server registros de eventos extendidos de mantenimiento del sistema en la réplica principal hasta el momento en que se sospecha que se agotó el tiempo de espera de la comprobación de estado.
En SQL Server Management Studio (SSMS), vaya a Abrir archivo >y seleccione Combinar archivos de eventos extendidos.
Seleccione el botón Agregar.
En el cuadro de diálogo Abrir archivo, vaya a los archivos del directorio SQL Server \LOG.
Mantenga presionado Control y, a continuación, seleccione los archivos cuyos nombres comiencen por
system_health_xxx.xel.Seleccione Abrir>aceptar.
Filtre los resultados. Haga clic con el botón derecho en un evento en la columna de nombre y seleccione Filtrar por este valor.
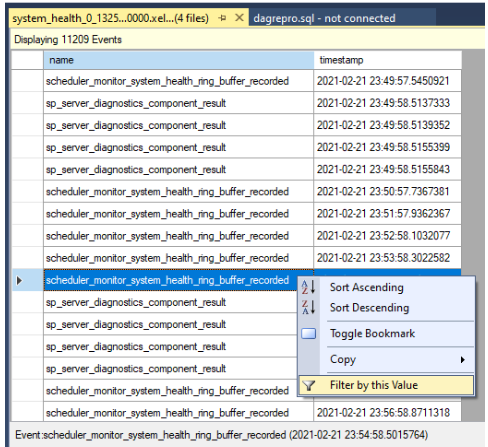
Defina un filtro para ordenar las filas en las que los valores de la columna de nombre contienen
yield, como se muestra en la captura de pantalla siguiente. Esto devuelve todos los tipos de eventos que no producen que se hayan registrado en lossystem_healthregistros.
Compare las marcas de tiempo para ver si hubo eventos que no producen en el momento del tiempo de espera de la comprobación de estado. Este es el tiempo de espera de la comprobación de estado, tal como se indica en el registro del clúster:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Puede ver que hubo eventos que no son de rendimiento que se produjeron en el momento del tiempo de espera de la comprobación de estado.
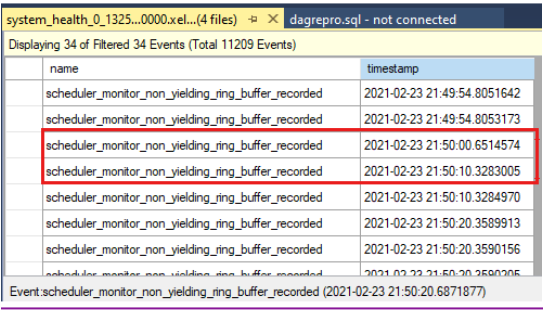
Si se detectan eventos que no producen resultados, compruebe la causa del evento que no produce. Considere la posibilidad de ponerse en contacto con el equipo de soporte técnico de SQL Server para investigar los eventos que no producen.
2. Compruebe el registro de errores de SQL Server
Compruebe el registro de errores de SQL Server para obtener eventos de correlación en el momento del tiempo de espera de la comprobación de estado. Estos eventos pueden proporcionar "migajas de pan" que sugieren pasos adicionales para limitar la causa principal de los tiempos de espera de la comprobación de estado.
Por ejemplo, la siguiente entrada de registro muestra que se ha producido un tiempo de espera de comprobación de estado en el registro del clúster:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
En el registro de errores de SQL Server, en cuestión de segundos del tiempo de espera de la comprobación de estado, SQL Server informa de que ha detectado una latencia de E/S grave:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Revise el registro de eventos del sistema para ver posibles pistas del sistema que podrían estar relacionadas con el evento de tiempo de espera de comprobación de estado. Al revisar el registro de eventos del sistema de Windows, es posible que encuentre un problema de E/S que se notifica al mismo tiempo para el mismo tiempo de espera de comprobación de estado:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
estado de SQL Server: un evento de estado de Always On
Always On supervisa diferentes tipos de eventos de estado de SQL Server. Aunque hospeda una réplica principal de grupo de disponibilidad, SQL Server ejecuta sp_server_diagnostics continuamente informes sobre el estado de SQL Server mediante distintos componentes. Cuando se detectan problemas de mantenimiento, sp_server_diagnostics notifica un error para ese componente determinado y, a continuación, envía los resultados al proceso de detección de estado de Always On. Cuando se notifica un error, el rol grupo de disponibilidad muestra el estado de error y la posible conmutación por error si el grupo de disponibilidad está configurado para hacerlo.
Síntomas de Always On SQL Server eventos de salud
Este es un ejemplo de un problema de estado de SQL Server como se indica sp_server_diagnostics en el registro del clúster. SQL Server notifica un estado de "error" en el componente del sistema para Always On supervisión de estado y el grupo de disponibilidad "contoso-ag" pasa a un estado con errores.
Nota:
Un problema de estado de SQL Server genera un informe similar al del tiempo de espera de la comprobación de estado. Ambos eventos de mantenimiento informan Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevelde . La distinción de un evento de estado de SQL Server es que informa de que el componente SQL Server ha cambiado de "advertencia" a "error".
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Diagnóstico y resolución de eventos de estado de SQL Server
El tipo de problema de mantenimiento notificado por SQL Server estado debe determinar la dirección del análisis de la causa principal.
De forma predeterminada, al implementar un grupo de disponibilidad, se FAILURE_CONDITION_LEVEL establece en tres. Esto activa la supervisión de algunos perfiles de estado, pero no todos SQL Server. En el nivel predeterminado, Always On desencadena un evento de mantenimiento cuando SQL Server genera demasiados archivos de volcado de memoria, una infracción de acceso de escritura o un bloqueo de número huérfano. Al establecer el grupo de disponibilidad hasta el nivel cuatro o cinco, se expandirán los tipos de problemas de estado de SQL Server que se supervisan. Para obtener más información sobre los monitores de Always On de mantenimiento de SQL Server, consulte Configuración de una directiva de conmutación por error automática flexible para un grupo de disponibilidad: SQL Server Always On.
Para identificar el Always On problema de mantenimiento específico, siga estos pasos:
Abra los registros de eventos extendidos de diagnóstico del clúster de SQL Server en la réplica principal hasta el momento en que se produjo el evento de mantenimiento de SQL Server sospecha.
En SSMS, vaya a Archivo>abierto y, a continuación, seleccione Combinar archivos de eventos extendidos.
Seleccione Agregar.
En el cuadro de diálogo Abrir archivo, vaya a los archivos del directorio SQL Server \LOG.
Presione Control, seleccione los archivos cuyos nombres coincidan
<servername>_<instance>_SQLDIAG_xxx.xely, a continuación, seleccione Abrir>aceptar.
Verá una nueva ventana con pestañas en SSMS que incluye los eventos extendidos, como se muestra en la captura de pantalla siguiente.
Para investigar un problema de estado de SQL Server, busque cuyo
component_health_resultstate_descvalor eserror. Este es un ejemplo de un evento de componente del sistema que ha notificado un error a Always On supervisión de estado: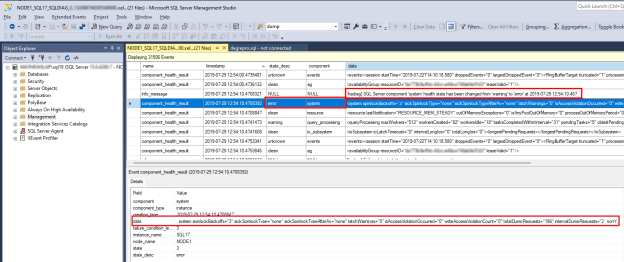
Haga doble clic en la columna de datos del panel inferior. Esto abre los datos detallados del componente en un nuevo panel de ventana de SSMS para su revisión. Este es el aspecto de los datos del componente del sistema:

Observe que los datos "totalDumprequests=186" indican que se han generado demasiados eventos de diagnóstico de archivos de volcado en este SQL Server. Esta es la razón por la que el componente del sistema informó de un estado de error. Cuando Always On supervisión de estado recibe este estado de error, desencadena un evento de mantenimiento del grupo de disponibilidad. También puede comprobar que no se han detectado infracciones de acceso de escritura ni bloqueos de número huérfanos a partir de los datos proporcionados en los datos del componente del sistema.
Si es necesario, póngase en contacto con SQL Server soporte técnico para abrir un incidente de soporte técnico para obtener más ayuda para encontrar la causa principal de estos problemas internos de SQL Server salud.


