Nouveautés de SQL Server Analysis Services
S’applique à :
 SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
Cet article résume les nouvelles fonctionnalités, les améliorations, les fonctionnalités déconseillées et abandonnées, ainsi que le comportement et les changements cassants dans les versions les plus récentes de SQL Server Analysis Services (SSAS).
SQL Server 2022 Analysis Services
Mise à jour cumulative 1 (CU1)
Mise à niveau du chiffrement
Cette mise à jour inclut une amélioration de l’algorithme de chiffrement des opérations d’écriture de schéma. Cette amélioration peut vous obliger à mettre à niveau des bases de données de modèle tabulaire et multidimensionnel pour garantir un chiffrement approprié. Pour plus d’informations, consultez Mettre à niveau le chiffrement.
Disponibilité générale (GA)
Fusion horizontale
Cette version introduit la fusion horizontale, une optimisation du plan d’exécution de requête visant à réduire le nombre de requêtes de source de données nécessaires pour générer et retourner des résultats. Plusieurs requêtes de source de données plus petites sont fusionnées en une requête de source de données plus grande. Moins de requêtes de source de données signifie moins d’allers-retours et moins d’analyses coûteuses sur des sources de données volumineuses, ce qui entraîne des gains de performances DAX importants et une réduction de la demande de traitement au niveau de la source de données. Les requêtes DAX s’exécutent plus rapidement avec la fusion horizontale, en particulier en mode DirectQuery. En outre, la scalabilité augmente également.
Plans d’exécution parallèles pour DirectQuery
Cette amélioration permet au moteur Analysis Services d’analyser les requêtes DAX sur une source de données DirectQuery et d’identifier les opérations indépendantes du moteur de stockage. Le moteur peut ensuite exécuter ces opérations sur la source de données en parallèle. En exécutant des opérations en parallèle, le moteur Analysis Services peut améliorer les performances des requêtes en tirant parti de la scalabilité des sources de données volumineuses qui peuvent être en mesure de fournir. Pour vous assurer que le traitement des requêtes ne surcharge pas votre source de données, utilisez le paramètre de propriété MaxParallelism pour spécifier un nombre fixe de threads pouvant être utilisés pour les opérations parallèles.
Prise en charge des modèles sémantiques Power BI DirectQuery
Cette version introduit la prise en charge des modèles Power BI avec des connexions DirectQuery à SQL Server modèles Analysis Services 2022. Les modélisateurs de données et les auteurs de rapports utilisant les versions de mai 2022 et ultérieures de Power BI Desktop peuvent désormais combiner d’autres données importées et DirectQuery à partir de modèles Power BI, Azure Analysis Services et maintenant SSAS 2022.
Pour plus d’informations, consultez Utilisation de DirectQuery pour les modèles sémantiques et Analysis Services | Documentation Power BI.
Performances des requêtes MDX
Introduit pour la première fois dans Power BI et maintenant dans SSAS 2022, MDX Fusion inclut l’optimisation du moteur de formule (FE) qui réduit le nombre de requêtes du moteur de stockage (SE) par requête MDX. Les applications clientes qui utilisent des expressions multidimensionnelles (MDX) pour interroger des données de modèle/jeu de données telles que Microsoft Excel verront des performances de requête améliorées. Les modèles de requête MDX courants nécessitent désormais moins de requêtes SE, alors qu’auparavant de nombreuses requêtes SE étaient nécessaires pour prendre en charge une granularité différente. Moins de requêtes SE signifient moins d’analyses coûteuses sur des modèles volumineux, ce qui entraîne des gains de performances significatifs, en particulier lors de la connexion à des modèles tabulaires en mode Requête directe.
Pour plus d’informations, consultez Annonce d’amélioration des performances des requêtes MDX dans Power BI | Blog Microsoft Power BI.
Gouvernance des ressources
Cette version inclut une précision améliorée pour la propriété de mémoire du serveur QueryMemoryLimit et la propriété de chaîne de connexion DbpropMsmdRequestMemoryLimit.
Introduite pour la première fois dans SSAS 2019, la propriété de mémoire du serveur QueryMemoryLimit s’applique uniquement aux pools de mémoire où les résultats de requête DAX intermédiaires sont créés pendant le traitement de la requête. Désormais, dans SSAS 2022, elle s’applique également aux requêtes MDX, couvrant efficacement toutes les requêtes. Vous pouvez mieux contrôler les requêtes coûteuses de processus qui entraînent une matérialisation significative. Si la requête atteint la limite spécifiée, le moteur annule la requête et retourne une erreur à l’appelant, ce qui réduit l’impact sur les autres utilisateurs simultanés.
Les applications clientes peuvent réduire davantage la mémoire autorisée par requête en spécifiant la propriété de chaîne de connexion DbpropMsmdRequestMemoryLimit. Spécifiée en Kilo-octets, cette propriété remplace la valeur de la propriété mémoire du serveur QueryMemoryLimit pour une connexion.
Entrelacement de requêtes - Biais de requête court avec annulation rapide
Cette version introduit une nouvelle valeur qui spécifie le biais de requête courte avec annulation rapide pour le paramètre de propriété Threadpool\SchedulingBehavior. Ce paramètre de propriété améliore les temps de réponse aux requêtes utilisateur dans les scénarios de haute concurrence. Pour plus d’informations, consultez Interlacement de requêtes - Configurer.
Niveau de compatibilité du modèle tabulaire 1600
Cette version introduit le niveau de compatibilité 1600 pour les modèles tabulaires. Le niveau de compatibilité 1600 coïncide avec les dernières fonctionnalités de Power BI et Azure Analysis Services.
Fonctionnalités dépréciées dans SSAS 2022
Aucune fonctionnalité déconseillée n’est annoncée avec cette version.
Fonctionnalités supprimées dans SSAS 2022
Les fonctionnalités suivantes sont supprimées dans cette version :
| Mode/Catégorie | Fonctionnalité |
|---|---|
| Tabulaire | Niveaux de compatibilité 1100 et 1103 |
| Multidimensionnel | Exploration de données |
| Mode Power Pivot | Power Pivot pour SharePoint |
Changements cassants dans SSAS 2022
Les niveaux de compatibilité des modèles tabulaires 1100 et 1103 sont supprimés dans cette version. Pour éviter toute modification cassant, mettez à niveau les modèles vers le niveau de compatibilité 1200 avant de mettre à niveau une version antérieure de SSAS vers SSAS 2022.
Changements de comportement dans SSAS 2022
Il n’y a aucun changement de comportement dans cette version.
SQL Server 2019 Analysis Services
SQL Server 2019 Analysis Services CU 5
SQL Server Analysis Services mises à jour cumulatives sont incluses avec SQL Server mises à jour cumulatives. Pour en savoir plus sur la dernière mise à jour cumulative et la télécharger, consultez SQL Server dernière mise à jour cumulative 2019. Les pages de base de connaissances des mises à jour cumulatives résument les problèmes connus, les améliorations et les correctifs pour toutes les fonctionnalités SQL Server, y compris SSAS. Des détails supplémentaires sur les principales mises à jour des fonctionnalités pour SSAS sont décrits ici.
SuperDAX pour les modèles multidimensionnels (SuperDAXMD)
Avec CU5, les clients basés sur DAX peuvent désormais utiliser des fonctions SuperDAX et des modèles de requête sur des modèles multidimensionnels, offrant ainsi des performances améliorées lors de l’interrogation des données du modèle. SuperDAX a introduit pour la première fois des optimisations de requête DAX pour les modèles tabulaires avec Power BI et SQL Server Analysis Services 2016. SuperDAXMD apporte désormais ces améliorations aux modèles multidimensionnels.
Une annonce distincte sur le blog Power BI montre comment les utilisateurs de Power BI peuvent tirer parti de cette amélioration des performances du modèle multidimensionnel en téléchargeant la dernière version de Power BI Desktop. Les rapports interactifs existants dans le service Power BI peuvent bénéficier sans aucune étape supplémentaire, car Power BI génère automatiquement les requêtes SuperDAX optimisées. Power BI détecte automatiquement les connexions aux modèles multidimensionnels avec la prise en charge de SuperDAX et utilise les mêmes fonctions DAX optimisées et les mêmes modèles de requête qu’il utilise déjà sur les modèles tabulaires. Bien que Power BI puisse basculer automatiquement vers SuperDAXMD, dans vos propres solutions d’aide à la décision, vous devrez peut-être optimiser manuellement les modèles de requête DAX.
Les modèles de requête optimisés doivent utiliser la fonction SUMMARIZECOLUMNS pour remplacer la fonction SUMMARIZE standard moins efficace. Utilisez des variables DAX, VAR, pour calculer des expressions une seule fois au lieu de définition, puis réutilisez les résultats dans d’autres expressions DAX sans avoir à effectuer à nouveau le calcul. D’autres fonctions SuperDAX, et peut-être moins courantes, sont SUBSTITUTEWITHINDEX, ADDMISSINGITEMS, ainsi que NATURALLEFTOUTERJOIN et NATURALINNERJOIN, ISONORAFTER et GROUPBY. SELECTCOLUMNS et UNION sont également des fonctions SuperDAX.
Pour en savoir plus sur le fonctionnement de DAX avec les modèles multidimensionnels, ainsi que sur les modèles et contraintes importants à connaître, consultez DAX pour les modèles multidimensionnels.
SQL Server 2019 Analysis Services GA (disponibilité générale)
Niveau de compatibilité du modèle tabulaire
Cette version introduit le niveau de compatibilité 1500 pour les modèles tabulaires.
Entrelacement de requêtes
L’entrelacement de requêtes est une configuration système en mode tabulaire qui peut améliorer les temps de réponse des requêtes utilisateur dans des scénarios à concurrence élevée. L’entrelacement des requêtes avec un biais de requête court permet aux requêtes simultanées de partager des ressources processeur. Pour en savoir plus, consultez Entrelacement de requêtes.
Groupes de calcul dans les modèles tabulaires
Les groupes de calcul peuvent réduire de manière significative le nombre de mesures redondantes en regroupant les expressions de mesure courantes en tant qu’éléments de calcul. Les groupes de calcul apparaissent dans les rapports de clients sous forme de table avec une seule colonne. Chaque valeur incluse dans la colonne représente un calcul réutilisable, ou un élément de calcul, applicable à l’une des mesures. Un groupe de calcul peut comporter n’importe quel nombre d’éléments de calcul. Chaque élément de calcul est défini par une expression DAX. Pour plus d’informations, consultez Groupes de calcul.
Paramètre de gouvernance pour les actualisations du cache Power BI
Le paramètre de propriété ClientCacheRefreshPolicy est désormais pris en charge dans SSAS 2019 et versions ultérieures. Ce paramètre de propriété est déjà disponible pour Azure Analysis Services. Le service Power BI met en cache les données de vignette du tableau de bord et les données de rapport pour la charge initiale de Live Connect rapport, ce qui entraîne l’envoi d’un nombre excessif de requêtes de cache au moteur et, dans les cas extrêmes, la surcharge du serveur. La propriété ClientCacheRefreshPolicy vous permet de remplacer ce comportement au niveau du serveur. Pour plus d’informations, consultez Propriétés générales.
Attachement en ligne
Cette fonctionnalité offre la possibilité d’attacher un modèle tabulaire dans le cadre d’une opération en ligne. L’attachement en ligne peut être utilisé pour la synchronisation des réplicas en lecture seule dans les environnements locaux de scale-out des requêtes. Pour effectuer une opération d’attachement en ligne, utilisez l’option AllowOverwrite de la commande Attacher XMLA.

Cette opération peut nécessiter deux fois plus de mémoire pour que l’ancienne version reste en ligne pendant le chargement de la nouvelle version.
Voici un exemple d’utilisation classique :
DB1 (version 1) est déjà attachée au serveur B en lecture seule.
DB1 (version 2) est traitée sur le serveur A d’écriture.
DB1 (version 2) est détachée puis placée à un emplacement accessible au serveur B (via un emplacement partagé ou à l’aide de Robocopy, etc.).
La <commande Attacher> avec AllowOverwrite=True est exécutée sur le serveur B avec le nouvel emplacement de DB1 (version 2).
Sans cette fonctionnalité, les administrateurs doivent d’abord détacher la base de données, puis attacher la nouvelle version de la base de données. Cette solution provoque un temps d’arrêt durant lequel la base de données n’est pas disponible et les requêtes qui lui sont envoyées échouent.
Lorsque ce nouvel indicateur est spécifié, la version 1 de la base de données est supprimée atomiquement dans la même transaction, sans temps d’arrêt. Toutefois, cela nécessite que les deux bases de données soient chargées en mémoire simultanément.
Relations plusieurs-à-plusieurs dans les modèles tabulaires
Cette amélioration permet des relations plusieurs-à-plusieurs entre les tables où les deux colonnes ne sont pas uniques. Une relation peut être définie entre une table de dimension et une table de faits à un niveau de précision supérieur à celui de la colonne clé de la dimension. Cela évite d’avoir à normaliser les tables de dimension et peut améliorer l’expérience utilisateur, car le modèle résultant a un plus petit nombre de tables avec des colonnes regroupées logiquement.
Les relations plusieurs-à-plusieurs nécessitent que les modèles soient au niveau de compatibilité 1500 et supérieur. Vous pouvez créer des relations plusieurs-à-plusieurs à l’aide de Visual Studio 2019 avec les projets Analysis Services VSIX update 2.9.2 et versions ultérieures, l’API TOM (Tabular Object Model), le langage TMSL (Tabular Model Scripting Language) et l’outil open source Tabular Editor.
Paramètres de mémoire pour la gouvernance des ressources
Les paramètres de propriété suivants fournissent une meilleure gouvernance des ressources :
- Memory\QueryMemoryLimit : cette propriété de mémoire peut être utilisée pour limiter les spools de mémoire générés par les requêtes DAX soumises au modèle.
- DbpropMsmdRequestMemoryLimit : cette propriété XMLA peut être utilisée pour remplacer la valeur de propriété de serveur Memory\QueryMemoryLimit pour une connexion.
- OLAP\Query\RowsetSerializationLimit : cette propriété de serveur limite le nombre de lignes retournées dans un ensemble de lignes, ce qui protège les ressources serveur contre une utilisation de l’exportation des données extensives. Cette propriété s’applique à la fois aux requêtes DAX et aux requêtes MDX.
Ces propriétés peuvent être définies en installant la dernière version de SQL Server Management Studio (SSMS). Ces paramètres sont déjà disponibles pour Azure Analysis Services.
Fonctionnalités déconseillées dans SSAS 2019
Aucune fonctionnalité déconseillée n’est annoncée avec cette version.
Fonctionnalités supprimées dans SSAS 2019
Aucune fonctionnalité abandonnée n’a été annoncée avec cette version.
Changements cassants dans SSAS 2019
Il n’y a aucune modification cassant dans cette version.
Changements de comportement dans SSAS 2019
Il n’y a aucun changement de comportement dans cette version.
SQL Server 2017 Analysis Services
SQL Server 2017, Analysis Services a vu certaines des améliorations les plus importantes depuis SQL Server 2012. S’appuyant sur le succès du mode tabulaire (introduit pour la première fois dans SQL Server 2012 Analysis Services), cette version rend les modèles tabulaires plus puissants que jamais.
Le mode multidimensionnel et le mode Power Pivot pour SharePoint sont des éléments de base pour de nombreux déploiements Analysis Services. Dans le cycle de vie du produit Analysis Services, ces modes sont matures. Il n’existe aucune nouvelle fonctionnalité pour l’un de ces modes dans cette version. Toutefois, des correctifs de bogues et des améliorations des performances sont inclus.
Les fonctionnalités décrites ici sont incluses dans SQL Server 2017 Analysis Services. Toutefois, pour en tirer parti, vous devez également utiliser les dernières versions de Visual Studio avec des projets et des SQL Server Management Studio Analysis Services (SSMS). Les projets Analysis Services et SSMS sont mis à jour chaque mois avec des fonctionnalités nouvelles et améliorées qui coïncident généralement avec de nouvelles fonctionnalités dans SQL Server.
S’il est important d’en savoir plus sur toutes les nouvelles fonctionnalités, il est également important de savoir ce qui est déprécié et abandonné dans cette version et les versions futures. Pour plus d’informations, consultez Fonctionnalités déconseillées dans SSAS 2017.
Examinons quelques-unes des nouvelles fonctionnalités clés de cette version.
Niveau de compatibilité 1400 pour les modèles tabulaires
Pour tirer parti de la plupart des nouvelles fonctionnalités décrites ici, les modèles tabulaires nouveaux ou existants doivent être définis ou mis à niveau vers le niveau de compatibilité 1400. Les modèles au niveau de compatibilité 1400 ne peuvent pas être déployés vers SQL Server 2016 SP1 ou version antérieure, ni passés à une version antérieure pour réduire les niveaux de compatibilité. Pour plus d’informations, consultez Niveau de compatibilité pour les modèles tabulaires Analysis Services.
Dans Visual Studio, vous pouvez sélectionner le nouveau niveau de compatibilité 1400 lors de la création de projets de modèle tabulaire.
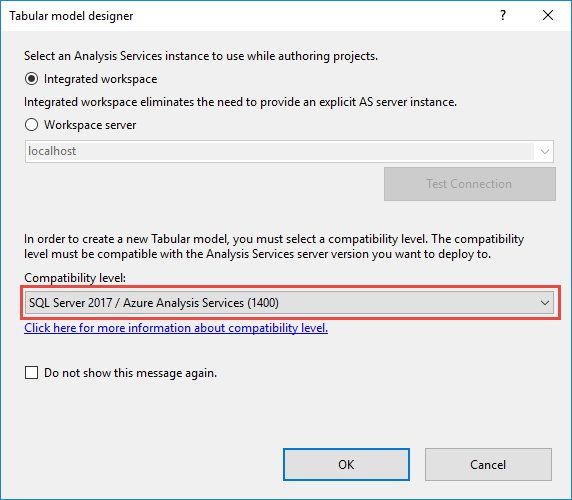
Pour mettre à niveau un modèle tabulaire existant dans Visual Studio, dans Explorateur de solutions, cliquez avec le bouton droit sur Model.bim, puis, dans Propriétés, définissez la propriété Niveau de compatibilitésur SQL Server 2017 (1400).
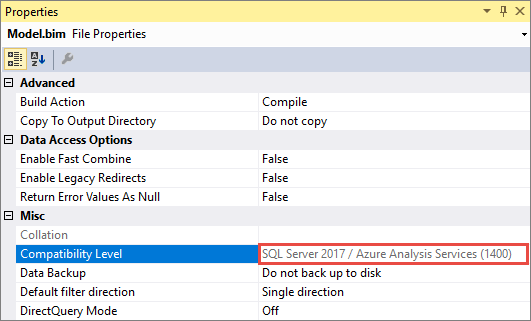
Il est important de garder à l’esprit qu’une fois que vous mettez à niveau un modèle existant vers 1400, vous ne pouvez pas passer à une version antérieure. Veillez à conserver une sauvegarde de votre base de données de modèle 1200.
Expérience moderne d’obtention des données
Quand il s’agit d’importer des données à partir de sources de données dans vos modèles tabulaires, SSDT introduit l’expérience moderne Get Data pour les modèles au niveau de compatibilité 1400. Cette nouvelle fonctionnalité est basée sur des fonctionnalités similaires de Power BI Desktop et de Microsoft Excel 2016. L’expérience moderne Get Data fournit d’immenses fonctionnalités de transformation de données et de mashup de données à l’aide du générateur de requêtes Get Data et des expressions M.
L’expérience moderne Get Data prend en charge un large éventail de sources de données. À l’avenir, les mises à jour incluront la prise en charge d’encore plus.
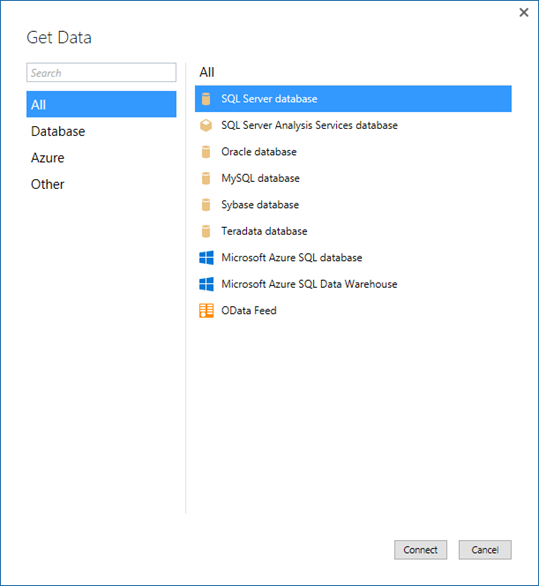
Une interface utilisateur puissante et intuitive facilite la sélection de vos données et de vos fonctionnalités de transformation/mashup.
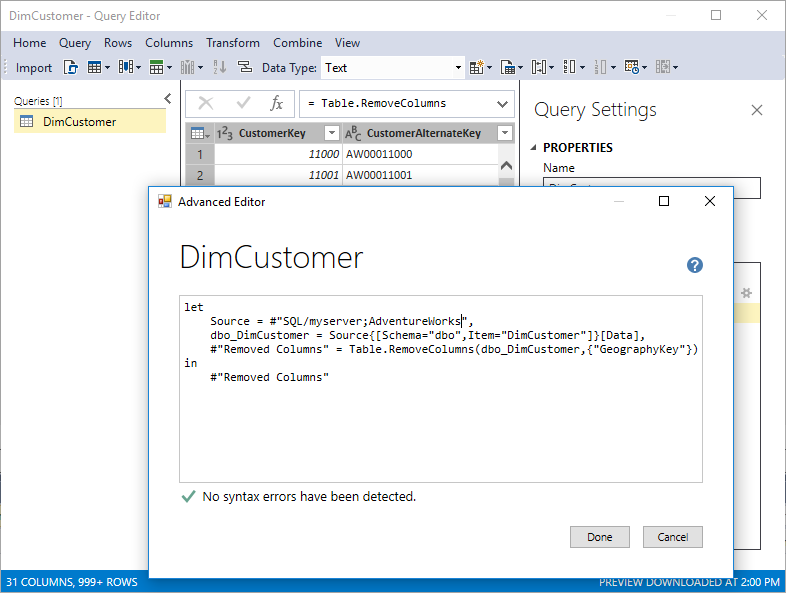
Les fonctionnalités modernes get data et mashup M ne s’appliquent pas aux modèles tabulaires existants mis à niveau du niveau de compatibilité 1200 à 1400. La nouvelle expérience s’applique uniquement aux nouveaux modèles créés au niveau de compatibilité 1400.
Indicateurs d’encodage
Cette version introduit des indicateurs d’encodage, une fonctionnalité avancée utilisée pour optimiser le traitement (actualisation des données) des grands modèles tabulaires en mémoire. Pour mieux comprendre l’encodage, consultez Réglage des performances des modèles tabulaires dans SQL Server livre blanc Analysis Services 2012 pour mieux comprendre l’encodage.
L’encodage de valeur offre de meilleures performances de requête pour les colonnes qui sont généralement utilisées uniquement pour les agrégations.
L’encodage de hachage est préféré pour les colonnes group-by (souvent des valeurs de table de dimension) et les clés étrangères. Les colonnes de chaîne sont toujours encodées au hachage.
Les colonnes numériques peuvent utiliser l’une de ces méthodes d’encodage. Quand Analysis Services commence à traiter une table, si la table est vide (avec ou sans partitions) ou si une opération de traitement de table complète est en cours, des valeurs d’échantillons sont prises pour chaque colonne numérique afin de déterminer s’il faut appliquer un encodage de valeur ou de hachage. Par défaut, l’encodage de valeur est choisi lorsque l’échantillon de valeurs distinctes dans la colonne est suffisamment grand ; sinon, l’encodage de hachage offre généralement une meilleure compression. Il est possible pour Analysis Services de modifier la méthode d’encodage après le traitement partiel de la colonne en fonction d’informations supplémentaires sur la distribution des données, puis de redémarrer le processus d’encodage ; toutefois, cela augmente le temps de traitement et est inefficace. Le livre blanc sur le réglage des performances décrit le réécodage plus en détail et explique comment le détecter à l’aide de SQL Server Profiler.
Les indicateurs d’encodage permettent au modélisateur de spécifier une préférence pour la méthode d’encodage en fonction des connaissances préalables du profilage des données et/ou en réponse à des événements de suivi de nouveau. Étant donné que l’agrégation sur des colonnes encodées par hachage est plus lente que sur les colonnes encodées avec une valeur, l’encodage de valeur peut être spécifié comme indicateur pour ces colonnes. Il n’est pas garanti que la préférence soit appliquée. Il s’agit d’un indicateur par opposition à un paramètre. Pour spécifier un indicateur d’encodage, définissez la propriété EncodingHint sur la colonne. Les valeurs possibles sont « Default », « Value » et « Hash ». L’extrait de code suivant des métadonnées JSON du fichier Model.bim spécifie l’encodage de valeur pour la colonne Sales Amount.
{
"name": "Sales Amount",
"dataType": "decimal",
"sourceColumn": "SalesAmount",
"formatString": "\\$#,0.00;(\\$#,0.00);\\$#,0.00",
"sourceProviderType": "Currency",
"encodingHint": "Value"
}
Hiérarchies déséquilibrées
Dans les modèles tabulaires, vous pouvez modéliser les hiérarchies parent-enfant. Les hiérarchies avec différents nombres de niveaux sont souvent appelées hiérarchies déséquilibrées. Par défaut, les hiérarchies déséquilibrées sont affichées avec des vides pour les niveaux en dessous de l’enfant le plus bas. Voici un exemple de hiérarchie déséquilibrée dans un organigramme :
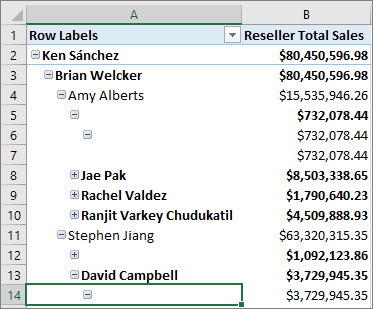
Cette version introduit la propriété Masquer les membres . Vous pouvez définir la propriété Masquer les membres pour une hiérarchie sur Masquer les membres vides.
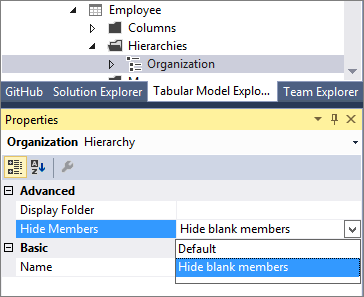
Notes
Dans le modèle, les membres vides sont représentés par une valeur vide DAX, et non par une chaîne vide.
Lorsque la propriété Masquer les membres videsest définie, et lorsque le modèle est déployé, une version plus lisible de la hiérarchie est affichée dans les clients de gestion de rapports comme Excel.
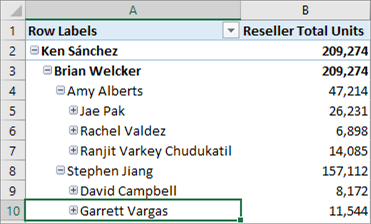
Lignes de détails
Vous pouvez maintenant définir un ensemble de lignes personnalisées contribuant à une valeur de mesure. Les lignes de détails sont similaires à l’action d’extraction par défaut dans les modèles multidimensionnels. Cela permet aux utilisateurs finaux d’afficher des informations de manière plus détaillée que le niveau agrégé.
Le tableau croisé dynamique suivant montre le total des ventes sur Internet par an de l’exemple de modèle tabulaire Adventure Works. Cliquez avec le bouton droit sur une cellule avec une valeur agrégée de la mesure, puis cliquez sur Afficher les détails pour afficher les lignes de détails.
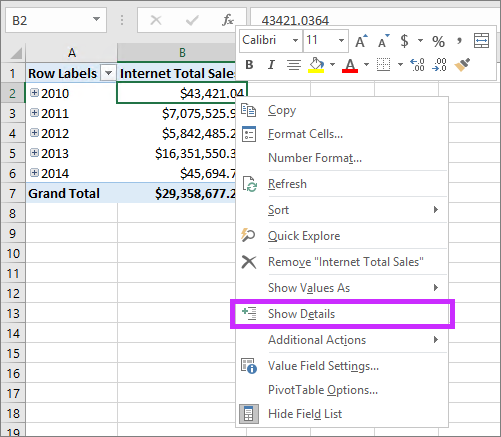
Par défaut, les données associées à la table des ventes sur Internet s’affiche. Ce comportement limité n’est généralement pas significatif pour l’utilisateur car la table ne dispose peut-être pas des colonnes nécessaires pour afficher des informations utiles telles que le nom du client et les informations de commande. Avec les lignes de détails, vous pouvez spécifier une propriété Expression de lignes de détails pour les mesures.
Propriété Expression de lignes de détails pour les mesures
La propriété Expression de lignes de détails pour les mesures permet aux créateurs de modèles de personnaliser les colonnes et les lignes renvoyées à l’utilisateur final.
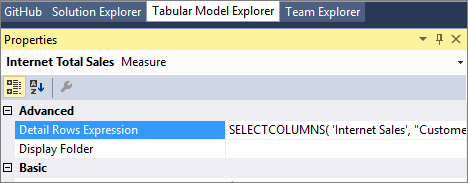
La fonction DAX SELECTCOLUMNS est couramment utilisée dans une expression de lignes de détail. L’exemple suivant définit les colonnes à renvoyer pour les lignes dans la table des ventes sur Internet, dans l’exemple de modèle tabulaire Adventure Works :
SELECTCOLUMNS(
'Internet Sales',
"Customer First Name", RELATED( Customer[Last Name]),
"Customer Last Name", RELATED( Customer[First Name]),
"Order Date", 'Internet Sales'[Order Date],
"Internet Total Sales", [Internet Total Sales]
)
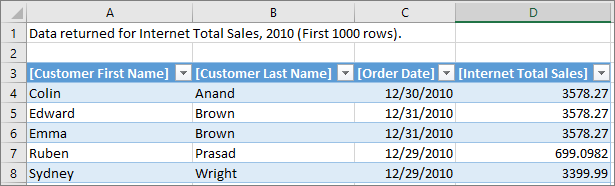
Lorsque la propriété est définie et lorsque le modèle est déployé, un ensemble de lignes personnalisé est renvoyé quand l’utilisateur sélectionne Afficher les détails. Il respecte automatiquement le contexte de filtre de la cellule sélectionnée. Dans cet exemple, seules les lignes pour la valeur 2010 sont affichées :
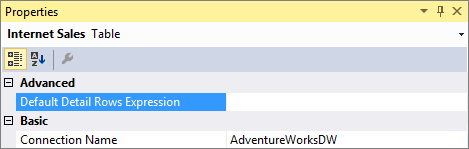
Propriété Expression de lignes de détails par défaut pour les tables
Outre les mesures, les tables possèdent également une propriété pour définir une expression de lignes de détails. La propriété Expression de lignes de détails par défaut agit comme valeur par défaut pour toutes les mesures de la table. Les mesures qui n’ont pas leur propre expression définie héritent de l’expression de la table et affichent le jeu de lignes défini pour la table. Cela permet la réutilisation des expressions, et les nouvelles mesures ajoutées à la table héritent automatiquement de l’expression.
Fonction DETAILROWS DAX
Cette version comprend une nouvelle fonction DAX DETAILROWS qui renvoie l’ensemble de lignes défini par l’expression de lignes de détails. Elle fonctionne de façon similaire à l’instruction DRILLTHROUGH dans MDX, qui est également compatible avec les expressions de lignes de détails définies dans les modèles tabulaires.
La requête DAX suivante retourne l’ensemble de lignes défini par l’expression de lignes de détails pour la mesure ou pour sa table. Si aucune expression n’est définie, les données pour la table des ventes sur Internet sont renvoyées, car c’est la table qui contient la mesure.
EVALUATE DETAILROWS([Internet Total Sales])
Sécurité au niveau des objets
Cette version introduit la sécurité au niveau de l’objet pour les tables et les colonnes. En plus de restreindre l’accès aux données de table et de colonne, les noms de tables et de colonnes sensibles peuvent être sécurisés. Cela permet d’empêcher qu’un utilisateur malveillant découvre l’existence de cette table.
La sécurité au niveau de l’objet doit être définie à l’aide des métadonnées json, du langage TMSL (Tabular Model Scripting Language) ou du modèle objet tabulaire (TOM).
Par exemple, le code suivant permet de sécuriser la table Produit dans l’exemple de modèle tabulaire Adventure Works en définissant la propriété MetadataPermission de la classe TablePermission sur Aucun.
//Find the Users role in Adventure Works and secure the Product table
ModelRole role = db.Model.Roles.Find("Users");
Table productTable = db.Model.Tables.Find("Product");
if (role != null && productTable != null)
{
TablePermission tablePermission;
if (role.TablePermissions.Contains(productTable.Name))
{
tablePermission = role.TablePermissions[productTable.Name];
}
else
{
tablePermission = new TablePermission();
role.TablePermissions.Add(tablePermission);
tablePermission.Table = productTable;
}
tablePermission.MetadataPermission = MetadataPermission.None;
}
db.Update(UpdateOptions.ExpandFull);
Vues de gestion dynamique
Les DMV sont des requêtes dans SQL Server Profiler qui retournent des informations sur les opérations du serveur local et l’intégrité du serveur. Cette version inclut des améliorations apportées aux vues de gestion dynamique (DMV) pour les modèles tabulaires aux niveaux de compatibilité 1200 et 1400.
DISCOVER_CALC_DEPENDENCY Fonctionne maintenant avec les modèles tabulaires 1200 et versions ultérieures. Les modèles tabulaires 1400 et versions ultérieures montrent les dépendances entre les partitions M, les expressions M et les sources de données structurées. Pour plus d’informations, consultez le blog Analysis Services.
MDSCHEMA_MEASUREGROUP_DIMENSIONS améliorations sont incluses pour cette DMV, qui est utilisée par différents outils clients pour afficher la dimensionnalité des mesures. Par exemple, la fonctionnalité Explorer dans les tableaux croisés dynamiques Excel permet à l’utilisateur d’effectuer une exploration croisée des dimensions liées aux mesures sélectionnées. Cette version corrige les colonnes de cardinalité, qui affichaient précédemment des valeurs incorrectes.
Améliorations DAX
L’un des éléments les plus importants de la nouvelle fonctionnalité DAX est la nouvelle fonction IN Operator/CONTAINSROW pour les expressions DAX. Elle est similaire à l’opérateur TSQL IN couramment utilisé pour spécifier plusieurs valeurs dans une clause WHERE .
Auparavant, il était courant de spécifier des filtres à valeurs multiples à l’aide de l’opérateur OR logique comme dans l’expression de mesure suivante :
Filtered Sales:=CALCULATE (
[Internet Total Sales],
'Product'[Color] = "Red"
|| 'Product'[Color] = "Blue"
|| 'Product'[Color] = "Black"
)
Ce processus est simplifié à l’aide de l’opérateur IN :
Filtered Sales:=CALCULATE (
[Internet Total Sales], 'Product'[Color] IN { "Red", "Blue", "Black" }
)
Dans ce cas, l’opérateur IN fait référence à une table d’une seule colonne avec 3 lignes ; une pour chacune des couleurs spécifiées. Notez que la syntaxe du constructeur de table utilise des accolades.
L’opérateur IN équivaut d’un point de vue fonctionnel à la fonction CONTAINSROW :
Filtered Sales:=CALCULATE (
[Internet Total Sales], CONTAINSROW({ "Red", "Blue", "Black" }, 'Product'[Color])
)
L’opérateur IN peut également être utilisé efficacement avec les constructeurs de table. Par exemple, la mesure suivante filtre par combinaison de couleur et de catégorie de produit :
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
( 'Product'[Color] = "Red" && Product[Product Category Name] = "Accessories" )
|| ( 'Product'[Color] = "Blue" && Product[Product Category Name] = "Bikes" )
|| ( 'Product'[Color] = "Black" && Product[Product Category Name] = "Clothing" )
)
)
Avec le nouvel opérateur IN , l’expression de mesure ci-dessus est maintenant équivalente à celle qui suit :
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
('Product'[Color], Product[Product Category Name]) IN
{ ( "Red", "Accessories" ), ( "Blue", "Bikes" ), ( "Black", "Clothing" ) }
)
)
Autres améliorations
En plus de toutes les nouvelles fonctionnalités, Analysis Services, SSDT et SSMS incluent également les améliorations suivantes :
- La réutilisation des hiérarchies et des colonnes a été exposée à des emplacements plus utiles dans la liste des champs Power BI.
- Relations de date pour créer facilement des relations avec des dimensions de date en fonction des champs de date.
- L’option d’installation par défaut pour Analysis Services est désormais en mode tabulaire.
- Nouvelles sources de données Get Data (Power Query).
- Éditeur DAX pour SSDT.
- Les sources de données DirectQuery existantes prennent en charge les requêtes M.
- Améliorations de SSMS, telles que l’affichage, la modification et la prise en charge des scripts pour les sources de données structurées.
Fonctionnalités dépréciées dans SSAS 2017
Les fonctionnalités suivantes sont déconseillées dans cette version :
| Mode/Catégorie | Fonctionnalité |
|---|---|
| Multidimensionnel | Exploration de données |
| Multidimensionnel | Groupes de mesures liés distants |
| Tabulaire | Modèles au niveau de compatibilité 1100 et 1103 |
| Tabulaire | Propriétés du modèle objet tabulaire - Column.TableDetailPosition, Column.IsDefaultLabel, Column.IsDefaultImage |
| Outils | Générateur de profils SQL Server pour la capture de trace La solution consiste à utiliser le Générateur de profils d’événements étendus, intégré dans SQL Server Management Studio. Consultez Surveiller Analysis Services avec des événements étendus SQL Server. |
| Outils | Server Profiler pour Trace Replay Remplacement. Il n’existe aucun remplacement. |
| Objets de gestion de trace et API de trace | Objets Microsoft.AnalysisServices.Trace (contenant les API des objets Analysis Services de trace et de relecture). La solution de remplacement est multiple : - Configuration de trace : Microsoft.SqlServer.Management.XEvent - Lecture de trace : Microsoft.SqlServer.XEvent.Linq - Relecture de trace : Aucune |
Fonctionnalités supprimées dans SSAS 2017
Les fonctionnalités suivantes sont supprimées dans cette version :
| Mode/Catégorie | Fonctionnalité |
|---|---|
| Tabulaire | Valeur de la propriété mémoire VertiPaqPagingPolicy (2), activez la pagination sur le disque à l’aide de fichiers mappés en mémoire. |
| Multidimensionnel | Partitions distantes |
| Multidimensionnel | Groupes de mesures liés distants |
| Multidimensionnel | Écriture différée dimensionnelle |
| Multidimensionnel | Dimensions liées |
Changements cassants dans SSAS 2017
Il n’y a aucune modification cassant dans cette version.
Changements de comportement dans SSAS 2017
Modifications apportées à MDSCHEMA_MEASUREGROUP_DIMENSIONS et DISCOVER_CALC_DEPENDENCY, détaillées dans l’annonce Nouveautés de SQL Server 2017 CTP 2.1 for Analysis Services.
SQL Server 2016 Analysis Services
SQL Server 2016 Analysis Services inclut de nombreuses nouvelles améliorations qui permettent d’améliorer les performances, de faciliter la création de solutions, de gérer automatiquement les bases de données, d’améliorer les relations avec le filtrage croisé bidirectionnel, le traitement de partition parallèle et bien plus encore. Au cœur de la plupart des améliorations apportées à cette version se trouve le nouveau niveau de compatibilité 1200 pour les bases de données model tabulaires.
SQL Server 2016 Service Pack 1 (SP1) Analysis Services
Télécharger SQL Server 2016 SP1
SQL Server 2016 SP1 Analysis Services offre une amélioration des performances et de la scalabilité grâce à la reconnaissance NUMA (Non-Uniform Memory Access) et à l’allocation de mémoire optimisée en fonction des blocs Intel TBB (Intel Threading Building Blocks). Cette nouvelle fonctionnalité permet de réduire le coût total de possession en prenant en charge davantage d’utilisateurs sur une quantité moindre de serveurs d’entreprise plus puissants.
En particulier, SQL Server 2016 SP1 Analysis Services offre des améliorations dans les domaines clés suivants :
- Reconnaissance NUMA : pour une meilleure prise en charge de NUMA, le moteur (VertiPaq) en mémoire dans Analysis Services gère maintenant une file d’attente de travail distincte sur chaque nœud NUMA. Cela garantit que les travaux d’analyse de segment s’exécutent sur le même nœud que celui où la mémoire est allouée pour les données du segment. Notez que la reconnaissance NUMA est activée par défaut uniquement sur les systèmes comptant au moins quatre nœuds NUMA. Sur les systèmes à deux nœuds, les coûts d’accès à la mémoire allouée à distance ne justifient généralement pas la surcharge liée à la gestion des spécificités NUMA.
- Allocation de mémoire : Analysis Services a été boosté avec Intel Threading Building Blocks, allocateur scalable qui fournit des pools de mémoire distincts pour chaque cœur. À mesure que le nombre de cœurs augmente, le système peut évoluer de manière quasi linéaire.
- Fragmentation des segments de mémoire : l’allocateur scalable basé sur Intel TBB permet également d’atténuer les problèmes de performances dus à la fragmentation des segments de mémoire ayant été observés avec les segments de mémoire Windows.
Des tests de performances et de scalabilité ont montré des gains de débit de requête significatifs lors de l’exécution de SQL Server 2016 SP1 Analysis Services sur de grands serveurs d’entreprise à plusieurs nœuds.
Alors que la plupart des améliorations apportées à cette version sont spécifiques aux modèles tabulaires, un certain nombre ont été apportées aux modèles multidimensionnels, par exemple, l’optimisation ROLAP du comptage de valeurs pour les sources de données telles que DB2 et Oracle, la prise en charge de plusieurs sélections pour l’extraction avec Excel 2016 et les optimisations de requête Excel.
SQL Server 2016 Disponibilité générale (GA) Analysis Services
Modélisation
Amélioration des performances de modélisation pour les modèles 1200 tabulaires
Pour les modèles tabulaires 1200, les opérations de métadonnées dans SSDT sont beaucoup plus rapides que les modèles tabulaires 1100 ou 1103. À titre de comparaison, sur le même matériel, la création d’une relation sur un modèle défini au niveau de compatibilité de SQL Server 2014 (1103) avec 23 tables prend trois secondes, alors que la même relation sur un modèle défini au niveau de compatibilité 1200 prend à peine une seconde.
Ajout de modèles de projet pour les modèles 1200 tabulaires dans SSDT
Avec cette version, vous n’avez plus besoin de deux versions de SSDT pour créer des projets BI et des projets relationnels. SQL Server Data Tools pour Visual Studio 2015 ajoute des modèles de projet pour les solutions Analysis Services, y compris les projets tabulaires Analysis Services utilisés pour créer des modèles au niveau de compatibilité 1200. D’autres modèles de projet Analysis Services pour les solutions multidimensionnelles et d’exploration de données sont également inclus, mais au même niveau fonctionnel (1100 ou 1103) que dans les versions précédentes.
Dossiers d’affichage
Les dossiers d’affichage sont désormais disponibles pour les modèles 1200 tabulaires. Définis dans SQL Server Data Tools et affichés dans les applications clientes comme Excel ou Power BI Desktop, les dossiers d’affichage vous permettent d’organiser facilement des mesures en grand nombre dans des dossiers individuels. De cette façon, les mesures sont présentées de façon hiérarchique, ce qui simplifie la navigation dans les listes de champs.
Filtrage croisé bidirectionnel
L’une des nouveautés de cette version est son approche intégrée d’activation des filtres croisés bidirectionnels dans les modèles tabulaires. Grâce à elle, plus besoin de concevoir manuellement des solutions de contournement DAX pour propager un contexte de filtre dans les relations de table. Les filtres sont créés automatiquement uniquement si la direction des filtres peut être établie avec un haut degré de certitude. S’il existe une ambiguïté en ce qui concerne le format de plusieurs chemins de requête sur les relations de table, les filtres ne sont pas créés automatiquement. Pour plus d’informations, consultez Filtres croisés bidirectionnels pour modèles tabulaires dans SQL Server 2016 Analysis Services .
Traductions
Vous pouvez désormais stocker des métadonnées traduites dans un modèle 1200 tabulaire. Les métadonnées du modèle incluent des champs pour la Culture, les légendes traduites et les descriptions traduites. Pour ajouter des traductions, utilisez la commande Model>Translations dans SQL Server Data Tools. Pour plus d’informations, consultez Traductions dans des modèles tabulaires (Analysis Services).
Tables collées
Si vous utilisez un modèle tabulaire 1100 ou 1103 qui contient des tables collées, vous pouvez désormais le mettre à niveau vers un modèle 1200. Nous vous recommandons d’utiliser SQL Server Data Tools. Dans SSDT, définissez CompatibilityLevel sur 1200, puis déployez sur une SQL Server 2017 instance de SQL Server Analysis Services. Pour plus d’informations, consultez Compatibility Level for Tabular models in Analysis Services .
Tables calculées dans SSDT
Une table calculée est une construction de modèle uniquement qui est basée sur une expression ou requête DAX dans SSDT. Quand une table calculée est déployée dans une base de données, elle ne se distingue pas des tables standard.
Les tables calculées ont plusieurs utilisations, notamment la création de tables pour exposer une table existante dans un rôle spécifique. L’exemple type est une table de dates qui s’utilise dans plusieurs contextes (date de commande, date d’expédition, etc.). En créant une table calculée pour un rôle donné, vous pouvez désormais établir une relation de table pour faciliter les requêtes ou les interactions de données avec cette table calculée. Une autre utilisation possible des tables calculées est de combiner certains éléments de tables existantes dans une toute nouvelle table qui existe uniquement dans le modèle. Pour en savoir plus, consultez Créer une table calculée .
Correction de formule
Avec la correction de formule sur un modèle tabulaire 1200, SSDT met automatiquement à jour toutes les mesures qui font référence à une colonne ou une table qui a été renommée.
Prise en charge du Gestionnaire de configuration Visual Studio
Pour garantir la prise en charge de plusieurs environnements, comme des environnements de test et de pré-production, Visual Studio permet aux développeurs de créer plusieurs configurations de projet à l’aide du Gestionnaire de configuration. Les modèles multidimensionnels offrent déjà cette possibilité, mais ce n’était pas le cas des modèles tabulaires. Avec cette version, vous pouvez utiliser le gestionnaire de configuration pour effectuer un déploiement sur différents serveurs.
Gestion d’instance
Administration de modèles 1200 tabulaires dans SSMS
Dans cette version, une instance d’Analysis Services en mode serveur tabulaire peut exécuter les modèles tabulaires à tous les niveaux de compatibilité (1100, 1103, 1200). La dernière version de SQL Server Management Studio a été mise à jour pour afficher les propriétés et permettre l’administration de modèles de base de données pour les modèles tabulaires au niveau de compatibilité 1200.
Traitement en parallèle de plusieurs partitions de tables dans les modèles tabulaires
Cette version inclut une nouvelle fonctionnalité de traitement en parallèle des tables avec plusieurs partitions, ce qui améliore les performances de traitement. Il n’y a pas de paramètres de configuration pour cette fonctionnalité. Pour plus d’informations sur la configuration des partitions et le traitement des tables, consultez Partitions de modèle tabulaire.
Ajout de comptes d’ordinateur en tant qu’administrateurs dans SSMS
SQL Server Analysis Services administrateurs peuvent désormais utiliser SQL Server Management Studio pour configurer des comptes d’ordinateur pour qu’ils soient membres du groupe administrateurs SQL Server Analysis Services. Dans la boîte de dialogue Sélectionner des utilisateurs ou des groupes , définissez l’option Emplacements pour le domaine des ordinateurs, puis ajoutez le type d’objet Ordinateurs . Pour plus d’informations, voir Accorder des droits d’administrateur de serveur à une instance de Analysis Services.
DBCC pour Analysis Services
DBCC (Database Consistency Checker) s’exécute en interne pour détecter la présence potentielle de données endommagées au chargement d’une base de données, mais il peut aussi être exécuté à la demande si vous soupçonnez des problèmes dans vos données ou un modèle. DBCC exécute des vérifications différentes selon que le modèle est tabulaire ou multidimensionnel. Pour plus d’informations, consultez Database Consistency Checker (DBCC) pour les bases de données tabulaires et multidimensionnelles Analysis Services .
Mises à jour des événements étendus
Cette version ajoute une interface utilisateur graphique à SQL Server Management Studio pour configurer et gérer SQL Server Analysis Services événements étendus. Vous pouvez configurer des flux de données actifs pour surveiller l’activité du serveur en temps réel, conserver les données de session chargées en mémoire pour une analyse plus rapide, ou enregistrer les flux de données dans un fichier pour une analyse hors connexion. Pour plus d’informations, consultez Surveiller Analysis Services avec des événements étendus SQL Server.
Scripts
PowerShell pour les modèles tabulaires
Cette version inclut des améliorations de PowerShell pour les modèles tabulaires au niveau de compatibilité 1200. Vous pouvez utiliser toutes les applets de commande applicables, ainsi que les applets de commande spécifiques du mode tabulaire : Invoke-ProcessASDatabase et Invoke-ProcessTable.
Création de scripts SSMS pour les opérations de base de données
Dans la dernière version de SQL Server Management Studio (SSMS), la création de scripts est désormais possible pour les commandes de base de données, notamment Create, Alter, Delete, Backup, Restore, Attach et Detach. La sortie est en langage TMSL (Tabular Model Scripting Language) au format JSON. Pour plus d’informations, consultez Référence TMSL (Tabular Model Scripting Language).
Tâche DDL d'exécution de SQL Server Analysis Services
Latâche DDL d’exécution Analysis Services prend aussi désormais en charge les commandes en langage TMSL (Tabular Model Scripting Language).
Applet de commande PowerShell de SSAS
L’applet de commande PowerShell Invoke-ASCmd de SSAS prend maintenant en charge les commandes en langage TMSL (Tabular Model Scripting Language). D’autres applets de commande PowerShell de SSAS pourraient être prises en charge dans une prochaine version pour pouvoir utiliser les nouvelles métadonnées tabulaires (les exceptions seront signalées dans les notes de publication). Pour plus d'informations, consultez Analysis Services PowerShell Reference .
Prise en charge du langage TMSL (Tabular Model Scripting Language) dans SSMS
Avec la version la plus récente de SSMS, vous pouvez maintenant créer des scripts pour automatiser la plupart des tâches d’administration pour les modèles 1200 tabulaires. Actuellement, vous pouvez créer des scripts pour les tâches suivantes : Process à tous les niveaux, ainsi que CREATE, ALTER et DELETE au niveau de la base de données.
TMSL fonctionne de manière équivalente à l’extension ASSL de XMLA qui fournit les définitions des objets multidimensionnels. La différence est que TMSL utilise des descripteurs natifs, tels que model, tableet relationship , pour décrire les métadonnées tabulaires. Pour plus d’informations sur le schéma, consultez Référence TMSL (Tabular Model Scripting Language).
Un script au format JSON créé pour un modèle tabulaire ressemble à ceci :
{
"create": {
"database": {
"name": "AdventureWorksTabular1200",
"id": "AdventureWorksTabular1200",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
}
}
La charge utile est un document JSON qui peut être aussi minimal que l’exemple ci-dessus, ou hautement embelli avec l’ensemble complet de définitions d’objets. La référence TMSL (Tabular Model Scripting Language) décrit la syntaxe.
Au niveau de la base de données, le script TMSL pour les commandes CREATE, ALTER et DELETE est généré dans la fenêtre XMLA classique. Dans cette version, d’autres commandes, telles que Process, peuvent également faire l’objet d’un script. La prise en charge des scripts pour de nombreuses autres actions pourrait être ajoutée dans une version ultérieure.
| Commandes autorisées dans un script | Description |
|---|---|
| create | Ajoute une base de données, connexion ou partition. L’équivalent ASSL est CREATE. |
| createOrReplace | Met à jour une définition d’objet existante (base de données, connexion ou partition) en remplaçant une version précédente. L’équivalent ASSL est ALTER avec AllowOverwrite défini sur true et ObjectDefinition défini sur ExpandFull. |
| supprimer | Supprime une définition d’objet. L’équivalent ASSL est DELETE. |
| actualiser | Traite l'objet. L’équivalent ASSL est PROCESS. |
DAX
Amélioration de la modification des formules DAX
Mises à jour à la barre de formule vous aide à écrire des formules plus facilement en différenciant les fonctions, les champs et les mesures à l’aide de la coloration syntaxique, il fournit des suggestions intelligentes de fonctions et de champs et vous indique si certaines parties de votre expression DAX sont incorrectes à l’aide de squiggles d’erreur. Vous pouvez également insérer plusieurs lignes (Alt+Entrée) et des retraits (Tab) dans vos formules. La barre de formule vous permet désormais d’écrire des commentaires dans le cadre de vos mesures, tapez simplement « / » et tout ce qui se trouve après ces caractères sur la même ligne sera considéré comme un commentaire.
Variables DAX
Cette version inclut désormais la prise en charge des variables DAX. Les variables peuvent maintenant stocker le résultat d’une expression comme une variable nommée, qui peut ensuite être passée en tant qu’argument à d’autres expressions de mesure. Une fois que les valeurs obtenues ont été calculées pour une expression de variable, ces valeurs ne changent pas, même si la variable est référencée dans une autre expression. Pour plus d’informations, consultez Fonction VAR.
Nouvelles fonctions DAX
Avec cette version, DAX introduit plus de cinquante nouvelles fonctions, qui accélèrent les calculs et améliorent les visualisations dans Power BI. Pour plus d’informations, consultez New DAX Functions(Nouvelles fonctions DAX).
Enregistrement des mesures incomplètes
Vous pouvez maintenant enregistrer les mesures DAX incomplètes directement dans un projet de modèle 1200 tabulaire et les terminer plus tard.
Autres améliorations DAX
- Calcul non vide : réduit le nombre d’analyses nécessaires pour les calculs non vides.
- Fusion de mesures : plusieurs mesures de la même table sont combinées dans une même requête du moteur de stockage.
- Regroupement des jeux : quand une requête demande des mesures impliquant plusieurs granularités (total/année/mois), une seule requête est envoyée au niveau le plus bas et le reste des granularités sont dérivées de ce niveau.
- Élimination des jointures redondantes : une seule requête vers le moteur de stockage retourne les colonnes de dimension et les valeurs de mesure.
- Évaluation stricte de IF/SWITCH : une branche dont la condition a la valeur false ne provoque plus de requêtes du moteur de stockage. Auparavant, les branches étaient évaluées de manière hâtive, mais les résultats étaient ignorés plus tard.
Développeur
Espace de noms Microsoft.AnalysisServices.Tabular pour la programmabilité d’objets tabulaires 1200 dans AMO
Les objets Analysis Services Management (AMO) ont été mis à jour. Ils incluent un nouvel espace de noms tabulaire pour gérer une instance en mode tabulaire de SQL Server 2016 Analysis Services, et fournissent le langage de définition de données (DLL) nécessaire pour créer ou modifier des modèles 1200 tabulaires par programmation. Pour plus d’informations sur l’API, consultez Microsoft.AnalysisServices.Tabular .
Mises à jour d’Analysis Services Management Objects (AMO)
AMO (Analysis Services Management Objects) a été refactorisé pour inclure un deuxième assembly, Microsoft.AnalysisServices.Core.dll. Le nouvel assembly sépare les classes communes (telles que Server, Database et Role) qui ont un champ d’application étendu dans Analysis Services, quel que soit le mode du serveur utilisé. Auparavant, ces classes faisaient partie de l'assembly Microsoft.AnalysisServices d’origine. En les déplaçant vers un nouvel assembly, cela rend possible de futures extensions vers AMO, grâce à une séparation claire entre les API génériques et les API contextuelles. Les applications existantes ne sont pas affectées par les nouveaux assemblys. Toutefois, si vous décidez de régénérer les applications avec le nouvel assembly AMO, assurez-vous d’ajouter une référence à Microsoft.AnalysisServices.Core. De la même façon, les scripts PowerShell qui chargent et appellent AMO doivent charger Microsoft.AnalysisServices.Core.dll. Veillez à mettre à jour tous les scripts.
Éditeur JSON pour les fichiers BIM
Le mode Code dans Visual Studio 2015 affiche maintenant le fichier BIM au format JSON pour les modèles 1200 tabulaires. La version de Visual Studio détermine si les fichiers BIM sont rendus au format JSON via l’éditeur JSON intégré ou sous forme de texte simple.
Pour utiliser l’éditeur JSON avec la possibilité de développer et réduire des sections du modèle, vous avez besoin de la dernière version de SQL Server Data Tools et de Visual Studio 2015 (n’importe quelle édition, y compris l’édition Community gratuite). Dans toutes les autres versions de SSDT ou de Visual Studio, les fichiers BIM sont rendus au format JSON sous forme de texte simple. Au minimum, un modèle vide contient le code JSON suivant :
{
"name": "SemanticModel",
"id": "SemanticModel",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
Avertissement
Évitez de modifier le fichier JSON directement, car cela peut endommager le modèle.
Nouveaux éléments dans le schéma MS-CSDLBI 2.0
Les éléments suivants ont été ajoutés au type complexe TProperty défini dans le schéma [MS-CSDLBI] 2.0 :
| Élément | Définition |
|---|---|
| DefaultValue | Propriété qui spécifie la valeur utilisée pour évaluer la requête. La propriété DefaultValue est facultative, mais elle est automatiquement sélectionnée si les valeurs du membre ne peuvent pas être agrégées. |
| Statistiques | Ensemble de statistiques effectuées sur les données sous-jacentes qui sont associées à la colonne. Ces statistiques, définies par le type complexe TPropertyStatistics, sont fournies uniquement si cela ne nécessite pas une grande quantité de ressources de calcul, comme cela est expliqué dans la section 2.1.13.5 sur le format CSDL (Conceptual Schema Definition Language) dans le document Business Intelligence Annotations. |
DirectQuery
Nouvelle implémentation de DirectQuery
Cette version comporte des améliorations significatives dans DirectQuery pour les modèles 1200 tabulaires. Voici un résumé :
- DirectQuery crée désormais des requêtes plus simples qui offrent de meilleures performances.
- Contrôle supplémentaire sur la définition des exemples de jeux de données utilisés pour la conception et le test de modèles.
- La sécurité au niveau des lignes (RLS) est maintenant prise en charge pour les modèles 1200 tabulaires en mode DirectQuery. Avant, l’activation de la sécurité au niveau des lignes empêchait le déploiement d’un modèle tabulaire en mode DirectQuery.
- Les colonnes calculées sont maintenant prises en charge pour les modèles 1200 tabulaires en mode DirectQuery. Avant, l’activation des colonnes calculées empêchait le déploiement d’un modèle tabulaire en mode DirectQuery.
- L’optimisation des performances inclut l’élimination des jointures redondantes pour VertiPaq et DirectQuery.
Nouvelles sources de données pour le mode DirectQuery
Les sources de données prises en charge pour les modèles tabulaires 1200 en mode DirectQuery incluent désormais Oracle, Teradata et Microsoft Analytics Platform (anciennement parallel Data Warehouse). Pour plus d’informations, consultez Mode DirectQuery.
Fonctionnalités dépréciées dans SSAS 2016
Les fonctionnalités suivantes sont déconseillées dans cette version :
| Mode/Catégorie | Fonctionnalité |
|---|---|
| Multidimensionnel | Partitions distantes |
| Multidimensionnel | Groupes de mesures liés distants |
| Multidimensionnel | Écriture différée dimensionnelle |
| Multidimensionnel | Dimensions liées |
| Multidimensionnel | Notifications de table SQL Server pour la mise en cache proactive. La solution de remplacement consiste à utiliser l’interrogation pour la mise en cache proactive. Consultez Mise en cache proactive (dimensions) et Mise en cache proactive (partitions). |
| Multidimensionnel | Cubes de session. Il n’existe aucun remplacement. |
| Multidimensionnel | Cubes locaux. Il n’existe aucun remplacement. |
| Tabulaire | Les niveaux de compatibilité 1100 et 1103 des modèles tabulaires ne seront pas pris en charge dans une future version. Le remplacement consiste à définir des modèles au niveau de compatibilité 1200 ou supérieur, en convertissant les définitions de modèle en métadonnées tabulaires. Consultez Compatibility Level for Tabular models in Analysis Services. |
| Outils | Générateur de profils SQL Server pour la capture de trace La solution consiste à utiliser le Générateur de profils d’événements étendus, intégré dans SQL Server Management Studio. Consultez Surveiller Analysis Services avec des événements étendus SQL Server. |
| Outils | Server Profiler pour Trace Replay Remplacement. Il n’existe aucun remplacement. |
| Objets de gestion de trace et API de trace | Objets Microsoft.AnalysisServices.Trace (contenant les API des objets Analysis Services de trace et de relecture). La solution de remplacement est multiple : - Configuration de trace : Microsoft.SqlServer.Management.XEvent - Lecture de trace : Microsoft.SqlServer.XEvent.Linq - Relecture de trace : Aucune |
Fonctionnalités supprimées dans SSAS 2016
Les fonctionnalités suivantes sont supprimées dans cette version :
| Fonctionnalité | Remplacement ou contournement |
|---|---|
| CalculationPassValue (MDX) | Aucun. L’utilisation de cette fonctionnalité a été déconseillée dans SQL Server 2005. |
| CalculationCurrentPass (MDX) | Aucun. L’utilisation de cette fonctionnalité a été déconseillée dans SQL Server 2005. |
| Indicateur d’optimiseur de requête NON_EMPTY_BEHAVIOR | Aucun. L’utilisation de cette fonctionnalité a été déconseillée dans SQL Server 2008. |
| Assemblys COM | Aucun. L’utilisation de cette fonctionnalité a été déconseillée dans SQL Server 2008. |
| Propriété intrinsèque de cellule CELL_EVALUATION_LIST | Aucun. L’utilisation de cette fonctionnalité a été déconseillée dans SQL Server 2005. |
Changements cassants dans SSAS 2016
Mise à niveau du .NET 4.0
Les bibliothèques clientes Analysis Services Management Objects (AMO), ADOMD.NET et TOM (Tabular Object Model) ciblent désormais le runtime .NET 4.0. Il peut s’agir d’une modification majeure pour les applications qui ciblent le .NET 3.5. Les applications utilisant des versions plus récentes de ces assemblys doivent maintenant cibler .NET 4.0 ou ultérieur.
Mise à niveau de la version AMO
Cette version est une mise à niveau de version pour Analysis Services Management Objects (AMO) et constitue un changement cassant dans certaines circonstances. Le code et les scripts qui appellent AMO continueront de s’exécuter comme avant, si vous mettez à niveau une version précédente. Toutefois, si vous devez recompiler votre application et que vous ciblez un SQL Server 2016 Analysis Services instance, vous devez ajouter l’espace de noms suivant pour rendre votre code ou script opérationnel :
using Microsoft.AnalysisServices;
using Microsoft.AnalysisServices.Core;
L’espace de noms Microsoft.AnalysisServices.Core est maintenant nécessaire chaque fois que vous faites référence à l’assembly Microsoft.AnalysisServices dans votre code. Les objets qui auparavant ne figuraient que dans l’espace de noms Microsoft.AnalysisServices sont déplacés dans l’espace de noms principal dans cette version, si l’objet est utilisé de la même façon dans des scénarios multidimensionnels et tabulaires. Par exemple, les API liées au serveur sont déplacées dans l’espace de noms principal.
Bien qu’il y ait plusieurs espaces de noms, deux coexistent dans le même assembly (Microsoft.AnalysisServices.dll).
Modifications de DISCOVER XEvent
Pour mieux prendre en charge le streaming XEvent DISCOVER dans SSMS pour SQL Server 2016 Analysis Services, DISCOVER_XEVENT_TRACE_DEFINITION est remplacé par les traces XEvent suivantes :
DISCOVER_XEVENT_PACKAGES
DISCOVER_XEVENT_OBJECT
DISCOVER_XEVENT_OBJECT_COLUMNS
DISCOVER_XEVENT_SESSION_TARGETS
Changements de comportement dans SSAS 2016
Analysis Services en mode SharePoint
L’exécution de l’Assistant de configuration de PowerPivot en tant que tâche de post-installation n’est plus nécessaire. Cela est vrai pour toutes les versions prises en charge de SharePoint qui chargent des modèles à partir du SQL Server 2016 Analysis Services actuel.
Mode DirectQuery dans les modèles tabulaires
DirectQuery est un mode d’accès aux données des modèles tabulaires, où la requête s’exécute sur une base de données relationnelle principale, extrayant le jeu de résultats en temps réel. Il est souvent utilisé pour les jeux de données trop volumineux pour la mémoire ou lorsque les données sont volatiles et que vous souhaitez recevoir les données les plus récentes suite aux requêtes exécutées sur un modèle tabulaire.
Dans plusieurs versions précédentes, DirectQuery existait sous la forme d’un mode d’accès aux données. Dans SQL Server 2016 Analysis Services, l’implémentation a été légèrement révisée, en supposant que le modèle tabulaire est au niveau de compatibilité 1200 ou supérieur. DirectQuery a moins de restrictions qu’auparavant. Il propose également d’autres propriétés de base de données.
Si vous utilisez DirectQuery dans un modèle tabulaire existant, vous pouvez conserver ce dernier à son niveau de compatibilité actuel (1100 ou 1103) et continuer de l’utiliser tel qu’il est mis en œuvre à ces niveaux. Vous pouvez également effectuer une mise à niveau vers la version 1200 ou ultérieure pour bénéficier des améliorations apportées à DirectQuery.
Il n’existe aucune mise à niveau sur place d’un modèle DirectQuery, car les paramètres des anciens niveaux de compatibilité n’ont pas d’équivalents exacts dans les niveaux de compatibilité 1200 et plus récents. Si vous avez un modèle tabulaire existant qui s’exécute en mode DirectQuery, vous devez ouvrir le modèle dans SQL Server Data Tools, désactiver DirectQuery, définir la propriété Niveau de compatibilité sur 1200 ou une version ultérieure, puis reconfigurer les propriétés DirectQuery. Pour plus d’informations, consultez Mode DirectQuery .
Définitions
Une fonctionnalité dépréciée sera supprimée du produit dans une version ultérieure, mais elle est toujours prise en charge et incluse dans la version actuelle pour maintenir la compatibilité descendante. Il est recommandé de cesser d’utiliser les fonctionnalités déconseillées dans les projets nouveaux et existants pour maintenir la compatibilité avec les versions futures. La documentation n’est pas mise à jour pour les fonctionnalités déconseillées.
Une fonctionnalité abandonnée a été déconseillée dans une version antérieure. Il peut continuer à être inclus dans la version actuelle, mais n’est plus pris en charge. Les fonctionnalités supprimées peuvent être entièrement supprimées dans la version indiquée ou future.
Une modification cassant entraîne la fin du fonctionnement d’une fonctionnalité, d’un modèle de données, d’un code d’application ou d’un script après la mise à niveau vers la version actuelle.
Un changement de comportement affecte le fonctionnement de la même fonctionnalité dans la version actuelle par rapport à la version précédente. Seules les modifications de comportement significatives sont décrites. Les modifications apportées à l’interface utilisateur ne sont pas incluses. Les modifications apportées aux valeurs par défaut, la configuration manuelle requise pour terminer une fonctionnalité de mise à niveau ou de restauration, ou une nouvelle implémentation d’une fonctionnalité existante sont tous des exemples de changement de comportement.