Demystifying Activity Scheduling with Azure Data Factory
By Nicholas Revell – Data Platform Solution Architect.
If, like me, you are familiar with scheduling SQL Server Integration Services (SSIS) packages with SQL Server Agent, then you will know that setting up a recurring schedule is a relatively straightforward process.
Things are not so simple with Azure Data Factory. I struggled the first time I had to schedule activities in Azure Data Factory, partly because scheduling is configured in more than one place, but also because I was approaching it with the wrong mindset. If you are in the same situation, then hopefully this blog post will help you.
Before discussing scheduling, let's set some context…
Azure Data Factory
Azure Data Factory is Microsoft's cloud-based data integration service to orchestrate and automate the movement and transformation of data, whether that data resides on-premises or in the cloud. As with all the managed Azure data and analytics services, Azure Data Factory offers the benefits of on-demand provisioning, scalability, and ease of administration.
Pipelines and Activities
At its highest level, an Azure Data Factory is simply a container for a set of data processing pipelines each of which contains one or more activities.
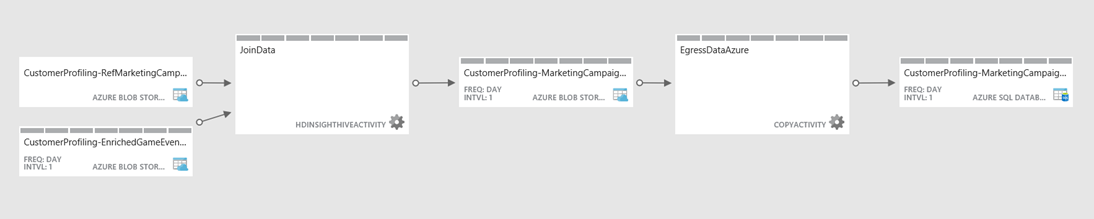
These activities can each take zero or more input datasets and one or more output datasets. All the activities in a single pipeline collectively perform a data processing task and the order and sequencing of activities is implicitly defined when activities are chained by defining the output of one activity as being the input for another activity. This is displayed in the following diagram of a single pipeline.
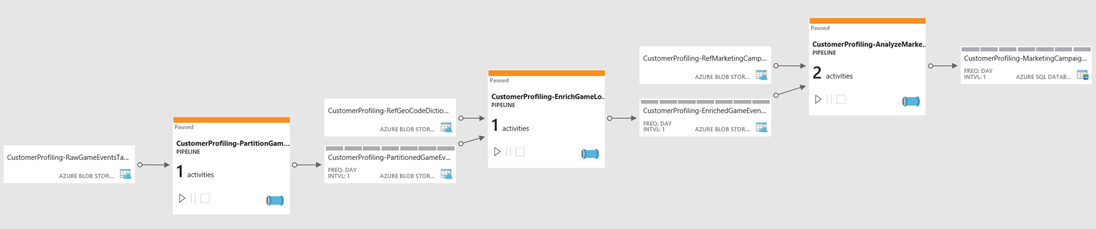
Similarly, pipelines themselves can be sequenced and ordered by defining the output of one pipeline as the input for another, providing the capability to build complex data processing operations from a sequence of data processing tasks. This is displayed in the following diagram of chained pipelines.
Once the order of execution for pipelines and activities has been defined, the next stage is to schedule the execution of those activities.
Activity Scheduling Concepts
The starting point to understanding how to schedule activities in Azure Data Factory is to understand the concepts behind the following configuration settings: 'active pipeline periods, 'activity schedules', 'activity windows', 'data slices', and 'dataset availability'. You will then need to understand what happens when different components have different schedules. Once you understand these concepts and interrelationships then configuring and troubleshooting activity schedules should be much more straightforward.
Active Pipeline Periods
Starting with the simplest concept: pipelines have start and end dates within which they are active. If you don't define a start and end time for a pipeline then it is not active, which might still be useful while you are developing the pipeline. Once you decide to make it active then you need to give it both a start and end date. If you want it be active indefinitely then set the end date year to 9999.
Example: The following JSON script fragment will create a pipeline that will be active from 17th to 26th April 2016. The active period is defined with the start and end properties that take a date and optional time in ISO format.
| {"name": "DemoPipeline","properties": {"description": "Demo pipeline with single copy activity to demonstrate activity scheduling","activities": […], "start": "2016-04-17T00:00:00Z", "end": "2016-04-26T00:00:00Z", "pipelineMode": "Scheduled" }} |
The pipelineMode property must be set to "Scheduled" to set up a recurring schedule. The alternative value for this property is "OneTime" which will execute the pipeline once. It is not necessary to set a start and end date for a one-time pipeline but it will just default the start time to the deployment time and the end time to 24 hours later.
A pipeline is always active between the start and end dates unless it is paused. However, being active does not mean the pipeline is constantly running because it is the activities within a pipeline that are executed on a scheduled basis and incur the costs. Azure Data Factory pricing is based on monthly charges for activities based on their frequency and data movement. There is a nominal monthly charge for an inactive pipeline but it is currently less than $1.
Pipelines can be paused or suspended with the option of terminating any running activities or letting them complete. Once a paused pipeline is resumed then any pending activities that were scheduled to execute during the paused period will still be executed assuming the pipeline is still active.
Activity Schedules
Every activity, whether it performs a data movement or transformation task, has its own schedule that determines how frequently the activity runs. This is configured as a frequency (which can be Minute, Hour, Day, Week, Month) and an interval, which is a multiplier for the frequency. If the frequency is set to 'Minute' then it is recommended that the interval is not less than 15.
Example: The following JSON script fragment will add a Copy Activity to our pipeline that will run once a day during the active period and copy the day's order details from a SQL database to Blob storage. The activity schedule is defined with the frequency and interval properties in the scheduler section.
| "activities": [{"name": "DemoCopyActivity""type": "Copy","typeProperties": {"source": {"type": "SqlSource","sqlReaderQuery": "select …"},"sink": {"type": "BlobSink",…}},"inputs": [{"name": "DemoSQLDataset"}],"outputs": [{"name": "DemoBlobDataset"}], "scheduler": { "frequency": "Day", "interval": 1},}], |
By default, an activity will be scheduled to execute at the end of each scheduled period, i.e. last day of month or last hour of day. If the intention is for the activity to be executed at the start of the scheduled interval, then there is an optional scheduler property called style that can take the values StartOfInterval or EndOfInterval.
If you do choose to set an activity execution or dataset availability to start of interval, then you should set this property for all other activities and datasets in the pipeline to have the desired effect. The reason is that activities and output datasets cannot take different style property values, and activities cannot start until input datasets are available.
If a pipeline has been configured to run once only and you want it to run immediately then you will need to explicitly configure its activities and datasets for start of interval.
Activity Windows
The effect of setting a recurring schedule for an activity is to define a set of tumbling activity windows, which are fixed-sized, non-overlapping and contiguous time intervals. Each activity window represents one occasion when the activity will run.
In our example, there will be one activity window for each day running from midnight to midnight because the frequency has been set to 'day' and the interval set to 1.
Once you have defined a pipeline's active period and a recurring schedule for each of its activities then Azure Data Factory can determine how many activity windows this represents and schedule them accordingly. When the time for a scheduled activity window arrives, Azure Data Factory will attempt to execute the activity.
Activity Scheduling and Execution
Let's take stock of the concepts we have covered before moving on:
- Every pipeline has a start and end date which is its active period. No activities are executed outside of this period.
- Every activity has its own recurring schedule that determines how frequently the activity is executed within the pipeline's active period.
- An activity's schedule creates a sequence of discrete time windows.
Data Slices
The next key concept in activity scheduling is data slices, and this is the underlying reason why every activity has its own schedule rather than creating a single schedule for a pipeline, as you would do for a SSIS package.
An activity window not only represents a time interval; it also represents a discrete period of time for time series data (i.e. any data which has some date or time attribute). For example, this could be telemetry data from sensors or transaction data from applications.
By chunking up time into discrete periods, as defined by activity windows, Azure Data Factory knows what set of time series data to process during each activity run. The data that is processed and produced by an activity window is known as a data slice.
It might be assumed that activities will be executed strictly in chronological order of activity windows. Under normal circumstances this will be the case but whenever a pipeline is paused and resumed then the backlog of activity runs will be executed in parallel if the concurrency property of the policy section of the activity has been set to a value greater than 1. Processing data in parallel should not be a problem if each data slice processes a different set of data.
Dataset Slice Status
When the scheduled time for an activity window to be executed arrives, the status of the activity can be monitored in the Azure Portal or using the Azure Data Factory's Monitoring and Management App.
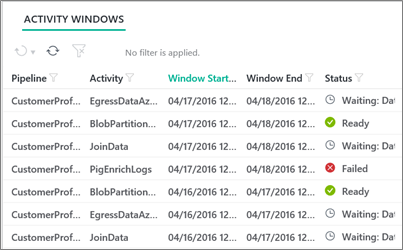
In practice, it is the status of the data slice produced by the activity that is being reported rather than the activity itself. Every data slice starts in a Waiting state until the conditions listed above are met. The state then changes to In Progress while the input and output datasets are validated and the data slice is processed. If the data slice is successfully processed then state of the data slice changes to Ready, which means it is available to be consumed as an input dataset by another activity. If the activity fails, then the state changes to Failed, after which it can be manually rerun if required.
Dataset Availability
To summarise the position so far, there are 4 conditions that need to be met before an activity can be executed:
- The pipeline is active. This means that the current date and time are within the pipeline's start and end period.
- The activity window's scheduled data and time has arrived (or passed if the pipeline was paused and resumed).
- There are sufficient resources to run the activity. This might not be the case if the Azure Data Factory instance is already running a number of concurrent activities.
- All input datasets are ready. This means that any input datasets processed by preceding (or upstream) activities have completed successfully and are in the Ready state.
If the only input datasets that an activity needs are external, which means that they were not generated as output from a preceding activity, then the conditions listed above are sufficient for the activity to be executed.
However, if an activity takes the output from another activity as one of its input datasets then those datasets will have been processed as time-specific data slices according to the previous activity's schedule. This is apparent from the following diagram, which shows that output datasets have details of activity windows representing data slices, whereas external datasets do not.
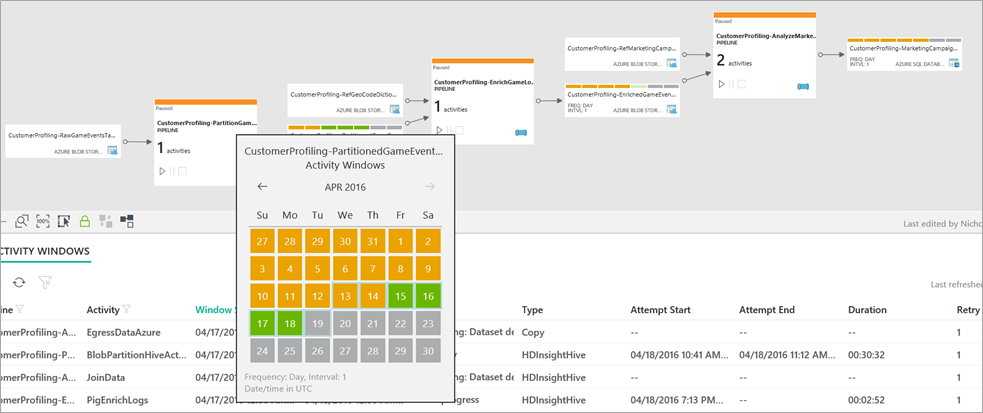
Even if an activity satisfies all the conditions listed above, it will still need to wait until all the required data slices from its input datasets are ready. This is where the concept of dataset availability comes into play.
Every dataset definition has a required availability section that includes the same properties as an activity's scheduler section, which are frequency, interval and style. There are a couple of other optional properties, anchorDateTime and offset, which are available to provide more precise times for dataset slice boundaries.
Example: The following JSON script fragment will create a dataset that will be available every 12 hours.
| {"name": "DemoSQLDataset","properties": {"published": false,"type": "AzureSqlTable","linkedServiceName": "DemoSQLLinkedService","typeProperties": {"tableName": "SalesLT.SalesOrderHeader"}, "availability": { "frequency": "Hour", "interval": 12},"external": true,"policy": {}}} |
We have now defined an execution schedule for each activity and a processing window for each dataset as a recurring period with a frequency and interval.
Output Dataset Availability
Whenever a dataset is configured as the output for an activity then the activity schedule must match the dataset's availability. In other words, whenever an activity executes it creates a data slice so the activity window must match the data slice's time period.
Azure Data Factory will not let you deploy a pipeline if an activity's scheduler does not match its output dataset's availability.
Input Dataset Availability
Unlike output datasets, the availability of an input dataset does not need to match the activity window of the activity that consumes it. The availability of an input dataset may be more or less frequent than the activity window of the activity that consumes it. Even if chained activities have the same frequency, their start times may be different. Regardless of these differences, Azure Data Factory checks the availability of each input dataset for each activity window and waits until all the required input data slices have been processed and are ready before it executes the activity.
If you have activities and datasets with different frequencies, then some activities will inevitably end up waiting for upstream dependent data slices. Details of these dependencies are part of the monitoring information available from the Azure portal or the Monitor & Manage app.
Physically slicing the data
Everything that has been discussed so far simply provides a schedule for time-series data to be sliced or processed in batches covering discrete time periods. However, none of this will actually ensure that each activity window or data slice will only contain data that is relevant to the defined period.
For many integration scenarios, Azure Data Factory pipelines will not be processing time series data. If your requirement is simply to periodically load a set of data to refresh or replace an existing data store, then you would still need to configure activity windows and matching dataset availability periods, but the data slices would not need to contain time-bound data.
On the other hand, if you are using Azure Data Factory to slice data into defined time periods, then you typically need to perform two additional steps: filter the input data and segregate the output data.
Filter the input data
In order to ensure that data, selected for a copy activity or processed by a transformation activity, is confined to the time period defined by an activity window, the activity needs to apply a filter. There are two variables that can be included in the JSON script for an activity for this purpose. These are WindowStart and WindowEnd which hold the start and end dates and times of the activity window.
Example: The following JSON script fragment configures a copy activity to filter the data that is selected to match the activity's window.
| "activities": [{"name": "DemoCopyActivity","type": "Copy","typeProperties": {"source": {"type": "SqlSource", "sqlReaderQuery": "$$Text.Format('select * FROM [SalesLT].[SalesOrderHeader]where OrderDate >= \\'{0:yyyy-MM-dd}\\'and OrderDate < \\'{1:yyyy-MM-dd}\\'', WindowStart, WindowEnd)" },"sink": {"type": "BlobSink",…}},"inputs": [{"name": "DemoSQLDataset"}],"outputs": [{"name": "DemoBlobDataset"}],"scheduler": {"frequency": "Day","interval": 1}}] |
Segregate the output data
In addition to the variables that hold the start and end of an activity window, there are also two variables that hold the start and end times for a data slice. These are SliceStart and SliceEnd and can be used in JSON scripts to dynamically specify a location when persisting output data.
Example: The following JSON script fragment configures a dataset to partition the data and store it in Blob storage with a folder path for each year, month, and day.
| {"name": "DemoBlobDataset","properties": {"published": false,"type": "AzureBlob","linkedServiceName": "DemoBlobLinkedService","typeProperties": { "folderPath": "adfdemo/orders/{Year}/{Month}/{Day}", "format": {"type": "TextFormat","rowDelimiter": "\n","columnDelimiter": ","}, "partitionedBy": [ { "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } }, { "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } }, { "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } } ] },"availability": {"frequency": "Day","interval": 1}}} |
Wrap up
This concludes our walkthrough of the core concepts that underpin activity scheduling and data slice processing in Azure Data Factory. To explore this subject in more detail, there is a useful learning path which provides links to the online documentation for Azure Data Factory at https://azure.microsoft.com/en-gb/documentation/learning-paths/data-factory/.
Comments
- Anonymous
September 27, 2016
Very informative and helpful.