Effectuez l’apprentissage d’un modèle vocal personnalisé
Dans cet article, vous apprenez à effectuer l’apprentissage d’un modèle personnalisé pour améliorer l’exactitude de la reconnaissance à partir du modèle de base Microsoft. L’exactitude et la qualité de la reconnaissance vocale d’un modèle vocal personnalisé restent cohérentes, même lorsqu’un nouveau modèle de base est publié.
Remarque
Vous payez pour l’utilisation du modèle vocal personnalisé et l’hébergement des points de terminaison. Vous serez également facturé pour la formation du modèle vocal personnalisé si le modèle de base a été créé le 1er octobre 2023 ou à une date ultérieure. La formation ne vous est pas facturée si le modèle de base a été créé avant octobre 2023. Pour plus d’informations, consultez Tarification d’Azure AI Speech et la section Frais d’adaptation dans le guide de migration de la reconnaissance vocale 3.2.
L’apprentissage d’un modèle est généralement un processus itératif. Vous devez sélectionner un modèle de base qui est le point de départ d’un nouveau modèle. Vous formez un modèle avec des jeux de données qui peuvent inclure du texte et de l’audio, puis vous le testez. Si la qualité ou l’exactitude de la reconnaissance ne répond pas à vos besoins, vous pouvez créer un nouveau modèle avec des données de formation plus nombreuses ou modifiées, puis effectuer un nouveau test.
Vous pouvez utiliser un modèle personnalisé pendant une durée limitée après sa formation. Vous devez périodiquement recréer et adapter votre modèle personnalisé à partir du dernier modèle de base pour profiter de l’amélioration de la précision et de la qualité. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
Important
Si vous prévoyez d’entraîner un modèle personnalisé avec des données audio, choisissez une région de ressource Speech dotée de matériel dédié à l’entraînement de données audio. Une fois qu’un modèle est entraîné, vous pouvez le copier dans une ressource Speech dans une autre région si nécessaire.
Dans les régions dotées de matériel dédié à la formation de la reconnaissance vocale personnalisée, le service Speech utilisera jusqu’à 100 heures de vos données de formation audio et pourra traiter environ 10 heures de données par jour. Pour plus d’informations, consultez les notes de bas de page du tableau des régions.
Créer un modèle
Après avoir chargé les jeux de données de formation, suivez les instructions suivantes pour commencer la formation de votre modèle :
Connectez-vous à Speech Studio.
Sélectionnez Reconnaissance vocale personnalisée> Votre nom de projet >Effectuer l’apprentissage des modèles personnalisés.
Sélectionnez Entraîner un nouveau modèle.
Dans la page Sélectionner un modèle de référence, sélectionnez un modèle de référence, puis Suivant. Si vous avez des doutes, sélectionnez le modèle le plus récent en haut de la liste. Le nom du modèle de base correspond à la date de sa publication au format AAAAMMJJ. Les fonctionnalités de personnalisation du modèle de base sont répertoriées entre parenthèses après le nom du modèle dans Speech Studio.
Important
Notez la date Expiration de l’adaptation. Il s’agit de la dernière date à laquelle vous pouvez utiliser le modèle de base pour la formation. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
Sur la page Choisir les données, sélectionnez un ou plusieurs jeux de données que vous souhaitez utiliser pour la formation. Si aucun jeu de données n’est disponible, annulez la configuration, puis accédez au menu Jeux de données Speech pour charger des jeux de données.
Entrez un nom et une description pour votre modèle personnalisé, puis sélectionnez Suivant.
Si vous le souhaitez, cochez la case Ajouter un test à l’étape suivante. Si vous ignorez cette étape, vous pouvez exécuter les mêmes tests ultérieurement. Pour plus d’informations, consultez Tester la qualité de la reconnaissance et Tester le modèle quantitativement.
Sélectionnez Enregistrer et fermer pour lancer la build de votre modèle personnalisé.
Revenez à la page Former des modèles personnalisés.
Important
Prenez note de la date d’Expiration. Il s’agit de la dernière date à laquelle vous pouvez utiliser votre modèle personnalisé pour la reconnaissance vocale. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
Pour créer un modèle avec des jeux de données pour la formation, utilisez la commande spx csr model create. Construisez les paramètres de la requête conformément aux instructions suivantes :
- Définissez le paramètre
projectsur l’ID d’un projet existant. Il est recommandé d’utiliser ce paramètre afin de pouvoir afficher et gérer le modèle dans Speech Studio. Vous pouvez exécuter la commandespx csr project listpour obtenir les projets disponibles. - Définissez le paramètre requis
datasetsur l’ID d’un jeu de données que vous souhaitez utiliser pour la formation. Pour spécifier plusieurs jeux de données, définissez le paramètredatasets(pluriel) et séparez les ID avec un point-virgule. - Définissez le paramètre requis
language. Les paramètres régionaux du jeu de données doivent correspondre aux paramètres régionaux du projet. Vous ne pourrez plus changer de paramètres régionaux. Le paramètrelanguageCLI Speech correspond à la propriétélocaledans la requête et la réponse JSON. - Définissez le paramètre requis
name. Ce paramètre est le nom qui est affiché dans Speech Studio. Le paramètrenameCLI Speech correspond à la propriétédisplayNamedans la requête et la réponse JSON. - Si vous le souhaitez, vous pouvez définir la propriété
base. Par exemple :--base 5988d691-0893-472c-851e-8e36a0fe7aaf. Si vous ne spécifiez pas debase, le modèle de base par défaut pour les paramètres régionaux est utilisé. Le paramètrebaseCLI Speech correspond à la propriétébaseModeldans la requête et réponse JSON.
Voici un exemple de commande CLI Speech qui crée un modèle avec des jeux de données pour la formation :
spx csr model create --api-version v3.2 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Notes
Dans cet exemple, le paramètre base n’est pas défini. Par conséquent, le modèle de base par défaut pour les paramètres régionaux est utilisé. L’URI du modèle de base est retourné dans la réponse.
Vous devriez recevoir un corps de réponse au format suivant :
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Important
Prenez note de la date dans la propriété adaptationDateTime. Il s’agit de la dernière date à laquelle vous pouvez utiliser le modèle de base pour la formation. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
Prenez note de la date dans la propriété transcriptionDateTime. Il s’agit de la dernière date à laquelle vous pouvez utiliser votre modèle personnalisé pour la reconnaissance vocale. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
La propriété self de niveau supérieur dans le corps de la réponse est l’URI du modèle. Utilisez cet URI pour obtenir des détails sur les dates de projet, de manifeste et de dépréciation du modèle. Vous utilisez également cet URI pour mettre à jour ou supprimer un modèle.
Pour l’aide de l’interface CLI Speech avec les modèles, exécutez la commande suivante :
spx help csr model
Pour créer un modèle avec des jeux de données pour l’entraînement, utilisez l’opération Models_Create de l’API REST de reconnaissance vocale. Construisez le corps de la requête conformément aux instructions suivantes :
- Définissez la propriété
projectsur l’URI d’un projet existant. Il est recommandé d’utiliser cette propriété afin de pouvoir afficher et gérer le modèle dans Speech Studio. Vous pouvez effectuer une requête Projects_List pour obtenir les projets disponibles. - Définissez la propriété requise
datasetssur l’URI des jeux de données que vous souhaitez utiliser pour la formation. - Définissez la propriété requise
locale. Les paramètres régionaux du modèle doivent correspondre aux paramètres régionaux du projet et du modèle de base. Vous ne pourrez plus changer de paramètres régionaux. - Définissez la propriété requise
displayName. Cette propriété est le nom qui est affiché dans Speech Studio. - Si vous le souhaitez, vous pouvez définir la propriété
baseModel. Par exemple :"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"}. Si vous ne spécifiez pas debaseModel, le modèle de base par défaut pour les paramètres régionaux est utilisé.
Effectuez une requête HTTP POST à l’aide de l’URI, comme illustré dans l’exemple suivant. Remplacez YourSubscriptionKey par votre clé de ressource Speech, remplacez YourServiceRegion par votre région de ressource Speech et définissez les propriétés du corps de la requête comme décrit précédemment.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Notes
Dans cet exemple, le paramètre baseModel n’est pas défini. Par conséquent, le modèle de base par défaut pour les paramètres régionaux est utilisé. L’URI du modèle de base est retourné dans la réponse.
Vous devriez recevoir un corps de réponse au format suivant :
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Important
Prenez note de la date dans la propriété adaptationDateTime. Il s’agit de la dernière date à laquelle vous pouvez utiliser le modèle de base pour la formation. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
Prenez note de la date dans la propriété transcriptionDateTime. Il s’agit de la dernière date à laquelle vous pouvez utiliser votre modèle personnalisé pour la reconnaissance vocale. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
La propriété self de niveau supérieur dans le corps de la réponse est l’URI du modèle. Utilisez cet URI pour obtenir des détails sur les dates de projet, de manifeste et de dépréciation du modèle. Vous utilisez également cet URI pour mettre à jour ou supprimer le modèle.
Copier un modèle
Vous pouvez copier un modèle vers un autre projet qui utilise les mêmes paramètres régionaux. Par exemple, une fois qu’un modèle est entraîné avec des données audio dans une région avec du matériel dédié pour la formation, vous pouvez le copier dans une ressource Speech dans une autre région si nécessaire.
Suivez ces instructions pour copier un modèle dans un projet dans une autre région :
- Connectez-vous à Speech Studio.
- Sélectionnez Reconnaissance vocale personnalisée> Votre nom de projet >Effectuer l’apprentissage des modèles personnalisés.
- Sélectionnez Copier vers.
- Dans la page Copier le modèle Speech, sélectionnez une région cible dans laquelle vous souhaitez copier le modèle.

- Sélectionnez une ressource Speech dans la région cible ou créez une ressource Speech.
- Sélectionnez un projet dans lequel vous souhaitez copier le modèle ou créer un projet.
- Sélectionnez Copier.

Une fois le modèle copié avec succès, vous serez averti et pourrez l’afficher dans le projet cible.
La copie d’un modèle directement vers un projet dans une autre région n’est pas prise en charge par l’interface de ligne de commande Speech. Vous pouvez copier un modèle vers un projet dans une autre région à l’aide de Speech Studio ou de l’API REST de reconnaissance vocale.
Pour copier un modèle vers une autre ressource Speech, utilisez l’opération Models_Copy de l’API REST de reconnaissance vocale. Construisez le corps de la requête conformément aux instructions suivantes :
- Définissez la propriété requise
targetSubscriptionKeysur la clé de la ressource Speech de destination.
Effectuez une requête HTTP POST à l’aide de l’URI, comme illustré dans l’exemple suivant. Utilisez la région et l’URI du modèle à partir desquels vous souhaitez copier. Remplacez YourModelId par l’ID de modèle, YourSubscriptionKey par votre clé de ressource Speech et YourServiceRegion par votre région de ressource Speech, et définissez les propriétés du corps de la requête comme décrit précédemment.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models/YourModelId:copy"
Notes
Seule la propriété targetSubscriptionKey du corps de la requête contient des informations sur la ressource Speech de destination.
Vous devriez recevoir un corps de réponse au format suivant :
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copy"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Connecter un modèle
Les modèles peuvent avoir été copiés à partir d’un projet à l’aide de l’interface CLI Speech ou de l’API REST, sans être connectés à un autre projet. La connexion d’un modèle est une question de mise à jour du modèle avec une référence au projet.
Si vous y êtes invité dans Speech Studio, vous pouvez les connecter en sélectionnant le bouton Se connecter.
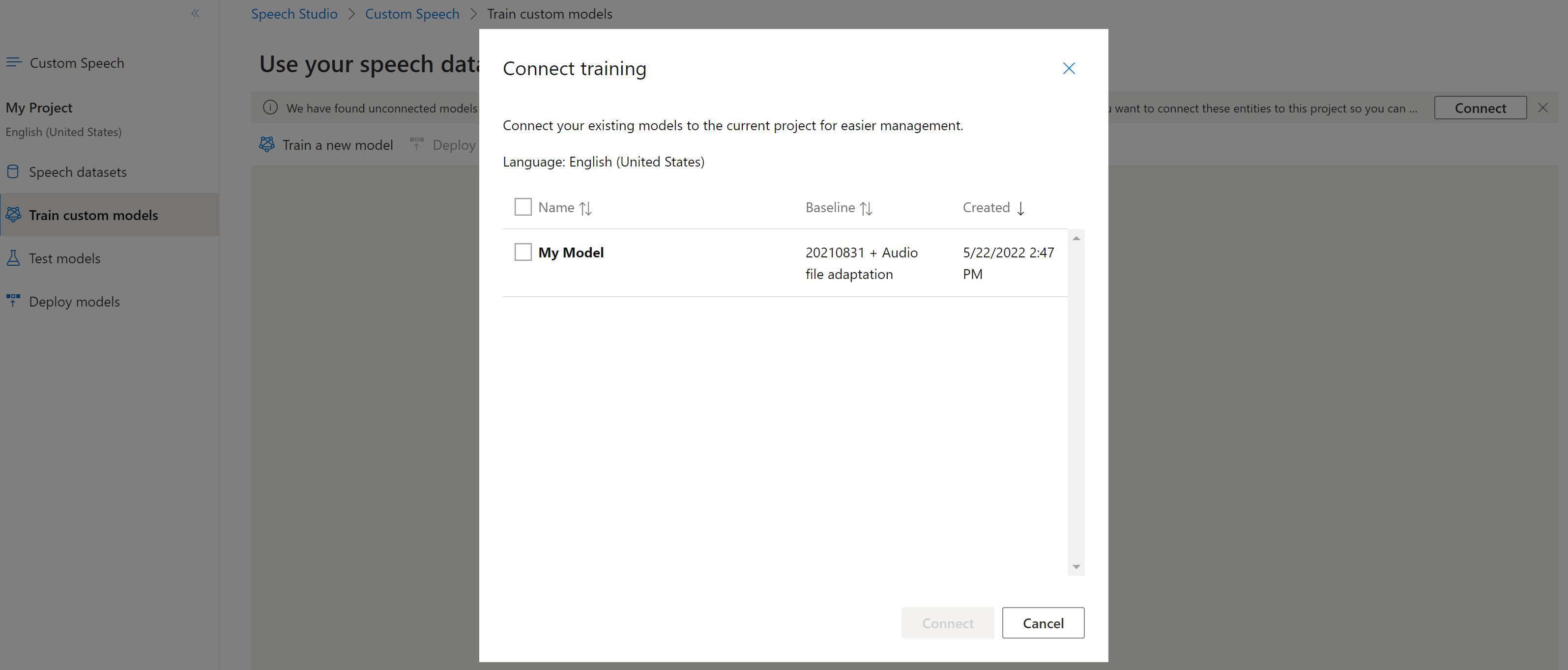
Pour connecter un modèle à un projet, utilisez la commande spx csr model update. Construisez les paramètres de la requête conformément aux instructions suivantes :
- Définissez le paramètre
projectsur l’URI d’un projet existant. Il est recommandé d’utiliser ce paramètre afin de pouvoir afficher et gérer le modèle dans Speech Studio. Vous pouvez exécuter la commandespx csr project listpour obtenir les projets disponibles. - Définissez le paramètre requis
modelIdsur l’ID du modèle que vous souhaitez connecter au projet.
Voici un exemple de commande CLI Speech qui connecte un modèle à un projet :
spx csr model update --api-version v3.2 --model YourModelId --project YourProjectId
Vous devriez recevoir un corps de réponse au format suivant :
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}
Pour l’aide de l’interface CLI Speech avec les modèles, exécutez la commande suivante :
spx help csr model
Pour connecter un nouveau modèle à un projet de la ressource Speech où le modèle a été copié, utilisez l’opération Models_Update de l’API REST de reconnaissance vocale. Construisez le corps de la requête conformément aux instructions suivantes :
- Définissez la propriété requise
projectsur l’URI d’un projet existant. Il est recommandé d’utiliser cette propriété afin de pouvoir afficher et gérer le modèle dans Speech Studio. Vous pouvez effectuer une requête Projects_List pour obtenir les projets disponibles.
Effectuez une requête HTTP PATCH à l’aide de l’URI, comme illustré dans l’exemple suivant. Utilisez l’URI du nouveau modèle. Vous pouvez obtenir le nouvel ID de modèle à partir de la propriété self du corps de la réponse Models_Copy. Remplacez YourSubscriptionKey par votre clé de ressource Speech, remplacez YourServiceRegion par votre région de ressource Speech et définissez les propriétés du corps de la requête comme décrit précédemment.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Vous devriez recevoir un corps de réponse au format suivant :
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}