Tutoriel : partie 2 – Créer une application de conversation personnalisée en utilisant le Kit de développement logiciel (SDK) de flux d’invite
Dans ce tutoriel, vous utilisez le Kit de développement logiciel (SDK) de flux d’invite (et d’autres bibliothèques) pour créer, configurer, évaluer et déployer une application de conversation pour votre entreprise de vente au détail appelée Contoso Trek. Votre entreprise de vente au détail se spécialise dans l’équipement de camping extérieur et les vêtements. L’application de conversation doit répondre à des questions sur vos produits et services. Par exemple, l’application de conversation peut répondre à des questions comme « quelle tente est la plus étanche ? » ou « quel est le meilleur sac de couchage par temps froid ? ».
Cette deuxième partie vous montre comment améliorer une application de conversation de base en ajoutant la Génération augmentée de récupération (RAG) pour fonder les réponses dans vos données personnalisées. La Génération augmentée de récupération (RAG) est un modèle qui utilise vos données avec un grand modèle de langage (LLM) pour générer des réponses spécifiques à vos données. Dans cette deuxième partie, vous allez apprendre à :
- Déployer des modèles IA dans Azure AI Studio à utiliser dans votre app
- Développer du code RAG personnalisé
- Utiliser le flux d’invite pour tester votre application de conversation
Ce tutoriel est la deuxième partie d’un tutoriel qui en compte trois.
Prérequis
Vous avez besoin d’une copie locale des données de produit. Le dépôt Azure-Samples/rag-data-openai-python-promptflow sur GitHub contient des exemples d’informations sur les produits de vente au détail pertinents pour le scénario de ce tutoriel. Télécharger l’exemple de données de produit de vente au détail Contoso Trek dans un fichier ZIP sur votre ordinateur local.
Structure du code d’application
Créez un dossier appelé rag-tutorial sur votre ordinateur local. Cette série de tutoriels décrit la création du contenu de chaque fichier. Lorsque vous terminez la série de tutoriels, la structure de votre dossiers ressemble à ceci :
rag-tutorial/
│ .env
│ build_index.py
│ deploy.py
│ evaluate.py
│ eval_dataset.jsonl
| invoke-local.py
│
├───copilot_flow
│ └─── chat.prompty
| └─── copilot.py
| └─── Dockerfile
│ └─── flow.flex.yaml
│ └─── input_with_chat_history.json
│ └─── queryIntent.prompty
│ └─── requirements.txt
│
├───data
| └─── product-info/
| └─── [Your own data or sample data as described in the prerequisites.]
L’implémentation de ce tutoriel utilise le flux flexible du flux d’invite, qui est l’approche orientée code pour implémenter des flux. Vous spécifiez une fonction d’entrée (qui est dans copilot.py), puis utilisez les fonctionnalités de test, d’évaluation et de suivi du flux d’invite pour votre flux. Ce flux est dans le code et n’a pas de DAG ou autre composant visuel. Apprenez-en davantage sur le développement d’un flux flexible dans la documentation sur le flux d’invite sur GitHub.
Définir les variables d’environnement initiales
Il existe une collection de variables d’environnement utilisées dans les différents extraits de code. Ajoutez-les toutes dans un fichier .env.
Important
Si vous le créez dans un référentiel Git, veillez à ce que .env se trouve dans votre fichier .gitignore afin de ne pas l’archiver par erreur dans le référentiel.
Commencez par ces valeurs. Vous ajoutez quelques valeurs à mesure que vous progressez dans le tutoriel.
Créez un fichier .env dans votre dossier rag-tutorial. Ajoutez ces variables :
AZURE_SUBSCRIPTION_ID=<your subscription id> AZURE_RESOURCE_GROUP=<your resource group> AZUREAI_PROJECT_NAME=<your project name> AZURE_OPENAI_CONNECTION_NAME=<your AIServices or Azure OpenAI connection name> AZURE_SEARCH_ENDPOINT=<your Azure Search endpoint> AZURE_SEARCH_CONNECTION_NAME=<your Azure Search connection name>
Remplacez les espaces réservés par les valeurs suivantes :
Recherchez les
<your subscription id>,<your resource group>et<your project name>à partir de l’affichage de votre projet dans AI Studio :- Dans AI Studio, accédez à votre projet et sélectionnez Paramètres dans le volet gauche.
- Dans la section Propriétés du projet, recherchez l’ID d’abonnement et le Groupe de ressources. Le champ Nom est
<your project name>
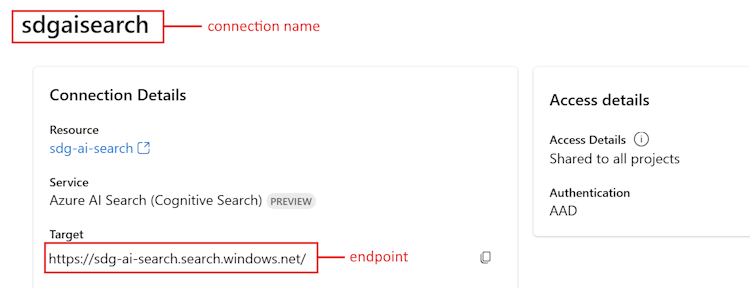
Toujours dans les Paramètres de votre projet, dans la section Ressources connectées, vous verrez une entrée pour Azure AI Services ou Azure OpenAI. Sélectionnez le nom pour ouvrir les Informations de connexion. Le nom de la connexion s’affiche en haut de la page Informations de connexion. Copiez ce nom à utiliser pour
<your AIServices or Azure OpenAI connection name>.Revenez à la page Paramètres du projet. Dans la section Ressources connectées, sélectionnez le lien du service Recherche Azure AI.
- Copiez l’URL Cible pour
<your Azure Search endpoint>. - Copiez le nom en haut pour
<your Azure Search connection name>.
- Copiez l’URL Cible pour
Déployer des modèles
Vous avez besoin de deux modèles pour créer une application de conversation basée sur la Génération augmentée de récupération (RAG) : un modèle de conversation Azure OpenAI (gpt-3.5-turbo) et un modèle d’incorporation Azure OpenAI (text-embedding-ada-002). Déployez ces modèles dans votre projet Azure AI Studio en utilisant cet ensemble de d’étapes pour chaque modèle.
Ces étapes déploient un modèle sur un point de terminaison en temps réel à partir du catalogue de modèles d’AI Studio :
Connectez-vous à AI Studio et accédez à la page Accueil .
Sélectionnez catalogue de modèles dans la barre latérale gauche.
Dans le filtre Collections, sélectionnez Azure OpenAI.

Sélectionnez le modèle à partir de la collection Azure OpenAI. La première fois, sélectionnez le modèle
gpt-3.5-turbo. La deuxième fois, sélectionnez le modèletext-embedding-ada-002.Sélectionnez Déployer pour ouvrir la fenêtre de déploiement.
Sélectionnez le hub sur lequel vous souhaitez déployer le modèle. Utilisez le même hub que votre projet.
Spécifiez le nom du déploiement et modifiez d’autres paramètres par défaut en fonction de vos besoins.
Sélectionnez Déployer.
Vous arrivez dans la page des détails du déploiement. Sélectionnez Ouvrir dans le terrain de jeu.
Sélectionnez Afficher le code pour obtenir des exemples de code qui permettront de consommer le modèle déployé dans votre application.

Lorsque vous déployez le modèle gpt-3.5-turbo, recherchez les valeurs suivantes dans la section Afficher le code, puis ajoutez-les dans votre fichier .env :
AZURE_OPENAI_ENDPOINT=<endpoint_value>
AZURE_OPENAI_CHAT_DEPLOYMENT=<chat_model_deployment_name>
AZURE_OPENAI_API_VERSION=<api_version>
Quand vous déployez le modèle text-embedding-ada-002, ajoutez le nom à votre fichier .env :
AZURE_OPENAI_EMBEDDING_DEPLOYMENT=<embedding_model_deployment_name>
Installer Azure CLI et se connecter
Vous installez l'interface Azure CLI et vous vous connectez depuis votre environnement de développement local, afin de pouvoir utiliser vos informations d'identification pour appeler le service Azure OpenAI.
Dans la plupart des cas, vous pouvez installer Azure CLI à partir de votre terminal à l’aide de la commande suivante :
Vous pouvez suivre les instructions Comment installer l’interface de ligne de commande Azure si ces commandes ne fonctionnent pas pour votre système d’exploitation ou configuration particulier.
Après avoir installé Azure CLI, connectez-vous à l’aide de la commande az login et connectez-vous à l’aide du navigateur :
az login
Nous créons maintenant notre application et appelons Azure OpenAI Service à partir du code.
Créer un environnement Python
Tout d’abord, nous devons créer un environnement Python que nous pouvons utiliser pour installer les packages du Kit de développement logiciel (SDK) de flux d’invite. N’installez pas de packages dans votre installation globale de Python. Vous devez toujours utiliser un environnement virtuel ou conda lors de l’installation de packages Python. Sinon, vous pouvez interrompre votre installation globale de Python.
Si nécessaire, installez Python
Nous vous recommandons d’utiliser Python 3.10 ou version ultérieure, mais l’utilisation d’au moins Python 3.8 est requise. Si vous n’avez pas installé une version appropriée de Python, vous pouvez suivre les instructions du didacticiel Python VS Code pour le moyen le plus simple d’installer Python sur votre système d’exploitation.
Créer un environnement virtuel
Si Python 3.10, ou une version ultérieure est déjà installé, vous pouvez créer un environnement virtuel à l’aide des commandes suivantes :
L'activation de l'environnement Python signifie que lorsque vous exécutez python ou pip depuis la ligne de commande, vous utilisez alors l'interpréteur Python contenu dans le dossier .venv de votre application.
Remarque
Vous pouvez utiliser la commande deactivate pour quitter l’environnement virtuel Python et la réactiver ultérieurement si nécessaire.
Mettre à niveau pip
Exécutez la commande suivante pour veiller à disposer de la version la plus récente de PIP :
python -m pip install --upgrade pip
Installer le Kit de développement logiciel (SDK) de flux d’invite
Flux d’invite est une suite d'outils de développement conçus pour rationaliser le cycle de développement de bout en bout des applications d'IA basées sur le LLM, depuis l'idéation, le prototypage, les tests, l'évaluation jusqu'au déploiement et à la surveillance de la production.
Utilisez pip pour installer le Kit de développement logiciel (SDK) de flux d’invite dans l’environnement virtuel que vous avez créé.
pip install promptflow
pip install azure-identity
Le Kit de développement logiciel (SDK) de flux d’invite prend une dépendance sur plusieurs packages, que vous pouvez choisir d’installer séparément si vous ne souhaitez pas tous les installer :
promptflow-core: contient le runtime de flux d’invite principal utilisé pour l’exécution du code LLMpromptflow-tracing: bibliothèque légère utilisée pour émettre des traces OpenTelemetry dans des normespromptflow-devkit: contient le lit de test de flux d’invite et les outils de visionneuse de trace pour les environnements de développement locauxopenai: bibliothèques clientes pour l’utilisation de Azure OpenAI servicepython-dotenv: utilisé pour définir des variables d’environnement en les lisant à partir de fichiers.env
Créer un index Recherche Azure AI
L’objectif avec cette application basée sur RAG est de baser les réponses du modèle sur vos données personnalisées. Vous utilisez un index Recherche Azure AI qui stocke des données vectorisées à partir du modèle d’incorporations. L’index de recherche est utilisé pour récupérer des documents pertinents en fonction de la question de l’utilisateur.
Si vous n’avez pas déjà créé d’index Recherche Azure AI, nous allons découvrir comment en créer un. Si vous avez déjà un index à utiliser, vous pouvez passer à la section Définir la variable d’environnement de recherche. L’index de recherche est créé sur le service Recherche Azure AI qui a été créé ou référencé à l’étape précédente.
Utilisez vos propres données ou téléchargez l’exemple de données de produit de vente au détail Contoso Trek dans un fichier ZIP sur votre ordinateur local. Décompressez le fichier dans votre dossier rag-tutorial/data. Ces données sont une collection de fichiers Markdown qui représentent des informations sur le produit. Les données sont structurées de manière simple à ingérer dans un index de recherche. Vous créez un index de recherche à partir de ces données.
Le package RAG de flux d’invite vous permet d’ingérer les fichiers Markdown, de créer localement un index de recherche et de l’inscrire dans le projet cloud. Installez le package RAG de flux d’invite :
pip install promptflow-ragCréez le fichier build_index.py dans votre dossier rag-tutorial.
Copiez et collez le code suivant dans votre fichier build_index.py.
import os from dotenv import load_dotenv load_dotenv() from azure.ai.ml import MLClient from azure.identity import DefaultAzureCredential from azure.ai.ml.entities import Index from promptflow.rag.config import ( LocalSource, AzureAISearchConfig, EmbeddingsModelConfig, ConnectionConfig, ) from promptflow.rag import build_index client = MLClient( DefaultAzureCredential(), os.getenv("AZURE_SUBSCRIPTION_ID"), os.getenv("AZURE_RESOURCE_GROUP"), os.getenv("AZUREAI_PROJECT_NAME"), ) import os # append directory of the current script to data directory script_dir = os.path.dirname(os.path.abspath(__file__)) data_directory = os.path.join(script_dir, "data/product-info/") # Check if the directory exists if os.path.exists(data_directory): files = os.listdir(data_directory) # List all files in the directory if files: print( f"Data directory '{data_directory}' exists and contains {len(files)} files." ) else: print(f"Data directory '{data_directory}' exists but is empty.") exit() else: print(f"Data directory '{data_directory}' does not exist.") exit() index_name = "tutorial-index" # your desired index name index_path = build_index( name=index_name, # name of your index vector_store="azure_ai_search", # the type of vector store - in this case it is Azure AI Search. Users can also use "azure_cognitive search" embeddings_model_config=EmbeddingsModelConfig( model_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), deployment_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_OPENAI_CONNECTION_NAME"), ), ), input_source=LocalSource(input_data=data_directory), # the location of your files index_config=AzureAISearchConfig( ai_search_index_name=index_name, # the name of the index store inside the azure ai search service ai_search_connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_SEARCH_CONNECTION_NAME"), ), ), tokens_per_chunk=800, # Optional field - Maximum number of tokens per chunk token_overlap_across_chunks=0, # Optional field - Number of tokens to overlap between chunks ) # register the index so that it shows up in the cloud project client.indexes.create_or_update(Index(name=index_name, path=index_path))- Définissez la variable
index_namesur le nom de l’index souhaité. - Si nécessaire, vous pouvez mettre à jour la variable
path_to_datavers le chemin d’accès où vos fichiers de données sont stockés.
Important
Par défaut, l’exemple de code attend la structure de code d’application décrite précédemment dans ce tutoriel. Le dossier
datadoit être au même niveau que votre build_index.py et le dossierproduct-infotéléchargé qui contient des fichiers md.- Définissez la variable
À partir de votre console, exécutez le code pour créer votre index localement et l’inscrire dans le projet cloud :
python build_index.pyUne fois le script exécuté, vous pouvez afficher votre index nouvellement créé dans la page Index de votre projet Azure AI Studio. Pour plus d’informations, consultez Comment créer et consommer des index vectoriels dans Azure AI Studio.
Si vous réexécutez le script avec le même nom d’index, il crée une nouvelle version du même index.
Définir la variable d’environnement d’index de recherche
Une fois que vous avez le nom d’index que vous souhaitez utiliser (en créant un nouveau nom ou en référençant un nom existant), ajoutez-le à votre fichier .env, comme suit :
AZUREAI_SEARCH_INDEX_NAME=<index-name>
Développer du code RAG personnalisé
Ensuite, vous créez du code personnalisé pour ajouter des fonctionnalités de génération augmentée de récupération (RAG) à une application de conversation de base. Dans le guide de démarrage rapide, vous avez créé les fichiers chat.py et chat.prompty. Ici, vous développez ce code pour inclure des fonctionnalités RAG.
L’application de conversation avec RAG implémente la logique générale suivante :
- Générer une requête de recherche basée sur l’intention de requête de l’utilisateur et sur l’historique des conversations
- Utiliser un modèle d’incorporations pour incorporer la requête
- Récupérer des documents pertinents à partir de l’index de recherche, en fonction de la requête
- Passer le contexte approprié au modèle d’achèvement de conversation Azure OpenAI
- Renvoyer la réponse du modèle Azure OpenAI
La logique d’implémentation de l’application de conversation
La logique d’implémentation de l’application de conversation se trouve dans le fichier copilot.py. Ce fichier contient la logique principale de l’application de conversation basée sur RAG.
Créez un dossier nommé copilot_flow dans le dossier rag-tutorial.
Créez ensuite un fichier appelé copilot.py dans le dossier copilot_flow.
Ajoutez le code suivant au fichier copilot.py :
import os from dotenv import load_dotenv load_dotenv() from promptflow.core import Prompty, AzureOpenAIModelConfiguration from promptflow.tracing import trace from openai import AzureOpenAI # <get_documents> @trace def get_documents(search_query: str, num_docs=3): from azure.identity import DefaultAzureCredential, get_bearer_token_provider from azure.search.documents import SearchClient from azure.search.documents.models import VectorizedQuery token_provider = get_bearer_token_provider( DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default" ) index_name = os.getenv("AZUREAI_SEARCH_INDEX_NAME") # retrieve documents relevant to the user's question from Cognitive Search search_client = SearchClient( endpoint=os.getenv("AZURE_SEARCH_ENDPOINT"), credential=DefaultAzureCredential(), index_name=index_name, ) aoai_client = AzureOpenAI( azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_ad_token_provider=token_provider, api_version=os.getenv("AZURE_OPENAI_API_VERSION"), ) # generate a vector embedding of the user's question embedding = aoai_client.embeddings.create( input=search_query, model=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT") ) embedding_to_query = embedding.data[0].embedding context = "" # use the vector embedding to do a vector search on the index vector_query = VectorizedQuery( vector=embedding_to_query, k_nearest_neighbors=num_docs, fields="contentVector" ) results = trace(search_client.search)( search_text="", vector_queries=[vector_query], select=["id", "content"] ) for result in results: context += f"\n>>> From: {result['id']}\n{result['content']}" return context # <get_documents> from promptflow.core import Prompty, AzureOpenAIModelConfiguration from pathlib import Path from typing import TypedDict class ChatResponse(TypedDict): context: dict reply: str def get_chat_response(chat_input: str, chat_history: list = []) -> ChatResponse: model_config = AzureOpenAIModelConfiguration( azure_deployment=os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT"), api_version=os.getenv("AZURE_OPENAI_API_VERSION"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), ) searchQuery = chat_input # Only extract intent if there is chat_history if len(chat_history) > 0: # extract current query intent given chat_history path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/queryIntent.prompty" # pass absolute file path to prompty intentPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": { "max_tokens": 256, }, }, ) searchQuery = intentPrompty(query=chat_input, chat_history=chat_history) # retrieve relevant documents and context given chat_history and current user query (chat_input) documents = get_documents(searchQuery, 3) # send query + document context to chat completion for a response path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/chat.prompty" chatPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": {"max_tokens": 256, "temperature": 0.2}, }, ) result = chatPrompty( chat_history=chat_history, chat_input=chat_input, documents=documents ) return dict(reply=result, context=documents)
Le fichier copilot.py contient deux fonctions clés : get_documents() et get_chat_response().
Notez que ces deux fonctions ont le décorateur @trace, ce qui vous permet de voir les journaux de suivi de flux d’invite des entrées et sorties de chaque appel de fonction. @trace est une approche alternative et étendue de la façon dont le guide de démarrage rapide a montré les fonctionnalités de suivi.
La fonction get_documents() est le cœur de la logique RAG.
- Prend la requête de recherche et le nombre de documents à récupérer.
- Incorpore la requête de recherche à l’aide d’un modèle d’incorporations.
- Interroge l’index Recherche Azure pour récupérer les documents pertinents pour la requête.
- Retourne le contexte des documents.
La fonction get_chat_response() s’appuie sur la logique précédente dans votre fichier chat.py :
- Prend
chat_inputetchat_history. - Construit la requête de recherche en fonction de l’intention
chat_inputet dechat_history. - Appelle
get_documents()pour récupérer les documents pertinents. - Appelle le modèle d’achèvement de conversation avec le contexte pour obtenir une réponse basée sur la requête.
- Retourne la réponse et le contexte. Nous définissons un dictionnaire typé comme objet de retour pour notre fonction
get_chat_response(). Vous pouvez choisir la façon dont votre code retourne la réponse pour correspondre le mieux à votre cas d’usage.
La fonction get_chat_response() utilise deux fichiers Prompty pour effectuer les appels nécessaires au grand modèle de langage (LLM), que nous abordons ensuite.
Modèle de prompt pour la conversation
Le fichier chat.prompty est simple et similaire au fichier chat.prompty du guide de démarrage rapide. L’invite du système est mise à jour pour refléter notre produit et les modèles d’invite incluent le contexte du document.
Ajoutez le fichier chat.prompty dans le répertoire copilot_flow. Le fichier représente l’appel au modèle d’achèvement de conversation, avec l’invite du système, l’historique des conversations et le contexte de document fournis.
Ajoutez ce code au fichier chat.prompty :
--- name: Chat Prompt description: A prompty that uses the chat API to respond to queries grounded in relevant documents model: api: chat configuration: type: azure_openai inputs: chat_input: type: string chat_history: type: list is_chat_history: true default: [] documents: type: object --- system: You are an AI assistant helping users with queries related to outdoor outdooor/camping gear and clothing. If the question is not related to outdoor/camping gear and clothing, just say 'Sorry, I only can answer queries related to outdoor/camping gear and clothing. So, how can I help?' Don't try to make up any answers. If the question is related to outdoor/camping gear and clothing but vague, ask for clarifying questions instead of referencing documents. If the question is general, for example it uses "it" or "they", ask the user to specify what product they are asking about. Use the following pieces of context to answer the questions about outdoor/camping gear and clothing as completely, correctly, and concisely as possible. Do not add documentation reference in the response. # Documents {{documents}} {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} user: {{chat_input}}
Modèle de prompt pour l’historique des conversations
Étant donné que nous implémentons une application basée sur RAG, une logique supplémentaire est nécessaire pour récupérer des documents pertinents non seulement pour la requête utilisateur actuelle, mais également en tenant compte de l’historique des conversations. Sans cette logique supplémentaire, votre appel LLM prendrait en compte l’historique des conversations. Mais vous ne récupéreriez pas les documents appropriés pour ce contexte, de sorte que vous n’obtiendriez pas la réponse attendue.
Par exemple, si l’utilisateur pose la question « est-elle étanche ? », nous avons besoin que le système examine l’historique des conversations pour déterminer à quoi le pronom « elle » fait référence et inclure ce contexte dans la requête de recherche à incorporer. Ainsi, nous récupérons les bons documents pour « elle » (peut-être la tente Alpine Explorer) et son « coût ».
Au lieu de passer uniquement la requête de l’utilisateur à incorporer, nous devons générer une nouvelle requête de recherche qui prend en compte l’historique des conversations. Nous utilisons un autre Prompty (qui est un autre appel LLM) avec une invite spécifique pour interpréter l’intention de la requête utilisateur en fonction de l’historique des conversations et construire une requête de recherche qui a le contexte nécessaire.
Créez le fichier queryIntent.prompty dans le dossier copilot_flow.
Entrez ce code pour obtenir des détails spécifiques sur le format d’invite et des exemples en quelques essais.
--- name: Chat Prompt description: A prompty that extract users query intent based on the current_query and chat_history of the conversation model: api: chat configuration: type: azure_openai inputs: query: type: string chat_history: type: list is_chat_history: true default: [] --- system: - You are an AI assistant reading a current user query and chat_history. - Given the chat_history, and current user's query, infer the user's intent expressed in the current user query. - Once you infer the intent, respond with a search query that can be used to retrieve relevant documents for the current user's query based on the intent - Be specific in what the user is asking about, but disregard parts of the chat history that are not relevant to the user's intent. Example 1: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." } ] \``` User query: "how much do they cost?" Intent: "The user wants to know how much the Trailwalker Hiking Shoes cost." Search query: "price of Trailwalker Hiking Shoes" Example 2: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." }, { "role": "user", "content": "how much do they cost?" }, { "role": "assistant", "content": "The TrailWalker Hiking Shoes are priced at $110." }, { "role": "user", "content": "do you have waterproof tents?" }, { "role": "assistant", "content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?" }, { "role": "user", "content": "which is your most waterproof tent?" }, { "role": "assistant", "content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture." } ] \``` User query: "how much does it cost?" Intent: "the user would like to know how much the Alpine Explorer Tent costs" Search query: "price of Alpine Explorer Tent" {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} Current user query: {{query}} Search query:
Le message système simple dans notre fichier queryIntent.prompty atteint le minimum requis pour que la solution RAG fonctionne avec l’historique des conversations.
Configurer les packages requis
Créez le fichier requirements.txt dans le dossier copilot_flow. Ajoutez ce contenu :
openai
azure-identity
azure-search-documents==11.4.0
promptflow[azure]==1.11.0
promptflow-tracing==1.11.0
promptflow-tools==1.4.0
promptflow-evals==0.3.0
jinja2
aiohttp
python-dotenv
Ces packages sont requis pour que le flux s’exécute localement et dans un environnement déployé.
Utiliser le flux flexible
Comme mentionné précédemment, cette implémentation utilise le flux flexible du flux d’invite, qui est l’approche orientée code pour implémenter des flux. Vous spécifiez une fonction d’entrée (définie dans copilot.py). Pour en savoir plus, consultez Développer un flux flexible.
Ce fichier yaml spécifie la fonction d’entrée, qui est la fonction get_chat_response définie dans copilot.py. Il spécifie également les exigences requises pour l’exécution du flux.
Créez le fichier flow.flex.yaml dans le dossier copilot_flow. Ajoutez ce contenu :
entry: copilot:get_chat_response
environment:
python_requirements_txt: requirements.txt
Utiliser le flux d’invite pour tester votre application de conversation
Utilisez la fonctionnalité de test du flux d’invite pour voir comment votre application de conversation fonctionne comme prévu sur des exemples d’entrées. En utilisant votre fichier flow.flex.yaml, vous pouvez utiliser le flux d’invite pour tester avec vos entrées spécifiées.
Exécutez le flux à l’aide de cette commande de flux d’invite :
pf flow test --flow ./copilot_flow --inputs chat_input="how much do the Trailwalker shoes cost?"
Vous pouvez également exécuter le flux de manière interactive avec l’indicateur --ui.
pf flow test --flow ./copilot_flow --ui
Lorsque vous utilisez --ui, l’exemple interactif d’expérience de conversation ouvre une fenêtre dans votre navigateur local.
- La première fois que vous exécutez avec l’indicateur
--ui, vous devez sélectionner manuellement vos entrées et sorties de conversation dans les options. La première fois que vous créez cette session, sélectionnez les paramètres de Configuration du champ d’entrée/sortie de conversation, puis démarrez la conversation. - La prochaine fois que vous exécutez avec l’indicateur
--ui, la session mémorisera vos paramètres.

Lorsque vous avez terminé avec votre session interactive, tapez Ctrl + C dans la fenêtre de terminal pour arrêter le serveur.
Tester avec l’historique des conversations
En général, le flux d’invite et Prompty prennent en charge l’historique des conversations. Si vous testez avec l’indicateur --ui dans le serveur frontal servi localement, le flux d’invite gère votre historique des conversations. Si vous testez sans --ui, vous pouvez spécifier un fichier d’entrée qui inclut l’historique des conversations.
Étant donné que notre application implémente RAG, nous avons dû ajouter une logique supplémentaire pour gérer l’historique des conversations dans le fichier queryIntent.prompty.
Pour tester l’historique des conversations, créez un fichier appelé input_with_chat_history.json dans le dossier copilot_flow, puis collez ce contenu :
{
"chat_input": "how much does it cost?",
"chat_history": [
{
"role": "user",
"content": "are the trailwalker shoes waterproof?"
},
{
"role": "assistant",
"content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions."
},
{
"role": "user",
"content": "how much do they cost?"
},
{
"role": "assistant",
"content": "The TrailWalker Hiking Shoes are priced at $110."
},
{
"role": "user",
"content": "do you have waterproof tents?"
},
{
"role": "assistant",
"content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?"
},
{
"role": "user",
"content": "which is your most waterproof tent?"
},
{
"role": "assistant",
"content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture."
}
]
}
Pour tester avec ce fichier, exécutez :
pf flow test --flow ./copilot_flow --inputs ./copilot_flow/input_with_chat_history.json
La sortie attendue est similaire à : « La tente Alpine Explorer est facturée à 350 $. »
Ce système est en mesure d’interpréter l’intention de la requête « combien coûte-t-elle ? » pour savoir que « elle » fait référence à la tente Alpine Explorer, qui était le contexte le plus récent dans l’historique des conversations. Ensuite, le système construit une requête de recherche pour le prix de la tente Alpine Explorer afin de récupérer les documents pertinents pour le coût de la tente Alpine Explorer, et nous obtenons la réponse.
Si vous accédez à la trace à partir de cette exécution de flux, vous voyez la conversation en action. Le lien des traces locales s’affiche dans la sortie de la console avant le résultat de l’exécution du test de flux.

Nettoyer les ressources
Pour éviter la facturation de coûts Azure inutiles, vous devez supprimer les ressources créées dans ce tutoriel si elles ne sont plus nécessaires. Pour gérer les ressources, vous pouvez utiliser le Portail Microsoft Azure.
Mais ne les supprimez pas encore, si vous souhaitez déployer votre application de conversation sur Azure dans la partie suivante de cette série de tutoriels.