Récupération de base de données accélérée dans Azure SQL
S’applique à : ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
La Récupération de base de données accélérée est une fonctionnalité du moteur de base de données SQL Server qui améliore considérablement la disponibilité des bases de données, en particulier en présence de transactions durables, grâce à une nouvelle conception du processus de récupération du moteur de base de données SQL Server.
La fonctionnalité ADR est actuellement disponible pour Azure SQL Database, Azure SQL Managed Instance, les bases de données d’Azure Synapse Analytics et les machines virtuelles SQL Server sur Azure à partir de SQL Server 2019. Pour plus d’informations sur ADR dans SQL Server, consultez Gérer la récupération de base de données accélérée.
Notes
ADR est activé par défaut dans Azure SQL Database et Azure SQL Managed Instance. La désactivation d’ADR dans Azure SQL Database et Azure SQL Managed Instance n’est pas prise en charge.
Vue d’ensemble
Les principaux avantages de la récupération de base de données accélérée sont les suivants :
Récupération de base de données rapide et cohérente
Avec la récupération de base de données accélérée, les transactions longues n’ont pas d’impact sur le temps de récupération global, ce qui permet une récupération rapide et cohérente des bases de données, quel que soit le nombre de transactions actives dans le système ou la taille de ces transactions.
Annulation instantanée des transactions
Avec la récupération de base de données accélérée, l’annulation des transactions est instantanée, quelle que soit la durée d’activité de la transaction ou le nombre de mises à jour effectuées.
Troncation agressive du journal
Avec la récupération de base de données accélérée, le journal des transactions est tronqué de façon agressive, même en présence de transactions longues, ce qui l’empêche de croître hors de contrôle.
Processus de récupération de base de données standard
La récupération de base de données suit le modèle de récupération ARIES et comporte trois phases, qui sont illustrées dans le schéma suivant et expliquées ensuite de façon plus détaillée.
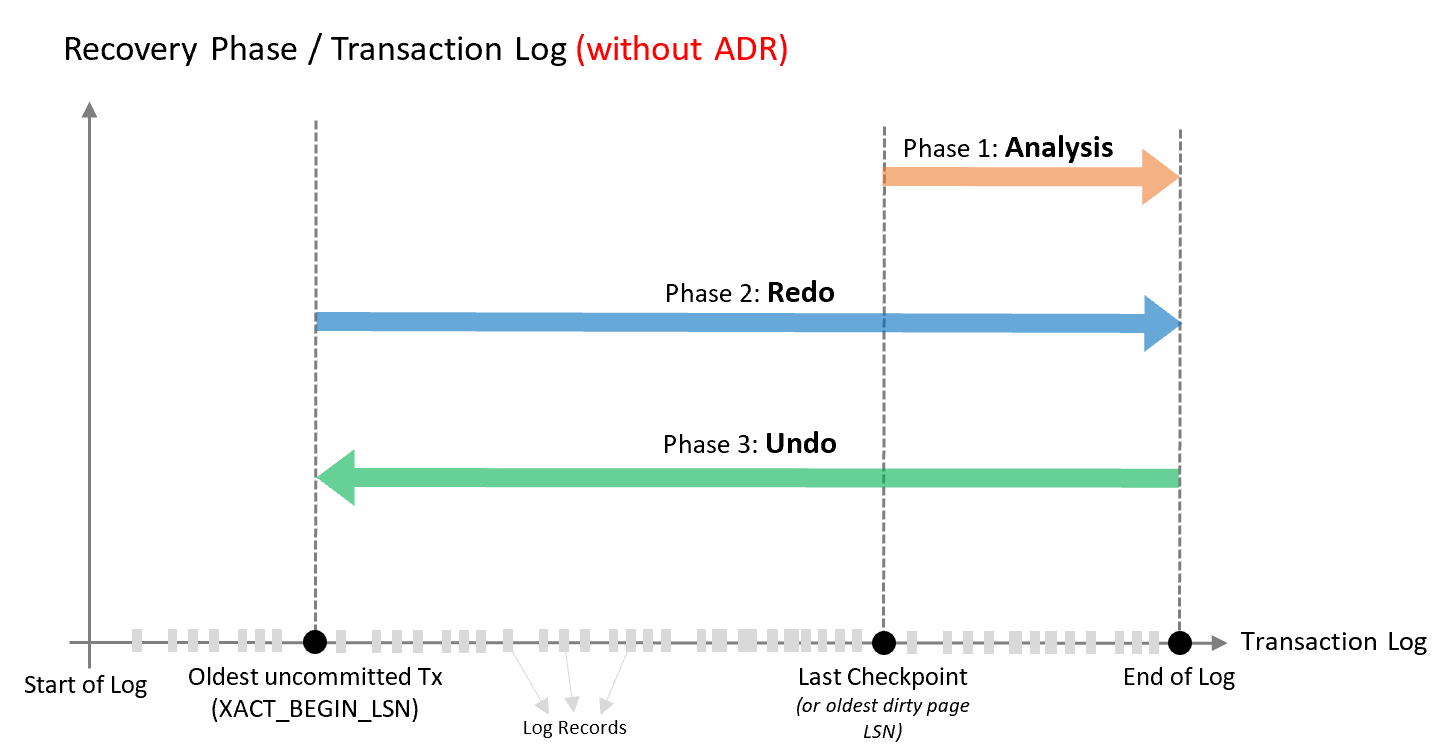
Phase d’analyse
Analyse vers l’avant du journal des transactions à partir du début du dernier point de contrôle réussi (ou du LSN de la page de modifications la plus ancienne) jusqu’à la fin, pour déterminer l’état de chaque transaction au moment de l’arrêt de la base de données.
Phase de restauration par progression
Analyse vers l’avant du journal des transactions depuis la transaction non validée la plus ancienne jusqu’à la fin, pour rétablir la base de données à l’état où elle était au moment de l’incident en refaisant toutes les opérations validées.
Phase d’annulation
Pour chaque transaction qui était active au moment du plantage, parcourt le journal vers l’arrière, en annulant les opérations effectuées par cette transaction.
Avec cette conception, le temps nécessaire au moteur de base de données SQL Server pour récupérer d’un redémarrage inattendu est (à peu près) proportionnel à la taille de la transaction active la plus longue dans le système au moment de l’incident. La récupération nécessite l’annulation de toutes les transactions incomplètes. Le temps nécessaire est proportionnel au travail effectué par la transaction et à la durée pendant laquelle elle a été active. Ainsi, le processus de récupération peut prendre beaucoup de temps en présence de transactions longues (comme des grosses opérations d’insertion en bloc ou des opérations de création d’index sur une grande table).
De plus, annuler/défaire une grande transaction selon cette conception peut également prendre beaucoup de temps, car cela utilise la même phase d’annulation que celle décrite plus haut.
En outre, le moteur de base de données SQL Server ne peut pas tronquer le journal des transactions quand il y a des transactions longues, car les enregistrements de journal correspondants sont nécessaires pour les processus de récupération et d’annulation. Le résultat de cette conception du moteur de base de données SQL Server est que certains clients étaient confrontés à un problème de taille du journal des transactions devenant très volumineux et consommant de très grandes quantités d’espace sur le disque.
Le processus de récupération de base de données accélérée
La récupération de base de données accélérée résout les problèmes évoqués plus haut en redéfinissant complètement le processus de récupération du moteur de base de données SQL Server pour :
- Rendre la durée de la récupération constante/instantanée en évitant d’avoir à parcourir le journal à partir de/vers le début de la transaction active la plus ancienne. Avec la récupération de base de données accélérée, le journal des transactions est traité seulement à partir du dernier point de contrôle réussi (ou du numéro séquentiel dans le journal (LSN) de la page de modifications la plus ancienne). Ainsi, le temps de récupération n’est pas affecté par les transactions longues.
- Minimiser l’espace nécessaire au journal des transactions, car il n’est plus nécessaire de traiter le journal pour l’ensemble de la transaction. Ainsi, le journal des transactions peut être tronqué de façon agressive à mesure que des points de contrôle et des sauvegardes se produisent.
À un niveau plus général, la récupération de base de données accélérée permet de récupérer rapidement la base de données en gérant des versions pour toutes les modifications physiques de la base de données et en annulant seulement les opérations logiques, qui sont limitées et peuvent être annulées quasi instantanément. Les transactions qui étaient actives au moment d’un plantage sont marquées comme étant abandonnées et par conséquent, toutes les versions générées par ces transactions peuvent être ignorées par les requêtes utilisateur simultanées.
Le processus de récupération de base de données accélérée a les trois mêmes phases que le processus de récupération actuel. Le fonctionnement de ces phases avec la récupération de base de données accélérée est illustré dans le diagramme suivant et expliqué plus en détails après celui-ci.
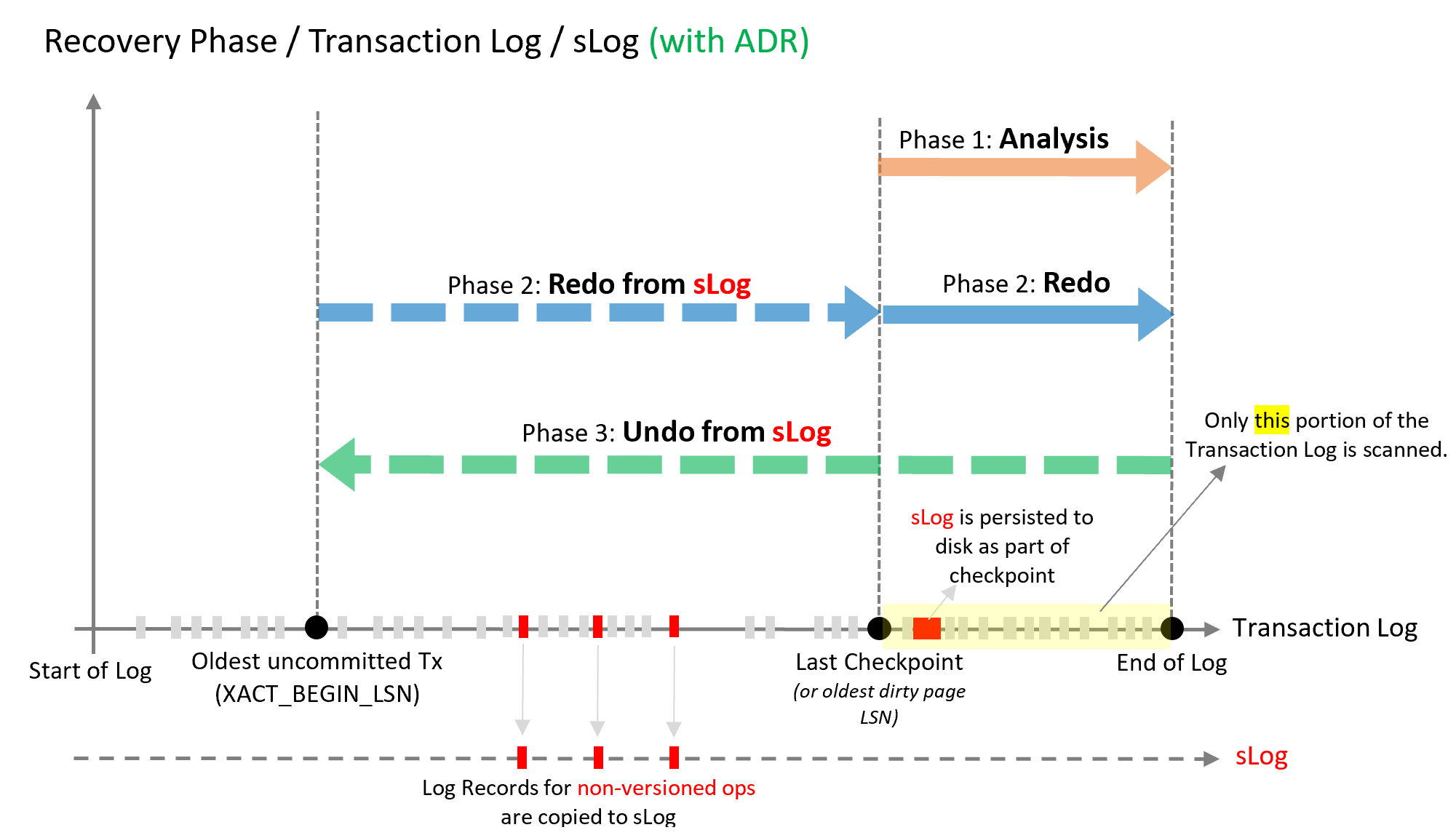
Phase d’analyse
Le processus reste le même qu’avant, avec l’ajout de la reconstruction de sLog et la copie des enregistrements de journal pour les opérations sans version.
Phase de restauration par progression
Divisée en deux phases (P)
Phase 1
Restauration par progression à partir de sLog (de la transaction non validée la plus ancienne jusqu’au dernier point de contrôle). La restauration par progression est une opération rapide, car elle ne doit traiter que quelques enregistrements du sLog.
Phase 2
La restauration par progression à partir du journal des transactions démarre à partir du dernier point de contrôle (au lieu de la transaction non validée la plus ancienne)
Phase d’annulation
Avec ADR, la phase d’annulation se termine quasi instantanément via l’utilisation du sLog pour annuler les opérations sans version et le Magasin de versions persistantes avec le rétablissement logique pour effectuer les annulations basées sur la version au niveau des lignes.
Composants de la récupération de base de données accélérée
Les quatre composants principaux de la récupération de base de données accélérée sont les suivants :
Magasin de versions persistantes
Le magasin de versions persistantes est un nouveau mécanisme du moteur de base de données SQL Server pour conserver les versions des lignes générées dans la base de données elle-même, au lieu du magasin de versions
tempdbtraditionnel. Le magasin de versions persistantes permet l’isolement des ressources et améliore la disponibilité des bases de données secondaires accessibles en lecture.Rétablissement logique
Le rétablissement logique est le processus asynchrone responsable de l’exécution des annulations basées sur la version au niveau de la ligne, qui permet l’annulation instantanée des transactions et l’annulation des opérations avec version. La restauration logique s’effectue en :
- assurant le suivi de toutes les transactions abandonnées et en les marquant comme invisibles pour d’autres transactions ;
- exécutant une restauration par PVS pour toutes les transactions utilisateurs, plutôt que d’analyser physiquement le journal des transactions et d’annuler les modifications une par une ;
- libérant tous les verrous juste après l’abandon de la transaction. Étant donné que l’abandon implique simplement le marquage des modifications en mémoire, le processus est très efficace et il n’est pas nécessaire de maintenir longtemps les verrous.
sLog
sLog est un flux de journal en mémoire secondaire qui stocke des enregistrements de journal pour les opérations sans version (comme l’invalidation du cache de métadonnées, les acquisitions de verrou, etc.). Le sLog présente les caractéristiques suivantes :
- Il est de faible volume et en mémoire.
- Il est conservé sur disque en étant sérialisé pendant le processus de point de contrôle.
- Il est tronqué régulièrement à mesure que les transactions sont validées.
- Il accélère les opérations de restauration par progression et d’annulation en traitant seulement les opérations non versionnées.
- Il permet la troncation agressive du journal des transactions en conservant seulement les enregistrements nécessaires du journal.
Nettoyeur
Le nettoyeur est le processus asynchrone qui sort de veille régulièrement et nettoie les versions des pages qui ne sont pas nécessaires.
Modèles de récupération de base de données accélérée (ADR)
Les types de charges de travail suivants tirent le meilleur parti d’ADR :
- ADR est recommandé pour les charges de travail avec des transactions de longue durée.
- ADR est recommandé pour les charges de travail qui ont rencontré des cas où des transactions actives provoquent une augmentation significative du journal des transactions.
- ADR est recommandé pour les charges de travail qui ont connu de longues périodes d’indisponibilité d’une base de données en raison d’une récupération de longue durée (par exemple, pour un redémarrage de service inattendu ou une restauration de transaction manuelle).
Meilleures pratiques pour la récupération de base de données accélérée
Évitez les transactions de longue durée dans la base de données. Bien qu’un objectif de la fonctionnalité ADR consiste à accélérer la récupération de la base de données en raison de transactions longues actives, les transactions de longue durée peuvent retarder le nettoyage de la version et augmenter la taille du PVS.
Évitez les transactions volumineuses avec des modifications de la définition de données ou des opérations DDL. La fonctionnalité ADR utilise un mécanisme de flux de journal système (SLOG, system log stream) pour effectuer le suivi des opérations DDL utilisées dans la récupération. Le SLOG n’est utilisé que pendant que la transaction est active. Le SLOG fait l’objet d’un point de contrôle, c’est pourquoi le fait d’éviter les transactions volumineuses qui utilisent SLOG peut améliorer les performances globales. Ces scénarios peuvent amener le SLOG à occuper davantage d’espace :
De nombreux DDL sont exécutés dans une seule transaction. Par exemple, dans une seule transaction, la création et la suppression rapides de tables temporaires.
Une table comporte un très grand nombre de partitions/index qui sont modifiés. Par exemple, une opération DROP TABLE sur une telle table nécessiterait une grande réservation de mémoire SLOG, ce qui retarderait la troncation du journal des transactions, ainsi que les opérations d’annulation/de rétablissement. La solution de contournement peut consister à supprimer les index individuellement et progressivement, puis à supprimer la table. Pour plus d’informations sur SLOG, consultez Composants de la récupération de base de données accélérée.
Empêchez ou réduisez les situations abandonnées inutiles. Un taux d’abandon élevé entraîne une pression sur le nettoyeur du PVS et une baisse des performances de la fonctionnalité ADR. Les abandons peuvent être dus à un taux élevé de blocages, des clés dupliquées ou d’autres violations de contrainte.
La vue DMV
sys.dm_tran_aborted_transactionsaffiche toutes les transactions abandonnées sur l’instance SQL Server. La colonnenested_abortindique que la transaction est validée, mais qu’il existe des parties abandonnées (points de sauvegarde ou transactions imbriquées) qui peuvent bloquer le processus de nettoyage du PVS. Pour plus d’informations, consultez sys.dm_tran_aborted_transactions (Transact-SQL).Pour activer manuellement le processus de nettoyage du PVS entre les charges de travail ou pendant les fenêtres de maintenance, utilisez
sys.sp_persistent_version_cleanup. Pour plus d’informations, consultez sys.sp_persistent_version_cleanup.
Si vous constatez des problèmes liés à l’utilisation du stockage, à un nombre élevé de transactions abandonnées et à d’autres facteurs, consultez Résolution des problèmes de récupération de base de données accélérée (ADR) sur SQL Server.