Applications intelligentes avec Azure SQL Database
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Cet article fournit une vue d’ensemble de l’utilisation d’options d’intelligence artificielle (IA), telles que OpenAI et des vecteurs, pour créer des applications intelligentes avec Azure SQL Database.
Pour obtenir des échantillons et des exemples, veuillez consulter le référentiel SQL IA Samples.
Regardez cette vidéo de la série Base de données Azure SQL essentials pour obtenir une brève vue d'ensemble de la création d'une application prête pour l'IA :
Vue d’ensemble
Les modèles de langage volumineux (LLMs) permettent aux développeurs de créer des applications basées sur l’IA avec une expérience utilisateur familière.
L’utilisation de LLMs dans les applications apporte une plus grande valeur et une expérience utilisateur améliorée lorsque les modèles peuvent accéder aux données appropriées, au bon moment, à partir de la base de données de votre application. Ce processus est appelé Génération de récupération augmentée (RAG) et Azure SQL Database a de nombreuses fonctionnalités qui prennent en charge ce nouveau modèle, ce qui en fait une base de données intéressante pour créer des applications intelligentes.
Les liens suivants fournissent un exemple de code de différentes options Azure SQL Database pour créer des applications intelligentes :
| Option IA | Description |
|---|---|
| Azure OpenAI | Générez des incorporations pour RAG et intégrez-les à n’importe quel modèle pris en charge par Azure OpenAI. |
| Vecteurs | Découvrez comment stocker et interroger des vecteurs dans Azure SQL Database. |
| Azure AI Search | Utilisez la base de données Azure SQL avec Azure AI Search pour entraîner LLM sur vos données. |
| Applications intelligentes | Découvrez comment créer une solution de bout en bout à l’aide d’un modèle commun qui peut être répliqué dans n’importe quel scénario. |
| Compétences Copilot dans la base de données Azure SQL | Découvrez les expériences assistées par l'IA conçues pour simplifier la conception, l'exploitation, l'optimisation et l'intégrité des applications basées sur la base de données Azure SQL. |
Concepts clés de l’implémentation de RAG avec Azure SQL Database et Azure OpenAI
Cette section inclut les concepts clés essentiels à l’implémentation de RAG avec Azure SQL Database et Azure OpenAI.
Génération augmentée de récupération (RAG)
RAG est une technique qui améliore la capacité du LLM à produire des réponses pertinentes et informatives en récupérant des données supplémentaires provenant de sources externes. Par exemple, RAG peut interroger des articles ou des documents qui contiennent des connaissances spécifiques au domaine liées à la question ou au message de l’utilisateur. Le LLM peut ensuite utiliser ces données récupérées comme référence lors de la génération de sa réponse. Par exemple, un modèle RAG simple utilisant Azure SQL Database peut être :
- Insérer des données dans un table Azure SQL Database.
- Lier la base de données Azure SQL à Azure AI Search.
- Créez un modèle Azure OpenAI GPT4 et connectez-le à Azure AI Search.
- Discutez et posez des questions sur vos données à l’aide du modèle Azure OpenAI entraîné à partir de votre application et d’Azure SQL Database.
Le modèle RAG, avec l’ingénierie d’invite, a pour but d’améliorer la qualité de la réponse en offrant des informations plus contextuelles au modèle. RAG permet au modèle d’appliquer une base de connaissances plus large en incorporant des sources externes pertinentes dans le processus de génération, ce qui aboutit à des réponses plus complètes et mieux fondées. Pour plus d’informations sur les LLMs de mise à la terre, consultez Mise à la terre des LLMs : Microsoft Community Hub.
Invites et ingénierie d’invite
Un message fait référence à des textes ou à des informations spécifiques qui servent d’instruction à un LLM, ou de données contextuelles sur lesquelles le LLM peut s’appuyer. Une invite peut prendre différentes formes, telles qu’une question, une instruction ou même un extrait de code.
Échantillon de requêtes pouvant être utilisées pour générer une réponse en provenance d'un LLM :
- Instructions : fournissent des directives au LLM
- Contenu principal : fournit des informations au LLM pour le traitement
- Exemples : aide à conditionner le modèle à une tâche ou à un processus en particulier
- Signaux : oriente les données de sortie du LLM dans la bonne direction
- Contenu de prise en charge : représente des informations supplémentaires que le LLM peut utiliser pour générer des données de sortie
Le processus de création de bons messages pour un scénario est appelé ingénierie d’invite. Pour plus d’informations sur les messages et les meilleures pratiques pour l’ingénierie d’invites, consultez Azure OpenAI Service.
Jetons
Les jetons sont de petits blocs de texte générés en fractionnant le texte d’entrée en segments plus petits. Ces segments peuvent être des mots ou des groupes de caractères, dont la longueur peut varier d’un caractère unique à un mot entier. Par exemple, le mot hamburger est divisé en jetons tels que ham, buret ger alors qu’un mot court et commun comme pear serait considéré comme un jeton unique.
Dans Azure OpenAI, le texte d’entrée fourni à l’API est transformé en jetons (segmenté). Le nombre total de jetons traités dans une requête API dépend de certains facteurs, tels que la longueur de paramètres de données d’entrée, de sortie et de requête. La quantité de jetons en cours de traitement affecte également le temps de réponse et le débit des modèles. Il existe des limites au nombre de jetons que chaque modèle peut prendre dans une requête/réponse unique d’Azure OpenAI. Pour en savoir plus, consultez Quotas et limites du service Azure OpenAI.
Vecteurs
Les vecteurs sont des tableaux ordonnés de nombres (généralement des floats) qui peuvent représenter des informations sur certaines données. Par exemple, une image peut être représentée comme un vecteur de valeurs de pixels, ou une chaîne de texte peut être représentée sous forme de valeurs vectorielles ou ASCII. Le processus pour transformer les données en vecteur est appelé vectorisation. Pour plus d’informations, consultez Vecteurs.
Incorporations
Les incorporations sont des vecteurs qui représentent des caractéristiques importantes des données. Les incorporations sont souvent apprises à l’aide d’un modèle Deep Learning, et les modèles Machine Learning et IA les utilisent comme fonctionnalités. Les incorporations peuvent également capturer la similarité sémantique entre des concepts similaires. Par exemple, lors de la génération d’une incorporation pour les mots person et human, nous nous attendons à ce que leurs incorporations (représentation vectorielle) soient similaires en valeur, car les mots sont également sémantiquement similaires.
Azure OpenAI propose des modèles pour créer des incorporations à partir de données texte. Le service décompose le texte en jetons et génère des incorporations à l’aide de modèles pré-entraînés par OpenAI. Pour en savoir plus, consultez Création d’incorporations avec Azure OpenAI.
Recherche vectorielle
La recherche vectorielle fait référence au processus de recherche de tous les vecteurs d’un jeu de données qui sont sémantiquement similaires à un vecteur de requête spécifique. Par conséquent, un vecteur de requête pour le mot human recherche dans l’ensemble du dictionnaire des mots sémantiquement similaires, et devrait trouver le mot person comme une correspondance proche. Cette proximité, ou distance, est mesurée à l’aide d’une métrique de similarité telle que la similarité cosinus. Plus les vecteurs sont similaires, plus la distance entre eux est faible.
Imaginez un scénario où vous exécutez une requête sur des millions de documents pour trouver les documents le plus similaires dans vos données. Vous pouvez créer des incorporations pour vos données et effecter une requête des documents à l’aide d’Azure OpenAI. Ensuite, vous pouvez effectuer une recherche vectorielle pour rechercher les documents les plus similaires de votre jeu de données. Toutefois, effectuer une recherche vectorielle sur quelques exemples est assez simple. Effectuer cette même recherche sur des milliers, ou des millions, de points de données devient difficile. Il existe également des compromis entre la recherche exhaustive et les méthodes de recherche approximatives du plus proche voisin (ANN), notamment la latence, le débit, la précision et le coût, qui dépendent des exigences de votre application.
Comme décrit dans les sections suivantes, les vecteurs dans Azure SQL Database peuvent être stockés et interrogés de manière efficace, ce qui permet une recherche exacte du plus proche voisin avec un excellent niveau de performance. Vous n’avez pas à décider entre précision et vitesse : vous pouvez avoir les deux. Le stockage d’incorporations vectorielles en même temps que les données dans une solution intégrée réduit la nécessité de gérer la synchronisation des données et accélère votre délai de commercialisation pour le développement d’applications IA.
Azure OpenAI
L’incorporation est le processus de représentation du monde réel en tant que données. Le texte, les images ou les sons peuvent être convertis en incorporations. Les modèles Azure OpenAI peuvent transformer des informations réelles en incorporations. Les modèles sont disponibles en tant que points de terminaison REST et peuvent donc être facilement consommés à partir d’Azure SQL Database en utilisant la procédure stockée du système sp_invoke_external_rest_endpoint :
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
L’utilisation d’un appel à un service REST pour obtenir des incorporations n’est qu’une des options d’intégration dont vous disposez lors de l’utilisation de SQL Database et d’OpenAI. Vous pouvez autoriser l’un des modèles disponibles à accéder aux données stockées dans Azure SQL Database pour créer des solutions où vos utilisateurs peuvent interagir avec les données, comme l’exemple suivant.
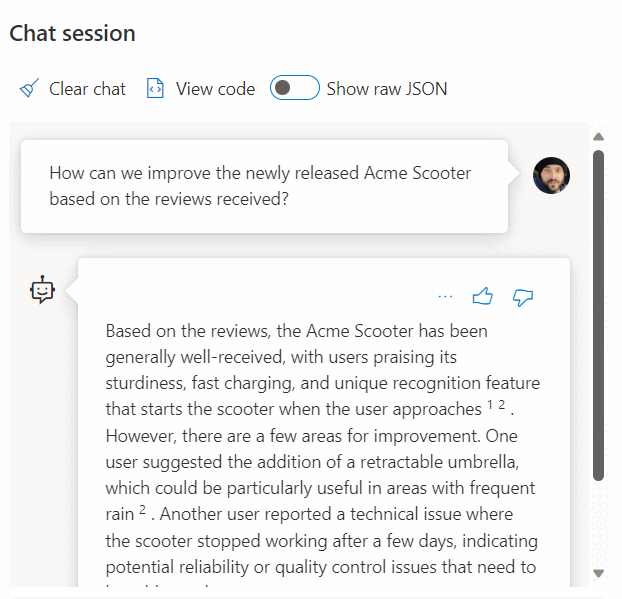
Pour obtenir des exemples supplémentaires sur l’utilisation de SQL Database et d’OpenAI, consultez les articles suivants :
- Générer des images avec Azure OpenAI Service (DALL-E) et Azure SQL Database
- Utilisation de points de terminaison REST OpenAI avec Azure SQL Database
Vecteurs
Type de données vectorielles
En novembre 2024, le nouveau type de données vecteur a été introduit dans Azure SQL Database.
Le type vecteur dédié permet un stockage efficace et optimisé des données vectorielles. Il est fourni avec un ensemble de fonctions qui aident les développeurs à simplifier l’implémentation de la recherche vectorielle et de similarité. Le calcul de la distance entre deux vecteurs peut être effectué en une seule ligne de code à l’aide de la nouvelle fonction VECTOR_DISTANCE. Pour plus d’informations sur le type de données vecteur et les fonctions associées, consultez Vue d’ensemble des vecteurs dans le Moteur de base de données SQL.
Par exemple :
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Vecteurs dans les anciennes versions de SQL Server
Bien que les anciennes versions du moteur SQL Server, jusqu’à SQL Server 2022 inclus, ne disposent pas d’un type vecteur natif, un vecteur n’est rien de plus qu’un tuple ordonné, et les bases de données relationnelles gèrent très bien les tuples. Vous pouvez considérer un tuple comme le terme formel d’une ligne dans une table.
Azure SQL Database prend également en charge les index columnstore et l’exécution en mode batch. Une approche basée sur des vecteurs est utilisée pour le traitement en mode batch, ce qui signifie que chaque colonne d’un lot possède son propre emplacement de mémoire où il est stocké en tant que vecteur. Cela permet un traitement plus rapide et plus efficace des données par lots.
L'exemple suivant montre comment un vecteur peut être stocké dans une base de données SQL Database :
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Pour obtenir un exemple qui utilise un sous-ensemble commun d’articles Wikipédia avec des incorporations déjà générées à l’aide d’OpenAI, consultez Recherche de similarité vectorielle avec Azure SQL Database et OpenAI.
Une autre option pour tirer parti de la recherche vectorielle dans la base de données Azure SQL est l'intégration à Azure AI à l'aide des fonctionnalités de vectorisation intégrées : Recherche vectorielle avec la base de données Azure SQL et Azure AI Search
Recherche Azure AI
Implémentez des modèles RAG avec la base de données Azure SQL et Azure AI Search. Vous pouvez exécuter des modèles de conversation pris en charge sur des données stockées dans base de données Azure SQL, sans avoir à entraîner ou affiner les modèles, grâce à l'intégration de Azure AI Search avec Azure OpenAI et la base de données Azure SQL. L’exécution de modèles sur vos données vous permet de converser par-dessus et d’analyser vos données avec plus de précision et de rapidité.
- Azure OpenAI sur vos données
- RAG (Génération augmentée de récupération) dans Azure AI Search
- Recherche vectorielle avec base de données Azure SQL et Azure AI Search
Applications intelligentes
La base de données Azure SQL peut être utilisée pour créer des applications intelligentes qui incluent des fonctionnalités IA, telles que des générateurs de recommandations et la Génération augmentée de récupération (RAG), comme le montre le diagramme suivant :

Pour obtenir un exemple de bout en bout de construction d'une application basée sur l'IA utilisant l'abrégé des sessions comme échantillon de jeu de données, consultez le site :
- Comment créer un générateur de recommandations de session en 1 heure à l'aide d'OpenAI.
- Utilisation de la génération augmentée pour créer un assistant de session de conférence
Intégration de LangChain
LangChain est une infrastructure bien connue pour le développement d’applications alimentées par des modèles de langage. Pour obtenir des exemples montrant comment utiliser LangChain pour créer un chatbot sur vos propres données, consultez :
- Créer un chatbot sur vos propres données en 1 heure avec Azure SQL, Langchain et Chainlit : créez un chatbot à l’aide du modèle RAG sur vos propres données en utilisant Langchain pour orchestrer les appels LLM et Chainlit pour l’interface utilisateur.
- Création de votre propre copilote de base de données pour Azure SQL avec Azure OpenAI GPT-4 : créez une expérience de type copilote pour interroger vos bases de données à l’aide du langage naturel.
Intégration du noyau sémantique
Le noyau sémantique est un kit de développement logiciel (SDK) open source qui vous permet de créer facilement des agents qui peuvent appeler votre code existant. Le noyau sémantique est un SDK très extensible qui vous permet d'utiliser des modèles d'OpenAI, d'Azure OpenAI, de Hugging Face et bien d'autres encore ! En combinant votre code existant en C#, Python et Java avec ces modèles, vous pouvez créer des agents qui répondent aux questions et automatisent les processus.
- Le chatbot ultime ? : créez un chatbot sur vos propres données en utilisant les modèles NL2SQL et RAG pour fournir une expérience utilisateur ultime.
- Exemple d'incorporations OpenAI : exemple qui montre comment utiliser le noyau sémantique et la mémoire du noyau pour utiliser des incorporations dans une application .NET à l'aide de SQL Server en tant que base de données vectorielle.
- Noyau sémantique et mémoire du noyau – connecteur SQL : fournit une connexion à une SQL Database pour le noyau sémantique des mémoires.
Compétences Microsoft Copilot dans la base de données Azure SQL
Les compétences Microsoft Copilot dans la base de données Azure SQL (Aperçu) est un ensemble d'expériences assistées par l'IA conçues pour simplifier la conception, l'opération, l'optimisation et l'intégrité des applications basées sur la base de données Azure SQL. Copilot peut améliorer la productivité en offrant un langage naturel à la conversion SQL et à l'auto-assistance pour l'administration de base de données.
Copilot propose des réponses pertinentes aux questions des utilisateurs. De plus, il simplifie la gestion de la base de données en exploitant le contexte de la base de données, la documentation, les vues de gestion dynamiques, le magasin de requêtes et d'autres sources de connaissances. Par exemple :
- Les administrateurs de bases de données peuvent gérer les bases de données de manière indépendante. Ils peuvent également résoudre des problèmes ou en savoir plus sur l'analyse des performances et les capacités de leur base de données.
- Les développeurs peuvent poser des questions sur leurs données comme ils le feraient dans un texte ou une conversation pour générer une requête T-SQL. Les développeurs peuvent également apprendre à rédiger des requêtes plus rapidement grâce à des explications détaillées de la requête générée.
Remarque
Les compétences Microsoft Copilot dans la base de données Azure SQL sont actuellement en aperçu pour un nombre restreint d'utilisateurs précoces. Pour vous inscrire à ce programme, consultez Demander l'accès à Copilot dans Azure SQL Database : préversion.
La préversion de Copilot pour la base de données Azure SQL comprend deux expériences du portail Azure :
| Emplacement du portail | Expériences |
|---|---|
| Éditeur de requêtes dans le portail Azure | Langage naturel en SQL : cette expérience au sein de l'éditeur de requête du portail Azure pour la base de données Azure SQL traduit les requêtes en langage naturel en SQL, ce qui rend les interactions de base de données plus intuitives. Pour obtenir un tutoriel et des exemples de capacités de langage naturel vers SQL, consultez Langage naturel en SQL dans l'éditeur de requête du portail Azure (Aperçu). |
| Microsoft Copilot pour Azure | Intégration d'Azure Copilot : cette expérience ajoute des compétences Azure SQL à Microsoft Copilot pour Azure, en proposant aux clients une assistance auto-guidée, ce qui leur permet de gérer leurs bases de données et de résoudre les problèmes indépendamment. |
Pour plus d'informations, consultez Questions fréquentes sur les compétences de Microsoft Copilot dans la base de données Azure SQL (préversion).