Montée en charge avec Azure SQL Database
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Vous pouvez facilement effectuer un scale-out des bases de données d'Azure SQL Database à l'aide des outils de base de données élastique. Ces outils et fonctionnalités vous permettent d’utiliser les ressources d’Azure SQL Database pour créer des solutions pour les charges de travail transactionnelles et notamment les applications Software as a Service (SaaS). Les fonctionnalités de base de données élastique se composent des éléments suivants :
- Bibliothèque de client de base de données élastique : la bibliothèque de client est une fonctionnalité qui vous permet de créer et de gérer des bases de données partitionnées. Voir Prise en main des outils de base de données élastiques.
- Déplacer des données entre bases de données cloud avec scale-out : déplace les données entre des bases de données partitionnées. Cet outil est particulièrement utile pour déplacer des données d’une base de données multilocataire vers une base de données monolocataire (ou inversement). Consultez Déployer un service de fractionnement et de fusion pour déplacer des données entre bases de données partitionnées.
- Tâches élastiques dans Azure SQL Database : Utilisez des tâches pour gérer un grand nombre de bases de données d'Azure SQL Database. Exécutez facilement les opérations administratives telles que les modifications de schéma, la gestion des informations d’identification, les mises à jour de données de référence, la collecte des données de performances ou la collecte télémétrique du client (customer) à l’aide des tâches.
- Vue d’ensemble de la requête élastique Azure SQL Database (préversion) : vous permet d’exécuter une requête Transact-SQL qui s’étend sur plusieurs bases de données. Cela permet une connexion à des outils de création de rapports comme Excel, Power BI, Tableau, etc.
- Transactions distribuées sur plusieurs bases de données cloud : cette fonctionnalité vous permet d’exécuter des transactions qui s’étendent sur plusieurs bases de données. Ces transactions sont disponibles pour les applications .NET utilisant ADO .NET et s’intègrent à une expérience de programmation familière basée sur les classes System.Transaction.
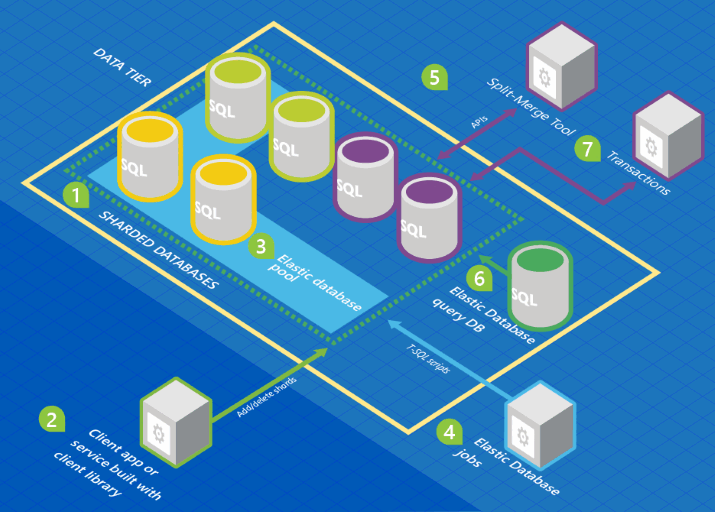
L’illustration ci-dessous montre une architecture qui inclut les fonctionnalités de base de données élastique liées à une collection de bases de données.
Dans ce graphique, les couleurs de la base de données représentent des schémas. Les bases de données de même couleur partagent le même schéma.
- Un ensemble de bases de données SQL est hébergé dans Azure avec une architecture de partitionnement.
- La bibliothèque cliente de base de données élastique sert à gérer un ensemble de partitions.
- Un sous-ensemble de ces bases de données est placé dans un pool élastique.
- Une tâche de base de données élastique exécute des scripts T-SQL sur toutes les bases de données.
- L’ outil de fusion et fractionnement sert à déplacer des données d’une partition à l’autre.
- La requête de base de données élastique vous permet d’écrire une requête qui s’étend sur toutes les bases de données de l’ensemble de partitions.
- Les transactions élastiques vous permettent d’exécuter des transactions qui s’étendent sur plusieurs bases de données.
Pourquoi utiliser les outils ?
Obtenir l’élasticité et l’évolutivité pour les applications cloud est simple pour les machines virtuelles et le stockage d’objets blob. En effet, il suffit d’ajouter ou de soustraire des unités, ou d’augmenter la puissance. Mais cela reste un défi pour le traitement des informations de bases de données relationnelles. Des difficultés sont apparues dans les scénarios suivants :
- Agrandissement et réduction des capacités pour la partie base de données relationnelle de votre charge de travail.
- Gestion des zones réactives susceptibles de survenir et d’affecter un sous-ensemble de données spécifique, comme un client final très occupé (locataire).
Traditionnellement, ces types de scénarios sont résolus en investissant dans des serveurs à plus grande échelle de manière à prendre en charge l'application. Toutefois, cette option est limitée dans le cloud où tous les traitements se produisent sur un matériel prédéfini. La distribution des données et le traitement sur plusieurs bases de données ayant la même structure (un schéma de montée en charge connu sous le terme « partitionnement ») constituent une alternative aux approches traditionnelles de montée en charge, à la fois en matière de coût et d’élasticité.
Mise à l’échelle horizontale et verticale
La figure ci-dessous illustre les dimensions horizontales et verticales de la mise à l'échelle, qui représentent les méthodes de base de mise à l'échelle des bases de données élastiques.

La mise à l’échelle horizontale fait référence à l’ajout ou à la suppression de bases de données afin d’ajuster la capacité ou les performances globales. On parle également de « scale-out ». Le partitionnement, dans lequel les données sont partitionnées sur une collection de bases de données structurées identiques, est un moyen courant d’implémenter la mise à l’échelle horizontale.
La mise à l’échelle verticale fait référence à l’augmentation ou à la réduction de la taille de calcul d’une base de données. Ce processus est également appelé « scale-up ».
La plupart des applications de base de données à l’échelle du cloud associent ces deux stratégies. Par exemple, une application Software as a Service peut utiliser la mise à l’échelle horizontale pour provisionner les nouveaux clients finaux et la mise à l’échelle verticale pour permettre l’augmentation ou la diminution des ressources de la base de données du client final, en fonction des besoins de la charge de travail.
- La mise à l’échelle horizontale est gérée à l’aide de la bibliothèque cliente de base de données élastique.
- La mise à l’échelle verticale est effectuée à l’aide des applets de commande Azure PowerShell pour modifier le niveau de service, ou en plaçant des bases de données dans un pool élastique.
Partitionnement
Le partitionnement est une technique permettant de distribuer de grandes quantités de données structurées de façon identique entre plusieurs bases de données indépendantes. Il est particulièrement populaire auprès des développeurs cloud qui créent des offres Software as a Service (SAAS) pour les clients finaux ou les entreprises. Ces clients finaux sont souvent appelés « locataires ». Le partitionnement peut être nécessaire pour plusieurs raisons :
- La quantité totale de données est trop importante pour respecter les contraintes d’une base de données individuelle
- Le débit des transactions de la charge de travail globale dépasse les capacités d’une base de données individuelle
- Les locataires peuvent nécessiter une isolation physique l'un de l'autre, donc des bases de données distinctes sont nécessaires pour chaque locataire
- Différentes sections d’une base de données peuvent se trouver dans différentes zones géographiques pour des raisons géopolitiques, de performances ou de conformité.
Dans d'autres scénarios, telle la réception de données à partir d'appareils distribués, le partitionnement peut servir à remplir un ensemble de bases de données organisées en fonction du temps. Par exemple, une base de données distincte peut être dédiée à chaque jour ou chaque semaine. Dans ce cas, la clé de partitionnement peut être un entier représentant la date (présente dans toutes les lignes des tables partitionnées) et les requêtes qui retournent des informations pour une plage de dates doivent être acheminées par l’application vers le sous-ensemble de bases de données couvrant la plage en question.
Le partitionnement fonctionne mieux lorsque toutes les transactions d'une application peuvent être limitées à une seule valeur de clé de partitionnement. Cela permet de garantir que toutes les transactions sont locales à une base de données spécifique.
Multilocataire et monolocataire
Certaines applications utilisent l'approche la plus simple consistant à créer une base de données distincte pour chaque locataire. Cette méthode correspond au modèle de partitionnement par locataire, qui offre des fonctionnalités d’isolation, de sauvegarde/restauration et de mise à l’échelle des ressources au niveau de granularité du locataire. Avec le partitionnement par locataire unique, chaque base de données est associée à une valeur d'identifiant de locataire spécifique (ou la valeur de clé du client), mais il n'est pas nécessaire que cette clé soit présente dans les données elles-mêmes. L’application est responsable du routage de chaque demande vers la base de données appropriée, et la bibliothèque cliente peut simplifier cette tâche.

D'autres scénarios regroupent plusieurs locataires dans des bases de données, plutôt que de les isoler dans des bases de données distinctes. Il s’agit d’un modèle type de partitionnement multilocataire. Il peut être nécessaire lorsqu’une application gère un grand nombre de petits locataires. Dans un partitionnement à plusieurs locataires, les lignes des tables de base de données sont toutes conçues pour comporter une clé identifiant l'ID du locataire ou la clé de partitionnement. Là encore, la couche Application est responsable du routage de la demande d’un locataire vers la base de données appropriée et la bibliothèque cliente de base de données élastique peut prendre cette procédure en charge. En outre, le dispositif de sécurité au niveau des lignes peut servir à filtrer les lignes auxquelles chaque locataire peut accéder. Pour plus d’informations, consultez Applications multi-locataires avec des outils de base de données élastique et la sécurité au niveau des lignes. Il peut être nécessaire de redistribuer les données entre les bases de données à l’aide du modèle de partitionnement multilocataire. L’outil de fusion et de fractionnement des bases de données élastiques facilite cette procédure. Pour en savoir plus sur les modèles de conception pour les applications SaaS à l’aide de pools élastiques, consultez Modèles de client de base de données SaaS multilocataires.
Déplacement de données de bases de données à plusieurs locataires vers des bases de données à un seul locataire
Lorsque vous créez une application SaaS, il est courant d'offrir aux clients potentiels une version d'évaluation du logiciel. Dans ce cas, il est plus rentable d'utiliser une base de données à plusieurs locataires pour les données. Toutefois, lorsqu'un prospect devient un client, une base de données à un seul locataire est préférable car elle offre de meilleures performances. Si le client crée des données pendant la période d’évaluation, utilisez l’ outil de fusion et de fractionnement pour déplacer les données de la base de données à plusieurs locataires vers la nouvelle base de données à un seul locataire.
Remarque
La restauration à partir de bases de données multilocataires vers un seul locataire n’est pas possible.
Exemples et tutoriels
Pour obtenir un exemple d’application illustrant la bibliothèque cliente, voir Prise en main des outils de base de données élastique.
Pour convertir des bases de données existantes afin d’utiliser les outils, voir Migration de bases de données existantes pour effectuer un scale-out.
Pour plus de détails sur le pool élastique, consultez Considérations sur les prix et performances pour un pool élastique ou créez un pool à l’aide des pools élastiques.
Contenu connexe
Vous n’utilisez pas encore d’outils de base de données élastique ? Consultez notre Guide de prise en main. Pour toute question, contactez-nous par le biais de la page de questions Microsoft Q&A sur SQL Database et, pour vos demandes de fonctionnalités, ajoutez de nouvelles idées ou votez pour les idées existantes sur le forum de commentaires SQL Database.