Gérer l'espace de fichier des bases de données dans Azure SQL Database
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Cet article décrit les différents types d'espace de stockage disponibles pour les bases de données dans Azure SQL Database, ainsi que les étapes à suivre lorsque l'espace de fichier alloué doit être explicitement géré.
Vue d’ensemble
Avec Azure SQL Database, il existe des modèles de charge de travail dans lesquels l’allocation des fichiers de données sous-jacents aux bases de données peut dépasser le nombre de pages de données utilisées. Ce scénario peut se produire quand l’espace utilisé augmente et que des données sont ensuite supprimées. La raison en est que l’espace de fichiers alloué n’est pas récupéré automatiquement quand des données sont supprimées.
La supervision de l’utilisation de l’espace de fichiers et la réduction des fichiers de données peuvent être nécessaires dans les scénarios suivants :
- Autoriser la croissance des données dans un pool élastique quand l’espace de fichiers alloué pour ses bases de données atteint la taille maximale du pool.
- Autoriser la réduction de la taille maximale d’une base de données unique ou d’un pool élastique.
- Autoriser la modification d’une base de données unique ou d’un pool élastique pour les faire passer à un niveau de service ou à un niveau de performance avec une taille maximale inférieure.
Notes
Les opérations de réduction ne doivent pas être considérées comme une opération de maintenance régulière. Les fichiers de données et les fichiers journaux qui augmentent en raison d’opérations d’entreprise périodiques régulières ne nécessitent pas d’opérations de réduction.
Surveiller l’utilisation de l’espace de stockage des fichiers
La plupart des métriques d’espace de stockage affichées dans les API suivantes mesurent seulement la taille des pages de données utilisées :
- API de métriques basées sur Azure Resource Manager dont l’API get-metrics PowerShell
Cependant, les API suivantes mesurent aussi la taille de l’espace alloué pour les bases de données et les pools élastiques :
- T-SQL: sys.resource_stats
- T-SQL : sys.elastic_pool_resource_stats
Appréhender les types d’espace de stockage d’une base de données
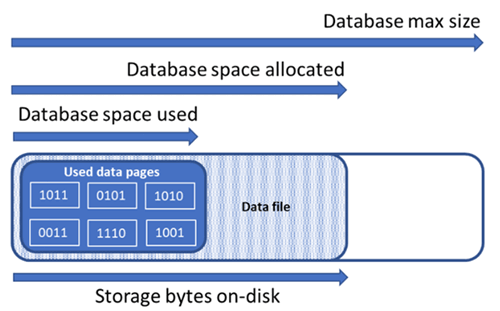
Il est essentiel d’appréhender les quantités d’espace de stockage suivantes pour gérer l’espace de fichier d’une base de données.
| Quantité pour une base de données | Définition | Commentaires |
|---|---|---|
| Espace de données utilisé | Quantité d’espace utilisée pour stocker les données de la base de données. | En général, l’espace utilisé augmente (diminue) lors des insertions (suppressions). Dans certains cas, l’espace utilisé ne change pas lors des insertions ou suppressions selon la quantité et le modèle des données impliquées dans l’opération et dans toute fragmentation éventuelle. Par exemple, la suppression d’une ligne dans chaque page de données ne diminue pas forcément l’espace utilisé. |
| Espace de données alloué | La quantité d’espace de fichiers formatés mise à disposition pour stocker les données de la base de données. | La quantité d’espace allouée augmente automatiquement, mais ne diminue jamais après les suppressions. Ce comportement garantit que les insertions ultérieures seront plus rapides, car l’espace n’aura pas besoin d’être reformaté. |
| Espace de données alloué mais non utilisé | La différence entre la quantité d’espace de données allouée et la quantité d’espace de données utilisée. | Cette quantité représente la quantité maximale d’espace libre qui peut être récupérée par la réduction des fichiers de données de la base de données. |
| Taille maximale des données | La quantité maximale d’espace qui peut être utilisée pour le stockage des données de la base de données. | La quantité d’espace de données allouée ne peut pas croître au-delà de la taille maximale des données. |
Le schéma suivant illustre la relation entre les différents types d’espace de stockage d’une base de données.
Interroger une base de données unique pour des informations relatives à l’espace de stockage des fichiers
Utilisez la requête suivante sur sys.database_files pour retourner la quantité d’espace de données allouée de la base de données et la quantité d’espace alloué non utilisé. Le résultat de la requête est exprimé en Mo.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Appréhender les types d’espace de stockage d’un pool élastique
Il est essentiel d’appréhender les quantités d’espace de stockage suivantes pour gérer l’espace de fichier d’un pool élastique.
| Quantité pour un pool élastique | Définition | Commentaires |
|---|---|---|
| Espace de données utilisé | L’espace de données total utilisé par toutes les bases de données dans le pool élastique. | |
| Espace de données alloué | L’espace de données total alloué par toutes les bases de données dans le pool élastique. | |
| Espace de données alloué mais non utilisé | La différence entre la quantité d’espace de données allouée et la quantité d’espace de données utilisée par toutes les bases de données dans le pool élastique. | Cette quantité représente la quantité maximale d’espace alloué au pool élastique qui peut être récupérée par la réduction des fichiers de données de la base de données. |
| Taille maximale des données | La quantité maximale d’espace de données qui peut être utilisée par le pool élastique pour toutes ses bases de données. | L’espace alloué au pool élastique ne doit pas dépasser la taille maximale du pool élastique. Si cette condition se produit, l’espace alloué qui n’est pas utilisé peut être récupéré en réduisant les fichiers de données de la base de données. |
Remarque
Le message d’erreur « Le pool élastique a atteint sa limite de stockage » indique que suffisamment d’espace a été alloué aux objets de base de données pour respecter la limite de stockage du pool élastique, mais qu’il peut y avoir de l’espace inutilisé dans l’allocation de l’espace de données. Envisagez d’augmenter la limite de stockage du pool élastique ou, comme solution à court terme, de libérer de l’espace de données à l’aide des modèles présentés dans la section Récupérer l’espace alloué non utilisé. Vous devez également tenir compte du possible impact négatif sur les performances que peut avoir la réduction des fichiers de la base de données. Consultez la section Maintenance des index après réduction.
Interroger un pool élastique pour des informations relatives à l’espace de stockage
Les requêtes suivantes peuvent être utilisées pour déterminer les quantités d’espace de stockage d’un pool élastique.
Espace de données du pool élastique utilisé
Modifiez la requête suivante pour retourner la quantité d’espace de données du pool élastique utilisée. Le résultat de la requête est exprimé en Mo.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Espace de données alloué et espace alloué non utilisé du pool élastique
Modifiez les exemples suivants pour retourner une table listant l’espace alloué et l’espace alloué non utilisé pour chaque base de données d’un pool élastique. La table trie les bases de données en commençant par celles qui ont la plus grande quantité d’espace alloué non utilisé jusqu’à celles qui en ont la plus petite quantité. Le résultat de la requête est exprimé en Mo.
Les résultats de requête permettant de déterminer l’espace alloué à chaque base de données dans le pool peuvent être cumulés pour déterminer l’espace total alloué au pool élastique. L’espace de pool élastique alloué ne doit pas dépasser la taille maximale du pool élastique.
Important
Le module PowerShell Azure Resource Manager est toujours pris en charge par Azure SQL Database, mais tous les développements futurs sont destinés au module Az.Sql. Le module AzureRM continue à recevoir des résolutions de bogues jusqu’à au moins décembre 2020. Les arguments des commandes dans le module Az sont sensiblement identiques à ceux des modules AzureRm. Pour en savoir plus sur leur compatibilité, consultez Présentation du nouveau module Az Azure PowerShell.
Le script PowerShell nécessite le module SQL Server PowerShell. Pour l’installer, consultez Télécharger le module PowerShell.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
La capture d’écran suivante est un exemple de sortie du script :

Taille maximale des données du pool élastique
Modifiez la requête T-SQL suivante pour retourner la dernière taille maximale enregistrée des données du pool élastique. Le résultat de la requête est exprimé en Mo.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Récupérer l’espace alloué non utilisé
Important
Les commandes de réduction ont un impact sur les performances de la base de données pendant l’exécution et, si possible, doivent être exécutées pendant les périodes de faible utilisation.
Réduire les fichiers de données
En raison d’un impact potentiel sur les performances de la base de données, la Base de données Azure SQL ne réduit pas automatiquement les fichiers de données. Cependant, les clients peuvent réduire les fichiers de données via une opération en libre-service quand ils le souhaitent. Cela ne doit pas être une opération planifiée régulièrement, mais plutôt un événement à usage unique en réponse à une réduction majeure de la consommation d’espace utilisée par le fichier de données.
Conseil
Il n’est pas recommandé de réduire les fichiers de données si la charge de travail normale de l’application entraîne une nouvelle augmentation pour atteindre la même taille allouée.
Dans Azure SQL Database, pour réduire les fichiers, vous pouvez utiliser les commandes DBCC SHRINKDATABASE ou DBCC SHRINKFILE :
DBCC SHRINKDATABASEréduit tous les fichiers de données et tous les fichiers journaux d’une base de données à l’aide d’une seule commande. La commande réduit un fichier de données à la fois, ce qui peut prendre beaucoup de temps pour les bases de données volumineuses. Elle permet également de réduire le fichier journal, ce qui est généralement inutile parce qu’Azure SQL Database réduit les fichiers journaux automatiquement si nécessaire.- La commande
DBCC SHRINKFILEprend en charge des scénarios plus avancés :- Elle peut cibler des fichiers individuels en fonction des besoins, au lieu de réduire tous les fichiers de la base de données.
- Chaque commande
DBCC SHRINKFILEpeut s’exécuter en parallèle avec d’autres commandesDBCC SHRINKFILEpour réduire plusieurs fichiers à la fois et raccourcir la durée totale de la réduction, au détriment d’une utilisation plus élevée des ressources avec un risque plus grand de blocage des requêtes utilisateur, si elles s’exécutent pendant la réduction.- La réduction simultanée de plusieurs fichiers de données vous permet d’effectuer l’opération de réduction plus rapidement. Si vous utilisez la réduction simultanée de fichiers de données, vous pourriez observer un blocage temporaire d’une demande de réduction par une autre.
- Si la fin du fichier ne contient pas de données, cela peut réduire la taille de fichier allouée beaucoup plus rapidement en spécifiant l’argument
TRUNCATEONLY. Cela ne nécessite pas le déplacement des données dans le fichier.
- Pour plus d’informations sur ces commandes de réduction, consultez DBCC SHRINKDATABASE et DBCC SHRINKFILE.
- Les opérations de réduction de base de données et de fichiers sont prises en charge en préversion pour Azure SQL Database Hyperscale. Pour en savoir plus, consultez Réduction pour Azure SQL Database Hyperscale.
Les exemples suivants doivent être exécutés lors d’une connexion à la base de données utilisateur cible, et non à la master base de données.
Pour utiliser DBCC SHRINKDATABASE pour réduire l’ensemble des données et des fichiers journaux dans une base de données spécifique :
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
Dans Azure SQL Database, une base de données peut avoir un ou plusieurs fichiers de données, créés automatiquement à mesure que les données augmentent. Pour déterminer la disposition des fichiers de votre base de données, y compris la taille utilisée et allouée de chaque fichier, interrogez la vue catalogue sys.database_files en utilisant l’exemple de script suivant :
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Vous pouvez exécuter une réduction sur un fichier uniquement avec la commande DBCC SHRINKFILE, par exemple :
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Tenez compte du possible impact négatif sur les performances que peut avoir la réduction des fichiers de la base de données. Consultez la section Maintenance des index après réduction.
Réduire le fichier journal de transactions
Contrairement aux fichiers de données, Azure SQL Database réduit automatiquement le fichier journal de transactions afin d’éviter une utilisation excessive de l’espace, qui peut entraîner des erreurs d’insuffisance d’espace. Il n’est généralement pas nécessaire pour les clients de réduire le fichier journal de transactions.
Dans les niveaux de service Premium et Critique pour l’entreprise, si le journal de transactions devient volumineux, il peut contribuer considérablement à la l’utilisation du stockage local jusqu’à la limite de stockage local maximal. Si l’utilisation du stockage local est proche de la limite, les clients peuvent choisir de réduire le journal des transactions à l’aide de la commande DBCC SHRINKFILE, comme dans l’exemple suivant. Cela libère le stockage local dès la fin de la commande, sans attendre l’opération de réduction automatique périodique.
Les exemples suivants doivent être exécutés lors d’une connexion à la base de données utilisateur cible, et non à la base de données master.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Réduction automatique
Comme alternative à la réduction manuelle des fichiers de données, la réduction automatique peut être activée pour une base de données. Cependant, elle peut être moins efficace pour récupérer de l’espace de fichiers que DBCC SHRINKDATABASE et DBCC SHRINKFILE.
Par défaut, la réduction automatique est désactivée, ce qui est recommandé pour la plupart des bases de données. S’il est nécessaire d’activer la réduction automatique, il est recommandé de la désactiver une fois les objectifs de gestion de l’espace atteints, au lieu de la conserver indéfiniment. Pour plus d’informations, consultez Considérations relatives à AUTO_SHRINK.
Par exemple, la réduction automatique peut être utile dans un scénario spécifique où un pool élastique contient de nombreuses bases de données qui subissent une augmentation et une réduction significatives de l’espace utilisé pour les fichiers de données, et du coup s’approche de sa limite de taille maximale. Ce scénario n’est pas très courant.
Pour activer la réduction automatique, exécutez la commande suivante en étant connecté à votre base de données (et non à la base de données master).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Pour plus d’informations sur cette commande, consultez les options de DATABASE SET.
Maintenance des index après réduction
Une fois que l’opération de réduction est effectuée sur les fichiers de données, les index peuvent devenir fragmentés. Cela réduit l’efficacité de l’optimisation des performances pour certaines charges de travail, comme les requêtes qui utilisent de grandes analyses. Si la dégradation des performances se produit une fois l’opération de réduction terminée, envisagez la maintenance des index pour reconstruire les index. N’oubliez pas que les reconstructions d’index demandent de l’espace libre dans la base de données, ce qui peut entraîner une augmentation de l’espace alloué et donc un affaiblissement de l’effet de réduction.
Pour plus d’informations sur la maintenance des index, consultez Optimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources.
Réduire les grandes bases de données
Lorsque l’espace alloué à la base de données se compte en centaines de gigaoctets ou plus, la réduction peut prendre un temps considérable qui se mesure souvent en heures ou en jours pour les bases de données de plusieurs To. Vous pouvez utiliser des optimisations de processus et des bonnes pratiques pour rendre ce processus plus efficace et moins impactant sur les charges de travail des applications.
Capturer une base de référence de l’utilisation de l’espace
Avant de commencer la réduction, capturez l’espace utilisé et alloué actuel dans chaque fichier de base de données en exécutant la requête d’utilisation d’espace suivante :
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Une fois que la réduction est terminée, vous pouvez réexécuter cette requête et comparer le résultat à la base de référence initiale.
Tronquer les fichiers de données
Il est recommandé d’effectuer d’abord la réduction de chaque fichier de données avec le paramètre TRUNCATEONLY. Ainsi, s’il y a de l’espace alloué mais inutilisé à la fin du fichier, il est supprimé rapidement et sans aucun déplacement des données. L’exemple de commande suivant tronque le fichier de données avec file_id 4 :
DBCC SHRINKFILE (4, TRUNCATEONLY);
Une fois que cette commande est exécutée pour chaque fichier de données, vous pouvez réexécuter la requête d’utilisation d’espace pour voir la réduction de l’espace alloué, le cas échéant. Vous pouvez également voir l’espace alloué pour la base de données dans le portail Azure.
Évaluer la densité des pages d’index
Si la troncation des fichiers de données n’entraîne pas une réduction suffisante de l’espace alloué, vous devrez réduire les fichiers de données. Toutefois, à titre d’étape facultative mais recommandée, vous devez d’abord déterminer la densité moyenne des pages des index dans la base de données. Pour une même quantité de données, la réduction est plus rapide si la densité des pages est élevée parce qu’elle devra déplacer moins de pages. Si la densité des pages est faible pour certains index, effectuez une maintenance sur ces index pour augmenter la densité des pages avant de réduire les fichiers de données. Cela permet également d’obtenir une réduction plus profonde de l’espace de stockage alloué.
Pour déterminer la densité des pages de tous les index de la base de données, utilisez la requête suivante. La densité des pages est signalée dans la colonne avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Si vous avez des index avec un nombre de pages élevé et avec une densité de page inférieure à 60-70 %, prévoyez de reconstruire ou de réorganiser ces index avant de réduire les fichiers de données.
Remarque
Pour les grandes bases de données, la requête pour déterminer la densité de page peut prendre un certain temps (plusieurs heures). De plus, la reconstruction ou la réorganisation de grands index demandent aussi un temps et une utilisation des ressources considérables. Il existe un compromis entre le temps passé à augmenter la densité des pages d’un côté et le raccourcissement de la durée et l’obtention de plus d’espace de l’autre.
Si vous avez plusieurs index avec une faible densité de page, vous pourrez peut-être les reconstruire en parallèle sur plusieurs sessions de base de données pour accélérer le processus. Assurez-vous toutefois de ne pas vous approcher des limites des ressources de base de données en le faisant, et laissez suffisamment de marge pour les charges de travail d’application susceptibles d’être en cours d’exécution. Surveillez la consommation des ressources (processeur, E/S de données, E/S de journal) dans le portail Azure ou en utilisant la vue sys.dm_db_resource_stats et démarrez d’autres reconstructions en parallèle seulement si l’utilisation des ressources sur chacune de ces dimensions reste considérablement inférieure à 100 %. Si l’utilisation du processeur, des E/S de données et des E/S de journal est à 100 %, vous pouvez effectuer un scale-up de la base de données pour avoir plus de cœurs de processeur et augmenter le débit des E/S. Cela peut vous permettre d’avoir d’autres reconstructions en parallèle pour effectuer le processus plus vite.
Exemple de commande de reconstruction d’index
Voici un exemple de commande pour reconstruire un index et augmenter la densité de ses pages, en utilisant l’instruction ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Cette commande lance une reconstruction d’index en ligne et reprenable. Cela permet aux charges de travail simultanées de continuer à utiliser la table pendant la reconstruction, et à vous de reprendre la reconstruction en cas d’interruption pour une raison ou une autre. Toutefois, ce type de reconstruction est plus lent qu’une reconstruction hors connexion, qui bloque l’accès à la table. Si aucune autre charge de travail n’a besoin d’accéder à la table pendant la reconstruction, définissez les options ONLINE et RESUMABLE sur OFF pour supprimer la clause WAIT_AT_LOW_PRIORITY.
Pour en savoir plus sur la maintenance des index, consultez Optimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources.
Réduire plusieurs fichiers de données
Comme indiqué précédemment, une réduction avec un déplacement des données est un processus de longue haleine. Si la base de données contient plusieurs fichiers de données, vous pouvez accélérer le processus en réduisant plusieurs fichiers de données en parallèle. Pour ce faire, vous devez ouvrir plusieurs sessions de base de données et utiliser DBCC SHRINKFILE sur chaque session avec une valeur file_id différente. Tout comme avec la reconstruction des index vue précédemment, assurez-vous d’avoir suffisamment de marge de ressources (processeur, E/S de données, E/S de journal) avant de commencer chaque nouvelle commande de réduction parallèle.
L’exemple de commande suivant réduit le fichier de données avec file_id 4, en cherchant à réduire la taille allouée à 52 000 Mo tout en déplaçant les pages au sein du fichier :
DBCC SHRINKFILE (4, 52000);
Si vous voulez réduire au minimum possible l’espace alloué au fichier, exécutez l’instruction sans spécifier la taille cible :
DBCC SHRINKFILE (4);
Si une charge de travail s’exécute en même temps qu’une réduction, elle peut commencer à utiliser l’espace de stockage libéré par la réduction avant que la réduction ne se termine et tronque le fichier. Dans ce cas, la réduction ne peut pas réduire l’espace alloué à la cible spécifiée.
Vous pouvez atténuer cela en réduisant chaque fichier en plus petites étapes. Cela signifie que dans la commande DBCC SHRINKFILE, vous définissez une cible légèrement plus petite que l’espace actuellement alloué au fichier, comme le montrent les résultats de la requête d’utilisation d’espace de référence. Par exemple, si l’espace alloué à un fichier avec file_id 4 est de 200 000 Mo et que vous voulez le réduire à 100 000 Mo, vous pouvez d’abord définir la cible sur 170 000 Mo :
DBCC SHRINKFILE (4, 170000);
Une fois cette commande terminée, elle aura tronqué le fichier et réduit sa taille allouée à 170 000 Mo. Vous pouvez ensuite répéter cette commande, en définissant d’abord la cible sur 140 000 Mo, puis sur 110 000 Mo, etc., jusqu’à ce que le fichier soit réduit à la taille souhaitée. Si la commande se termine mais que le fichier n’est pas tronqué, utilisez des étapes plus petites, par exemple 15 000 Mo au lieu de 30 000 Mo.
Pour surveiller la progression de la réduction de toutes les sessions de réduction exécutées en simultané, vous pouvez utiliser la requête suivante :
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Remarque
La progression de la réduction peut être non linéaire et la valeur de la colonne percent_complete peut rester pratiquement inchangée pendant de longues périodes, même si la réduction est toujours en cours.
Une fois que la réduction de tous les fichiers de données est exécutée, réexécutez la requête d’utilisation d’espace (ou consultez le portail Azure) pour déterminer la réduction résultante de la taille de stockage allouée. Si la différence entre l’espace utilisé et l’espace alloué reste importante, vous pouvez reconstruire les index comme décrit précédemment. Cela peut augmenter temporairement l’espace alloué. Toutefois, une nouvelle réduction des fichiers de données après la reconstruction des index devrait aboutir à une réduction plus profonde de l’espace alloué.
Erreurs temporaires lors de la réduction
Parfois, une commande de réduction peut échouer avec diverses erreurs telles que des expirations de délai ou des interblocages. En règle générale, ces erreurs sont temporaires et ne se représentent pas si la même commande est répétée. Si la réduction échoue avec une erreur, la progression qu’elle a faite jusqu’ici dans le déplacement des pages de données est conservée et la même commande de réduction peut être réexécutée pour continuer à réduire le fichier.
L’exemple de script suivant montre comment effectuer une réduction dans une boucle de nouvelle tentative pour réessayer automatiquement jusqu’à un nombre configurable de fois lorsqu’une erreur d’expiration de délai ou une erreur d’interblocage se produit. Cette approche de nouvelle tentative s’applique à de nombreuses autres erreurs qui peuvent se produire pendant la réduction.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
En plus des expirations de délai et des interblocages, la réduction peut rencontrer des erreurs dues à certains problèmes connus.
Les erreurs retournées et les étapes de contournement sont les suivantes :
- Numéro d’erreur : 49503, message d’erreur : %.*ls : Impossible de déplacer la page %d:%d car il s’agit d’une page de banque de versions persistante hors ligne. Raison du retard de la page : %ls. Horodatage du retard de la page : %l64d.
Cette erreur se produit lorsqu’il existe de longues transactions actives qui ont généré des versions de ligne dans la banque de versions persistante (PVS, persistent version store). Les pages contenant ces versions de ligne ne peuvent pas être déplacées par une réduction, laquelle ne peut pas poursuivre et échoue avec cette erreur.
Pour contourner le problème, vous devez attendre la fin de ces longues transactions. Vous pouvez également identifier et mettre fin à ces longues transactions, mais cela peut avoir un impact sur votre application si elle ne gère pas correctement les échecs de transaction. Pour rechercher des transactions longues, vous pouvez, entre autres, exécuter la requête suivante dans la base de données dans laquelle vous avez exécuté la commande de réduction :
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Vous pouvez mettre fin à une transaction à l’aide de la commande KILL et spécifier la valeur session_id associée à partir du résultat de la requête :
KILL 4242; -- replace 4242 with the session_id value from query results
Attention
Mettre fin à une transaction peut avoir un impact négatif sur les charges de travail.
Une fois que vous avez mis fin aux transactions longues ou qu’elles sont terminées, une tâche en arrière-plan interne nettoie les versions de ligne qui ne sont plus nécessaires passé un certain temps. Vous pouvez surveiller la taille de la banque de versions persistante pour évaluer la progression du nettoyage à l’aide de la requête suivante. Exécutez la requête dans la base de données dans laquelle vous avez exécuté la commande de réduction :
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Une fois que la taille de la banque de versions persistante signalée dans la colonne persistent_version_store_size_gb est considérablement réduite par rapport à sa taille d’origine, la réexécution de la réduction devrait aboutir.
- Numéro de version : 5223, message d’erreur : %.*ls : Impossible de libérer la page vide %d:%d.
Cette erreur peut se produire si des opérations de maintenance d’index sont en cours, telles que ALTER INDEX. Réessayez la commande de réduction une fois ces opérations terminées.
Si cette erreur persiste, l’index associé risque de devoir être reconstruit. Pour rechercher l’index à reconstruire, exécutez la requête suivante dans la même base de données où vous avez exécuté la commande de réduction :
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Avant d’exécuter cette requête, remplacez les espaces réservés <file_id> et <page_id> par les valeurs réelles du message d’erreur que vous avez reçu. Par exemple, si le message est Impossible de libérer la page vide 1:62669, <file_id> est 1 et <page_id> est 62669.
Reconstruisez l’index identifié par la requête, puis réessayez la commande de réduction.
- Numéro d’erreur : 5201, message d’erreur : DBCC SHRINKDATABASE : le fichier ID %d de la base de données ID %d a été ignoré, parce qu’il n’a pas assez d’espace disponible à récupérer.
Cette erreur signifie que le fichier de données ne peut pas être réduit davantage. Vous pouvez passer au fichier de données suivant.
Contenu connexe
Pour plus d’informations sur les tailles maximales de base de données, consultez :
- Limites du modèle d’achat vCore Azure SQL Database pour une base de données unique
- Limites de ressources pour des bases de données uniques suivant le modèle d’achat DTU
- Limites du modèle d’achat vCore Azure SQL Database pour les pools élastiques
- Limites de ressources pour des pools élastiques suivant le modèle d’achat DTU