Tutoriel : configurer SQL Data Sync entre des bases de données d'Azure SQL Database et SQL Server
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Important
SQL Data Sync sera mis hors service le 30 septembre 2027. Envisagez de migrer vers d’autres solutions de réplication/synchronisation de données.
Dans ce tutoriel, vous allez apprendre à configurer SQL Data Sync en créant un groupe de synchronisation contenant à la fois des instances d'Azure SQL Database et de SQL Server. Le groupe de synchronisation est configuré de manière personnalisée et se synchronise selon la planification définie.
Ce tutoriel part du principe que vous avez déjà utilisé SQL Database et SQL Server.
Pour une vue d’ensemble de SQL Data Sync, consultez la Présentation de SQL Data Sync pour Azure.
Pour obtenir des exemples PowerShell sur la façon de configurer SQL Data Sync, consultez Utiliser PowerShell pour synchroniser des données entre plusieurs bases de données dans Azure SQL Database ou entre des bases de données d’Azure SQL Database et SQL Server.
La base de données Hub est le point de terminaison central d’une topologie de synchronisation, où un groupe de synchronisation a plusieurs points de terminaison de base de données. Toutes les autres bases de données membres avec des points de terminaison dans le groupe de synchronisation sont synchronisées avec la base de données Hub. SQL Data Sync est pris en charge uniquement sur Azure SQL Database. La base de données Hub doit être une base de données Azure SQL.
L’hyperscale de la base de données Azure SQL est uniquement pris en charge en tant que base de données membre, et non en tant que base de données Hub.
Créer un groupe de synchronisation
Accédez au portail Azure. Recherchez et sélectionnez des bases de données SQL pour rechercher une base de données Azure SQL existante.
Sélectionnez la base de données existante que vous souhaitez utiliser comme base de données Hub pour la synchronisation des données.
Dans le menu de ressource Base de données SQL de la base de données choisie, sous Gestion des données, sélectionnez Synchroniser avec les autres bases de données.
Dans la page Synchroniser avec les autres bases de données, sélectionnez Nouveau groupe de synchronisation. La page Créer un groupe de synchronisation de données s’ouvre également.
Dans la page Créer un groupe de synchronisation de données, configurez les paramètres suivants :

Paramètre Description Nom du groupe de synchronisation Entrez le nom du nouveau groupe de synchronisation. Ce nom est différent du nom de la base de données. Synchroniser la base de données de métadonnées Choisissez de créer une base de données (recommandé) ou d’utiliser une base de données existante pour servir en tant que base de données de métadonnées de synchronisation.
Microsoft recommande de créer une nouvelle base de données vide, à utiliser comme base de données de métadonnées de synchronisation. SQL Data Sync crée les tables dans cette base de données et exécute une charge de travail fréquente. Cette base de données est partagée comme base des métadonnées de synchronisation pour l’ensemble des groupes de synchronisation dans une région et un abonnement sélectionnés. Vous ne pouvez pas modifier la base de données ou son nom sans supprimer tous les groupes de synchronisation et les agents de synchronisation dans la région.
Si vous choisissez de créer une base de données, sélectionnez Nouvelle base de données. Sélectionnez Configuration des paramètres de la base de données. Dans la page Base de données SQL, nommez et configurez une nouvelle base de données Azure SQL, puis sélectionnez OK.
Si vous choisissez Utiliser une base de données existante, sélectionnez la base de données dans la liste déroulante Base de données de métadonnées de synchronisation.Synchronisation automatique Sélectionnez Activé ou Désactivé.
Si vous choisissez Activé, entrez un nombre et sélectionnez Secondes, Minutes, Heures ou Jours dans la section Fréquence de synchronisation.
La première synchronisation commence après que la période d’intervalle sélectionnée se soit écoulée à partir du moment où la configuration est enregistrée.Résolution des conflits Sélectionnez Gain du hub ou Gain du membre.
Gain du hub signifie qu’en cas de conflit, les données de la base de données Hub remplacent les données en conflit de la base de données membre.
Gain du membre signifie qu’en cas de conflit, les données de la base de données membre remplacent les données en conflit de la base de données Hub.Nom d’utilisateur de la base de données Hub et mot de passe de la base de données Hub Fournissez le nom d’utilisateur et le mot de passe à la connexion authentifiée SQL de l’administrateur du serveur pour la base de données Hub. Il s’agit du nom d’utilisateur et du mot de passe de l’administrateur du serveur pour le même serveur logique Azure SQL sur lequel vous avez commencé. L’authentification Microsoft Entra (anciennement Azure Active Directory) n’est pas prise en charge. Utiliser une liaison privée Choisissez un point de terminaison privé managé par le service pour établir une connexion sécurisée entre le service de synchronisation et la base de données Hub. Sélectionnez OK et attendez que le groupe de synchronisation soit créé et déployé.
Dans la page Nouveau groupe de synchronisation, si vous avez sélectionné Utiliser une liaison privée, vous devez approuver la connexion au point de terminaison privé. Le lien dans le message d’informations vous permet d’accéder à l’expérience des connexions au point de terminaison privé, où vous pouvez approuver la connexion.

Remarque
Les liaisons privées du groupe de synchronisation et les membres de synchronisation doivent être créés, approuvés et désactivés séparément.


Ajouter des membres de synchronisation
Une fois le groupe de synchronisation créé et déployé, ouvrez-le et accédez à la page Bases de données, où vous sélectionnez les membres de synchronisation.
Remarque
Pour mettre à jour ou insérer le nom d’utilisateur et le mot de passe dans votre base de données de hub, accédez à la section Base de données de hub de la page Sélectionner les membres de synchronisation.
Ajouter une base de données dans Azure SQL Database en tant que membre à un groupe de synchronisation
Dans la section Sélectionner les membres de synchronisation, vous pouvez ajouter une base de données dans Azure SQL Database au groupe de synchronisation en sélectionnant Ajouter une base de données Azure. La page Configurer une base de données Azure s’ouvre.

Dans la page Configurer Azure SQL Database, changez les paramètres suivants :
Paramètre Description Nom du membre de synchronisation Entrez le nom du nouveau membre de synchronisation. Ce nom est différent de celui de la base de données. Abonnement Sélectionnez l’abonnement Azure associé en vue de la facturation. Azure SQL Server Sélectionnez le serveur existant. Azure SQL Database Sélectionnez la base de données existante dans SQL Database. Sens de la synchronisation La direction de la synchronisation peut être Hub vers membre ou membre vers Hub, ou les deux. Sélectionnez Depuis le Hub, Vers le Hub ou Synchronisation bidirectionnelle. Pour plus d’informations, consultez la section Comment ça marche. Nom d’utilisateur et Mot de passe Entrez les informations d'identification du serveur qui héberge la base de données membre. N’entrez pas de nouvelles informations d’identification dans cette section. Utiliser une liaison privée Choisissez un point de terminaison privé managé par le service pour établir une connexion sécurisée entre le service de synchronisation et la base de données membre. Sélectionnez OK et attendez que le nouveau membre de synchronisation soit créé et déployé.

Ajouter une base de données sur une instance SQL Server en tant que membre à un groupe de synchronisation
Dans la section Base de données membre, ajoutez éventuellement une base de données dans une instance SQL Server au groupe de synchronisation en sélectionnant Ajouter une base de données locale.
Dans la page Configurer localement qui s’ouvre, vous pouvez effectuer les tâches suivantes :
Sélectionnez Choisir la passerelle de l’agent de synchronisation. La page Sélectionner l’agent de synchronisation s’ouvre.
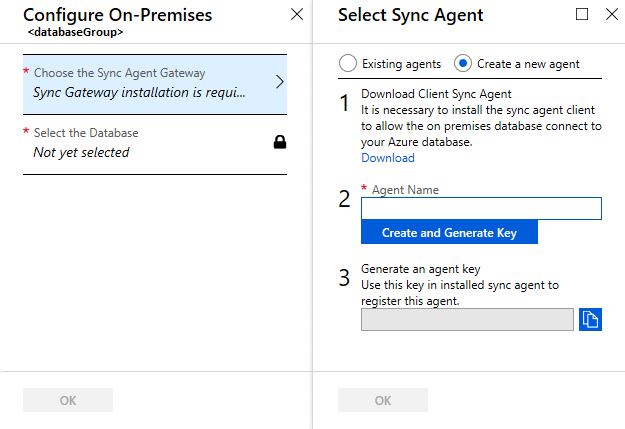
Dans la page Choisir l’agent de synchronisation, choisissez entre utiliser un agent existant ou en créer un.
Si vous choisissez Agents existants, sélectionnez un agent dans la liste.
Si vous choisissez Créer un agent, effectuez les étapes suivantes :
Téléchargez l’agent de synchronisation de données à l’aide du lien fourni et installez-le sur l’ordinateur qui héberge le serveur SQL Server. Vous pouvez également télécharger directement l’agent à partir de Azure SQL Data Sync Agent. Pour connaître les meilleures pratiques relatives à l’agent client de synchronisation, consultez Bonnes pratiques pour Azure SQL Data Sync.
Important
Vous devez ouvrir le port TCP sortant 1433 dans le pare-feu pour permettre à l’agent du client de communiquer avec le serveur.
Entrez un nom d’agent.
Sélectionnez Créer et générer une clé et copiez la clé de l’agent dans le Presse-papiers.
Sélectionnez OK pour fermer la page Sélectionner l’agent de synchronisation.
Sur le serveur sur lequel l’agent client de synchronisation est installé, recherchez et exécutez l’application Agent de synchronisation du client.

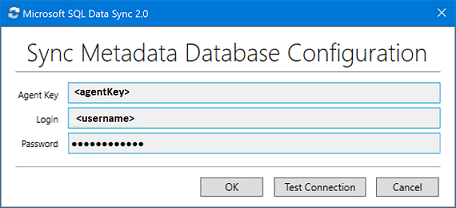
Dans l’application de l’agent de synchronisation, sélectionnez Submit Agent Key (Envoyer la clé de l’agent) . La boîte de dialogue Sync Metadata Database Configuration (Configuration de la base des métadonnées de synchronisation) s’ouvre.
Dans la boîte de dialogue Sync Metadata Database Configuration (Configuration de la base des métadonnées de synchronisation) , collez la clé de l’agent copiée à partir du portail Azure. Indiquez également les informations d’identification du serveur qui héberge la base de données de métadonnées de synchronisation. Sélectionnez OK et attendez la fin de la configuration.
Remarque
Si vous recevez une erreur de pare-feu, créez une règle de pare-feu sur Azure pour autoriser le trafic entrant en provenance de l’ordinateur qui héberge le serveur SQL Server. Vous pouvez créer cette règle manuellement dans le portail ou dans SSMS (SQL Server Management Studio). Dans SSMS, connectez-vous à la base de données Hub sur Azure en entrant son nom au format
<hub_database_name>.database.windows.net.Sélectionnez Inscrire pour inscrire une base de données SQL Server auprès de l’agent. La boîte de dialogue Configuration de SQL Server s’ouvre.
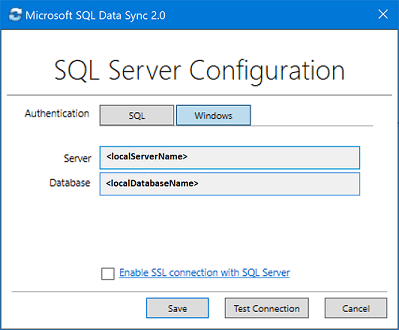
Dans la boîte de dialogue Configuration de SQL Server, choisissez une connexion avec authentification SQL Server ou authentification Windows. Si vous choisissez l’authentification SQL Server, entrez les informations d’identification existantes. Indiquez le nom du serveur SQL Server et le nom de la base de données à synchroniser, puis sélectionnez Tester la connexion pour tester vos paramètres. Sélectionnez ensuite Enregistrer. La base de données inscrite apparaît alors dans la liste.
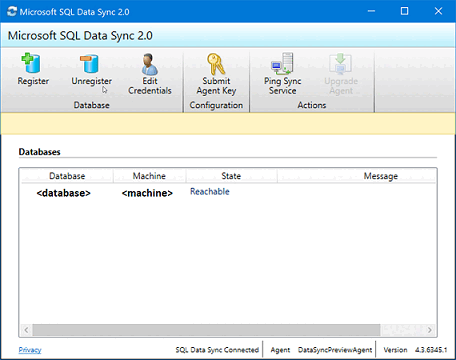
Fermez l’application Agent de synchronisation du client.
Dans le portail Azure, dans la page Configurer localement, choisissez Sélectionner la base de données.
Dans la page Sélectionner la base de données, indiquez le nom du nouveau membre de synchronisation dans le champ Nom du membre de synchronisation. Ce nom est différent du nom de la base de données. Sélectionnez la base de données dans la liste. Dans le champ Sens de la synchronisation, sélectionnez Synchronisation bidirectionnelle, Vers le hub ou À partir du hub.
Sélectionnez OK pour fermer la page Sélectionner la base de données. Ensuite, sélectionnez OK pour fermer la page Configurer localement et attendez que le nouveau membre de synchronisation soit créé et déployé. Pour finir, sélectionnez OK pour fermer la page Sélectionner les membres de synchronisation.
Notes
Pour vous connecter à SQL Data Sync et à l’agent local, ajoutez votre nom d’utilisateur au rôle DataSync_Executor. Data Sync crée ce rôle sur l’instance SQL Server.
Configurer le groupe de synchronisation
Une fois les membres du groupe de synchronisation créés et déployés, accédez à la section Tables de la page Groupe de synchronisation de base de données.

Dans la page Tables, sélectionnez une base de données dans la liste des membres du groupe de synchronisation, puis sélectionnez Actualiser le schéma. L’actualisation du schéma peut prendre quelques minutes et ce délai peut être rallongé de quelques minutes supplémentaires en cas d’utilisation d’une liaison privée.
Dans la liste, sélectionnez les tables à synchroniser. Toutes les colonnes étant sélectionnées par défaut, décochez celles que vous ne souhaitez pas synchroniser. Vérifiez que la colonne de la clé primaire est sélectionnée.
Sélectionnez Enregistrer.
Par défaut, les bases de données ne sont synchronisées que si l’opération de synchronisation est planifiée ou exécutée manuellement. Pour exécuter une synchronisation manuelle, accédez à votre base de données dans SQL Database dans le portail Azure, sélectionnez Synchroniser avec d’autres bases de données, puis sélectionnez le groupe de synchronisation. La page Synchronisation des données s’ouvre. Sélectionnez Synchroniser.
Forum aux questions
Cette section répond aux questions fréquemment posées sur le service Azure SQL Data Sync.
SQL Data Sync gère-t-il intégralement la création des tables ?
Si des tables de schéma de synchronisation ne figurent pas dans la base de données de destination, SQL Data Sync les crée avec les colonnes que vous avez sélectionnées. Cela ne permet toutefois pas la création d’un schéma haute fidélité, et ce pour les raisons suivantes :
- Seules les colonnes que vous sélectionnez sont créées dans la table de destination. Les colonnes non sélectionnées sont ignorées.
- Seuls les index des colonnes sélectionnées sont créés dans la table de destination. Pour les colonnes non sélectionnées, ces index sont ignorés.
- Les index sur les colonnes de type XML ne sont pas créés.
- Les contraintes CHECK ne sont pas créées.
- Les déclencheurs sur les tables sources ne sont pas créés.
- Les vues et procédures stockées ne sont pas créées.
En raison de ces limitations, nous vous recommandons les opérations suivantes :
- Pour les environnements de production, créez vous-même le schéma haute fidélité.
- Quand vous testez le service, utilisez la fonctionnalité de provisionnement automatique.
Comment se fait-il que je vois des tables que je n’ai pas créées ?
Data Sync crée des tables supplémentaires dans la base de données pour le suivi des changements. Ne les supprimez pas, sinon Data Sync cessera de fonctionner.
Mes données sont-elles convergentes après une synchronisation ?
Pas nécessairement. Prenez un groupe de synchronisation comprenant un hub et trois rayons (A, B et C), avec les synchronisations suivantes : Hub vers A, Hub vers B et Hub vers C. Si un changement est apporté à la base de données A après la synchronisation Hub vers A, ce changement n’est écrit dans la base de données B ou C qu’au cours de la prochaine tâche de synchronisation.
Comment faire pour répercuter les changements de schéma dans un groupe de synchronisation ?
Apportez et propagez tous les changements de schéma manuellement.
- Répliquez les modifications du schéma manuellement vers le hub et tous les membres de synchronisation.
- Mettez à jour le schéma de synchronisation.
Ajout de nouvelles tables et colonnes :
Les nouvelles tables et colonnes n’ont aucun impact sur la synchronisation actuelle. Data Sync les ignore tant qu’elles ne sont pas ajoutées au schéma de synchronisation. Quand vous ajoutez des objets de base de données, suivez cette séquence :
- Ajoutez les nouvelles tables ou colonnes au hub et à tous les membres de synchronisation.
- Ajoutez les nouvelles tables ou colonnes au schéma de synchronisation.
- Commencez par insérer des valeurs dans les nouvelles tables et colonnes.
Pour modifier le type de données d’une colonne :
Lorsque vous modifiez le type de données d’une colonne existante, Data Sync continue à fonctionner tant que les nouvelles valeurs correspondent au type de données d’origine défini dans le schéma de synchronisation. Par exemple, si vous remplacez le type int dans la base de données source par bigint, Data Sync continue de fonctionner jusqu’à ce que vous insériez une valeur trop grande pour le type de données int. Pour terminer le changement, répliquez le changement de schéma manuellement sur le hub et sur tous les membres de synchronisation, puis mettez à jour le schéma de synchronisation.
Comment faire pour exporter et importer une base de données avec Data Sync ?
Après avoir exporté une base de données sous forme de fichier .bacpac et avoir importé le fichier pour créer une base de données, effectuez les tâches suivantes pour utiliser Data Sync dans la nouvelle base de données :
- Nettoyer les objets Data Sync et les tables annexes de la nouvelle base de données à l’aide de Data Sync complete cleanup.sql. Le script supprime tous les objets Data Sync requis de la base de données.
- Recréer le groupe de synchronisation avec la nouvelle base de données. Si vous n’avez plus besoin de l’ancien groupe de synchronisation, supprimez-le.
Où puis-je trouver des informations sur l’agent client ?
Pour les questions fréquemment posées sur l’agent client, consultez FAQ sur l'agent.
Faut-il approuver manuellement la liaison avant de pouvoir commencer à l’utiliser ?
Oui. Vous devez approuver manuellement le point de terminaison privé géré par le service dans la page Connexions de point de terminaison privé du portail Azure pendant le déploiement du groupe de synchronisation ou à l’aide de PowerShell.
Pourquoi est-ce que j’obtiens une erreur de pare-feu quand la tâche de synchronisation provisionne ma base de données Azure ?
Cela peut se produire si des ressources Azure ne sont pas autorisées à accéder à votre serveur. Il existe deux solutions :
- Vérifiez que le pare-feu sur la base de données Azure a défini Autoriser les services et les ressources Azure à accéder à ce serveur sur Oui. Pour plus d’informations, consultez Contrôles d’accès réseau Azure SQL Database.
- Configurez une liaison privée pour Data Sync, qui est différente d’une liaison privée Azure. Private Link est le moyen de créer des groupes de synchronisation en utilisant une connexion sécurisée avec des bases de données derrière un pare-feu. SQL Data Sync Private Link est un point de terminaison géré par Microsoft et crée en interne un sous-réseau dans le réseau virtuel existant. Il n’est donc pas nécessaire de créer un autre réseau virtuel ou sous-réseau.
Contenu connexe
- Présentation de SQL Data Sync pour Azure
- Data Sync Agent pour SQL Data Sync
- Bonnes pratiques pour Azure SQL Data Sync
- Résoudre les problèmes liés à SQL Data Sync
- Surveillance et réglage des performances dans Azure SQL Database et Azure SQL Managed Instance
- Automatiser la réplication des modifications de schéma dans Azure SQL Data Sync
- Utiliser PowerShell pour mettre à jour le schéma de synchronisation dans un groupe de synchronisation existant
- Qu’est-ce qu’Azure SQL Database ?
- Gestion du cycle de vie des bases de données