Régler les applications et les bases de données pour de meilleures performances dans Azure SQL Managed Instance
S’applique à : ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Une fois que vous avez identifié un problème de performances avec Azure SQL Managed Instance, consultez cet article pour savoir comment le résoudre :
- Paramétrez votre application et appliquez quelques meilleures pratiques susceptibles d’améliorer les performances.
- Paramétrez la base de données en modifiant les index et les requêtes afin d’utiliser plus efficacement les données.
Cet article part du principe que vous avez consulté la vue d’ensemble de la surveillance et du réglage et l’article Surveiller les performances à l’aide du Magasin des requêtes. Il suppose également que vous n’avez aucun problème de performances lié à l’utilisation des ressources d’UC pouvant être résolu en augmentant la taille de calcul ou le niveau de service afin de fournir davantage de ressources à votre base de données gérée SQL.
Remarque
Pour obtenir des conseils semblables dans Azure SQL Database, consultez Régler les applications et les bases de données pour de meilleures performances dans Azure SQL Database.
Paramétrer votre application
Dans un SQL Server local traditionnel, le processus de planification de la capacité initiale est souvent séparé du processus d’exécution d’une application en production. Le matériel et les licences de produit sont achetés dans un premier temps, tandis que le paramétrage des performances est exécuté ultérieurement. Lorsque vous utilisez Azure SQL, il est judicieux d’imbriquer le processus d’exécution et de réglage d’une application. Avec le modèle de paiement de la capacité à la demande, vous pouvez paramétrer votre application pour utiliser les ressources minimales requises immédiatement, au lieu de surprovisionner massivement du matériel en vous appuyant sur des hypothèses de plans de croissance à venir pour une application (qui sont souvent incorrectes).
Certains clients peuvent décider de ne pas paramétrer une application et choisir à la place de surprovisionner des ressources matérielles. Cette approche peut s’avérer utile si vous ne souhaitez pas modifier une application clé pendant une période d’activité. Cependant, le réglage d’une application peut réduire vos besoins en ressources et diminuer vos factures mensuelles.
Meilleures pratiques et antimodèles dans la conception d’applications pour Azure SQL Managed Instance
Bien que les niveaux de service d’Azure SQL Managed Instance soient conçus pour améliorer la stabilité et la prévisibilité des performances d’une application, quelques meilleures pratiques peuvent vous aider à régler votre application afin de mieux tirer parti des ressources d’une taille de calcul. Bien que de nombreuses applications gagnent considérablement en performances en passant simplement à une taille de calcul ou un niveau de service supérieurs, certaines d’entre elles nécessitent un paramétrage supplémentaire pour bénéficier de ces avantages.
Pour améliorer les performances, envisagez de procéder à un paramétrage supplémentaire sur les applications présentant ces caractéristiques :
Les applications dont les performances sont lentes en raison d’un comportement bavard
Les applications qui se caractérisent par un comportement bavard effectuent trop d’opérations d’accès aux données qui sont sensibles à la latence du réseau. Il vous faudra peut-être modifier ces types d’applications pour réduire le nombre d’opérations d’accès aux données de la base de données. Par exemple, vous pouvez améliorer les performances applicatives à l’aide de techniques comme le traitement par lot des requêtes ad hoc ou le déplacement de requêtes vers les procédures stockées. Pour plus d’informations, consultez la section Traitement par lot des requêtes.
Bases de données présentant une charge de travail intensive et qui ne peuvent pas être prise en charge par un seul ordinateur
Les bases de données qui dépassent le quota de ressources de la taille de calcul Premium supérieure peuvent profiter de la montée en puissance de la charge de travail. Pour plus d’informations, consultez les sections Partitionnement entre plusieurs bases de données et Partitionnement fonctionnel.
Applications présentant des requêtes non optimales
Il se peut que les applications dont les requêtes sont mal paramétrées ne tirent pas parti d’une taille de calcul supérieure. Cela inclut les requêtes dépourvues d’une clause WHERE et les requêtes présentant des index manquants ou des statistiques obsolètes. Ces applications bénéficient des techniques de paramétrage des performances de requête standard. For more information, consultez les sections Index manquants et Paramétrage/Compréhension de requêtes.
Les applications dotées d’un accès aux données non optimal
Il se peut que les applications qui rencontrent des problèmes inhérents de concurrence d’accès aux données (interblocage, par exemple) ne tirent pas parti d’une taille de calcul supérieure. Envisagez de réduire les allers-retours sur la base de données en mettant en cache des données côté client à l’aide du service caching d’Azure ou d’autres technologies de mise en cache. Consultez la section Mise en cache de la couche Application.
Pour prévenir les blocages dans Azure SQL Managed Instance, consultez Outils d’information sur le blocage dans le Guide des interblocages.
Optimiser votre base de données
Cette section explique certaines techniques que vous pouvez utiliser pour paramétrer une base de données afin d’obtenir les meilleures performances de votre application et l’exécuter à la plus petite taille de calcul possible. Certaines de ces techniques correspondent aux meilleures pratiques de réglage SQL Server traditionnelles, mais d’autres sont propres à Azure SQL Managed Instance. Dans certains cas, vous pouvez examiner les ressources consommées par une base de données afin de déterminer des zones à régler davantage et d’étendre les techniques SQL Server traditionnelles afin qu’elles fonctionnent dans Azure SQL Managed Instance.
Identifier et ajouter des index manquants
Un problème courant dans les performances de base de données OLTP est la conception physique de la base de données. Souvent, les schémas de base de données sont conçus et livrés sans test de mise à l’échelle (en charge ou en volume de données). Malheureusement, les performances d’un plan de requête peuvent être acceptables à petite échelle mais se dégrader notablement avec des volumes de données au niveau de la production. La cause la plus courante de ce problème est l’absence d’index appropriés pour satisfaire des filtres ou d’autres restrictions dans une requête. Souvent, cela se manifeste comme une analyse de table là où une recherche d’index pourrait suffire.
Dans cet exemple, le plan de requête sélectionné utilise une analyse là où une recherche suffirait :
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
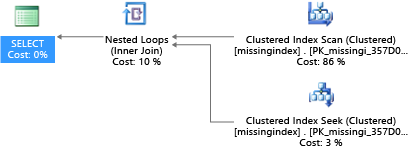
Les vues de gestion dynamique (DMV) intégrées à SQL Server depuis 2005 analysent les compilations de requêtes dans lesquelles un index réduirait considérablement le coût estimé d’exécution d’une requête. Pendant l’exécution de requêtes, le moteur de base de données suit la fréquence selon laquelle chaque plan de requête est exécuté, ainsi que l’écart estimé entre le plan de requête en cours d’exécution et le plan imaginé dans lequel cet index existait. Ces vues de gestion dynamique vous permettent d’identifier rapidement les modifications de conception physique de la base de données susceptibles d’améliorer le coût total de la charge de travail pour une base de données et sa charge de travail réelle.
Vous pouvez utiliser cette requête pour évaluer les index manquants potentiels :
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
Dans cet exemple, la requête a entraîné cette suggestion :
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Après sa création, cette même instruction SELECT sélectionne un plan différent, qui utilise une recherche en lieu et place d’une analyse, puis exécute plus efficacement le plan :
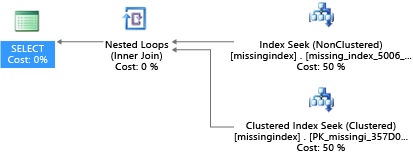
L’insight clé est que la capacité d’E/S d’un système partagé est plus limitée que celle d’un serveur dédié. Il est primordial de réduire les E/S inutiles pour tirer le meilleur parti du système dans les ressources de chaque taille de calcul des niveaux de service. Des choix appropriés de conception physique de base de données peuvent considérablement améliorer la latence des requêtes individuelles, le débit des requêtes simultanées que vous pouvez traiter par unité d’échelle, et réduire les coûts nécessaires pour satisfaire la requête.
Pour plus d’informations sur le paramétrage des index à l’aide de requêtes d’index manquants, consultez Paramétrer les index non-cluster avec les suggestions d’index manquants.
Paramétrage/Compréhension de requêtes
L’optimiseur de requête d’Azure SQL Managed Instance est semblable à l’optimiseur de requête SQL Server traditionnel. La plupart des meilleures pratiques pour régler les requêtes et comprendre la logique des limitations de modèle pour l’optimiseur de requête s’appliquent également à Azure SQL Managed Instance. Si vous réglez des requêtes dans Azure SQL Managed Instance, vous pourriez également profiter d’une réduction des demandes en ressources agrégées. Votre application peut s’exécuter à un coût inférieur à celui d’une instance équivalente non paramétrée, car elle peut fonctionner à une taille de calcul moindre.
Un scénario courant dans SQL Server, qui s’applique également à Azure SQL Managed Instance, est la détection des paramètres par l’optimiseur de requête. Pendant la compilation, l’optimiseur de requête évalue la valeur actuelle d’un paramètre pour déterminer s’il est possible de générer un plan de requête plus optimal. Bien que cette stratégie mène souvent à un plan de requête qui est beaucoup plus rapide qu’un plan compilé sans valeurs de paramètre connues, elle fonctionne actuellement de manière imparfaite dans Azure SQL Managed Instance. (Une nouvelle fonctionnalité de performances intelligentes des requêtes introduite avec SQL Server 2022, nommé optimisation du plan de sensibilité des paramètres, résout le scénario dans lequel un plan mis en cache unique pour une requête paramétrable n’est pas optimal pour toutes les valeurs de paramètres entrantes possibles. Actuellement, l’optimisation du plan de sensibilité des paramètres n’est pas disponible dans Azure SQL Managed Instance.)
Parfois le paramètre n’est pas surveillé, et d’autres fois le paramètre est surveillé, mais le plan généré n’est pas optimal pour l’ensemble complet de valeurs de paramètres d’une charge de travail. Microsoft inclut des indicateurs de requête (directives) pour vous permettre de spécifier vos intentions plus délibérément et de remplacer le comportement par défaut pour la détection des paramètres. Vous pouvez choisir d’utiliser des indicateurs lorsque le comportement par défaut est imparfait pour une charge de travail client spécifique.
L’exemple suivant illustre la manière dont le processeur de requêtes peut générer un plan non optimal en matière de performances et de ressources requises. Cet exemple vous montre également que, si vous utilisez un indicateur de requête, vous pouvez réduire la durée d’exécution de la requête et le nombre de ressources requises pour votre base de données :
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Le code de configuration crée une table qui a des données distribuées de manière irrégulière dans la table t1. Le plan de requête optimal varie en fonction du paramètre sélectionné. Malheureusement, le comportement de mise en cache du plan ne recompile pas toujours la requête en fonction de la valeur de paramètre la plus courante. Par conséquent, il est possible de mettre en cache un plan non optimal et de l’utiliser pour plusieurs valeurs, même si un autre plan pourrait constituer un meilleur choix en moyenne. Ensuite, le plan de requête génère deux procédures stockées identiques, sauf que celle-ci présente un indicateur spécifique de requête.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Nous vous recommandons d’attendre au moins 10 minutes avant de commencer la partie 2 de l’exemple, de manière à ce que les résultats soient différents dans les données de télémétrie obtenues.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
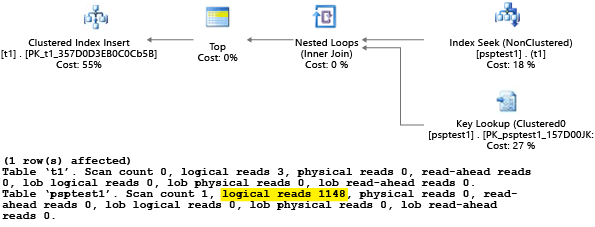
Chaque partie de cet exemple essaie d’exécuter une instruction insert paramétrable 1 000 fois (pour générer une charge suffisante pour être intéressante sur un jeu de données de test). Lors de l’exécution des procédures stockées, le processeur de requêtes examine la valeur de paramètre transmise à la procédure lors de sa première compilation (appelée détection de paramètres). Le processeur met en cache le plan résultant et l’utilise pour les appels ultérieurs, même si la valeur de paramètre est différente. Le plan optimal peut ne pas être utilisé dans tous les cas. Parfois, les clients doivent guider l’optimiseur vers le choix d’un plan adapté aux situations courantes, plutôt qu’aux situations spécifiques lorsque la requête a été compilée en premier lieu. Dans cet exemple, le plan initial génère un plan de type analyse qui lit toutes les lignes pour trouver chaque valeur qui correspond au paramètre :

Étant donné que nous avons exécuté la procédure avec la valeur 1, le plan obtenu était optimal pour la valeur 1, mais non optimal pour toutes les autres valeurs dans la table. Le résultat n’est probablement pas ce que vous attendriez en sélectionnant chaque plan de manière aléatoire, car le plan s’exécute plus lentement et utilise davantage de ressources.
Si vous exécutez le test avec SET STATISTICS IO défini sur ON, la tâche d’analyse logique de cet exemple est effectuée en arrière-plan. Vous pouvez voir que 1 148 lectures sont effectuées par le plan (ce qui est inefficace, si le cas moyen renvoie juste une ligne) :

La deuxième partie de l’exemple utilise un indicateur de requête pour spécifier à l’optimiseur d’utiliser une valeur spécifique pendant le processus de compilation. Dans ce cas, il force le processeur de requêtes à ignorer la valeur transmise en tant que paramètre, et à prendre en compte UNKNOWN. Cela fait référence à une valeur présentant la fréquence moyenne de la table (en ignorant le décalage). Le plan obtenu est un plan basé sur la recherche, qui est plus rapide et utilise moins de ressources en moyenne que le plan de la partie 1 de cet exemple :
Vous pouvez voir l’effet dans l’affichage catalogue système sys.server_resource_stats. Les données sont collectées, agrégées et mises à jour par intervalles de cinq à dix minutes. Une ligne est créée pour chaque rapport de 15 secondes. Par exemple :
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Vous pouvez examiner sys.server_resource_stats pour déterminer si la ressource d’un test donnée utilise plus ou moins de ressource qu’un autre test. Lorsque vous comparez les données, espacez les tests dans le temps pour qu’ils ne soient pas groupés dans la même fenêtre temporelle de cinq minutes dans la vue sys.server_resource_stats. Le but de cet exercice est de réduire les ressources totales utilisées, et non pas de réduire les ressources. En règle générale, l’optimisation d’une partie de code pour la latence permet également de réduire l’utilisation des ressources. Assurez-vous que les modifications apportées à une application sont nécessaires, et que les modifications n’affectent pas négativement les utilisateurs susceptibles d’utiliser des indicateurs de requêtes dans l’application.
Si une charge de travail présente un ensemble de requêtes répétitives, il est souvent judicieux de capturer et de valider l’optimalité de ces choix de plan, dans la mesure où ils proposeront l’unité de taille de ressource minimum requise pour héberger la base de données. Après la validation, réexaminez régulièrement les plans afin de vous assurer de leur non-dégradation. Pour plus d’informations, consultez la page Indicateurs de requête (Transact-SQL).
Meilleures pratiques pour les architectures de base de données très volumineuse dans Azure SQL Managed Instance
Les deux sections suivantes présentent deux options pour résoudre les problèmes liés aux bases de données très volumineuses dans Azure SQL Managed Instance.
Partitionnement entre plusieurs bases de données
Azure SQL Managed Instance s’exécutant sur du matériel courant, les limites de capacité pour une base de données individuelle sont inférieures à celles d’une installation SQL Server sur site traditionnelle. Certains clients utilisent des techniques de partitionnement pour répartir les opérations de base de données sur plusieurs bases de données si les limites d’une base de données individuelle dans Azure SQL Managed Instance ne permettent pas de réaliser toutes les opérations. La plupart des clients utilisant des techniques de partitionnement dans Azure SQL Managed Instance fractionnent leurs données dans une seule dimension sur plusieurs bases de données. Pour cette approche, vous devez comprendre que les applications OLTP exécutent souvent des transactions s’appliquant uniquement à une ligne ou à un petit groupe de lignes dans le schéma.
Par exemple, si une base de données comporte le nom d’un client, une commande et des détails relatifs à la commande (comme dans la base de données AdventureWorks), vous pouvez fractionner ces données en plusieurs bases de données, en regroupant un client avec la commande associée et les détails relatifs à cette commande. Vous pouvez garantir que les données du client sont conservées dans une base de données individuelle. L’application fractionnerait différents clients sur les bases de données, répartissant ainsi efficacement la charge sur celles-ci. Le partitionnement permet non seulement aux clients d’éviter la limite de taille maximale de la base de données, mais également à Azure SQL Managed Instance de traiter des charges de travail qui sont beaucoup plus volumineuses que les limites des différentes tailles de calcul, à condition que chaque base de données individuelle s’inscrive dans les limites de son niveau de service.
Bien que le partitionnement de base de données ne réduise pas la capacité des ressources globales pour une solution, cette technique est très efficace pour prendre en charge des solutions volumineuses réparties sur plusieurs bases de données. Chaque base de données peut s’exécuter à une taille de calcul différente afin de prendre en charge des bases de données très grandes, efficaces, dont les besoins en ressources sont importants.
Partitionnement fonctionnel
Les utilisateurs combinent bien souvent de nombreuses fonctions dans une base de données individuelle. Par exemple, si une application contient une logique pour gérer le stock d’un magasin, cette base de données peut contenir la logique associée au stock, le suivi des bons de commande, les procédures stockées et les vues indexées/matérialisées pour la gestion de rapports de fin de mois et d’autres fonctions. Cette technique facilite l’administration de la base de données pour des opérations comme la sauvegarde, mais elle nécessite également que vous redimensionniez le matériel pour gérer la charge maximale sur toutes les fonctions d’une application.
Si vous utilisez une architecture scale-out dans Azure SQL Managed Instance, il peut être judicieux de répartir différentes fonctions d’une application entre plusieurs bases de données. Si vous utilisez cette technique, chaque application est mise à l’échelle indépendamment. Lorsqu’une application devient plus occupée (et reçoit plus de charge sur la base de données), l’administrateur peut choisir des tailles de calcul indépendamment pour chaque fonction dans une application. À la limite, cette architecture permet à une application de devenir plus grande que ce qu’un seul ordinateur peut gérer en diffusant la charge sur plusieurs ordinateurs.
Traitement par lot des requêtes
Pour les applications qui accèdent aux données sous la forme de requêtes ad hoc, fréquentes et à volume élevé, une grande partie du temps de réponse est consacrée à la communication réseau entre la couche Application et la couche Données. Même lorsque l’application et la base de données résident dans le même centre de données, la latence du réseau entre les deux peut être accrue par un nombre élevé d’opérations d’accès aux données. Pour réduire les boucles réseau requises par les opérations d’accès aux données, envisagez d’utiliser l’option pour traiter par lot les requêtes ad hoc, ou pour les compiler en tant que procédures stockées. Si vous traitez par lot les requêtes ad hoc, vous pouvez envoyer en une fois plusieurs requêtes dans un seul lot à la base de données. Si vous compilez les requêtes ad hoc dans une procédure stockée, vous pouvez obtenir des résultats similaires à ceux du traitement par lot. L’utilisation d’une procédure stockée vous permet également d’augmenter les possibilités de mise en cache des plans de requête dans la base de données pour les exécutions suivantes de la même procédure stockée.
Certaines applications sont gourmandes en écriture. Il est parfois possible de réduire la charge d’E/S totale sur une base de données en effectuant des écritures par lots. Souvent, cela est aussi simple que d’utiliser des transactions explicites au lieu des transactions de validation automatique dans les procédures stockées et les lots ad hoc. Vous trouverez une évaluation des différentes techniques utilisables à la page Utiliser le traitement par lot pour améliorer les performances des applications de base de données dans Azure. Faites des essais avec votre propre charge de travail afin d’identifier le modèle approprié pour le traitement par lot. Assurez-vous de tenir compte du fait que les modèles peuvent présenter des garanties de cohérence transactionnelle légèrement différentes. L’identification de la charge de travail adaptée pour la réduction de l’utilisation des ressources nécessite de trouver le bon équilibre entre cohérence et performances.
Mise en cache de la couche Application
Certaines applications de base de données contiennent des charges de travail à lecture intensive. Les couches de mise en cache peuvent contribuer à réduire la charge sur la base de données et éventuellement la taille de calcul requise pour la prise en charge d’une base de données à l’aide d’Azure SQL Managed Instance. Avec Azure Cache pour Redis, si vous possédez une charge de travail à lecture intensive, vous pouvez lire les données une fois (ou peut-être une fois par machine de la couche Application, selon sa configuration) et stocker ces données en dehors de votre base de données. Cela permet de réduire la charge de la base de données (UC et E/S de lecture). Toutefois, cela a un impact sur la cohérence transactionnelle, puisque les données lues à partir du cache peuvent ne pas être synchronisées avec les données de la base de données. Si un certain niveau d’incohérence est acceptable dans de nombreuses applications, cela ne se vérifie pas pour l’ensemble des charges de travail. Assurez-vous de comprendre pleinement les exigences d’une application avant d’utiliser une stratégie de mise en cache de couche Application.
Contenu connexe
- Modèle d’achat vCore - Azure SQL Managed Instance
- Configurer les paramètres tempdb pour Azure SQL Managed Instance
- Surveillance des performances de Microsoft Azure SQL Managed Instance à l’aide de vues de gestion dynamique
- Paramétrer les index non-cluster avec les suggestions d’index manquants
- Surveiller Azure SQL Managed Instance avec Azure Monitor