Restaurer les bases de données SAP HANA sur des machines virtuelles Azure
Cet article explique comment restaurer des bases de données SAP HANA qui sont exécutées sur des machines virtuelles Azure et qui ont été sauvegardées dans un coffre Recovery Services par le service Sauvegarde Azure. Vous pouvez utiliser les données restaurées pour créer des copies dans le cadre de scénarios de développement et de test, ou pour revenir à un état antérieur.
La Sauvegarde Azure prend désormais en charge la sauvegarde et la restauration des instances de réplication système SAP HANA (HSR).
Notes
- Le processus de restauration des bases de données HANA avec HSR est identique à celui de la restauration des bases de données HANA sans HSR. Conformément aux avis SAP, vous pouvez restaurer des bases de données avec le mode HSR en tant que bases de données autonomes. Si le mode HSR est activé sur le système cible, désactivez d’abord ce mode, puis restaurez la base de données. Toutefois, si vous restaurez en tant que fichiers, la désactivation du mode HSR (cassant le HSR) n’est pas nécessaire.
- La récupération d’emplacement d’origine (OLR) n’est actuellement pas prise en charge pour la réplication HSR. Autrement, sélectionnez Restauration d’un autre emplacement, puis sélectionnez la machine virtuelle source comme hôte dans la liste.
- La restauration sur l’instance HSR n’est pas prise en charge. Toutefois, la restauration uniquement sur l’instance HANA est prise en charge.
Pour obtenir des informations sur les configurations et scénarios pris en charge, consultez Matrice de prise en charge des sauvegardes SAP HANA.
Restaurer à un point dans le temps ou à un point de récupération
La Sauvegarde Azure restaure les bases de données SAP HANA qui s’exécutent sur des machines virtuelles Azure. Il peut :
Vous pouvez les restaurer à une date ou à une heure spécifique (à la seconde près) en utilisant les sauvegardes de fichiers journaux. La Sauvegarde Azure détermine automatiquement les sauvegardes complètes, les sauvegardes différentielles et la chaîne des sauvegardes de fichiers journaux qui sont nécessaires pour effectuer la restauration selon la date ou l’heure sélectionnée.
Vous pouvez les restaurer dans une sauvegarde complète ou différentielle, à un point de récupération spécifique.
Prérequis
Avant de restaurer une base de données, notez les points suivants :
Vous pouvez restaurer la base de données uniquement sur une instance SAP HANA qui se trouve dans la même région.
L’instance cible doit être inscrite auprès du même coffre que la source. En savoir plus sur la sauvegarde des bases de données SAP HANA.
Sauvegarde Azure ne peut pas identifier deux instances de SAP HANA différentes sur la même machine virtuelle. Par conséquent, il est impossible de restaurer des données d’une instance vers une autre sur la même machine virtuelle.
Pour que l’instance de SAP HANA cible soit prête pour la restauration, vérifiez son état Préparation de la sauvegarde :
Sur le portail Azure, accédez à Centre de sauvegarde, puis sélectionnez Sauvegarde.
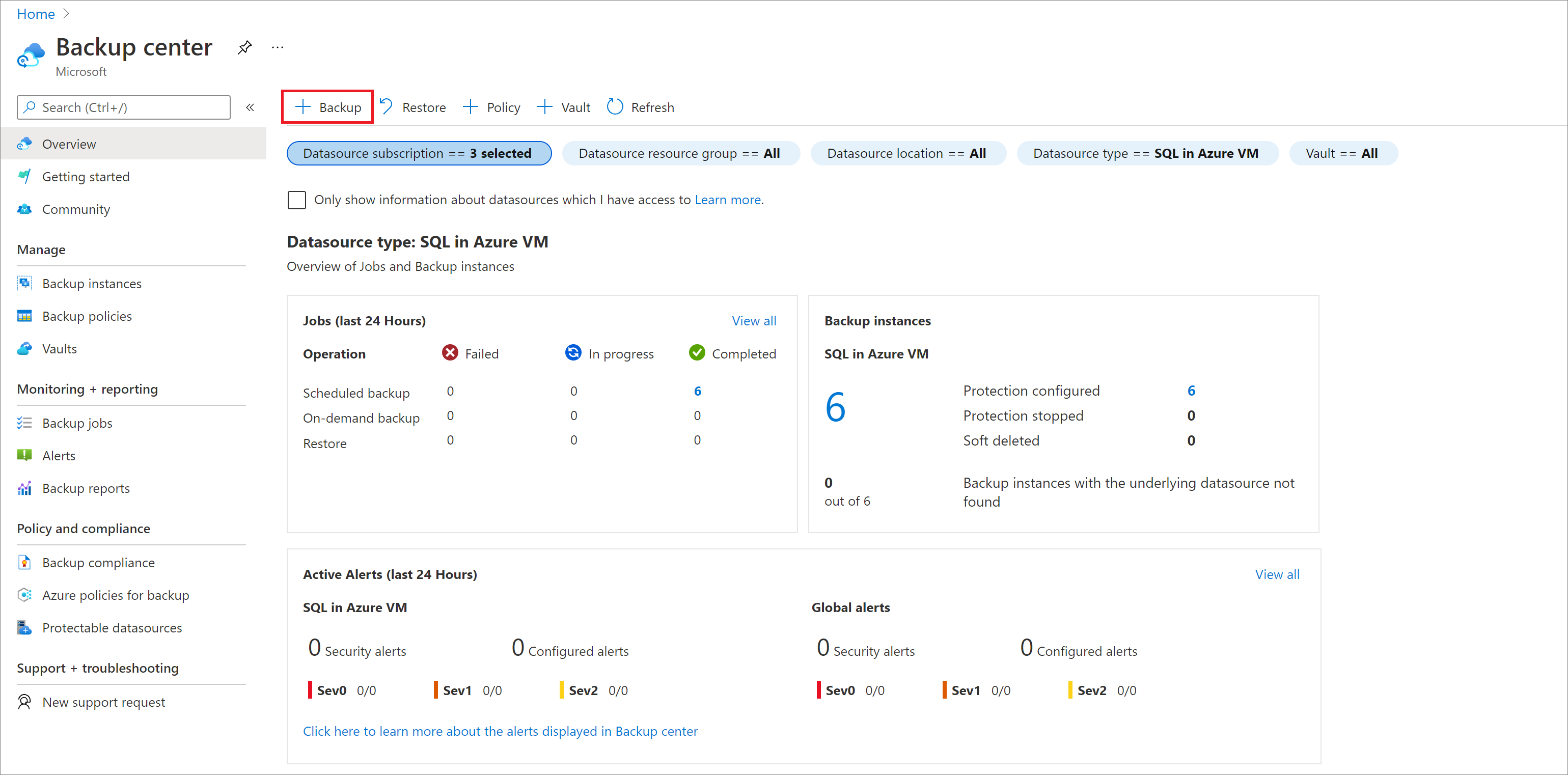
Dans le volet Démarrer : Configurer la sauvegarde, pour Type de source de données, sélectionnez SAP HANA dans la machine virtuelle Azure, sélectionnez le coffre dans lequel l’instance SAP HANA est inscrite, puis sélectionnez Continuer.
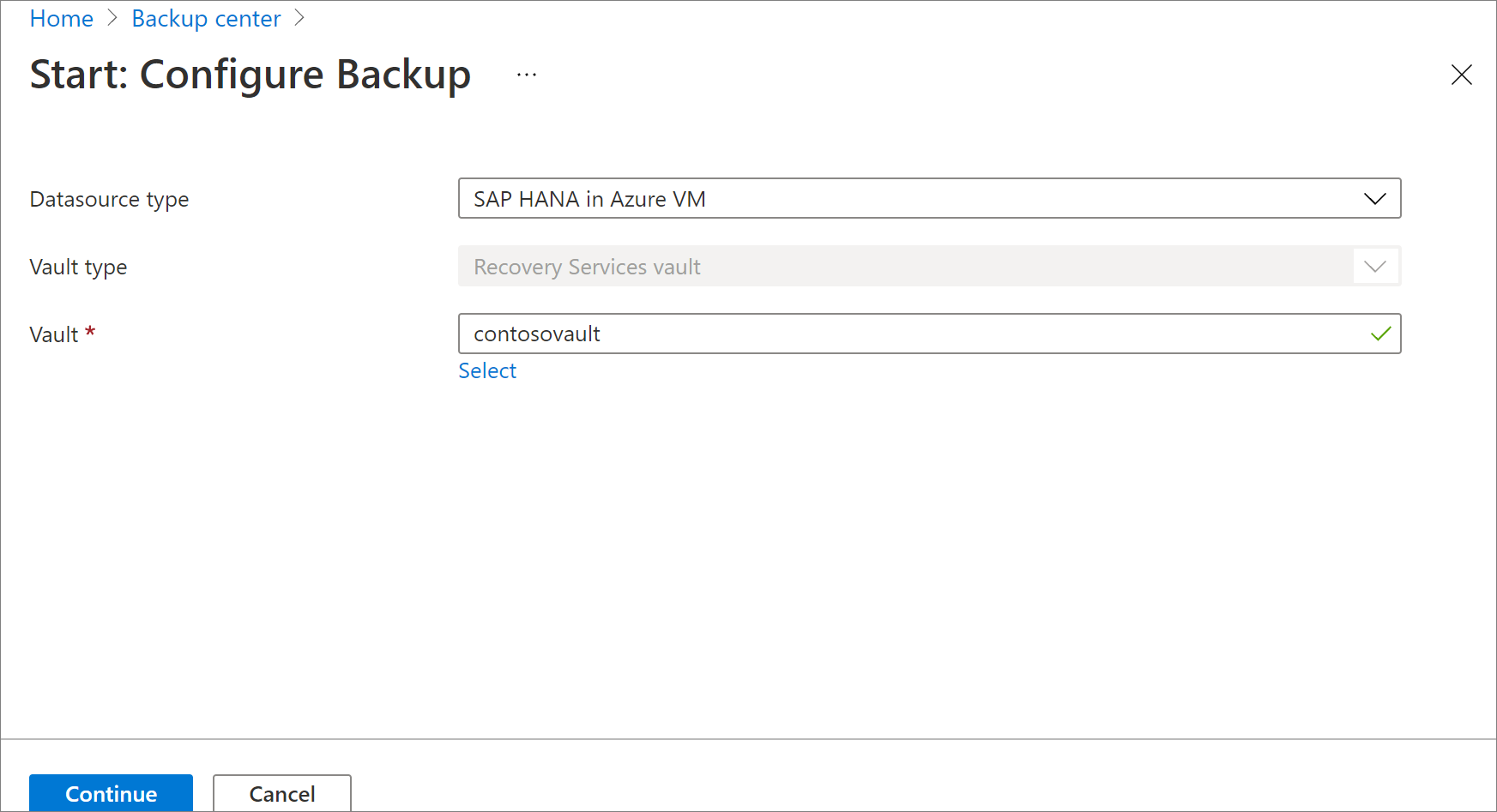
Sous Découvrir les bases de données dans les machines virtuelles, sélectionnez Afficher les détails.
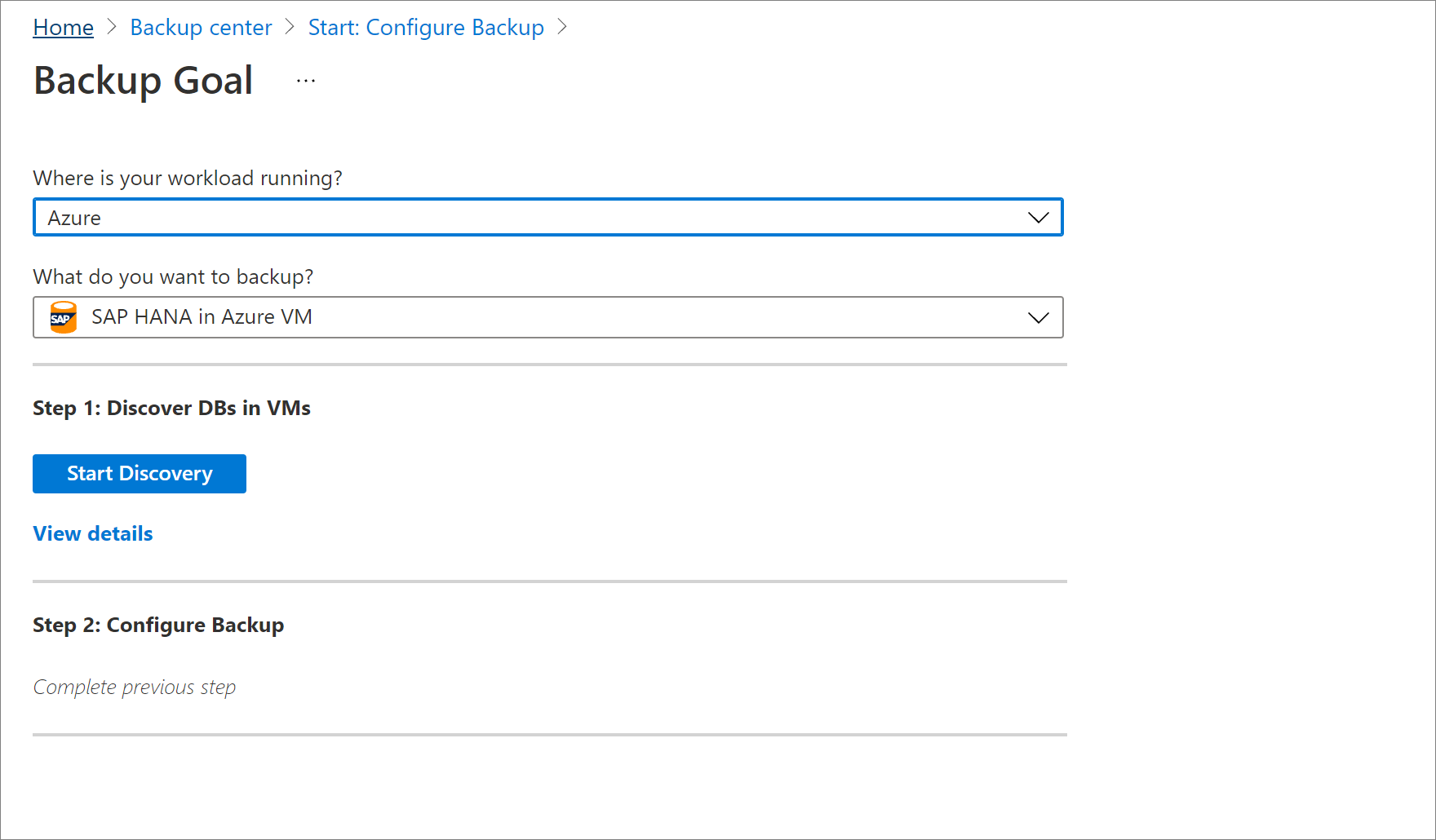
Passez en revue la Préparation de la sauvegarde de la machine virtuelle cible.
Pour en savoir plus sur les types de restauration pris en charge par SAP HANA, reportez-vous à la note SAP HANA 1642148.


Restaurer une base de données
Pour restaurer une base de données, vous avez besoin des autorisations suivantes :
- Opérateur de sauvegarde : fournit les autorisations du coffre dans lequel vous effectuez la restauration.
- Contributeur (écriture) : fournit l’accès à la machine virtuelle source qui est sauvegardée.
- Contributeur (écriture) : fournit l’accès à la machine virtuelle cible.
- Si vous effectuez une restauration sur la même machine virtuelle, ce sera la machine virtuelle source.
- Si vous effectuez une restauration à un autre emplacement, ce sera la nouvelle machine virtuelle cible.
Sur le portail Azure, accédez à Centre de sauvegarde, puis sélectionnez Restauration.
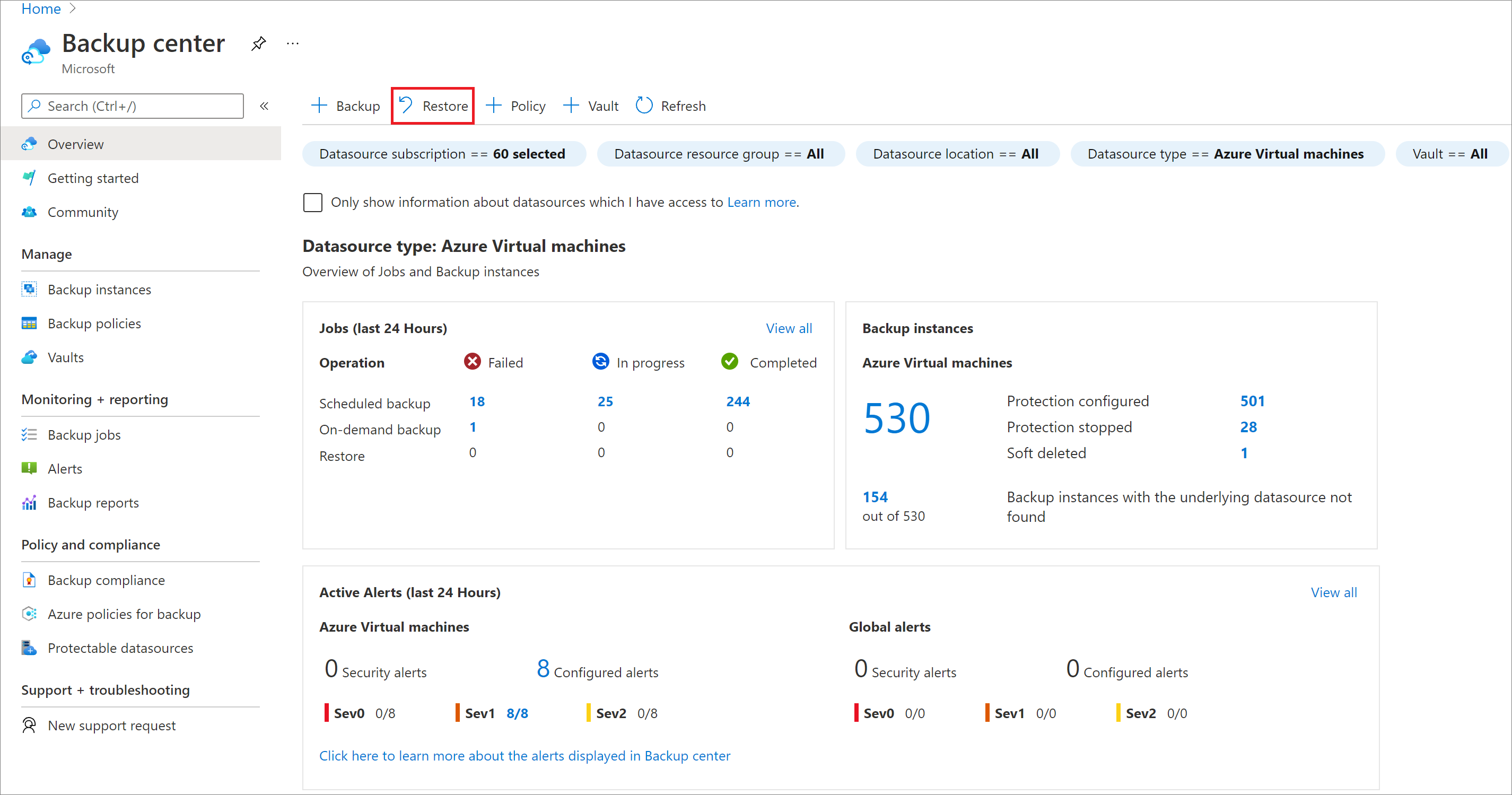
Sélectionnez SAP HANA dans la machine virtuelle Azure comme type de source de données, sélectionnez la base de données à restaurer, puis cliquez sur Continuer.
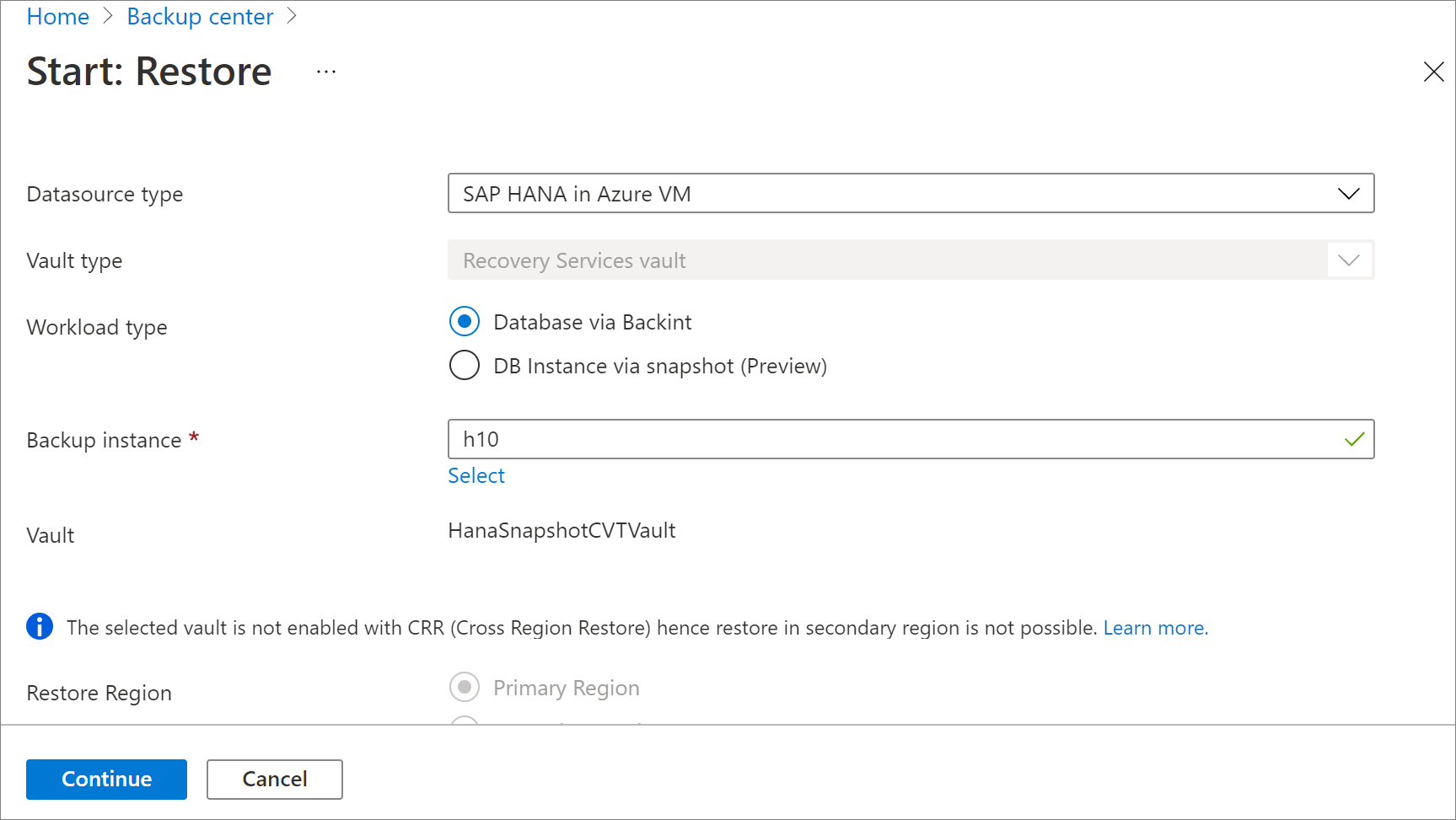
Sous Configuration de la restauration, spécifiez où et comment vous voulez restaurer les données :
- Autre emplacement : restaure la base de données vers un autre emplacement et conserve la base de données source d’origine.
- Remplacer la base de données : Restaurez les données sur la même instance de SAP HANA que la source d’origine. Cette option remplace la base de données d’origine.
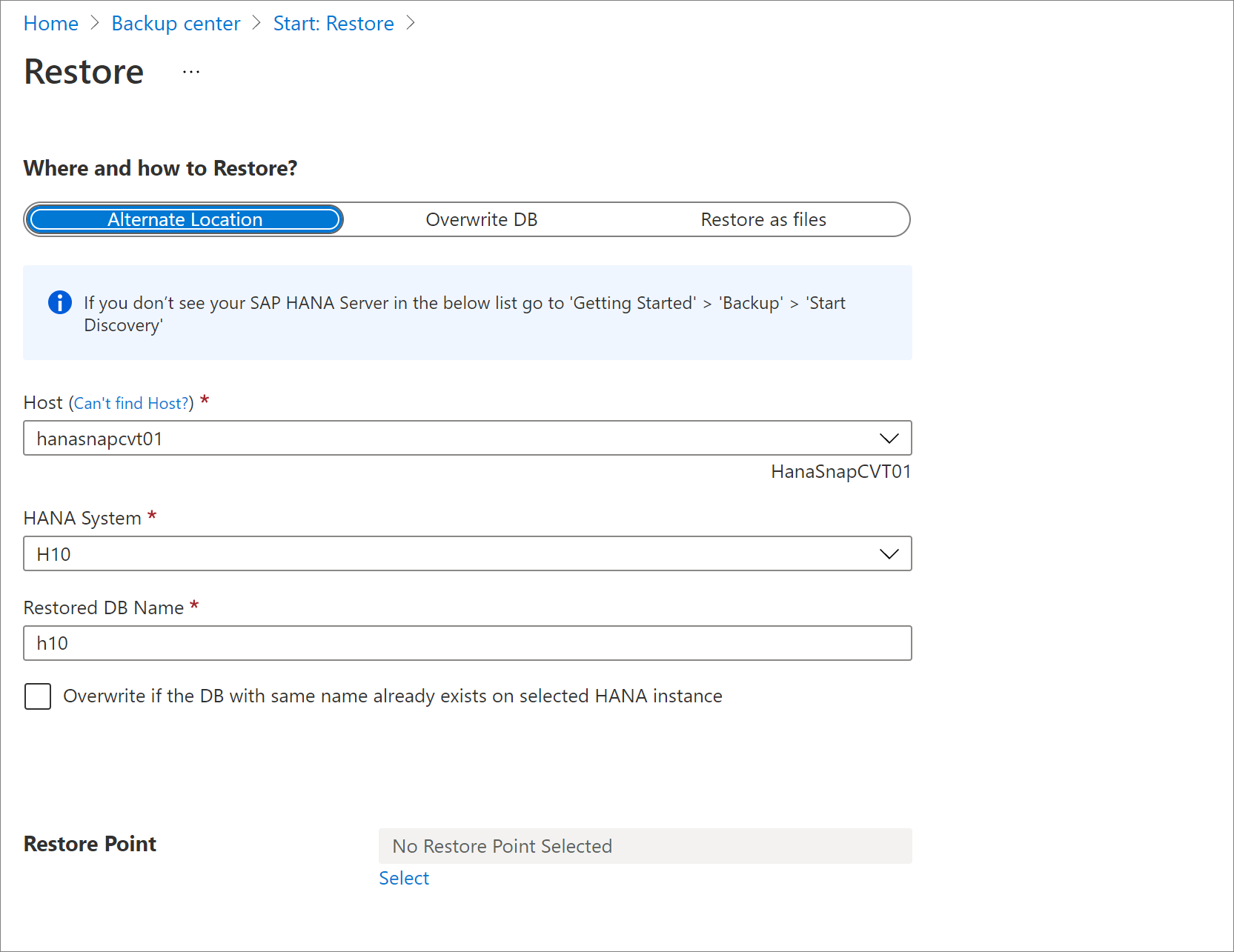

Notes
Pendant la restauration (applicable au scénario d’ adresse IP virtuelle/d’équilibreur de charge uniquement), si vous essayez de restaurer une sauvegarde sur le nœud cible après avoir modifié le mode HSR en tant que HSR autonome ou cassant avant la restauration, comme recommandé par SAP, assurez-vous que Load Balancer est pointé vers le nœud cible.
Exemples de scénarios :
- Si vous utilisez hdbuserstore set SYSTEMKEY localhost dans votre script de préinscription, il n’y aura aucun problème pendant la restauration.
- Si votre *hdbuserstore est défini sur
SYSTEMKEY <load balancer host/ip>dans votre script de préinscription et que vous essayez de restaurer la sauvegarde sur le nœud cible, assurez-vous que l’équilibreur de charge pointe vers le nœud cible qui doit être restauré.
Restaurer à un autre emplacement
Dans le volet Restaurer, sous Où et comment effectuer la restauration ?, sélectionnez Autre emplacement.
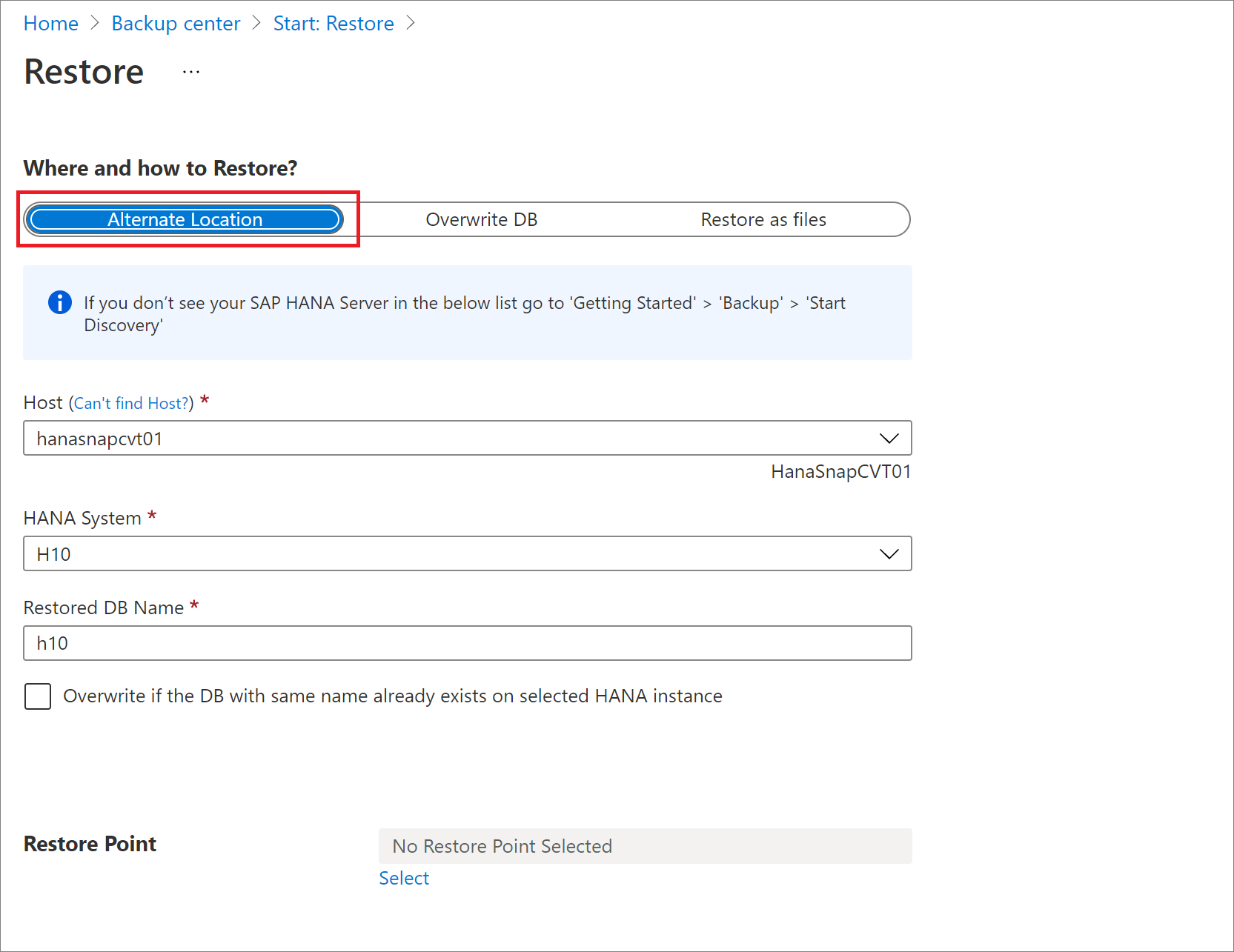
Sélectionnez le nom de l’hôte SAP HANA et le nom de l’instance dans lesquels vous souhaitez restaurer la base de données.
Vérifiez si l’instance SAP HANA cible est prête à être restaurée en vérifiant son niveau de préparation à la sauvegarde. Pour plus d’informations, consultez Prérequis.
Dans la boîte de dialogue Nom de la base de données restaurée, indiquez le nom de la base de données cible.
Notes
Les restaurations SDC (Single Database Container) doivent suivre ces contrôles.
Si elle est prête, cochez la case Remplacer si une base de données du même nom existe déjà sur l’instance HANA sélectionnée.
Dans Sélectionner un point de restauration, sélectionnez Journaux (point dans le temps) pour effectuer une restauration vers un point spécifique dans le temps. Ou sélectionnez Complète et différentielle pour effectuer une restauration à un point de récupération spécifique.
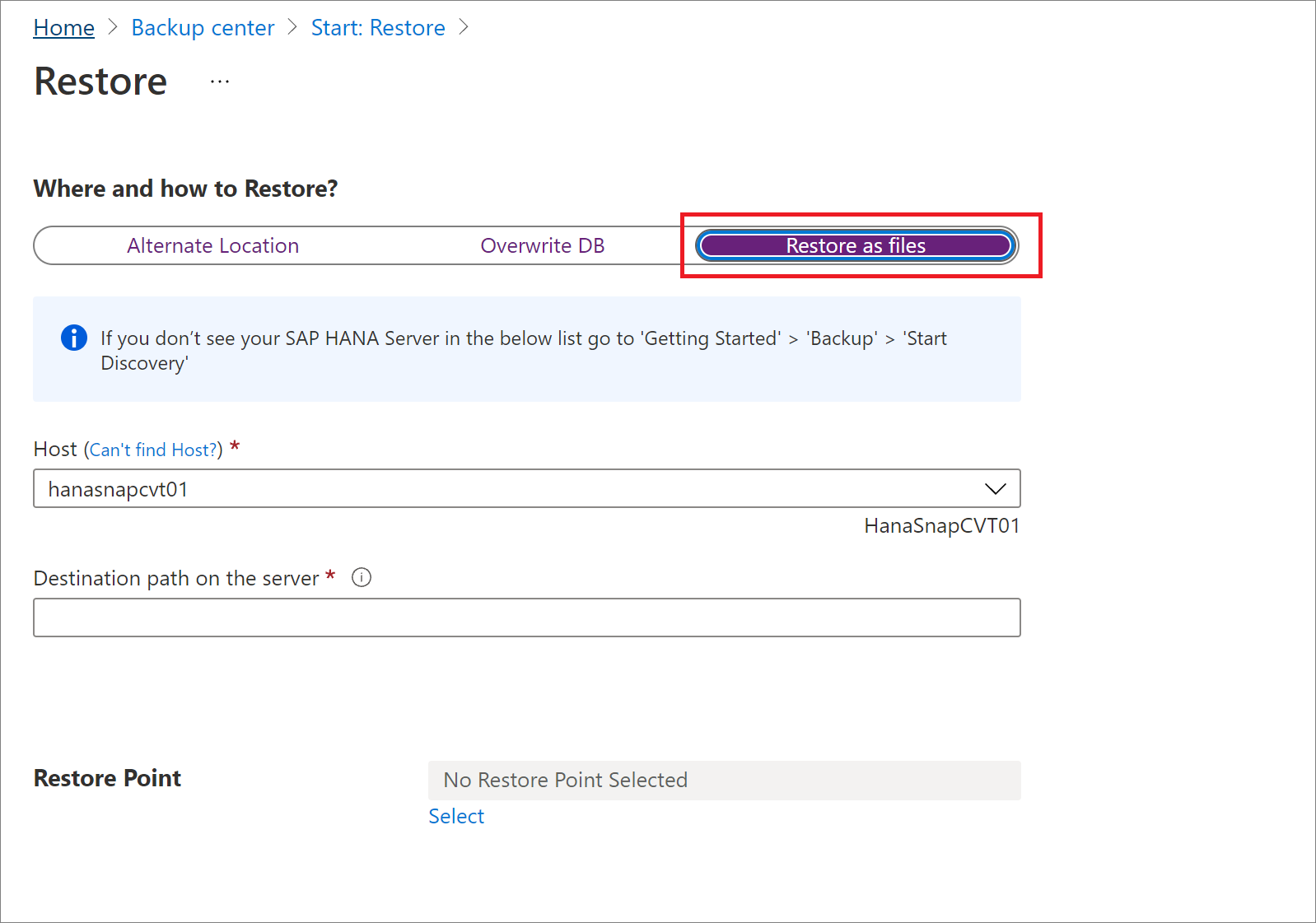
Restaurer sous forme de fichiers
Notes
L’option Restaurer sous forme de fichiers ne fonctionne pas sur les partages CIFS, mais elle fonctionne pour le système NFS.
Pour restaurer les données de sauvegarde sous forme de fichiers plutôt que sous forme de base de données, sélectionnez Restaurer sous forme de fichiers. Une fois les fichiers vidés dans un chemin spécifié, vous pouvez placer ces fichiers sur n’importe quel ordinateur SAP HANA afin de les y restaurer sous forme de base de données. Étant donné que vous pouvez déplacer ces fichiers sur n’importe quel ordinateur, vous pouvez désormais restaurer les données entre les abonnements et les régions.
Dans le volet Restaurer, sous Où et comment effectuer la restauration ?, sélectionnez Restaurer sous forme de fichiers.
Sélectionnez le nom du serveur hôte ou du serveur HANA où vous voulez restaurer les fichiers de sauvegarde.
Dans la zone Chemin de destination sur le serveur, entrez le chemin de dossier du serveur que vous avez sélectionné à l’étape précédente. Il s’agit de l’emplacement où le service doit vider tous les fichiers de sauvegarde nécessaires.
Les fichiers qui sont vidés sont les suivants :
- Fichiers de sauvegarde de base de données
- Fichiers de métadonnées JSON (pour chaque fichier de sauvegarde impliqué)
En règle générale, un chemin de partage réseau, ou le chemin d’un partage de fichiers Azure monté et spécifié comme un chemin de destination, permet aux autres ordinateurs du même réseau ou au même partage de fichiers Azure monté sur ces machines d’accéder plus facilement aux fichiers.
Notes
Pour restaurer les fichiers de sauvegarde de base de données sur un partage de fichiers Azure monté sur la machine virtuelle inscrite cible, assurez-vous que le compte racine dispose d’autorisations en lecture/écriture pour ce partage.
Sélectionnez le point de restauration à partir duquel tous les fichiers et dossiers de sauvegarde seront restaurés.
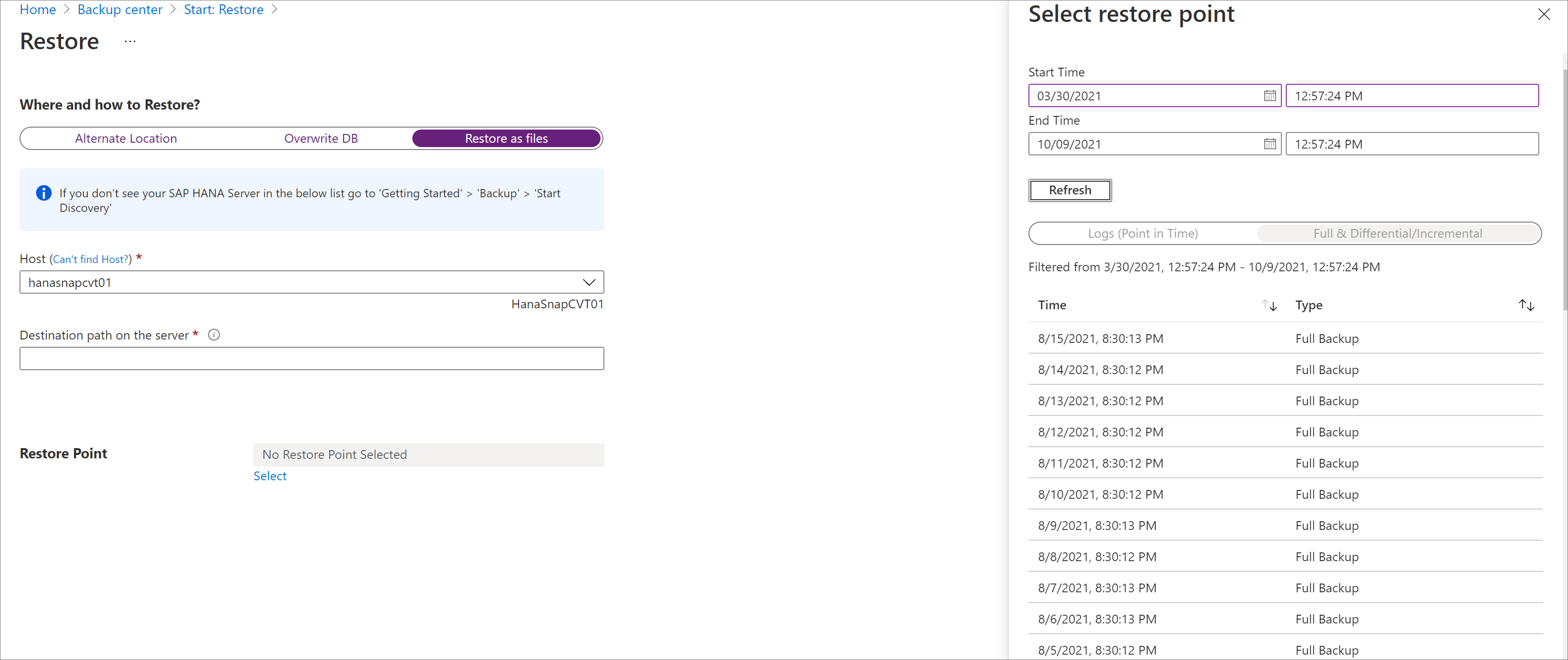
Tous les fichiers de sauvegarde associés au point de restauration sélectionné sont vidés dans le chemin de destination.
En fonction du type de point de restauration choisi (Limite dans le temps ou Complète et différentielle), vous verrez un ou plusieurs dossiers créés dans le chemin de destination. Le dossier nommé Data_<date et heure de restauration> contient les sauvegardes complètes, tandis que l’autre dossier nommé Log contient les sauvegardes de fichiers journaux et d’autres sauvegardes (notamment les sauvegardes différentielles et incrémentielles).
Notes
Si vous avez sélectionné Restaurer à un point dans le temps, les fichiers journaux qui ont été vidés dans la machine virtuelle cible peuvent contenir des journaux ultérieurs au point dans le temps choisi pour la restauration. La Sauvegarde Azure procède ainsi pour que les sauvegardes des fichiers journaux de tous les services HANA soient disponibles pour une restauration cohérente et réussie jusqu’au point dans le temps choisi.
Déplacez les fichiers restaurés vers le serveur SAP HANA où vous souhaitez les restaurer sous forme de base de données, puis effectuez les étapes suivantes :
a. Définissez des autorisations pour le dossier ou le répertoire où sont stockés les fichiers de sauvegarde en exécutant la commande suivante :
chown -R <SID>adm:sapsys <directory>b. Exécutez l’ensemble de commandes suivant en tant que
<SID>adm:su: <sid>admc. Générez le fichier catalogue pour la restauration. Extrayez le BackupId du fichier de métadonnées JSON pour la sauvegarde complète, car vous en aurez besoin plus tard pour l’opération de restauration. Assurez-vous que les sauvegardes complètes et celles de fichiers journaux (non présentes dans la récupération des sauvegardes complètes) se trouvent dans des dossiers différents et supprimez les fichiers de métadonnées JSON de ces dossiers. Exécutez :
hdbbackupdiag --generate --dataDir <DataFileDir> --logDirs <LogFilesDir> -d <PathToPlaceCatalogFile><DataFileDir>: dossier qui contient les sauvegardes complètes.<LogFilesDir>: dossier qui contient les sauvegardes de fichiers journaux, les sauvegardes différentielles et les sauvegardes incrémentielles. Pour la restauration des sauvegardes complètes, étant donné que le dossier Log n’est pas créé, ajoutez un répertoire vide.<PathToPlaceCatalogFile>: dossier dans lequel le fichier catalogue généré doit être placé.
d. Vous pouvez effectuer une restauration à l’aide du fichier catalogue qui vient d’être généré via HANA Studio, ou exécutez la requête de restauration de l’outil HDBSQL SAP HANA avec ce catalogue nouvellement généré. Les requêtes HDBSQL sont listées ci-dessous :
Pour ouvrir l’invite HDBSQL, exécutez la commande suivante :
hdbsql -U AZUREWLBACKUPHANAUSER -d systemDBPour restaurer à une limite dans le temps :
Si vous créez une base de données restaurée, exécutez la commande HDBSQL pour créer une base de données
<DatabaseName>, puis arrêtez la base de données à restaurer avec la commandeALTER SYSTEM STOP DATABASE <db> IMMEDIATE. Toutefois, si vous restaurez uniquement une base de données existante, exécutez la commande HDBSQL pour arrêter la base de données.Exécutez ensuite la commande suivante pour restaurer la base de données :
RECOVER DATABASE FOR <db> UNTIL TIMESTAMP <t1> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> USING BACKUP_ID <bkId> CHECK ACCESS USING FILE<DatabaseName>: nom de la nouvelle base de données ou de la base de données existante que vous souhaitez restaurer.<Timestamp>: horodatage exact de la restauration à partir d’un point dans le temps.<DatabaseName@HostName>: nom de la base de données dont la sauvegarde est utilisée pour la restauration, et nom du serveur hôte ou du serveur SAP HANA sur lequel réside cette base de données. L’optionUSING SOURCE <DatabaseName@HostName>spécifie que la sauvegarde de données (utilisée pour la restauration) est celle d’une base de données avec un SID ou un nom différent de celui de la machine SAP HANA cible. Il n’est pas nécessaire de spécifier les restaurations qui sont effectuées sur le même serveur HANA à partir duquel la sauvegarde est effectuée.<PathToGeneratedCatalogInStep3>: chemin du fichier catalogue généré à l’étape C.<DataFileDir>: dossier qui contient les sauvegardes complètes.<LogFilesDir>: dossier qui contient les sauvegardes de fichiers journaux, les sauvegardes différentielles et les sauvegardes incrémentielles (s’il en existe).<BackupIdFromJsonFile>: BackupId qui a été extrait à l’étape C.
Pour restaurer une sauvegarde complète ou différentielle particulière :
Si vous créez une base de données restaurée, exécutez la commande HDBSQL pour créer une base de données
<DatabaseName>, puis arrêtez la base de données à restaurer avec la commandeALTER SYSTEM STOP DATABASE <db> IMMEDIATE. Toutefois, si vous restaurez uniquement une base de données existante, exécutez la commande HDBSQL pour arrêter la base de données :RECOVER DATA FOR <DatabaseName> USING BACKUP_ID <BackupIdFromJsonFile> USING SOURCE '<DatabaseName@HostName>' USING CATALOG PATH ('<PathToGeneratedCatalogInStep3>') USING DATA PATH ('<DataFileDir>') CLEAR LOG<DatabaseName>: nom de la nouvelle base de données ou de la base de données existante que vous souhaitez restaurer.<Timestamp>: horodatage exact de la restauration à partir d’un point dans le temps.<DatabaseName@HostName>: nom de la base de données dont la sauvegarde est utilisée pour la restauration, et nom du serveur hôte ou du serveur SAP HANA sur lequel réside cette base de données. L’optionUSING SOURCE <DatabaseName@HostName>spécifie que la sauvegarde de données (utilisée pour la restauration) est celle d’une base de données avec un SID ou un nom différent de celui de la machine SAP HANA cible. Il n’est donc pas nécessaire de spécifier les restaurations qui sont effectuées sur le même serveur HANA à partir duquel la sauvegarde est effectuée.<PathToGeneratedCatalogInStep3>: chemin du fichier catalogue généré à l’étape C.<DataFileDir>: dossier qui contient les sauvegardes complètes.<LogFilesDir>: dossier qui contient les sauvegardes de fichiers journaux, les sauvegardes différentielles et les sauvegardes incrémentielles (s’il en existe).<BackupIdFromJsonFile>: BackupId qui a été extrait à l’étape C.
Pour effectuer une restauration à l’aide d’un ID de sauvegarde :
RECOVER DATA FOR <db> USING BACKUP_ID <bkId> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> CHECK ACCESS USING FILEExemples :
Restauration SAP HANA SYSTEM sur le même serveur :
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERestauration de locataire SAP HANA sur le même serveur :
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERestauration SAP HANA SYSTEM sur un autre serveur :
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERestauration de locataire SAP HANA sur un autre serveur :
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE

Restauration partielle en tant que fichiers
Le service Sauvegarde Azure détermine la chaîne de fichiers à télécharger lors d’une restauration sous forme de fichiers. Toutefois, il existe des scénarios où vous ne souhaiterez peut-être pas retélécharger l’intégralité du contenu.
Par exemple, vous pouvez avoir une stratégie de sauvegardes complètes hebdomadaires, de sauvegardes différentielles quotidiennes et de journaux, et avoir déjà téléchargé des fichiers pour une sauvegarde différentielle particulière. Vous avez constaté que ce n’était pas le bon point de récupération et vous avez décidé de télécharger la sauvegarde différentielle du lendemain. Maintenant, vous avez simplement besoin du fichier de sauvegarde différentielle, car vous avez déjà la sauvegarde complète de départ. Avec la capacité de restauration partielle sous forme de fichiers fournie par la Sauvegarde Azure, vous pouvez désormais exclure la sauvegarde complète de la chaîne de téléchargement et télécharger uniquement la sauvegarde différentielle.
Exclusion de types de fichiers de sauvegarde
ExtensionSettingOverrides.json est un fichier JSON qui contient des valeurs de remplacement pour plusieurs paramètres du service Sauvegarde Azure pour SQL. Pour une opération de restauration partielle sous forme de fichiers, vous devez ajouter un nouveau champ JSON : RecoveryPointsToBeExcludedForRestoreAsFiles. Ce champ contient une valeur de chaîne qui indique quels types de points de récupération doivent être exclus de l’opération de restauration sous forme de fichiers suivante.
Sur l’ordinateur cible où les fichiers doivent être téléchargés, accédez au dossier opt/msawb/bin.
Créez un fichier JSON nommé ExtensionSettingOverrides.JSON s’il n’existe pas encore.
Ajoutez la paire clé-valeur JSON suivante :
{ "RecoveryPointsToBeExcludedForRestoreAsFiles": "ExcludeFull" }Modifiez les autorisations et la propriété du fichier :
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.jsonAucun service ne doit être redémarré. Le service Sauvegarde Azure tentera d’exclure les types de sauvegarde de la chaîne de restauration comme indiqué dans ce fichier.
RecoveryPointsToBeExcludedForRestoreAsFiles n’accepte que certaines valeurs qui indiquent les points de récupération à exclure de la restauration. Pour SAP HANA, ces valeurs sont les suivantes :
ExcludeFull. Les autres sauvegardes (différentielles, incrémentielles et journaux) seront téléchargées si elles sont présentes dans la chaîne de point de restauration.ExcludeFullAndDifferential. Les autres sauvegardes (incrémentielles et journaux) seront téléchargées si elles sont présentes dans la chaîne de point de restauration.ExcludeFullAndIncremental. Les autres sauvegardes (différentielles, et journaux) seront téléchargées si elles sont présentes dans la chaîne de point de restauration.ExcludeFullAndDifferentialAndIncremental. Les autres sauvegardes (journaux) seront téléchargées si elles sont présentes dans la chaîne de point de restauration.
Restaurer à un point spécifique dans le temps
Si vous avez sélectionné Journaux d’activité (point dans le temps) comme type de restauration, effectuez les actions suivantes :
Sélectionnez un point de récupération dans le graphe du journal et sélectionnez OK pour choisir le point de restauration.
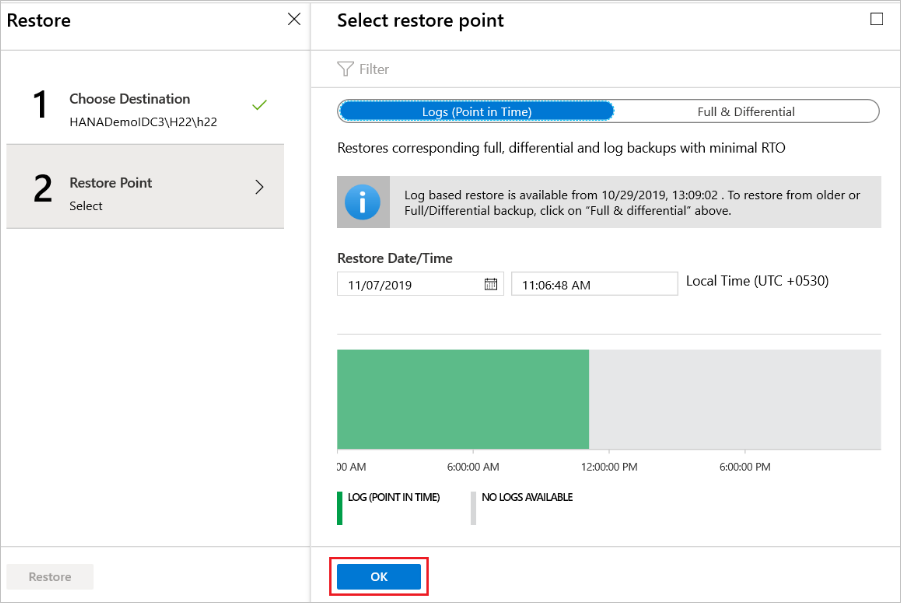
Dans le menu Restaurer, sélectionnez Restaurer pour démarrer le travail de restauration.
Suivez la progression de la restauration dans la zone de Notifications ou en sélectionnant Restaurer les travaux dans le menu de la base de données.

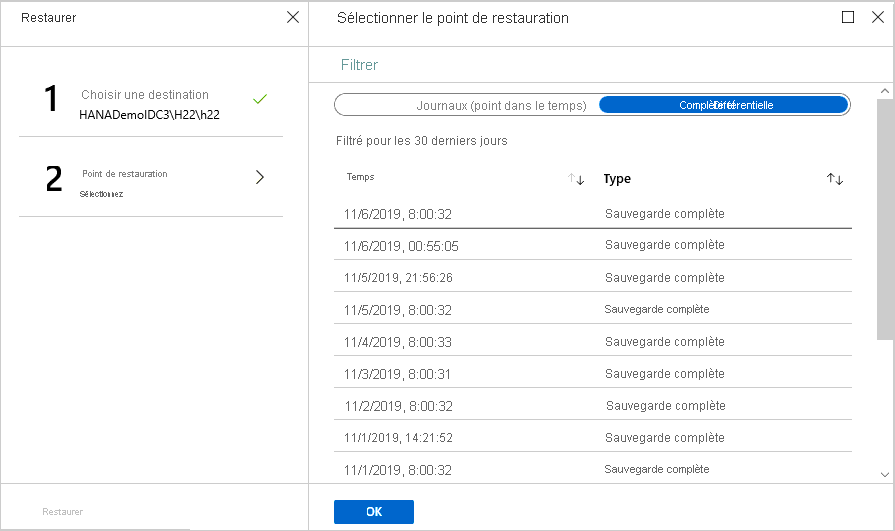
Restaurer à un point de récupération spécifique
Si vous avez sélectionné Complète et différentielle comme type de restauration, effectuez les actions suivantes :
Sélectionnez un point de récupération dans la liste, puis sélectionnez OK pour choisir le point de restauration.
Dans le menu Restaurer, sélectionnez Restaurer pour démarrer le travail de restauration.
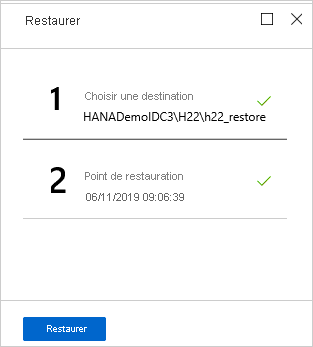
Suivez la progression de la restauration dans la zone de Notifications ou en sélectionnant Restaurer les travaux dans le menu de la base de données.

Notes
Dans les restaurations MDC, une fois que la base de données système est restaurée vers une instance cible, vous devez réexécuter le script de préinscription. C’est à ce moment-là que les restaurations ultérieures de la base de données locataire réussiront. Pour plus d’informations, consultez Restauration de la base de données à conteneurs multiples (MDC).
Restauration interrégion
Parmi les options de restauration, la restauration entre régions (CRR) est celle qui vous permet de restaurer les bases de données SAP HANA hébergées sur des machines virtuelles Azure dans une région secondaire qui est une région jumelée Azure.
Pour commencer à utiliser cette fonctionnalité, consultez Définir la restauration interrégion.
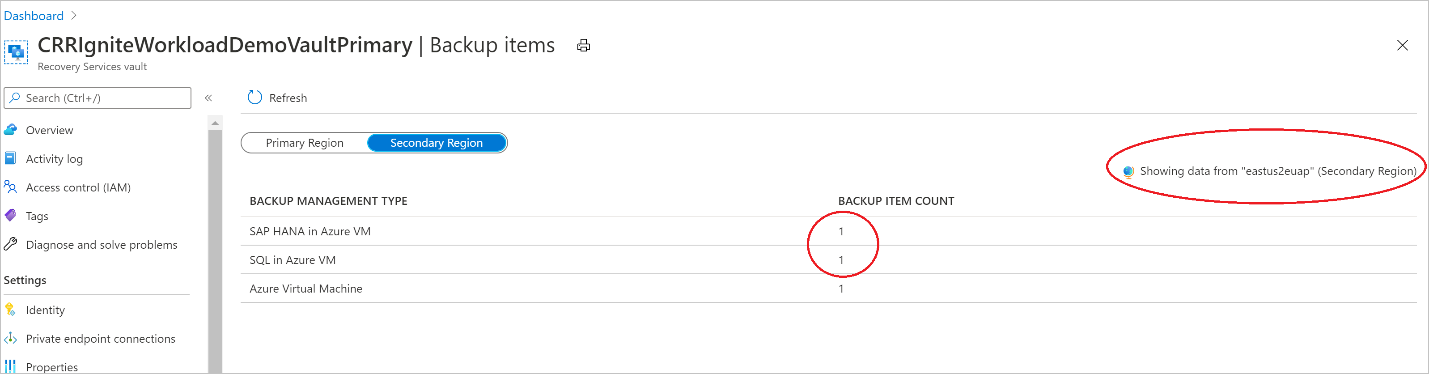
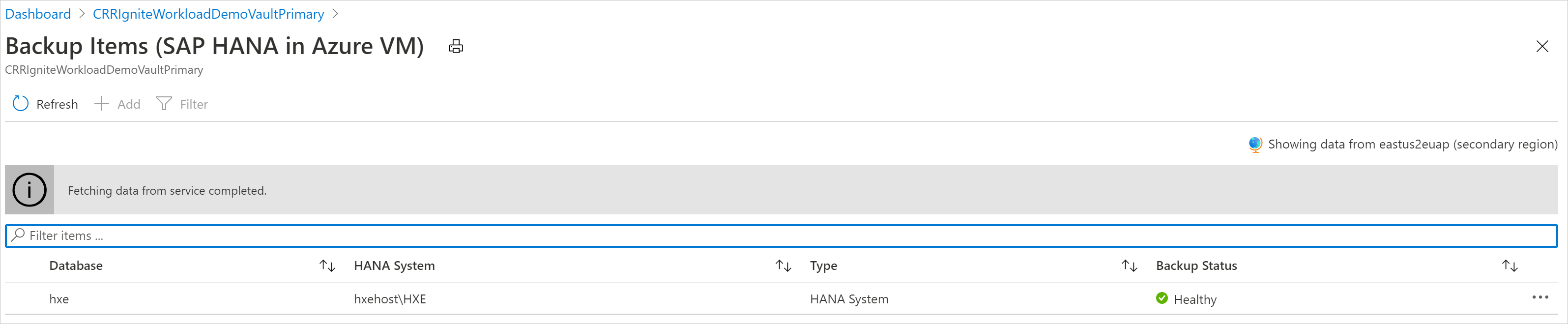
Afficher les éléments de sauvegarde dans la région secondaire
Si la CRR est activée, vous pouvez afficher les éléments de sauvegarde dans la région secondaire.
- Dans le portail Azure, accédez à Coffre Recovery Services, puis sélectionnez Éléments de sauvegarde.
- Cliquez sur Région secondaire pour afficher les éléments de la région secondaire.
Notes
Seuls les types de gestion de sauvegardes qui prennent en charge la fonctionnalité CRR s’affichent dans la liste. Actuellement, seule la prise en charge de la restauration de données de région secondaire vers une région secondaire est autorisée.
Effectuer la restauration dans la région secondaire
L’expérience utilisateur de restauration dans la région secondaire est similaire à celle de la région primaire. Quand vous configurez des informations dans le panneau Configuration de la restauration, vous êtes invité à fournir uniquement les paramètres de la région secondaire. Un coffre doit exister dans la région secondaire et le serveur SAP HANA doit être inscrit dans le coffre de la région secondaire.
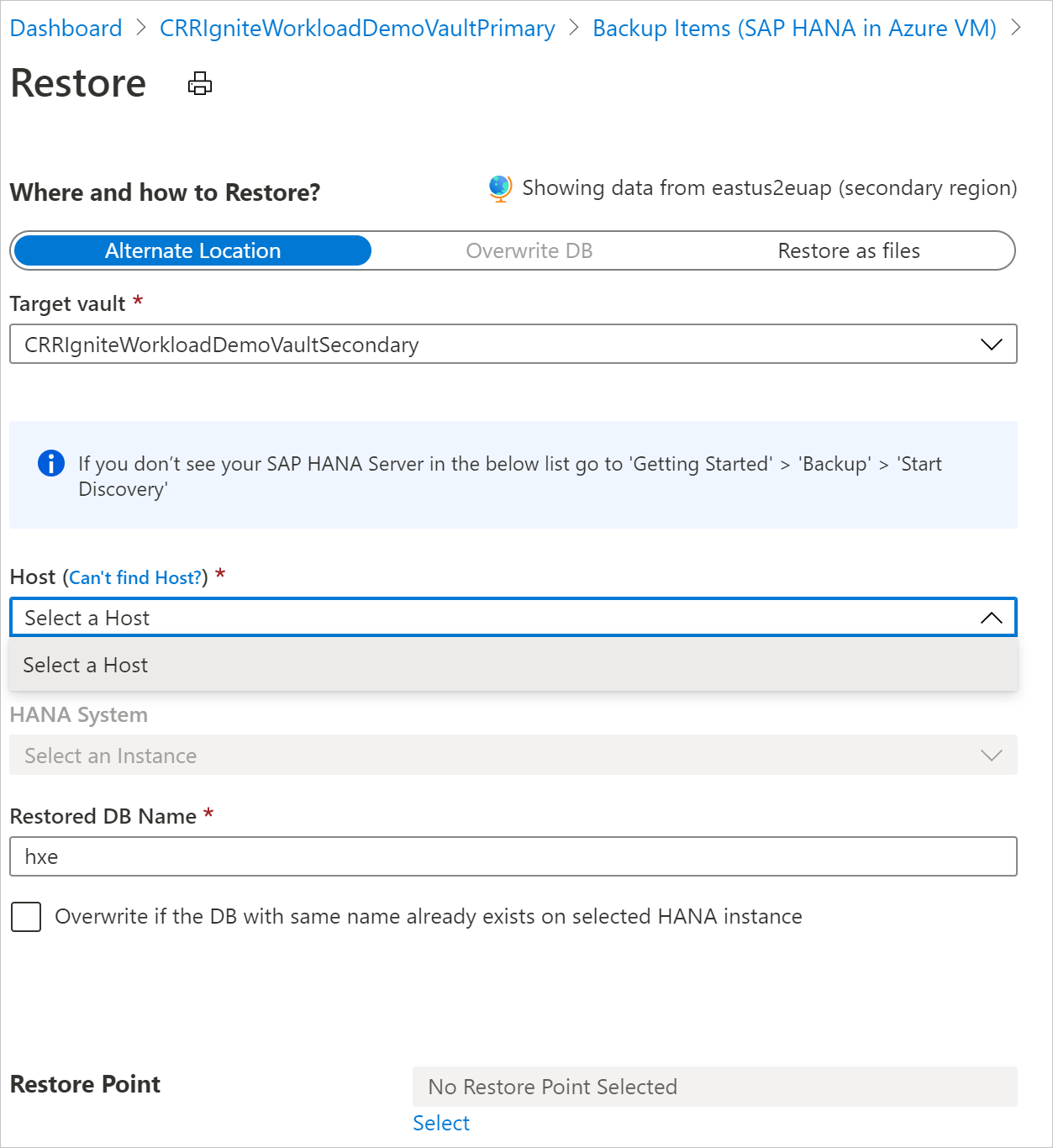
Notes
- Une fois la restauration déclenchée, et pendant la phase de transfert des données, le travail de restauration ne peut pas être annulé.
- Les niveaux de rôle et d’accès nécessaires pour effectuer l’opération de restauration interrégions sont le rôle Opérateur de sauvegarde dans l’abonnement et l’accès Contributeur(écriture) sur les machines virtuelles source et cible. Pour afficher les travaux de sauvegarde, l’autorisation minimale exigée dans l’abonnement est Lecteur de sauvegarde.
- Pour que les données de sauvegarde soient disponibles dans la région secondaire, l’objectif de point de récupération (RPO) doit être de 12 heures. Ainsi, quand vous activez la restauration CRR (restauration interrégionale), l’objectif RPO de la région secondaire est de 12 heures + la durée de la fréquence de journalisation (qui peut être définie sur une valeur minimale de 15 minutes).
Découvrez les exigences de rôle minimales pour la restauration inter-régions.
Monitorer les travaux de restauration de la région secondaire
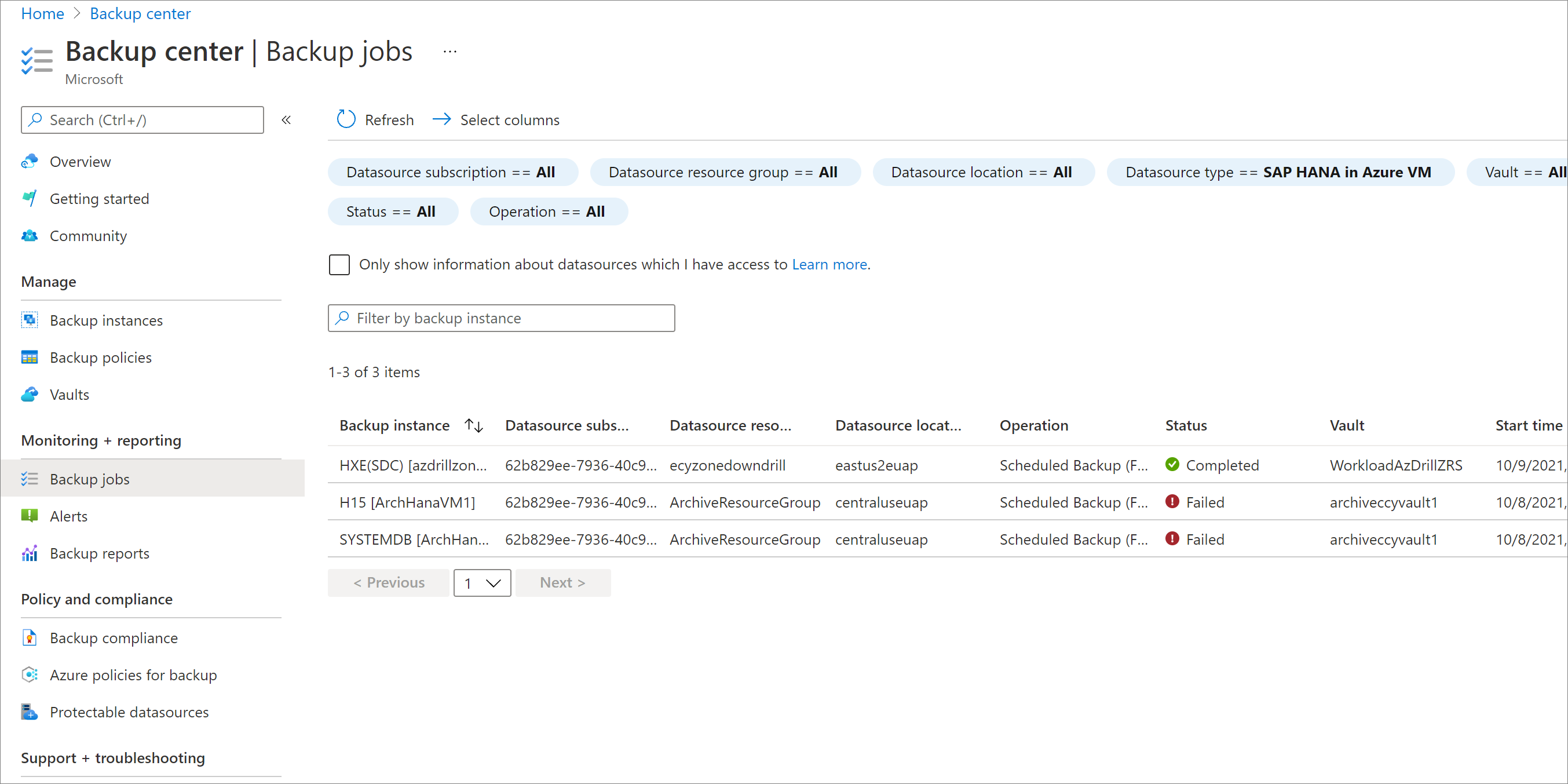
Sur le portail Azure, accédez à Centre de sauvegarde, puis sélectionnez Travaux de sauvegarde.
Pour afficher les travaux dans la région secondaire, filtrez Operation sur CrossRegionRestore.

Restauration avec plusieurs abonnements
Sauvegarde Azure vous permet désormais de restaurer une base de données SAP HANA sur n’importe quel abonnement (conformément aux exigences RBAC Azure suivantes) à partir du point de restauration. Par défaut, Sauvegarde Azure restaure sur le même abonnement que celui où les points de restauration sont disponibles.
Avec la restauration avec plusieurs abonnements (CSR), vous avez la possibilité de restaurer n’importe quel abonnement et tout coffre sous votre tenant (locataire) si des autorisations de restauration sont disponibles. Par défaut, une CSR est activée sur tous les coffres Recovery Services (coffres existants et nouvellement créés).
Notes
- Vous pouvez déclencher la restauration avec plusieurs abonnements à partir d’un coffre Recovery Services.
- La CSR est prise en charge uniquement pour des sauvegardes basées sur une diffusion en continu/Backint et n’est pas prise en charge pour des sauvegardes basées sur des instantanés.
- La restauration inter-région (CRR) avec CSR n’est pas prise en charge.
Restauration entre abonnements sur un coffre avec point de terminaison privé activé
Pour effectuer une restauration entre abonnements sur un coffre avec point de terminaison privé activé :
- Dans le coffre Recovery Services source, accédez à l’onglet Mise en réseau.
- Accédez à la section Accès privé et créez des Points de terminaison privés.
- Sélectionnez l’abonnement du coffre cible dans lequel vous souhaitez effectuer la restauration.
- Dans la section Réseau virtuel, sélectionnez le réseau virtuel de la machine virtuelle cible que vous souhaitez restaurer entre les abonnements.
- Créez le Point de terminaison privé et déclenchez le processus de restauration.
Conditions requises de RBAC Azure
| Type d'opération | Opérateur de sauvegarde | Coffre Recovery Services | Autre opérateur |
|---|---|---|---|
| Restaurer une base de données ou restaurer en tant que fichiers | Virtual Machine Contributor |
Machine virtuelle source qui a été sauvegardée | Au lieu d’un rôle intégré, vous pouvez utiliser un rôle personnalisé qui dispose des autorisations suivantes : - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
Virtual Machine Contributor |
Machine virtuelle cible dans laquelle la base de fichiers sera restaurée ou des fichiers seront créés. | Au lieu d’un rôle intégré, vous pouvez utiliser un rôle personnalisé qui dispose des autorisations suivantes : - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
|
Backup Operator |
Coffre Recovery Services cible |
Par défaut, la CSR est activée sur le coffre Recovery Services. Pour mettre à jour les paramètres de restauration du coffre Recovery Services, accédez à Propriétés, puis Restauration avec plusieurs abonnements et apportez les modifications nécessaires.

Restauration entre abonnements à l’aide d’Azure CLI
az backup vault create
Ajoutez le paramètre cross-subscription-restore-state qui vous permet de définir l’état CSR du coffre lors de la création et de la mise à jour du coffre.
az backup recoveryconfig show
Ajoutez le paramètre --target-subscription-id qui vous permet de fournir l’abonnement cible en tant qu’entrée lors du déclenchement de la restauration avec plusieurs abonnements pour des sources de données SQL ou HANA.
Exemple :
az backup vault create -g {rg_name} -n {vault_name} -l {location} --cross-subscription-restore-state Disable
az backup recoveryconfig show --restore-mode alternateworkloadrestore --backup-management-type azureworkload -r {rp} --target-container-name {target_container} --target-item-name {target_item} --target-resource-group {target_rg} --target-server-name {target_server} --target-server-type SQLInstance --target-subscription-id {target_subscription} --target-vault-name {target_vault} --workload-type SQLDataBase --ids {source_item_id}