Qu’est-ce qu’Azure Chaos Studio ?
Azure Chaos Studio est un service managé qui utilise l’ingénierie du chaos pour vous aider à mesurer, comprendre et améliorer votre application cloud et la résilience du service. L’ingénierie du chaos est une méthodologie par laquelle vous injectez des erreurs réelles dans votre application pour exécuter des expériences d’injection de panne contrôlées.
La résilience est la capacité d’un système à gérer et à récupérer des interruptions. Les interruptions d’application peuvent entraîner des erreurs et des défaillances susceptibles d’affecter votre entreprise ou votre mission. Que vous développiez, migriez ou utilisiez des applications Azure, il est important de valider et d’améliorer la résilience de votre application.
Chaos Studio vous aide à éviter les conséquences négatives en validant le fait que votre application répond efficacement aux interruptions et aux défaillances. Vous pouvez utiliser Chaos Studio pour tester la résilience contre les incidents réels, tels que les pannes ou une utilisation élevée du processeur sur des machines virtuelles.
La vidéo suivante fournit plus d’informations sur Chaos Studio :
Scénarios Chaos Studio
Vous pouvez utiliser l’ingénierie du chaos pour différents scénarios de validation de résilience qui couvrent le cycle de vie du développement de service et des opérations. Il existe deux types de scénarios :
- Décalage vers la droite : ces scénarios utilisent un environnement de production ou de préproduction. En règle générale, vous effectuez des scénarios de décalage vers la droite avec un trafic client réel ou une charge simulée.
- Décalage vers la gauche : ces scénarios peuvent utiliser un environnement de développement ou de test partagé. Vous pouvez effectuer des scénarios de décalage vers la gauche sans aucun trafic client réel.
Vous pouvez utiliser Chaos Studio pour les scénarios d’ingénierie de chaos courants suivants :
- Reproduisez un incident qui a affecté votre application afin de mieux comprendre la défaillance. Veiller à ce que les réparations post-incident empêchent l’incident de se reproduire
- Vous préparer à un événement majeur ou à une saison avec une charge, une mise à l’échelle, des performances et une validation de résilience appropriés au moment voulu
- Effectuez des exercices de continuité d’activité et reprise d’activité pour vérifier que votre application peut récupérer rapidement et préserver des données critiques en cas de sinistre.
- Exécutez des exercices de haute disponibilité pour tester la résilience des applications contre des défaillances telles que des pannes régionales, des erreurs de configuration du réseau, des événements à forte sollicitation ou des problèmes de voisins bruyants.
- Développer des points de référence des performances d’application
- Planifier les besoins en capacité pour les environnements de production
- Exécuter des tests de contrainte ou des tests de charge
- Veiller à ce que les services migrés à partir d’un environnement local ou d’un autre environnement cloud restent résilients aux défaillances connues
- Renforcer la confiance envers les services basés sur les architectures natives cloud
- Valider le fait que les outils de site dynamiques, les données d’observation et les processus d’appel fonctionnent toujours dans des conditions inattendues
Pour la plupart de ces scénarios, vous créez d’abord la résilience en utilisant des expériences de chaos ad hoc. Ensuite, vous vérifiez en permanence que de nouveaux déploiements ne feront pas régresser la résilience. Pour vérifier, vous exécutez des expériences de chaos en tant que portes de déploiement dans vos pipelines d’intégration continue/de déploiement continu.
Fonctionnement de Chaos Studio
Avec Chaos Studio, vous pouvez orchestrer l’injection de pannes sécurisée et contrôlée sur vos ressources Azure. Les expériences de chaos sont au cœur de Chaos Studio. Une expérience de chaos décrit les erreurs à exécuter et les ressources sur lesquelles les exécuter. Vous pouvez organiser les erreurs à exécuter en parallèle ou en séquence, en fonction de vos besoins.
Chaos Studio prend en charge deux types d’erreurs :
- service-direct : ces erreurs s’exécutent directement sur une ressource Azure, sans aucune installation ou instrumentation. Des exemples incluent le redémarrage d’un cluster Azure Cache pour Redis ou l’ajout d’une latence réseau à des pods Azure Kubernetes Service (AKS).
- Basée sur l’agent : ces erreurs s’exécutent sur des machines virtuelles ou des groupes de machines virtuelles identiques pour effectuer des échecs dans l’invité. Les exemples incluent l’application d’une sollicitation sur la mémoire virtuelle ou l’arrêt d’un processus.
Chaque erreur a des paramètres spécifiques que vous pouvez contrôler, par exemple le processus à arrêter, ou la quantité de sollicitation de mémoire à générer.
Lorsque vous générez une expérience de chaos, vous définissez une ou plusieurs étapes qui s’exécutent séquentiellement. Chaque étape contient une ou plusieurs branches qui s’exécutent en parallèle au sein de l’étape. Chaque branche contient une ou plusieurs actions, telles que l’injection d’une erreur ou l’attente pendant une certaine durée.
Vous organisez des ressources cibles sur lesquelles exécuter des erreurs dans des groupes appelés sélecteurs afin que vous puissiez référencer facilement un groupe de ressources dans chaque action.
Le diagramme suivant montre la disposition d’une expérience de chaos dans Chaos Studio :
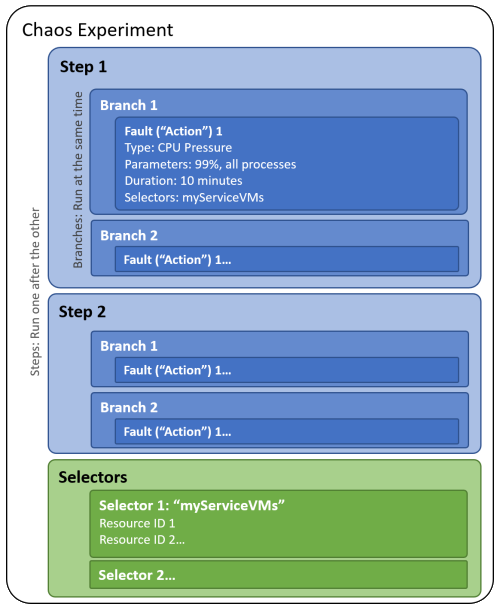
Une expérience de chaos est une ressource Azure dans un abonnement et un groupe de ressources. Vous pouvez utiliser le portail Azure ou l’API REST de Chaos Studio pour créer, mettre à jour, démarrer, annuler et afficher l’état des expériences.
Étapes suivantes
Maintenant que vous comprenez comment utiliser l’ingénierie du chaos, vous êtes prêt à :