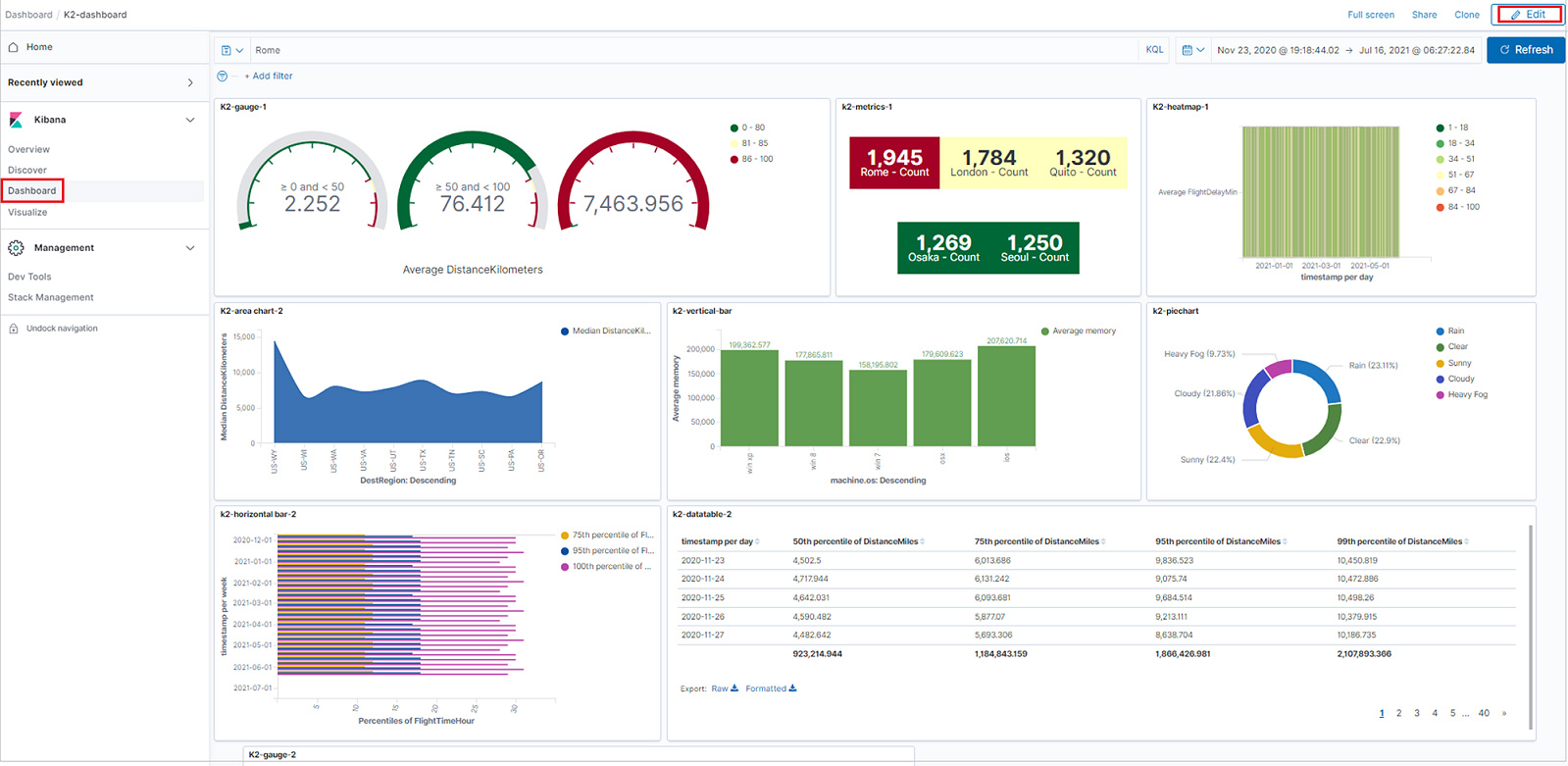
Visualiser des données à partir d’Azure Data Explorer dans Kibana avec le connecteur open source K2Bridge
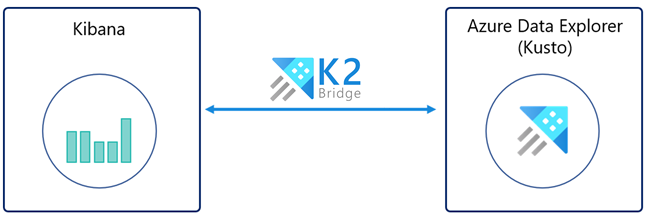
K2Bridge (Kibana-Kusto Bridge) vous permet d’utiliser Azure Data Explorer comme source de données et de visualiser ces données dans Kibana. K2Bridge est une application conteneurisée open source. Elle fait office de proxy entre une instance Kibana et un cluster Azure Data Explorer. Cet article explique comment utiliser K2Bridge pour créer cette connexion.
K2Bridge traduit les requêtes Kibana en langage de requête Kusto (KQL) et renvoie les résultats d’Azure Data Explorer à Kibana.
K2Bridge prend en charge les onglets Discover (Découvrir), Visualize (Visualiser) et Dashboard (Tableau de bord) de Kibana.
Avec l’onglet Discover, vous pouvez :
- Effectuer une recherche dans les données et les explorer
- Filtrer les résultats
- Ajouter ou supprimer des champs dans la grille de résultats
- Afficher le contenu des enregistrements
- Enregistrer et partager les recherches
Avec l’onglet Visualize, vous pouvez :
- Créez des visualisations comme des graphiques à barres, des graphiques en secteurs, des tables de données, des cartes thermiques, etc.
- Enregistrer une visualisation
Avec l’onglet Dashboard, vous pouvez :
- Créer des panneaux en utilisant des visualisations nouvelles ou enregistrées.
- Enregistrer un tableau de bord.
L’image suivante montre une instance Kibana liée à Azure Data Explorer par K2Bridge. L’expérience utilisateur dans Kibana est inchangée.

Prérequis
Avant de pouvoir visualiser des données à partir d’Azure Data Explorer dans Kibana, préparez les éléments suivants :
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Vous aurez besoin de l’URL du cluster et du nom de la base de données.
- Helm V3, gestionnaire de package de Kubernetes.
- Cluster Azure Kubernetes Service (AKS) ou tout autre cluster Kubernetes. Utilisez la version 1.21.2 ou ultérieure, avec au minimum trois nœuds Azure Kubernetes Service. La version 1.21.2 a été testée et vérifiée. Si vous avez besoin d’un cluster AKS, consultez la documentation indiquant comment déployer un cluster AKS avec Azure CLI ou avec le portail Azure.
- Un principal de service Microsoft Entra autorisé à afficher les données dans Azure Data Explorer, y compris l’ID client et la clé secrète client. Vous pouvez aussi utiliser une identité managée affectée par le système.
Si vous choisissez d’utiliser un principal de service Microsoft Entra, vous devez créer un principal de service Microsoft Entra. Pour l’installation, vous aurez besoin du ClientID et d’un secret. Nous recommandons un principal de service avec autorisation d’affichage et déconseillons l’utilisation d’autorisations de niveau supérieur. Pour attribuer des autorisations, consultez Gérer les autorisations de base de données dans le Portail Azure ou utilisez les commandes de gestion pour Gérer les rôles de sécurité de la base de données.
Si vous choisissez d’utiliser une identité affectée par le système, vous devez obtenir l’ID client d’identité managée du pool d’agents (situé dans le groupe de ressources « [MC_xxxx] » généré)
Exécuter K2Bridge sur Azure Kubernetes Service (AKS)
Par défaut, le chart Helm de K2Bridge référence une image disponible publiquement située dans le registre de conteneurs de Microsoft. Ce registre ne nécessite aucune information d’identification.
Téléchargez les charts Helm requis.
Ajoutez la dépendance Elasticsearch à Helm. La dépendance est nécessaire, car K2Bridge utilise une petite instance Elasticsearch interne. L’instance traite les demandes relatives aux métadonnées, telles que les requêtes de modèles d’index et les requêtes enregistrées. Cette instance interne n’enregistre aucune donnée métier. Vous pouvez considérer l’instance comme un détail d’implémentation.
Pour ajouter la dépendance Elasticsearch à Helm, exécutez les commandes suivantes :
helm repo add elastic https://helm.elastic.co helm repo updatePour récupérer le graphique K2Bridge du répertoire charts du dépôt GitHub :
Clonez le dépôt à partir de GitHub.
Accédez au répertoire du dépôt racine K2Bridges.
Exécutez cette commande :
helm dependency update charts/k2bridge
Déployez K2Bridge.
Définissez les variables sur les valeurs correctes applicables à votre environnement.
ADX_URL=[YOUR_ADX_CLUSTER_URL] #For example, https://mycluster.westeurope.kusto.windows.net ADX_DATABASE=[YOUR_ADX_DATABASE_NAME] ADX_CLIENT_ID=[SERVICE_PRINCIPAL_CLIENT_ID] ADX_CLIENT_SECRET=[SERVICE_PRINCIPAL_CLIENT_SECRET] ADX_TENANT_ID=[SERVICE_PRINCIPAL_TENANT_ID]Remarque
Lors de l’utilisation d’une identité managée, la valeur ADX_CLIENT_ID est l’ID de client de l’identité managée située dans le groupe de ressources généré « [MC_xxxx] ». Pour plus d’informations, consultez MC_ groupe de ressources. La ADX_SECRET_ID n’est requise que si vous utilisez un principal de service Microsoft Entra.
Si vous le souhaitez, activez la télémétrie Azure Application Insights. Si vous utilisez Application Insights pour la première fois, créez une ressource Application Insights. Copiez la clé d’instrumentation dans une variable.
APPLICATION_INSIGHTS_KEY=[INSTRUMENTATION_KEY] COLLECT_TELEMETRY=trueInstallez le graphique K2Bridge. Les visualisations et les tableaux de bord sont pris en charge seulement avec Kibana version 7.10. Les étiquettes d’image les plus récentes sont : 6.8_latest et 7.16_latest, qui prennent en charge respectivement Kibana 6.8 et Kibana 7.10. L’image de « 7.16_latest » prend en charge Kibana OSS 7.10.2, et son instance Elasticsearch interne est 7.16.2.
Si un principal de service Microsoft Entra a été utilisé :
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.aadClientSecret="$ADX_CLIENT_SECRET" --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=6.8_latest/7.16_latest] [--set image.repository=$REPOSITORY_NAME/$CONTAINER_NAME] [--set privateRegistry="$IMAGE_PULL_SECRET_NAME"] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]Ou si une identité managée a été utilisée :
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.useManagedIdentity=true --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=7.16_latest] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]Dans Configuration, vous trouverez l’ensemble complet des options de configuration.
La sortie de la commande précédente suggère la prochaine commande Helm pour déployer Kibana. Si vous le souhaitez, exécutez la commande suivante :
helm install kibana elastic/kibana --version 7.17.3 -n k2bridge --set image=docker.elastic.co/kibana/kibana-oss --set imageTag=7.10.2 --set elasticsearchHosts=http://k2bridge:8080Utilisez le réacheminement de port pour accéder à Kibana sur localhost.
kubectl port-forward service/kibana-kibana 5601 --namespace k2bridgeConnectez-vous à Kibana en accédant à http://127.0.0.1:5601.
Exposez Kibana aux utilisateurs. Pour ce faire, il existe plusieurs méthodes. La méthode que vous utilisez dépend en grande partie de votre cas d’usage.
Par exemple, vous pouvez exposer le service en tant que service Load Balancer. Pour ce faire, ajoutez le paramètre --set service.type=LoadBalancer à la commande Helm install Kibana antérieure.
Ensuite, exécutez cette commande :
kubectl get service -w -n k2bridgeLa sortie doit ressembler à ceci :
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana-kibana LoadBalancer xx.xx.xx.xx <pending> 5601:30128/TCP 4m24sVous pouvez ensuite utiliser la valeur EXTERNAL-IP générée qui s’affiche. Utilisez-la pour accéder à Kibana en ouvrant un navigateur et en accédant à <EXTERNAL-IP>:5601.
Configurez des modèles d’index pour accéder à vos données.
Dans une nouvelle instance de Kibana :
- Ouvrez Kibana.
- Accédez à Management (Gestion).
- Sélectionnez Index Patterns (Modèles d’index).
- Créez un modèle d’index. Le nom de l’index doit correspondre exactement au nom de la table ou au nom de la fonction sans astérisque (*). Vous pouvez copier la ligne appropriée à partir de la liste.
Remarque
Pour exécuter K2Bridge sur d’autres fournisseurs Kubernetes, définissez la valeur du paramètre storageClassName Elasticsearch dans values.yaml sur celle suggérée par le fournisseur.
Découvrir des données
Quand Azure Data Explorer est configuré en tant que source de données pour Kibana, vous pouvez utiliser Kibana pour explorer les données.
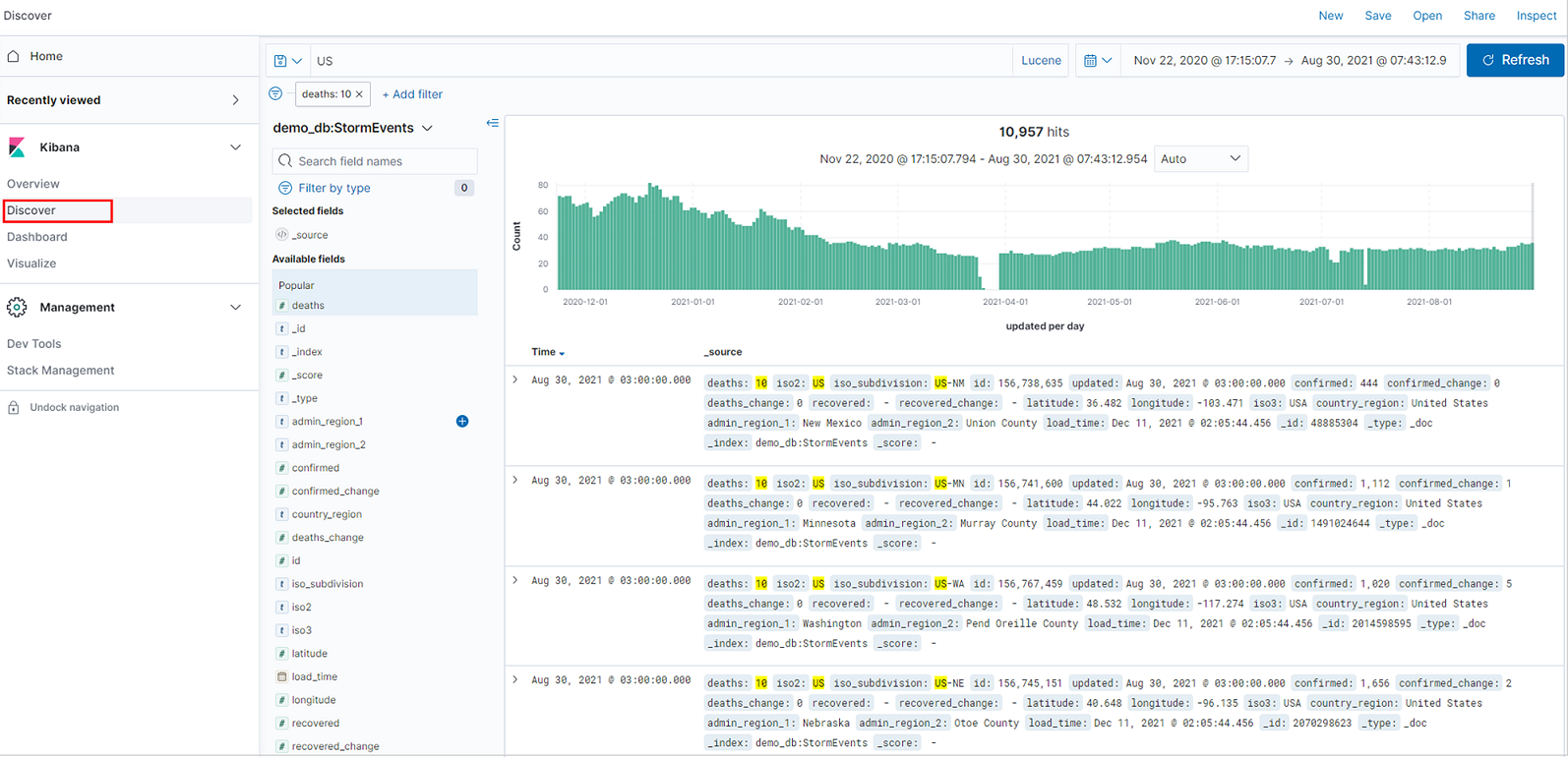
Dans Kibana, sélectionnez l’onglet Discover.
Dans la liste des modèles d’index, sélectionnez un modèle d’index qui définit la source de données à explorer. Ici, le modèle d’index est une table Azure Data Explorer.
Si vos données comportent un champ de filtre d’heure, vous pouvez spécifier l’intervalle de temps. En haut à droite de la page Discover, sélectionnez un filtre de temps. Par défaut, la page affiche les données des 15 dernières minutes.

La table des résultats affiche les 500 premiers enregistrements. Vous pouvez développer un document pour examiner les données des champs au format JSON ou de table.
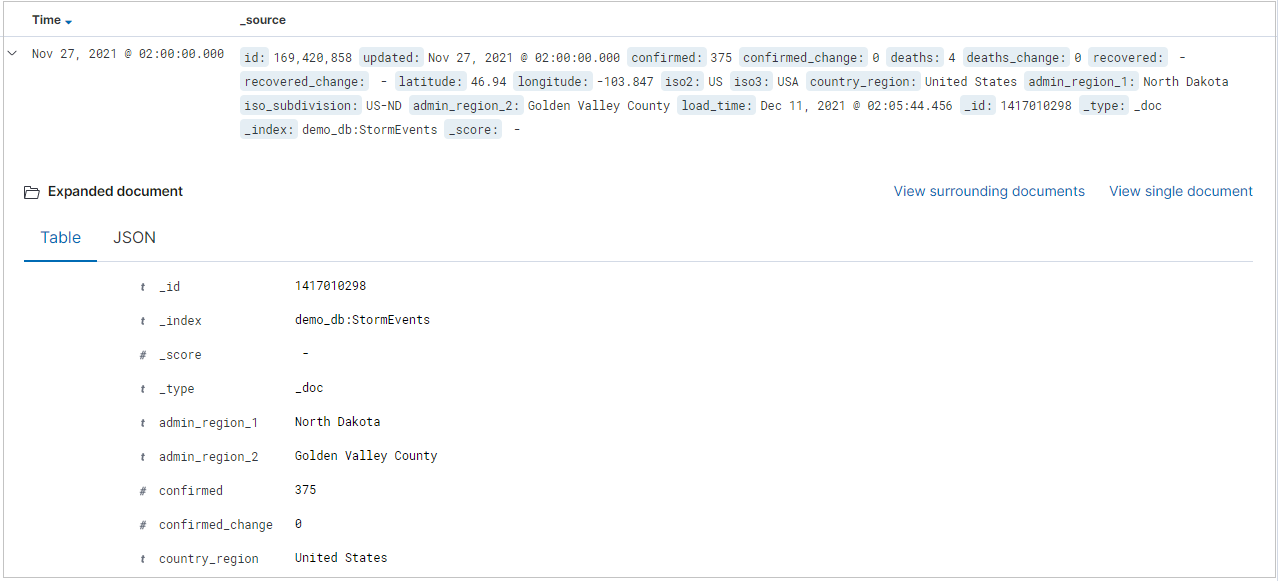
Vous pouvez ajouter des colonnes spécifiques à la table des résultats en sélectionnant Add (Ajouter) en regard du nom du champ. Par défaut, le tableau des résultats comprend la colonne _source et une colonne Time (Heure) si le champ d’heure existe.
Dans la barre de requête, vous pouvez rechercher des données en :
- Entrant un terme de recherche.
- Utilisant la syntaxe de requête Lucene. Par exemple :
- Recherchez « error » (erreur) pour trouver tous les enregistrements qui contiennent cette valeur.
- Recherchez « status : 200 » pour obtenir tous les enregistrements dont la valeur d’état est 200.
- Utilisant les opérateurs logiques AND, OR et NOT.
- Utilisant les caractères génériques astérisque (*) et point d’interrogation ( ?). Par exemple, la requête « destination_city : L* » correspond aux enregistrements où la valeur de destination-ville commence par « L » ou « l ». (K2Bridge ne respecte pas la casse.)

Remarque
Seule la syntaxe de requête Lucene de Kibana est prise en charge. N’utilisez pas l’option KQL, qui représente le langage de requête Kibana.
Conseil
Dans Searching (Recherche), vous pouvez rechercher d’autres règles et logiques de recherche.
Pour filtrer les résultats de votre recherche, utilisez la liste Available fields (Champs disponibles). La liste des champs indique :
- Les cinq premières valeurs du champ
- Le nombre d’enregistrements qui contiennent le champ
- Le pourcentage d’enregistrements qui contiennent chaque valeur
Conseil
Utilisez la loupe pour rechercher tous les enregistrements qui ont une valeur spécifique.
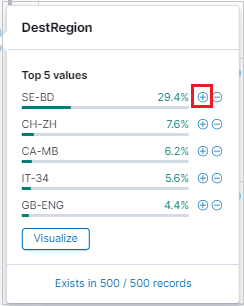
Vous pouvez également utiliser la loupe pour filtrer les résultats et afficher la vue format de la table de résultats pour chaque enregistrement.

Sélectionnez Save (Enregistrer) ou Share (Partager) pour conserver votre recherche.

Visualiser les données
Utilisez les visualisations de Kibana pour obtenir un aperçu des données Azure Data Explorer.
Créer une visualisation à partir de l’onglet Discover
Pour créer une visualisation à barres verticales, sous l’onglet Discover, localisez la barre latérale Available fields.
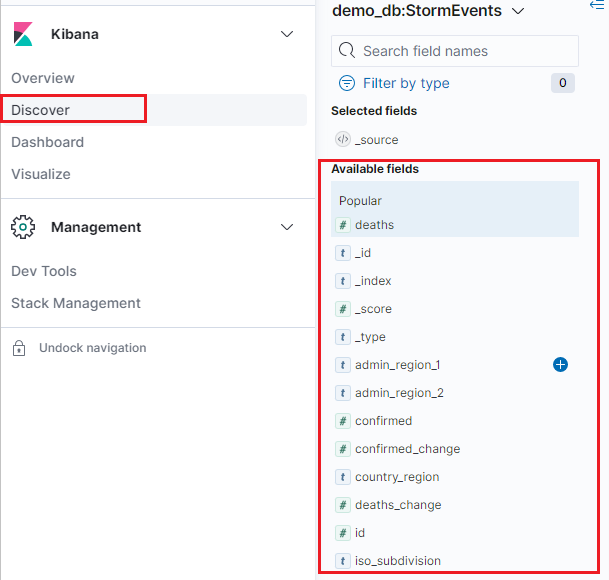
Sélectionnez un nom de champ, puis cliquez sur Visualize.
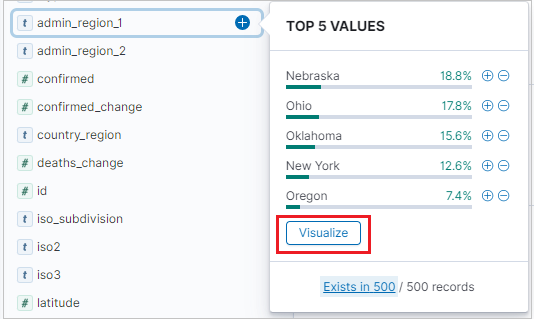
L’onglet Visualize s’ouvre et affiche la visualisation. Pour modifier les données et les métriques de la visualisation, consultez également Créer une visualisation à partir de l’onglet Visualize.
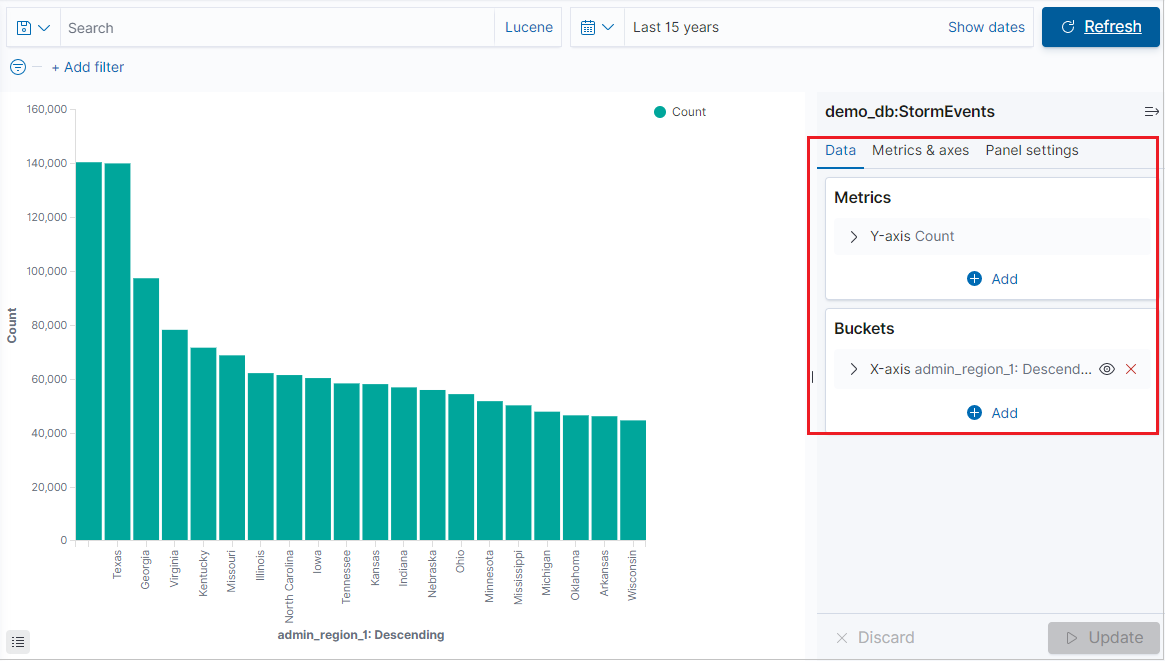
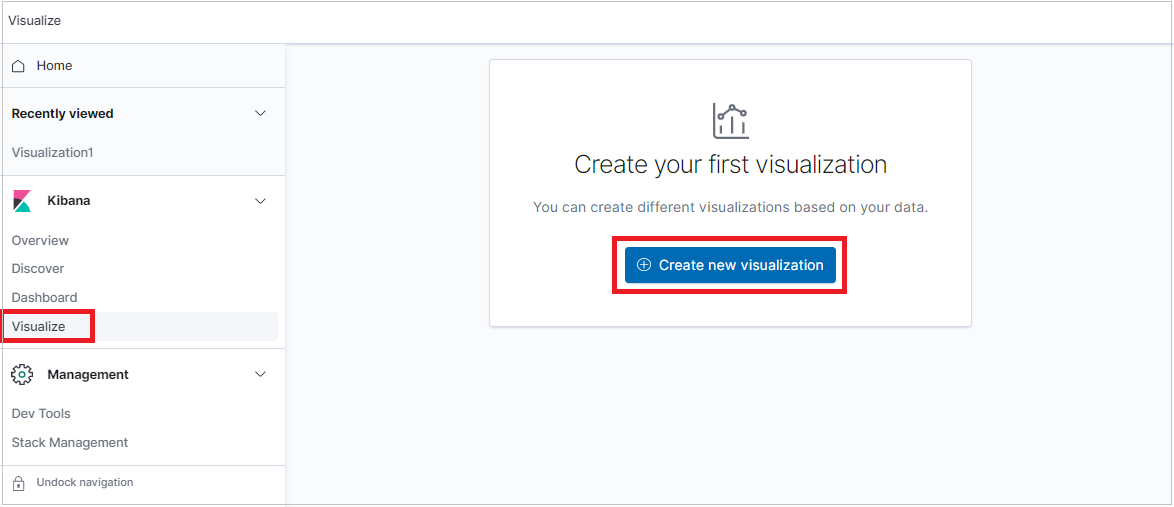
Créer une visualisation à partir de l’onglet Visualize
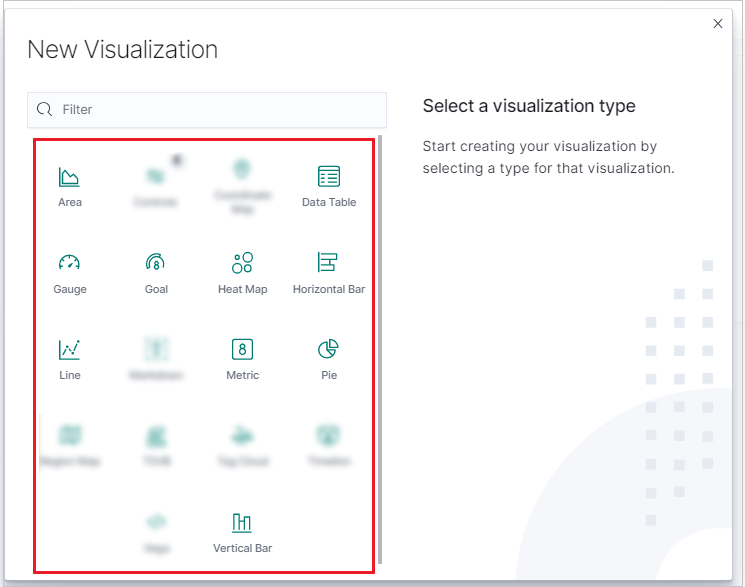
Sélectionnez l’onglet Visualize, puis cliquez sur Create visualization (Créer une visualisation).
Dans la fenêtre New Visualization (Nouvelle visualisation), sélectionnez un type de visualisation.
Une fois la visualisation générée, vous pouvez modifier les métriques et ajouter un compartiment.
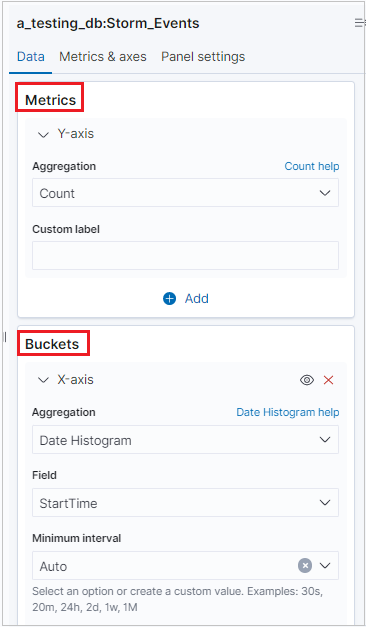
Remarque
K2Bridge prend en charge une agrégation de compartiments. Certaines agrégations prennent en charge les options de recherche. Utilisez la syntaxe Lucene, et non pas l’option KQL, qui correspond à la syntaxe du langage de requête Kibana.
Important
- Les visualisations suivantes sont prises en charge :
Vertical bar,Area chart,Line chart,Horizontal bar,Pie chart,Gauge,Data table,Heat map,Goal chartetMetric chart. - Les métriques suivantes sont prises en charge :
Average,Count,Max,Median,Min,Percentiles,Standard deviation,Sum,Top hitsetUnique count. - La métrique
Percentiles ranksn’est pas prise en charge. - L’utilisation d’agrégations de compartiments est facultative ; vous pouvez visualiser les données sans agrégation de compartiments.
- Les compartiments suivants sont pris en charge :
No bucket aggregation,Date histogram,Filters,Range,Date range,HistogrametTerms. - Les compartiments
IPv4 rangeetSignificant termsne sont pas pris en charge.
Créer des tableaux de bord
Vous pouvez créer des tableaux de bord avec des visualisations Kibana pour résumer, comparer et comparer en un clin d’œil des vues de données Azure Data Explorer.
Pour créer un tableau de bord, sélectionnez l’onglet Dashboard, puis cliquez sur Create new dashboard (Créer un tableau de bord).
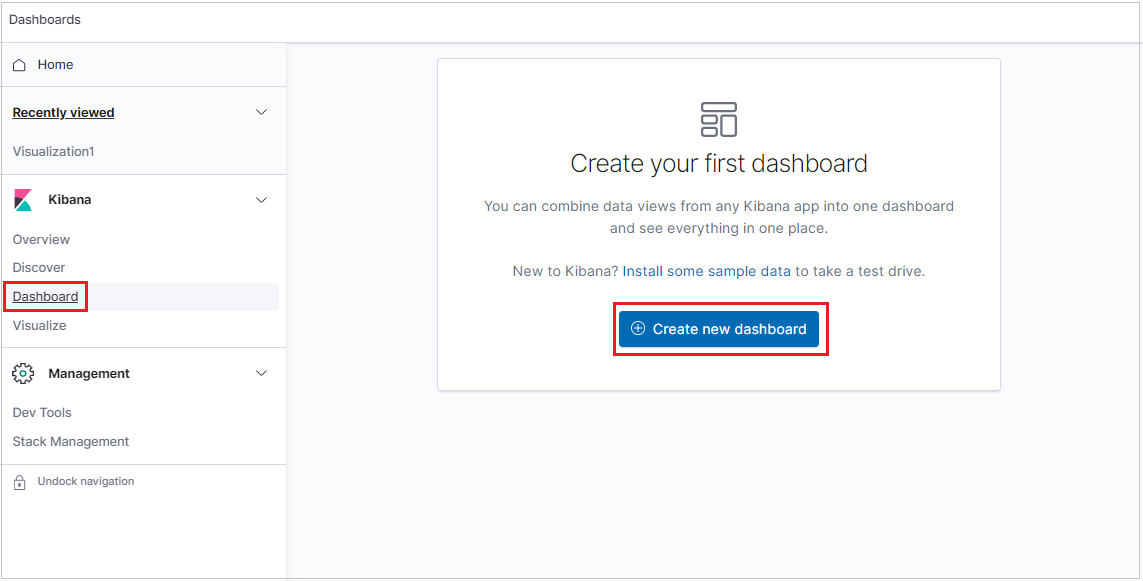
Le nouveau tableau de bord s’ouvre en mode édition.
Pour ajouter un nouveau panneau de visualisation, cliquez sur Create new (Créer nouveau).
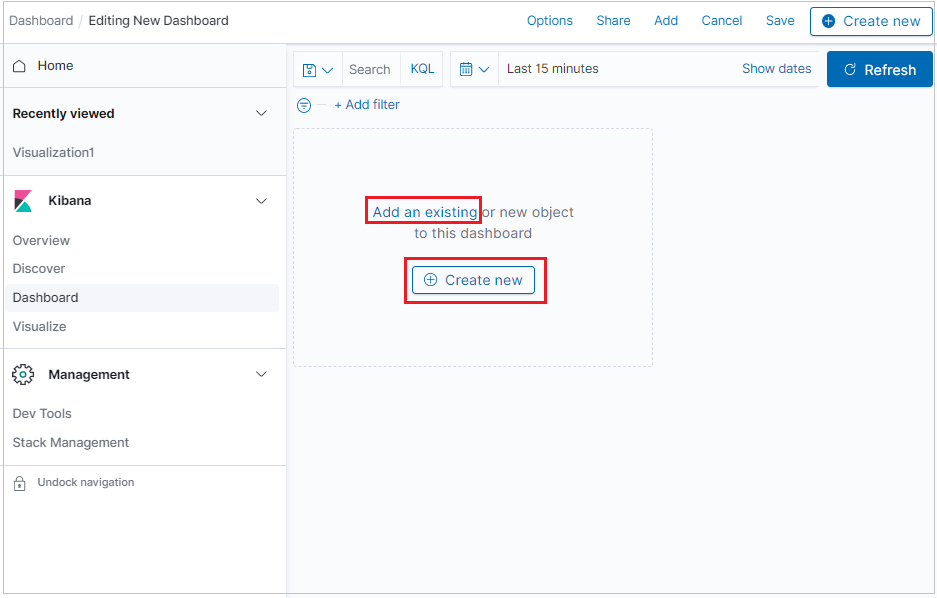
Pour ajouter une visualisation que vous avez déjà créée, cliquez sur Add an existing (Ajouter existant) et sélectionnez une visualisation.
Pour arranger des panneaux, organiser les panneaux par priorité, redimensionner les panneaux, etc., cliquez sur Edit (Modifier), puis utilisez les options suivantes :
- Pour déplacer un panneau, cliquez sur l’en-tête du panneau et laissez le bouton de la souris enfoncé, puis faites-le glisser vers le nouvel emplacement.
- Pour redimensionner un panneau, cliquez sur le contrôle de redimensionnement, puis faites-le glisser jusqu’à obtenir les nouvelles dimensions souhaitées.