Résoudre les problèmes de performances de l’activité de copie
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment résoudre les problèmes de performances de l’activité de copie dans Azure Data Factory.
Après avoir exécuté une activité de copie, vous pouvez collecter les résultats de l’exécution et les statistiques de performances dans l’affichage de l’analyse de l’activité de copie. Voici un exemple.
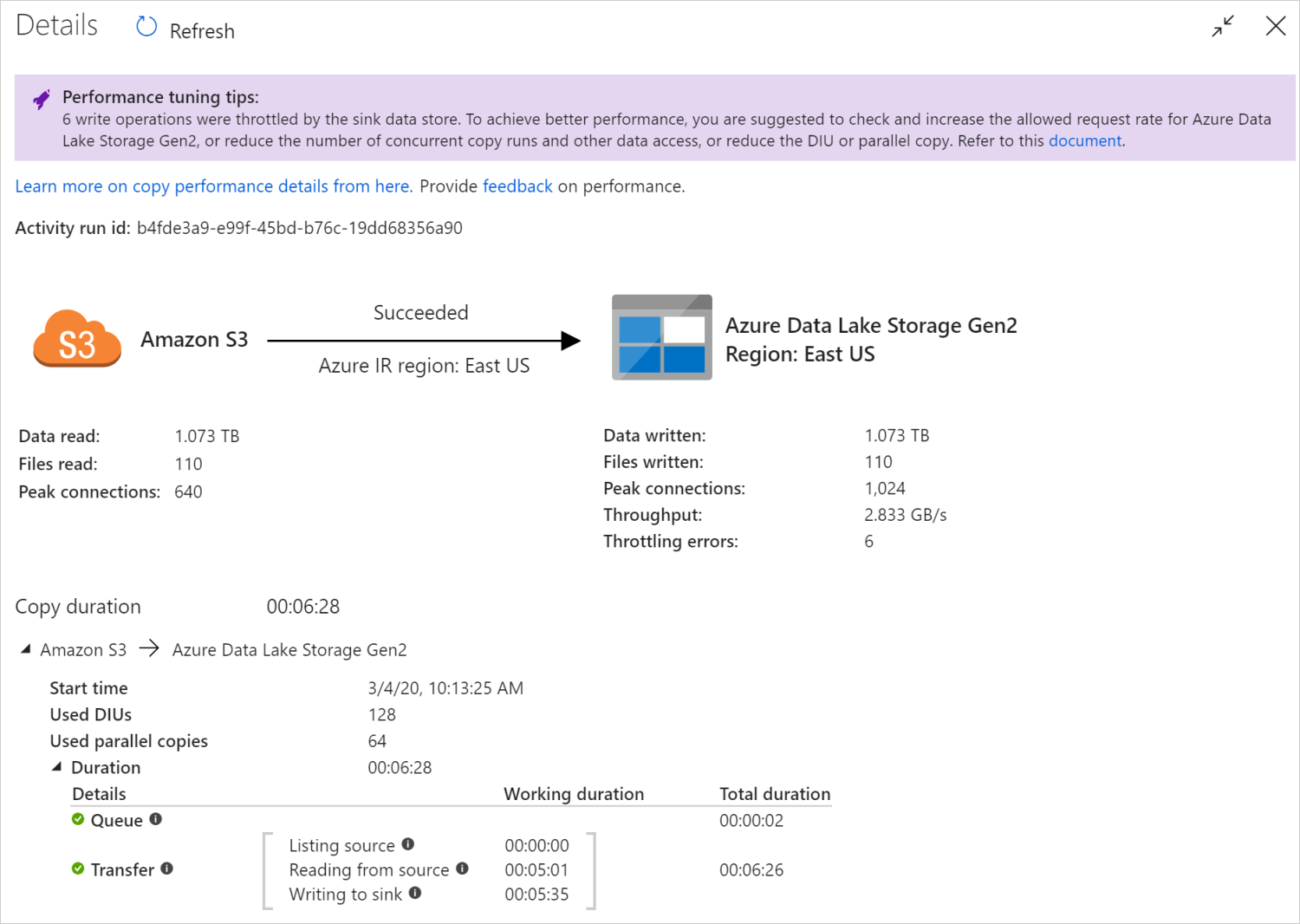
Conseils sur le réglage des performances
Dans certains scénarios, lorsque vous exécutez une activité de copie, vous voyez des « Conseils sur le réglage des performances » en haut, comme indiqué dans l’exemple ci-dessus. Les conseils vous indiquent le goulot d’étranglement identifié par le service pour cette exécution de copie spécifique, ainsi que des suggestions sur la manière d’améliorer le débit de copie. Essayez d’effectuer la modification recommandée, puis réexécutez la copie.
À titre de référence, les conseils de réglage des performances fournissent actuellement des suggestions pour les cas suivants :
| Category | Conseils sur le réglage des performances |
|---|---|
| Spécifique au magasin de données | Chargement de données dans Azure Synapse Analytics : suggérez le recours à PolyBase ou à l’instruction COPY si elle n’est pas utilisée. |
| Copie de données depuis/vers Azure SQL Database : lorsque la DTU est très utilisée, suggérez une mise à niveau vers un niveau supérieur. | |
| Copie de données depuis/vers Azure Cosmos DB : lorsque la RU est très utilisée, suggérez une mise à niveau vers une RU plus importante. | |
| Copie de données à partir d’une table SAP : quand de grandes quantités de données sont copiées, nous suggérons de tirer parti de l’option de partition du connecteur SAP pour activer la charge parallèle et augmenter le nombre maximal de partitions. | |
| Ingestion de données à partir d’Amazon Redshift : suggérez l’utilisation de UNLOAD si elle n’est pas utilisée. | |
| Limitation du magasin de données | Si plusieurs opérations de lecture/écriture sont limitées par le magasin de données au cours de la copie, suggérez de vérifier et d’augmenter le taux de requêtes autorisées pour le magasin de données ou de réduire la charge de travail simultanée. |
| Runtime d’intégration | Si vous utilisez un runtime d’intégration (IR) auto-hébergé et que l’activité de copie attend longtemps dans la file d’attente avant que le runtime d’intégration ne dispose des ressources nécessaires à son exécution, suggérez une montée en charge ou en puissance de votre IR. |
| Si vous utilisez un Azure Integration Runtime qui se trouve dans une région non optimale, ce qui entraîne une lecture/écriture lente, suggérez de configurer l’utilisation d’un IR dans une autre région. | |
| Tolérance de panne | Si vous configurez la tolérance de panne et que le fait d’ignorer des lignes incompatibles entraîne un ralentissement des performances, suggérez de vous assurer que les données de la source et du récepteur sont compatibles. |
| copie intermédiaire | Si la copie intermédiaire est configurée, mais n’est pas utile pour votre paire source-récepteur, suggérez de la supprimer. |
| Reprendre | Lorsque l’activité de copie est reprise à partir du dernier point d’échec, mais que vous modifiez le paramètre DIU après l’exécution d’origine, notez que le nouveau paramètre DIU n’est pas appliqué. |
Comprendre les détails de l’exécution de l’activité de copie
Les détails et les durées d’exécution en bas de l’affichage de l’analyse de l’activité de copie décrivent les principales étapes de l’activité de copie (voir l’exemple au début de cet article), ce qui est particulièrement utile pour la résolution des problèmes de performances de copie. Le goulet d’étranglement de votre exécution de copie est celui dont la durée est la plus longue. Reportez-vous au tableau suivant sur la définition de chaque étape et découvrez comment résoudre les problèmes liés à l’activité de copie sur Azure IR et résoudre les problèmes liés à l’activité de copie sur un IR auto-hébergé avec ces informations.
| Étape | Description |
|---|---|
| File d'attente | Temps écoulé jusqu’à ce que l’activité de copie commence sur le runtime d’intégration. |
| Script de pré-copie | Temps écoulé entre le début de l’activité de copie sur le runtime d’intégration et la fin de l’exécution du script de pré-copie de l’activité de copie dans la banque de données réceptrice. Appliquez lorsque vous configurez le script de pré-copie pour les récepteurs de base de données : par exemple, lors de l’écriture de données dans Azure SQL Database, effectuez un nettoyage avant de copier les nouvelles données. |
| Transférer | Temps écoulé entre la fin de l’étape précédente et le transfert par le runtime de toutes les données de la source vers le récepteur. Notez que les sous-étapes sous le transfert s’exécutent en parallèle et que certaines opérations ne sont pas affichées actuellement, par exemple, l’analyse/la génération du format de fichier. - Temps jusqu’au premier octet : Temps écoulé entre la fin de l’étape précédente et l’heure à laquelle le runtime d'intégration reçoit le premier octet du magasin de données source. S’applique aux sources non basées sur des fichiers. - Liste des sources : Durée d’énumération des fichiers sources ou des partitions de données. Ces derniers s’appliquent lorsque vous configurez des options de partition pour des sources de base de données, par exemple lorsque vous copiez des données à partir de bases de données comme Oracle/SAP HANA/Teradata/Netezza/etc. -Lecture à partir de la source : Durée de récupération des données dans le magasin de données source. - Écriture dans le récepteur : Durée d’écriture des données dans le magasin de données récepteur. Notez que certains connecteurs n’ont pas cette métrique pour le moment, notamment Recherche Azure AI, Azure Data Explorer, Stockage Table Azure, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Résoudre les problèmes liés à l’activité de copie sur Azure IR
Suivez la procédure de réglage des performances pour planifier et effectuer un test de performances pour votre scénario.
Si les performances de l’activité de copie ne répondent pas à vos attentes et si vous voyez Conseils sur le réglage des performances affiché dans la vue de l’analyse de copie, appliquez la suggestion, puis réessayez pour résoudre les problèmes liés à l’activité de copie unique exécutée sur Azure Integration Runtime. Dans le cas contraire, comprenez les détails de l’exécution de l’activité de copie, vérifiez quelle étape a la durée la plus longue et appliquez les conseils ci-dessous pour améliorer les performances de copie :
Le « script de pré-copie » a connu une longue durée : cela signifie que le script de pré-copie exécuté sur la base de données du récepteur prend beaucoup de temps à se terminer. Ajustez la logique du script de pré-copie spécifiée pour améliorer les performances. Si vous avez besoin d’aide pour améliorer le script, contactez votre équipe de base de données.
Le « transfert – temps jusqu’au premier octet » a connu une longue durée de travail : cela signifie que votre requête source prend beaucoup de temps pour retourner des données. Vérifiez et optimisez la requête ou le serveur. Si vous avez besoin d’une aide supplémentaire, contactez votre équipe de magasin de données.
Le « transfert – liste des sources » a connu une longue durée de travail : cela signifie que l’énumération des fichiers sources ou des partitions de données de la base de données source est lente.
Lorsque vous copiez des données à partir d’une source basée sur des fichiers, si vous utilisez le filtre de caractères génériques sur le chemin d’accès au dossier ou le nom de fichier (
wildcardFolderPathouwildcardFileName), ou si vous utilisez le filtre de l’heure de dernière modification du fichier (modifiedDatetimeStartoumodifiedDatetimeEnd), notez qu’un tel filtre entraînerait une activité de copie répertoriant tous les fichiers sous le dossier spécifié vers le côté client puis appliquerait le filtre. Cette énumération de fichiers peut devenir le goulot d’étranglement, en particulier lorsque seul un petit ensemble de fichiers répond à la règle de filtre.Vérifiez si vous pouvez copier des fichiers en fonction du chemin d’accès de fichier ou du nom de fichier partitionné DateHeure. De cette façon, le côté source n’est plus chargé.
Vérifiez si vous pouvez utiliser le filtre natif du magasin de données à la place, en particulier « prefix » pour Amazon S3/Stockage Blob Azure/Azure Files et « listAfter/listBefore » pour ADLS Gen1. Ces filtres sont des filtres côté serveur du magasin de données et offrent de meilleures performances.
Envisagez de fractionner un jeu de données volumineux en plusieurs jeux de données plus petits et de laisser les travaux de copie s’exécuter simultanément, chacun s’attaquant à une partie des données. Vous pouvez le faire avec Lookup/GetMetadata + ForEach + Copy. Reportez-vous aux modèles de solution Copie de fichiers à partir de plusieurs conteneurs ou Migrer des données d’Amazon S3 vers ADLS Gen2 en guise d’exemple général.
Vérifiez si le service signale une erreur de limitation sur la source ou si votre magasin de données est dans un état d’utilisation élevée. Si c’est le cas, réduisez vos charges de travail sur le magasin de données ou essayez de contacter votre administrateur de magasin de données pour augmenter la valeur de limitation ou la ressource disponible.
Utilisez Azure IR dans la région de votre magasin de données source ou près de celle-ci.
Le « transfert – lecture à partir de la source » a connu une longue durée de travail :
adoptez les meilleures pratiques de chargement de données spécifiques au connecteur si elles s’appliquent. Par exemple, lorsque vous copiez des données à partir d’Amazon Redshift, configurez l’utilisation de Redshift UNLOAD.
Vérifiez si le service signale une erreur de limitation sur la source ou si votre magasin de données est soumis à une utilisation intensive. Si c’est le cas, réduisez vos charges de travail sur le magasin de données ou essayez de contacter votre administrateur de magasin de données pour augmenter la valeur de limitation ou la ressource disponible.
Vérifiez votre modèle de source et de récepteur de copie :
Si votre modèle de copie prend en charge plus de quatre unités d’intégration de données (DIU), reportez-vous à cette section pour plus de détails, vous pouvez généralement essayer d’augmenter les DIU pour obtenir de meilleures performances.
Dans le cas contraire, envisagez de fractionner un jeu de données volumineux en plusieurs jeux de données plus petits et de laisser les travaux de copie s’exécuter simultanément, chacun s’attaquant à une partie des données. Vous pouvez le faire avec Lookup/GetMetadata + ForEach + Copy. Reportez-vous aux modèles de solution Copie de fichiers à partir de plusieurs conteneurs, Migrer des données d’Amazon S3 vers ADLS Gen2 ou Copie en bloc avec une table de contrôles en guise d’exemple général.
Utilisez Azure IR dans la région de votre magasin de données source ou près de celle-ci.
Le « transfert – écriture dans le récepteur » a connu une longue durée de travail :
Adoptez les meilleures pratiques de chargement de données spécifiques au connecteur si elles s’appliquent. Par exemple, pour copier des données dans Azure Synapse Analytics, utilisez PolyBase ou l’instruction COPY.
Vérifiez si le service signale une erreur de limitation sur le récepteur ou si votre magasin de données est soumis à une utilisation intensive. Si c’est le cas, réduisez vos charges de travail sur le magasin de données ou essayez de contacter votre administrateur de magasin de données pour augmenter la valeur de limitation ou la ressource disponible.
Vérifiez votre modèle de source et de récepteur de copie :
Si votre modèle de copie prend en charge plus de quatre unités d’intégration de données (DIU), reportez-vous à cette section pour plus de détails, vous pouvez généralement essayer d’augmenter les DIU pour obtenir de meilleures performances.
Dans le cas contraire, réglez progressivement les copies parallèles. Notez qu’un trop grand nombre de copies parallèles peut également nuire aux performances.
Utilisez Azure IR dans la région de votre magasin de données récepteur ou près de celle-ci.
Résoudre les problèmes liés à l’activité de copie sur IR auto-hébergé
Suivez la procédure de réglage des performances pour planifier et effectuer un test de performances pour votre scénario.
Si les performances de copie ne répondent pas à vos attentes et si vous voyez Conseils sur le réglage des performances affiché dans la vue de l’analyse de copie, appliquez la suggestion, puis réessayez pour résoudre les problèmes liés à l’activité de copie unique exécutée sur Azure Integration Runtime. Dans le cas contraire, comprenez les détails de l’exécution de l’activité de copie, vérifiez quelle étape a la durée la plus longue et appliquez les conseils ci-dessous pour améliorer les performances de copie :
La « file d’attente » a connu une longue durée : cela signifie que l’activité de copie attend longtemps dans la file d’attente avant que votre IR auto-hébergé ne dispose des ressources nécessaires à son exécution. Vérifiez la capacité et l’utilisation du runtime d’intégration, puis montez en puissance ou en charge en fonction de votre charge de travail.
Le « transfert – temps jusqu’au premier octet » a connu une longue durée de travail : cela signifie que votre requête source prend beaucoup de temps pour retourner des données. Vérifiez et optimisez la requête ou le serveur. Si vous avez besoin d’une aide supplémentaire, contactez votre équipe de magasin de données.
Le « transfert – liste des sources » a connu une longue durée de travail : cela signifie que l’énumération des fichiers sources ou des partitions de données de la base de données source est lente.
Vérifiez si l’ordinateur IR auto-hébergé a une faible latence lors de la connexion au magasin de données source. Si votre source est dans Azure, vous pouvez utiliser cet outil pour vérifier la latence de l’ordinateur IR auto-hébergé dans la région Azure, sachant que moins la latence est importance, mieux c’est.
Lorsque vous copiez des données à partir d’une source basée sur des fichiers, si vous utilisez le filtre de caractères génériques sur le chemin d’accès au dossier ou le nom de fichier (
wildcardFolderPathouwildcardFileName), ou si vous utilisez le filtre de l’heure de dernière modification du fichier (modifiedDatetimeStartoumodifiedDatetimeEnd), notez qu’un tel filtre entraînerait une activité de copie répertoriant tous les fichiers sous le dossier spécifié vers le côté client puis appliquerait le filtre. Cette énumération de fichiers peut devenir le goulot d’étranglement, en particulier lorsque seul un petit ensemble de fichiers répond à la règle de filtre.Vérifiez si vous pouvez copier des fichiers en fonction du chemin d’accès de fichier ou du nom de fichier partitionné DateHeure. De cette façon, le côté source n’est plus chargé.
Vérifiez si vous pouvez utiliser le filtre natif du magasin de données à la place, en particulier « prefix » pour Amazon S3/Stockage Blob Azure/Azure Files et « listAfter/listBefore » pour ADLS Gen1. Ces filtres sont des filtres côté serveur du magasin de données et offrent de meilleures performances.
Envisagez de fractionner un jeu de données volumineux en plusieurs jeux de données plus petits et de laisser les travaux de copie s’exécuter simultanément, chacun s’attaquant à une partie des données. Vous pouvez le faire avec Lookup/GetMetadata + ForEach + Copy. Reportez-vous aux modèles de solution Copie de fichiers à partir de plusieurs conteneurs ou Migrer des données d’Amazon S3 vers ADLS Gen2 en guise d’exemple général.
Vérifiez si le service signale une erreur de limitation sur la source ou si votre magasin de données est dans un état d’utilisation élevée. Si c’est le cas, réduisez vos charges de travail sur le magasin de données ou essayez de contacter votre administrateur de magasin de données pour augmenter la valeur de limitation ou la ressource disponible.
Le « transfert – lecture à partir de la source » a connu une longue durée de travail :
Vérifiez si l’ordinateur IR auto-hébergé a une faible latence lors de la connexion au magasin de données source. Si votre source est dans Azure, vous pouvez utiliser cet outil pour vérifier la latence de l’ordinateur IR auto-hébergé dans les régions Azure, sachant que moins la latence est importance, mieux c’est.
Vérifiez si l’ordinateur IR auto-hébergé a suffisamment de bande passante entrante pour lire et transférer les données efficacement. Si votre magasin de données source est dans Azure, vous pouvez utiliser cet outil pour vérifier la vitesse de téléchargement.
Vérifiez la tendance d’utilisation de l’UC et de la mémoire de l’IR auto-hébergé dans le Portail Azure -> votre fabrique de données ou espace de travail Synapse -> page de vue d’ensemble. Envisagez de monter en puissance ou en charge l’IR si l’utilisation de l’UC est élevée ou si la mémoire disponible est faible.
Adoptez les meilleures pratiques de chargement de données spécifiques au connecteur si elles s’appliquent. Par exemple :
Lorsque vous copiez des données à partir des magasins de données Oracle, Netezza, Teradata, SAP HANA, SAP Table et SAP Open Hub, activer les options de partition de données pour copier les données en parallèle.
Lorsque vous copiez des données à partir de HDFS, configurez l’utilisation de DistCp.
Lorsque vous copiez des données à partir d’Amazon Redshift, configurez l’utilisation de Redshift UNLOAD.
Vérifiez si le service signale une erreur de limitation sur la source ou si votre magasin de données est soumis à une utilisation intensive. Si c’est le cas, réduisez vos charges de travail sur le magasin de données ou essayez de contacter votre administrateur de magasin de données pour augmenter la valeur de limitation ou la ressource disponible.
Vérifiez votre modèle de source et de récepteur de copie :
Si vous copiez des données à partir de magasins de données avec option de partition, envisagez de régler progressivement les copies parallèles. Notez qu’un trop grand nombre de copies parallèles peut également nuire aux performances.
Dans le cas contraire, envisagez de fractionner un jeu de données volumineux en plusieurs jeux de données plus petits et de laisser les travaux de copie s’exécuter simultanément, chacun s’attaquant à une partie des données. Vous pouvez le faire avec Lookup/GetMetadata + ForEach + Copy. Reportez-vous aux modèles de solution Copie de fichiers à partir de plusieurs conteneurs, Migrer des données d’Amazon S3 vers ADLS Gen2 ou Copie en bloc avec une table de contrôles en guise d’exemple général.
Le « transfert – écriture dans le récepteur » a connu une longue durée de travail :
Adoptez les meilleures pratiques de chargement de données spécifiques au connecteur si elles s’appliquent. Par exemple, pour copier des données dans Azure Synapse Analytics, utilisez PolyBase ou l’instruction COPY.
Vérifiez si l’ordinateur IR auto-hébergé a une faible latence lors de la connexion au magasin de données du récepteur. Si votre récepteur est dans Azure, vous pouvez utiliser cet outil pour vérifier la latence de l’ordinateur IR auto-hébergé dans la région Azure, sachant que moins la latence est importance, mieux c’est.
Vérifiez si l’ordinateur IR auto-hébergé a suffisamment de bande passante sortante pour transférer et écrire les données efficacement. Si votre magasin de données récepteur est dans Azure, vous pouvez utiliser cet outil pour vérifier la vitesse de chargement.
Vérifiez la tendance d’utilisation de l’UC et de la mémoire de l’IR auto-hébergé dans le Portail Azure -> votre fabrique de données -> page de vue d’ensemble. Envisagez de monter en puissance ou en charge l’IR si l’utilisation de l’UC est élevée ou si la mémoire disponible est faible.
Vérifiez si le service signale une erreur de limitation sur le récepteur ou si votre magasin de données est soumis à une utilisation intensive. Si c’est le cas, réduisez vos charges de travail sur le magasin de données ou essayez de contacter votre administrateur de magasin de données pour augmenter la valeur de limitation ou la ressource disponible.
Réglez progressivement les copies parallèles. Notez qu’un trop grand nombre de copies parallèles peut également nuire aux performances.
Performances du connecteur et du runtime d’intégration (IR)
Cette section explore certains guides de résolution des problèmes en matière de performances pour un type de connecteur spécifique ou pour le runtime d’intégration.
La durée d’exécution de l’activité varie selon que vous utilisez le runtime d’intégration Azure ou le runtime d’intégration VNet Azure
La durée d’exécution de l’activité varie quand le jeu de données est basé sur différents runtime d’intégration.
Symptômes : L’activation/désactivation de la liste déroulante Service lié dans le jeu de données effectue les mêmes activités de pipeline, mais avec des délais d’exécution radicalement différents. Lorsque le jeu de données est basé sur le runtime d’intégration de réseau virtuel géré, il faut plus de temps en moyenne que n’en nécessite l’exécution quand elle est basée sur le runtime d’intégration par défaut.
Cause : Dans les détails des exécutions du pipeline, vous pouvez constater que le pipeline lent s’exécute sur le runtime d’intégration du réseau virtuel géré, alors que le pipeline normal s’exécute sur le runtime d'intégration Azure. En raison de sa conception, le runtime d’intégration du réseau virtuel géré prend plus de temps que le runtime d’intégration Azure car nous ne réservons aucun nœud de calcul par instance de service. Par conséquent, il y a un temps de démarrage pour chaque activité de copie, qui se produit principalement à la jonction du réseau virtuel plutôt que dans le runtime d’intégration Azure.
Faible niveau de performance pendant le chargement de données dans Azure SQL Database
Symptômes : La copie de données dans Azure SQL Database devient lente.
Cause : La cause racine du problème est principalement provoquée par le goulot d’étranglement du côté d’Azure SQL Database. Voici quelques causes possibles :
Le niveau Azure SQL Database n’est pas assez élevé.
L’utilisation des DTU d’Azure SQL Database est proche de 100 %. Vous pouvez superviser le niveau de performance et envisager une mise à niveau d’Azure SQL Database.
Les index ne sont pas bien définis. Supprimez tous les index avant le chargement des données, puis recréez-les une fois le chargement terminé.
La valeur de WriteBatchSize n’est pas suffisante pour la taille de ligne de schéma. Essayez d’attribuer une valeur supérieure à la propriété pour résoudre le problème.
Une procédure stockée est utilisée à la place de l’insertion en bloc, ce qui est censé amoindrir le niveau de performance.
Expiration du délai ou baisse du niveau de performance lors de l’analyse d’un fichier Excel volumineux
Symptômes :
Lorsque vous créez un jeu de données Excel et importez un schéma à partir de feuilles de calcul de connexion/du magasin, d’aperçu de données, de liste ou d’actualisation, le délai d’attente peut expirer si la taille du fichier Excel est importante.
Lorsque vous utilisez l’activité de copie pour copier des données à partir d’un fichier Excel volumineux (>= 100 Mo) dans un autre magasin de données, vous pouvez rencontrer une baisse du niveau de performance ou une erreur de type OOM (mémoire insuffisante).
Cause :
Pour les opérations comme l’importation de feuilles de calcul de schéma, d’aperçu de données et de liste dans un jeu de données Excel, le délai d’expiration est statique et fixé à 100 secondes. Pour un fichier Excel volumineux, ces opérations peuvent ne pas se terminer dans ce délai.
L’activité de copie lit l’intégralité du fichier Excel en mémoire, puis localise la feuille de calcul et les cellules spécifiées pour lire les données. Ce comportement est dû à l’utilisation du Kit de développement logiciel (SDK) sous-jacent.
Résolution :
Pour importer un schéma, vous pouvez générer un exemple de fichier plus petit représentant un sous-ensemble du fichier d’origine, puis choisir « import schema from sample file » (importer le schéma à partir d’un exemple de fichier) au lieu de « import schema from connection/store » (importer le schéma à partir d’une connexion/d’un magasin).
Pour lister une feuille de calcul, dans la liste déroulante de la feuille de calcul, vous pouvez cliquer sur « Modifier » et entrer à la place le nom/index de la feuille.
Pour copier un fichier Excel volumineux (>100 Mo) dans un autre magasin, vous pouvez utiliser le flux de données source Excel qui prend en charge la diffusion en continu et offre de meilleures performances.
Problème de mémoire insuffisante (OOM) lié à la lecture de fichiers JSON/Excel/XML volumineux
Symptômes : lorsque vous lisez des fichiers JSON/Excel/XML volumineux, vous rencontrez le problème de mémoire insuffisante (OOM) pendant l’exécution de l’activité.
Cause :
- Pour des fichiers XML volumineux : le problème OOM lié à la lecture de fichiers XML volumineux est normal. La raison en est que l’intégralité du fichier XML doit être lue en mémoire, car il s’agit d’un objet unique. Le schéma est ensuite déduit et les données sont récupérées.
- Pour des fichiers Excel volumineux : le problème OOM lié à la lecture de fichiers Excel volumineux est normal. En effet, le Kit de développement logiciel (SDK) POI/NPOI utilisé doit lire l’intégralité du fichier Excel en mémoire, puis déduire le schéma et obtenir des données.
- Pour des fichiers JSON volumineux : le problème OOM lié à la lecture de fichiers JSON volumineux est normal lorsque le fichier JSON est un objet unique.
Recommandation : appliquez l’une des options suivantes pour résoudre votre problème.
- Option 1 : inscrivez un runtime d’intégration auto-hébergé en ligne à l’aide d’un ordinateur puissant (processeur/mémoire élevée) pour lire les données de votre fichier volumineux via votre activité de copie.
- Option 2 : utilisez une mémoire optimisée et un cluster de grande taille (par exemple, 48 cœurs) pour lire les données de votre fichier volumineux via l’activité de flux de données de mappage.
- Option 3 : fractionnez le fichier volumineux en petits fichiers, puis utilisez l’activité de flux de données de mappage ou de copie pour lire le dossier.
- Option 4 : si vous êtes bloqué ou que vous rencontrez le problème OOM pendant la copie du dossier XML/Excel/JSON, utilisez l’activité ForEach + l’activité de flux de données de mappage/copie dans votre pipeline pour gérer chaque fichier ou sous-dossier.
- Option 5 : autres :
- Pour XML, utilisez l’activité Notebook avec un cluster mémoire optimisé pour lire les données à partir des fichiers si chaque fichier a le même schéma. Actuellement, Spark dispose de différentes implémentations pour gérer XML.
- Pour JSON, utilisez différents formulaires de document (par exemple, Document unique, Document par ligne et Tableau de documents) dans les paramètres JSON sous source de flux de données de mappage. Si le contenu du fichier JSON est Document par ligne, il consomme très peu de mémoire.
Autres références
Voici des références relatives au monitoring et au réglage des performances pour quelques magasins de données pris en charge :
- Stockage Blob Azure : Objectifs de performance et de scalabilité pour le stockage d’objets blob et Liste de contrôle des performances et de la scalabilité pour le stockage d’objets blob.
- Stockage Table Azure : Objectifs de performance et de scalabilité pour le stockage Table et Liste de contrôle des performances et de la scalabilité pour le stockage Table.
- Azure SQL Database : Vous pouvez surveiller les performances et vérifier le pourcentage de l’unité de transaction de base de données (DTU).
- Azure Synapse Analytics : Sa capacité est mesurée en DWU (Data Warehouse Units). Voir Gérer la puissance de calcul dans Azure Synapse Analytics (présentation).
- Azure Cosmos DB : Niveaux de performances dans Azure Cosmos DB.
- SQL Server : Surveiller et régler les performances.
- Serveur de fichiers local : Réglage des performances des serveurs de fichiers.
Contenu connexe
Consultez les autres articles relatifs à l’activité de copie :
- Vue d’ensemble des activités de copie
- Guide sur les performances et l’extensibilité de l’activité de copie
- Fonctionnalités d’optimisation des performances de l’activité de copie
- Migrer vos données à partir d’un lac de données ou d’un entrepôt de données vers Azure
- Migrer des données d’Amazon S3 vers le stockage Azure