Développement et débogage itératifs avec des pipelines Azure Data Factory et Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Azure Data Factory et Synapse Analytics prennent en charge le développement et le débogage itératifs des pipelines. Ces fonctionnalités vous permettent de tester vos modifications avant de créer une demande de tirage (pull request) ou de les publier sur le service.
Pour une présentation de huit minutes et la démonstration de cette fonctionnalité, regardez la vidéo suivante :
Débogage d’un pipeline
Lorsque vous créez à l’aide du canevas du pipeline, vous pouvez tester vos activités à l’aide de la capacité Déboguer. Lorsque vous effectuez des séries de tests, vous n’êtes pas obligé de publier vos modifications du service avant de sélectionner Déboguer. Cette fonctionnalité est utile dans les scénarios où vous souhaitez vous assurer que les modifications fonctionnent comme prévu avant de mettre à jour le flux de travail.
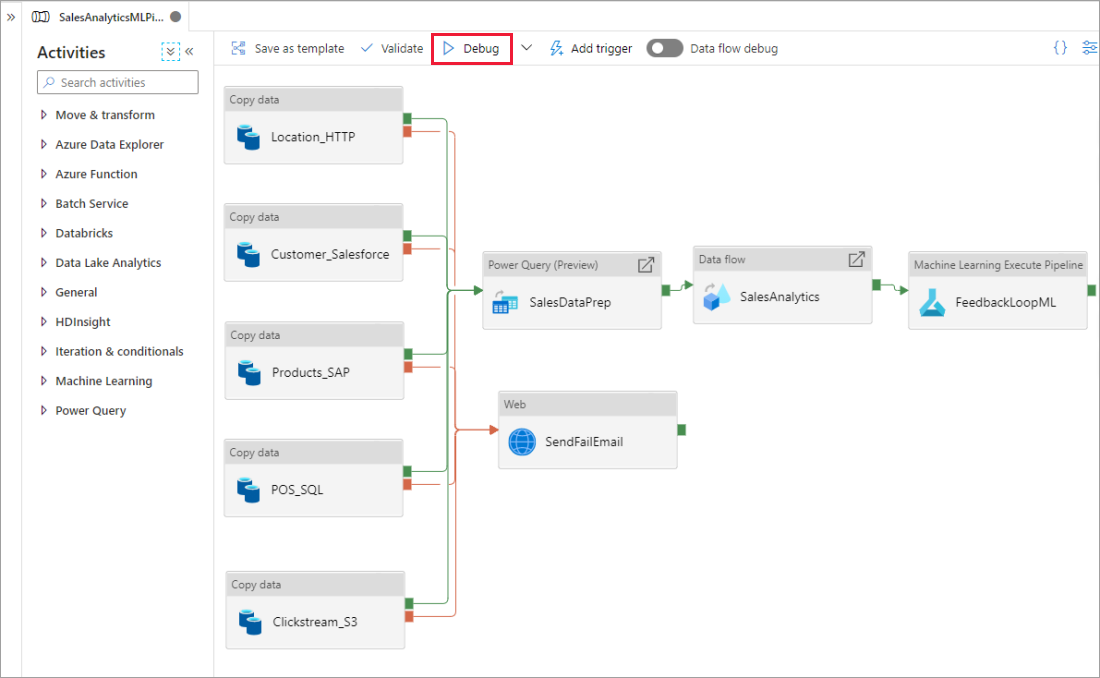
Lorsque le pipeline est en cours d’exécution, vous pouvez voir les résultats de chaque activité dans l’onglet Sortie du canevas du pipeline.
Affichez les résultats de vos séries de tests dans la fenêtre Sortie du canevas du pipeline.
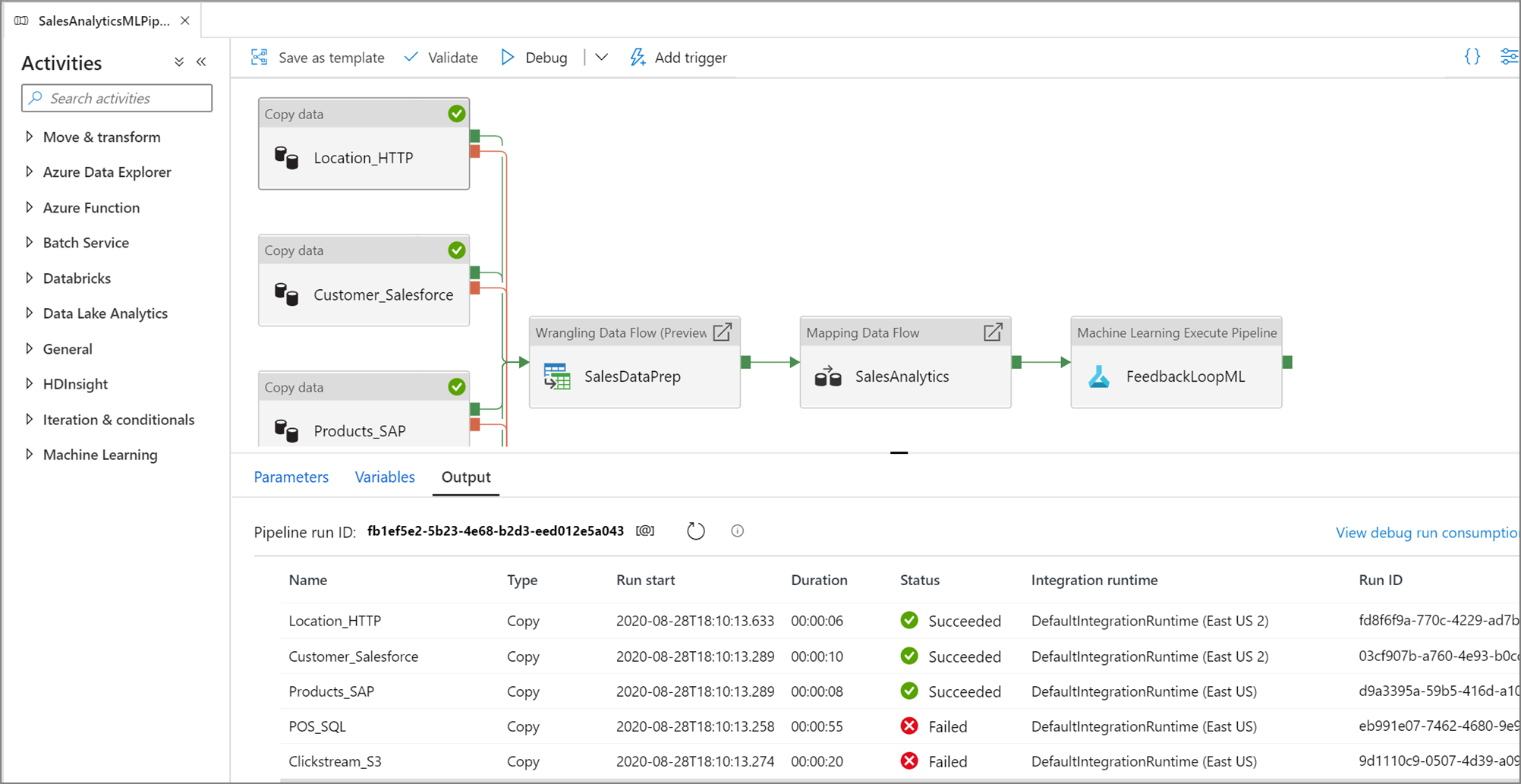
Après la réussite d’une série de tests, ajoutez d’autres activités à votre pipeline et continuez le débogage de façon itérative. Vous pouvez également Annuler une série de tests alors qu’elle est en cours d’exécution.
Important
En sélectionnant Déboguer, le pipeline est exécuté. Par exemple, si le pipeline contient une activité de copie, la série de tests copie des données de la source vers la destination. Par conséquent, nous vous recommandons d’utiliser des dossiers test pour vos activités de copie et autres lors du débogage. Une fois que vous avez débogué le pipeline, basculez vers les dossiers que vous souhaitez utiliser lors des opérations normales.
Définition de points d’arrêt
Le service vous permet de déboguer un pipeline jusqu’à ce que vous atteigniez une activité précise dans le canevas du pipeline. Placez un point d’arrêt sur l’activité jusqu’à laquelle vous souhaitez tester, puis sélectionnez Déboguer. Le service garantit que le test s’exécute uniquement jusqu’à l’activité de point d’arrêt sur le canevas du pipeline. Cette fonctionnalité Déboguer jusqu’à est utile lorsque vous ne souhaitez pas tester le pipeline en entier, mais uniquement un sous-ensemble des activités à l’intérieur du pipeline.
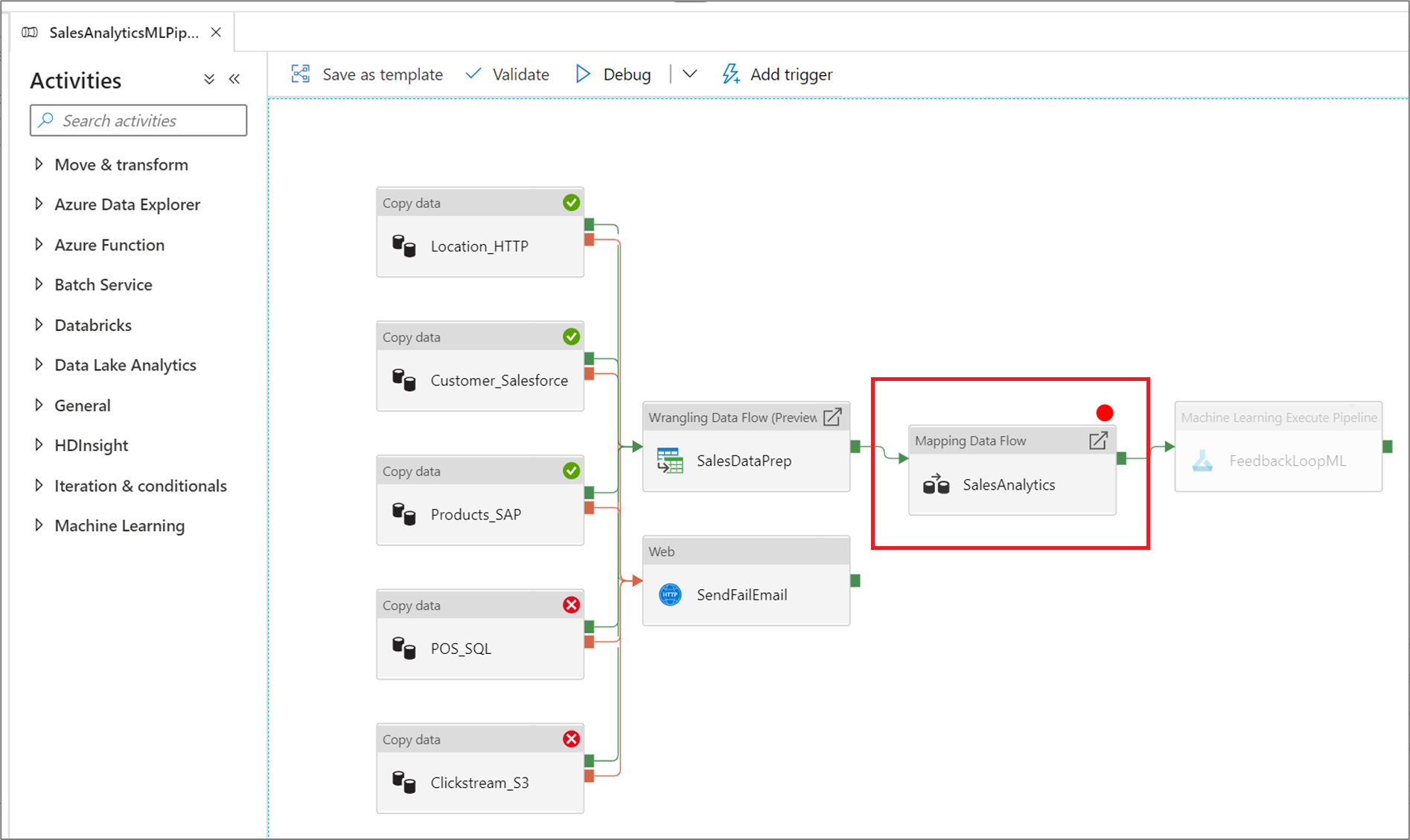
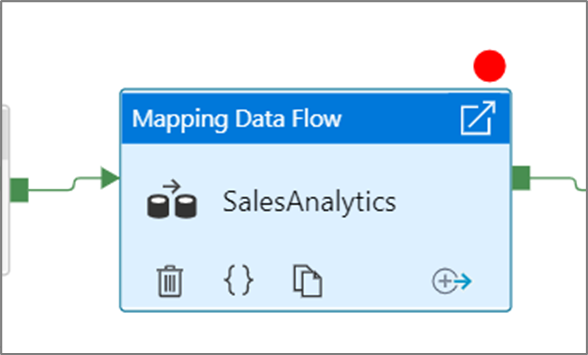
Pour définir un point d’arrêt, sélectionnez un élément du canevas du pipeline. Une option Déboguer jusqu’à apparaît sous la forme d’un cercle rouge vide dans le coin supérieur droit de l’élément.
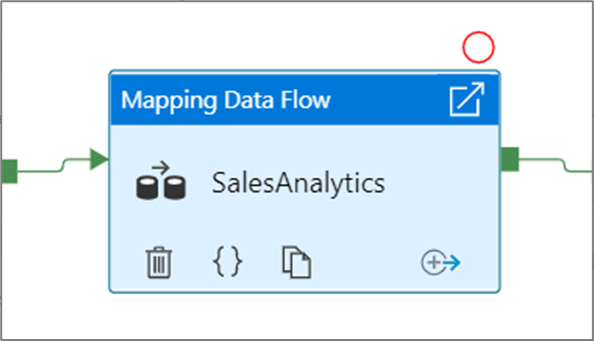
Après que vous avez sélectionné l’option Déboguer jusqu’à, elle se transforme en un cercle rouge plein pour indiquer que le point d’arrêt est activé.
Supervision des exécutions de débogage
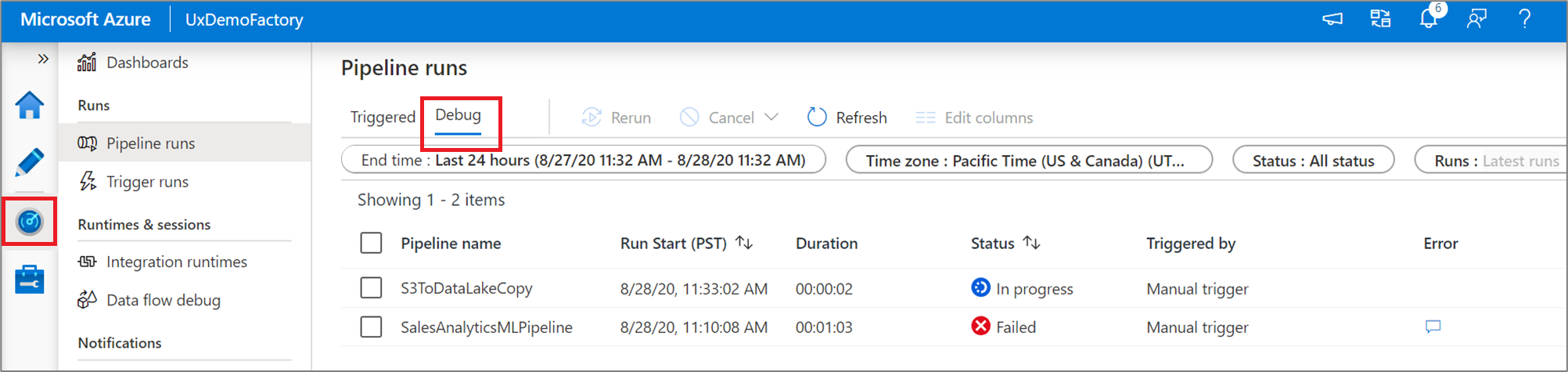
Lorsque vous exécutez un débogage de pipeline, les résultats s’affichent dans la fenêtre Sortie du canevas du pipeline. L’onglet Sortie ne contiendra que l’exécution la plus récente qui a eu lieu pendant la session de navigation en cours.
Pour afficher l’historique des exécutions de débogage ou afficher une liste de toutes les exécutions de débogage actives, vous pouvez accéder à l’expérience Superviser.
Notes
Le service conserve uniquement l’historique des exécutions de débogage pendant 15 jours.
Débogage de flux de données de mappage
Les flux de données de mappage vous permettent de créer une logique de transformation des données sans code qui s’exécute à grande échelle. Lors de la génération de votre logique, vous pouvez activer une session de débogage pour travailler de manière interactive avec vos données à l’aide d’un cluster Spark en direct. Pour plus d’informations, consultez Mode de débogage du flux de données de mappage.
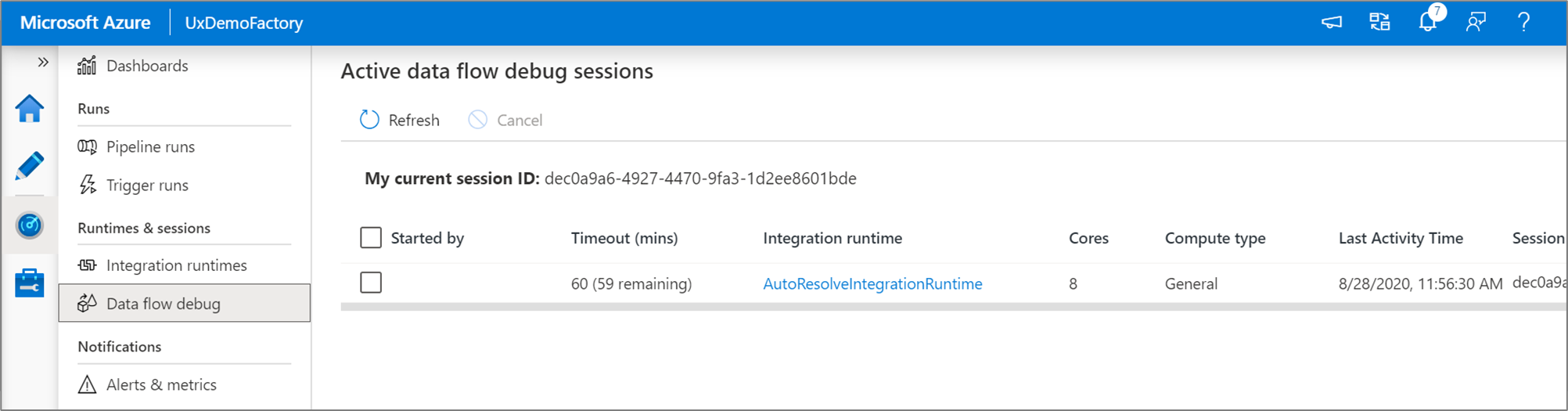
Vous pouvez superviser les sessions de débogage du flux de données qui sont actives dans l’expérience Superviser.
L’aperçu des données dans le concepteur de flux de données et le débogage du pipeline des flux de données sont conçus pour fonctionner de façon optimale avec de petits échantillons de données. Toutefois, si vous devez tester votre logique dans un pipeline ou un flux de données sur de grandes quantités de données, augmentez la taille de l’instance Azure Integration Runtime utilisée dans la session de débogage avec davantage de cœurs et au minimum un calcul à usage général.
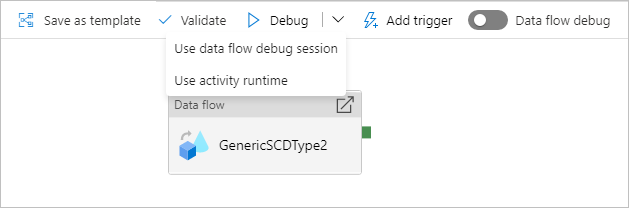
Débogage d’un pipeline avec une activité de flux de données
Lorsque vous procédez à l’exécution d’un débogage de pipeline avec un flux de données, vous disposez de deux options de calcul à utiliser. Vous pouvez utiliser un cluster de débogage existant ou créer un nouveau cluster juste-à-temps pour vos flux de données.
L’utilisation d’une session de débogage existante réduira considérablement le temps de démarrage du flux de données puisque le cluster fonctionne déjà, mais cette pratique n’est pas recommandée pour les charges de travail complexes ou parallèles, car elle peut échouer lorsque plusieurs travaux sont exécutés en même temps.
L’utilisation de l’exécution d’activité permettra de créer un nouveau cluster en utilisant les paramètres spécifiés dans le runtime d’intégration de chaque activité de flux de données. Cela permet d’isoler chaque travail ; cette méthode doit être utilisée pour des charges de travail complexes ou des tests de performance. Vous pouvez également contrôler le temps jusqu’au dernier octet dans Azure IR, afin que les ressources de cluster utilisées pour le débogage restent disponibles pendant cette période pour traiter des demandes de travaux supplémentaires.
Notes
Si, dans votre pipeline, des flux de données s’exécutent en parallèle ou doivent être testés avec de grands jeux de données, choisissez « Utiliser le runtime d’activité » pour que le service puisse utiliser le Runtime d’intégration que vous avez sélectionné dans votre activité de flux de données. Les flux de données pourront ainsi s’exécuter sur plusieurs clusters et prendre en charge vos exécutions de flux de données parallèles.
Contenu connexe
Après avoir testé vos modifications, promouvez-les dans des environnements plus élevés à l’aide de l’intégration et du déploiement continus.