Démarrage rapide : Créer une fabrique de données et un pipeline avec le kit .NET SDK
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Ce guide de démarrage rapide explique comment utiliser le SDK .NET pour créer une fabrique de données Azure. Le pipeline que vous créez dans cette fabrique de données copie les données d’un dossier vers un autre dossier dans un stockage Blob Azure. Pour suivre un tutoriel sur la transformation des données à l’aide d’Azure Data Factory, consultez Tutoriel : Transformer des données à l’aide de Spark.
Notes
Cet article ne fournit pas de présentation détaillée du service Data Factory. Pour une présentation du service Azure Data Factory, consultez Présentation d’Azure Data Factory.
Prérequis
Abonnement Azure
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Rôles Azure
Pour créer des instances Data Factory, le compte d’utilisateur que vous utilisez pour vous connecter à Azure doit être membre des rôles Contributeur ou Propriétaire, ou administrateur de l’abonnement Azure. Pour voir les autorisations dont vous disposez dans l’abonnement, accédez au portail Azure, sélectionnez votre nom d’utilisateur en haut à droite, sélectionnez l’icône « ... » pour plus d’options, puis sélectionnez Mes autorisations. Si vous avez accès à plusieurs abonnements, sélectionnez l’abonnement approprié.
Les exigences applicables à la création et à la gestion des ressources enfants pour Data Factory (jeux de données, services liés, pipelines, déclencheurs et runtimes d’intégration) sont les suivantes :
- Pour créer et gérer des ressources enfants dans le Portail Azure, vous devez appartenir au rôle Contributeurs de Data Factory au niveau du groupe de ressources ou à un niveau supérieur.
- Pour créer et gérer des ressources enfants à l’aide de PowerShell ou du Kit de développement logiciel (SDK), le rôle Contributeur au niveau du groupe de ressources ou à un niveau supérieur est suffisant.
Pour découvrir des exemples d’instructions concernant l’ajout d’un utilisateur à un rôle, consultez l’article décrivant comment ajouter des rôles.
Pour plus d’informations, consultez les articles suivants :
- Rôle Contributeurs de fabrique de données
- Roles and permissions for Azure Data Factory (Rôles et autorisations pour Azure Data Factory)
Compte de Stockage Azure
Dans ce guide de démarrage rapide, vous utilisez un compte de Stockage Azure (plus précisément, un compte de Stockage Blob) à usage général à la fois comme magasins de données source et de destination. Si vous ne possédez pas de compte de Stockage Azure à usage général, consultez Créer un compte de stockage pour en créer un.
Obtenir le nom du compte de stockage
Pour ce guide de démarrage rapide, vous avez besoin du nom de votre compte de Stockage Azure. La procédure suivante détaille les étapes à suivre pour obtenir le nom de votre compte de stockage :
- Dans un navigateur web, accédez au portail Azure et connectez-vous à l’aide de vos nom d’utilisateur et mot de passe Azure.
- Dans le menu Portail Azure, sélectionnez Tous les services, puis sélectionnez Stockage>Comptes de stockage. Vous pouvez également rechercher et sélectionner Comptes de stockage à partir de n’importe quelle page.
- Dans la page Comptes de stockage, appliquez un filtre pour votre compte de stockage (si nécessaire), puis sélectionnez votre compte de stockage.
Vous pouvez également rechercher et sélectionner Comptes de stockage à partir de n’importe quelle page.
Création d’un conteneur d’objets blob
Dans cette section, vous allez créer un conteneur d’objets blob nommé adftutorial dans un stockage Blob Azure.
Dans la page du compte de stockage, sélectionnez Présentation>Conteneurs.
Dans la barre d’outils de la page <Nom du compte> - Conteneurs, sélectionnez Conteneur.
Dans la boîte de dialogue Nouveau conteneur, saisissez le nom adftutorial, puis sélectionnez OK. La page <Nom du compte> - Conteneurs est mise à jour pour inclure adftutorial dans la liste des conteneurs.
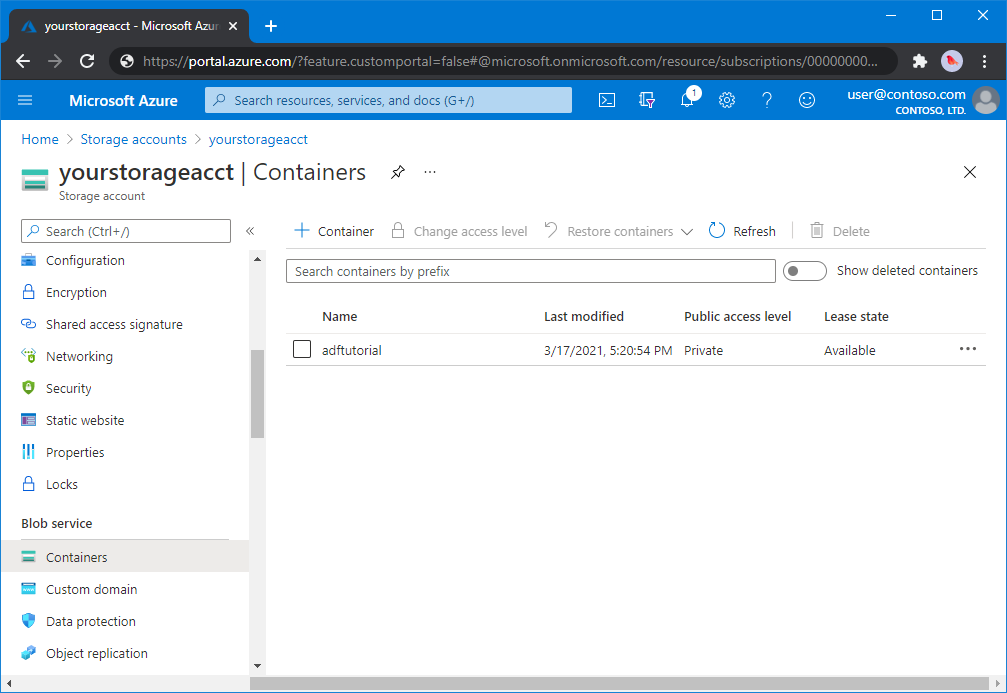
Ajouter un dossier et un fichier d’entrée pour le conteneur d’objets blob
Dans cette section, vous créez un dossier nommé input (entrée) dans le conteneur que vous avez créé, puis chargez un exemple de fichier dans ce dossier. Avant de commencer, ouvrez un éditeur de texte tel que Bloc-notes, puis créez un fichier nommé emp.txt avec le contenu suivant :
John, Doe
Jane, Doe
Enregistrez-le dans le dossier C:\ADFv2QuickStartPSH (si le dossier n’existe pas, créez-le). Revenez ensuite au portail Azure et procédez comme suit :
Dans la page <Nom du compte> - Conteneurs, là où vous vous êtes arrêté, sélectionnez adftutorial dans la liste mise à jour des conteneurs.
- Si vous avez fermé la fenêtre ou accédé à une autre page, connectez-vous au Portail Azure à nouveau.
- Dans le menu Portail Azure, sélectionnez Tous les services, puis sélectionnez Stockage>Comptes de stockage. Vous pouvez également rechercher et sélectionner Comptes de stockage à partir de n’importe quelle page.
- Sélectionnez votre compte de stockage, puis sélectionnez Conteneurs>adftutorial.
Dans la barre d’outils de la page du conteneur adftutorial, sélectionnez Charger.
Dans la page Charger l’objet blob, sélectionnez la zone Fichiers, puis recherchez et sélectionnez le fichier emp.txt.
Développez le titre Avancé. La page s’affiche à présent comme indiqué :
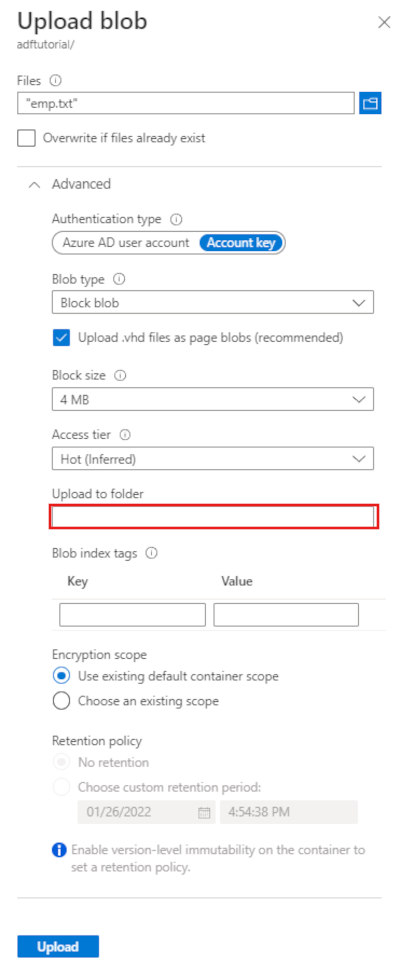
Dans la zone Charger dans le dossier, entrez input.
Cliquez sur le bouton Charger. Vous devriez voir le fichier emp.txt et l’état du chargement dans la liste.
Sélectionnez l’icône Fermer (X) pour fermer la page Charger l’objet blob.
Laissez la page du conteneur adftutorial ouverte. Vous l’utiliserez pour vérifier la sortie à la fin de ce guide de démarrage rapide.
Visual Studio
La procédure pas à pas décrite dans cet article utilise Visual Studio 2019. Les procédures pour Visual Studio 2013, 2015 ou 2017 diffèrent légèrement.
Créer une application dans Microsoft Entra ID
Dans les sections de la Procédure : utiliser le portail pour créer une application et un principal du service Microsoft Entra pouvant accéder aux ressources, suivez les instructions pour effectuer ces tâches :
- Dans Créer une application Microsoft Entra, créez une application qui représente l’application .NET que vous créez dans ce didacticiel. Pour l’URL de connexion, vous pouvez fournir une URL factice, comme indiqué dans l’article (
https://contoso.org/exampleapp). - Dans Obtenir les valeurs pour la connexion, récupérez l’ID d’application et l’ID de locataire, puis notez ces valeurs que vous allez utiliser ultérieurement dans ce didacticiel.
- Dans Certificats et secrets, récupérez la clé d’authentification, puis notez cette valeur que vous allez utiliser ultérieurement dans ce didacticiel.
- Dans Affecter l’application à un rôle, affectez l’application au rôle Contributeur au niveau de l’abonnement de sorte que l’application puisse créer des fabriques de données dans l’abonnement.
Créer un projet Visual Studio
Créez ensuite une application console .NET en C# dans Visual Studio :
- Lancez Visual Studio.
- Dans la fenêtre Démarrer, sélectionnez Créer un projet>Application console (.NET Framework) . .NET version 4.5.2 ou ultérieure est nécessaire.
- Dans Nom du projet, entrez ADFv2QuickStart.
- Sélectionnez Créer pour créer le projet.
Installer les packages NuGet
Cliquez sur Outils>Gestionnaire de package NuGet>Console du Gestionnaire de package.
Dans le volet Console du Gestionnaire de package, exécutez les commandes suivantes pour installer les packages. Pour plus d’informations, consultez la package NuGet Azure.ResourceManager.DataFactory.
Install-Package Azure.ResourceManager.DataFactory -IncludePrerelease Install-Package Azure.Identity
Créer une fabrique de données
Ouvrez Program.cs, insérez les instructions suivantes pour ajouter des références aux espaces de noms.
using Azure; using Azure.Core; using Azure.Core.Expressions.DataFactory; using Azure.Identity; using Azure.ResourceManager; using Azure.ResourceManager.DataFactory; using Azure.ResourceManager.DataFactory.Models; using Azure.ResourceManager.Resources; using System; using System.Collections.Generic;Ajoutez le code suivant à la méthode Main qui définit les variables. Remplacez les espaces réservés par vos valeurs. Pour obtenir la liste des régions Azure dans lesquelles Data Factory est actuellement disponible, sélectionnez les régions qui vous intéressent dans la page suivante, puis développez Analytique pour localiser Data Factory : Disponibilité des produits par région. Les magasins de données (Stockage Azure, Azure SQL Database, etc.) et les services de calcul (HDInsight et autres) utilisés par la fabrique de données peuvent être situés dans d’autres régions.
// Set variables string tenantID = "<your tenant ID>"; string applicationId = "<your application ID>"; string authenticationKey = "<your authentication key for the application>"; string subscriptionId = "<your subscription ID where the data factory resides>"; string resourceGroup = "<your resource group where the data factory resides>"; string region = "<the location of your resource group>"; string dataFactoryName = "<specify the name of data factory to create. It must be globally unique.>"; string storageAccountName = "<your storage account name to copy data>"; string storageKey = "<your storage account key>"; // specify the container and input folder from which all files // need to be copied to the output folder. string inputBlobContainer = "<blob container to copy data from, e.g. containername>"; string inputBlobPath = "<path to existing blob(s) to copy data from, e.g. inputdir/file>"; //specify the contains and output folder where the files are copied string outputBlobContainer = "<blob container to copy data from, e.g. containername>"; string outputBlobPath = "<the blob path to copy data to, e.g. outputdir/file>"; // name of the Azure Storage linked service, blob dataset, and the pipeline string storageLinkedServiceName = "AzureStorageLinkedService"; string blobDatasetName = "BlobDataset"; string pipelineName = "Adfv2QuickStartPipeline";Ajoutez le code suivant à la méthode Main qui crée une fabrique de données.
ArmClient armClient = new ArmClient( new ClientSecretCredential(tenantID, applicationId, authenticationKey, new TokenCredentialOptions { AuthorityHost = AzureAuthorityHosts.AzurePublicCloud }), subscriptionId, new ArmClientOptions { Environment = ArmEnvironment.AzurePublicCloud } ); ResourceIdentifier resourceIdentifier = SubscriptionResource.CreateResourceIdentifier(subscriptionId); SubscriptionResource subscriptionResource = armClient.GetSubscriptionResource(resourceIdentifier); Console.WriteLine("Get an existing resource group " + resourceGroupName + "..."); var resourceGroupOperation = subscriptionResource.GetResourceGroups().Get(resourceGroupName); ResourceGroupResource resourceGroupResource = resourceGroupOperation.Value; Console.WriteLine("Create a data factory " + dataFactoryName + "..."); DataFactoryData dataFactoryData = new DataFactoryData(AzureLocation.EastUS2); var dataFactoryOperation = resourceGroupResource.GetDataFactories().CreateOrUpdate(WaitUntil.Completed, dataFactoryName, dataFactoryData); Console.WriteLine(dataFactoryOperation.WaitForCompletionResponse().Content); // Get the data factory resource DataFactoryResource dataFactoryResource = dataFactoryOperation.Value;
Créer un service lié
Ajoutez le code suivant à la méthode Main qui crée un service lié Stockage Azure.
Vous allez créer des services liés dans une fabrique de données pour lier vos magasins de données et vos services de calcul à la fabrique de données. Dans ce guide de démarrage rapide, vous devez uniquement créer un service lié Stockage Blob Azure pour la source de copie et le magasin récepteur ; elle est nommée « AzureBlobStorageLinkedService » dans l’exemple.
// Create an Azure Storage linked service
Console.WriteLine("Create a linked service " + storageLinkedServiceName + "...");
AzureBlobStorageLinkedService azureBlobStorage = new AzureBlobStorageLinkedService()
{
ConnectionString = azureBlobStorageConnectionString
};
DataFactoryLinkedServiceData linkedServiceData = new DataFactoryLinkedServiceData(azureBlobStorage);
var linkedServiceOperation = dataFactoryResource.GetDataFactoryLinkedServices().CreateOrUpdate(WaitUntil.Completed, storageLinkedServiceName, linkedServiceData);
Console.WriteLine(linkedServiceOperation.WaitForCompletionResponse().Content);
Créer un jeu de données
Ajoutez le code suivant à la méthode Main qui crée un jeu de données de texte délimité.
Vous définissez un jeu de données qui représente les données à copier d’une source vers un récepteur. Dans cet exemple, ce jeu de données de texte délimité fait référence au service lié Stockage Blob Azure que vous avez créé à l’étape précédente. Le jeu de données prend deux paramètres dont la valeur est définie dans une activité qui consomme le jeu de données. Les paramètres sont utilisés pour construire le « conteneur » et le « folderPath » pointant vers l’emplacement où les données résident/sont stockées.
// Create an Azure Blob dataset
DataFactoryLinkedServiceReference linkedServiceReference = new DataFactoryLinkedServiceReference(DataFactoryLinkedServiceReferenceType.LinkedServiceReference, storageLinkedServiceName);
DelimitedTextDataset delimitedTextDataset = new DelimitedTextDataset(linkedServiceReference)
{
DataLocation = new AzureBlobStorageLocation
{
Container = DataFactoryElement<string>.FromExpression("@dataset().container"),
FileName = DataFactoryElement<string>.FromExpression("@dataset().path")
},
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("container",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("path",new EntityParameterSpecification(EntityParameterType.String))
},
FirstRowAsHeader = false,
QuoteChar = "\"",
EscapeChar = "\\",
ColumnDelimiter = ","
};
DataFactoryDatasetData datasetData = new DataFactoryDatasetData(delimitedTextDataset);
var datasetOperation = dataFactoryResource.GetDataFactoryDatasets().CreateOrUpdate(WaitUntil.Completed, blobDatasetName, datasetData);
Console.WriteLine(datasetOperation.WaitForCompletionResponse().Content);
Créer un pipeline
Ajoutez le code suivant à la méthode Main qui crée un pipeline avec une activité de copie.
Dans cet exemple, ce pipeline contient une activité et prend quatre paramètres : le conteneur d’objets blob d’entrée et le chemin d’accès, ainsi que le conteneur d’objets blob de sortie et le chemin d’accès. Les valeurs de ces paramètres sont définies quand le pipeline est déclenché/exécuté. L’activité de copie fait référence au même jeu de données d’objet blob créé à l’étape précédente comme entrée et sortie. Lorsque le jeu de données est utilisé comme jeu de données d’entrée, le conteneur d’entrée et le chemin d’accès sont spécifiés. Et, lorsque le jeu de données est utilisé comme jeu de données de sortie, le conteneur de sortie et le chemin d’accès sont spécifiés.
// Create a pipeline with a copy activity
Console.WriteLine("Creating pipeline " + pipelineName + "...");
DataFactoryPipelineData pipelineData = new DataFactoryPipelineData()
{
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("inputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("inputPath",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputPath",new EntityParameterSpecification(EntityParameterType.String))
},
Activities =
{
new CopyActivity("CopyFromBlobToBlob",new DataFactoryBlobSource(),new DataFactoryBlobSink())
{
Inputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.inputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.inputPath\""))
}
}
},
Outputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.outputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.outputPath\""))
}
}
}
}
}
};
var pipelineOperation = dataFactoryResource.GetDataFactoryPipelines().CreateOrUpdate(WaitUntil.Completed, pipelineName, pipelineData);
Console.WriteLine(pipelineOperation.WaitForCompletionResponse().Content);
Créer une exécution du pipeline
Ajoutez le code suivant à la méthode Main qui déclenche une exécution du pipeline.
Ce code définit également les valeurs des inputContainer, inputPath, outputContaineret paramètres outputPath spécifiés dans le pipeline avec les valeurs réelles des chemins d’objet blob source et récepteur.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, BinaryData> parameters = new Dictionary<string, BinaryData>()
{
{ "inputContainer",BinaryData.FromObjectAsJson(inputBlobContainer) },
{ "inputPath",BinaryData.FromObjectAsJson(inputBlobPath) },
{ "outputContainer",BinaryData.FromObjectAsJson(outputBlobContainer) },
{ "outputPath",BinaryData.FromObjectAsJson(outputBlobPath) }
};
var pipelineResource = dataFactoryResource.GetDataFactoryPipeline(pipelineName);
var runResponse = pipelineResource.Value.CreateRun(parameters);
Console.WriteLine("Pipeline run ID: " + runResponse.Value.RunId);
Surveiller une exécution du pipeline
Ajoutez le code suivant à la méthode Main afin de vérifier continuellement l’état jusqu’à la fin de la copie des données.
// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); DataFactoryPipelineRunInfo pipelineRun; while (true) { pipelineRun = dataFactoryResource.GetPipelineRun(runResponse.Value.RunId.ToString()); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress" || pipelineRun.Status == "Queued") System.Threading.Thread.Sleep(15000); else break; }Ajoutez le code suivant à la méthode Main qui récupère les détails de l’exécution de l’activité de copie, tels que la taille des données lues ou écrites.
// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); var queryResponse = dataFactoryResource.GetActivityRun(pipelineRun.RunId.ToString(), new RunFilterContent(DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10))); var enumerator = queryResponse.GetEnumerator(); enumerator.MoveNext(); if (pipelineRun.Status == "Succeeded") Console.WriteLine(enumerator.Current.Output); else Console.WriteLine(enumerator.Current.Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Exécuter le code
Créez et démarrez l’application, puis vérifiez l’exécution du pipeline.
La console affiche la progression de la création de la fabrique de données, du service lié, des jeux de données, du pipeline et de l’exécution du pipeline. Elle vérifie ensuite l’état de l’exécution du pipeline. Patientez jusqu’à voir les détails de l’exécution de l’activité de copie avec la taille des données lues/écrites. Utilisez ensuite des outils comme l’Explorateur Stockage Azure pour vérifier que les objets blob sont copiés dans « outputBlobPath » depuis « inputBlobPath » comme vous l’avez spécifié dans les variables.
Exemple de sortie
Create a data factory quickstart-adf...
{
"name": "quickstart-adf",
"type": "Microsoft.DataFactory/factories",
"properties": {
"provisioningState": "Succeeded",
"version": "2018-06-01"
},
"location": "eastus2"
}
Create a linked service AzureBlobStorage...
{
"name": "AzureBlobStorage",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;",
"encryptedCredential": "<encryptedCredential>"
}
}
}
Creating dataset BlobDelimitedDataset...
{
"name": "BlobDelimitedDataset",
"type": "Microsoft.DataFactory/factories/datasets",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureBlobStorage"
},
"parameters": {
"container": {
"type": "String"
},
"path": {
"type": "String"
}
},
"typeProperties": {
"location": {
"container": {
"type": "Expression",
"value": "@dataset().container"
},
"type": "AzureBlobStorageLocation",
"fileName": {
"type": "Expression",
"value": "@dataset().path"
}
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\\",
"firstRowAsHeader": false
}
}
}
Creating pipeline Adfv2QuickStartPipeline...
{
"properties": {
"activities": [
{
"inputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.inputContainer",
"path": "@pipeline().parameters.inputPath"
}
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.outputContainer",
"path": "@pipeline().parameters.outputPath"
}
}
],
"name": "CopyFromBlobToBlob",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
}
}
],
"parameters": {
"inputContainer": {
"type": "String"
},
"inputPath": {
"type": "String"
},
"outputContainer": {
"type": "String"
},
"outputPath": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 3aa26ffc-5bee-4db9-8bac-ccbc2d7b51c1
Checking pipeline run status...
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 1048,
"dataWritten": 1048,
"filesRead": 1,
"filesWritten": 1,
"sourcePeakConnections": 1,
"sinkPeakConnections": 1,
"copyDuration": 8,
"throughput": 1.048,
"errors": [],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"usedDataIntegrationUnits": 4,
"billingReference": {
"activityType": "DataMovement",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
],
"totalBillableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
]
},
"usedParallelCopies": 1,
"executionDetails": [
{
"source": {
"type": "AzureBlobStorage"
},
"sink": {
"type": "AzureBlobStorage"
},
"status": "Succeeded",
"start": "2023-12-15T10:25:33.9991558Z",
"duration": 8,
"usedDataIntegrationUnits": 4,
"usedParallelCopies": 1,
"profile": {
"queue": {
"status": "Completed",
"duration": 5
},
"transfer": {
"status": "Completed",
"duration": 1,
"details": {
"listingSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"readingFromSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"writingToSink": {
"type": "AzureBlobStorage",
"workingDuration": 0
}
}
}
},
"detailedDurations": {
"queuingDuration": 5,
"transferDuration": 1
}
}
],
"dataConsistencyVerification": {
"VerificationResult": "NotVerified"
}
}
Press any key to exit...
Vérifier la sortie
Le pipeline crée automatiquement le dossier de sortie dans le conteneur d’objets blob adftutorial. Ensuite, il copie le fichier emp.txt à partir du dossier d’entrée dans le dossier de sortie.
- Sur le portail Azure, dans la page de conteneur adftutorial que vous avez arrêtée dans la section Ajouter un dossier et un fichier d’entrée pour le conteneur d’objets blob ci-dessus, sélectionnez Actualiser pour voir le dossier de sortie.
- Dans la liste des dossiers, sélectionnez sortie.
- Vérifiez que le fichier emp.txt a été copié dans le dossier de sortie.
Nettoyer les ressources
Pour supprimer par programmation la fabrique de données, ajoutez les lignes de code suivantes au programme :
Console.WriteLine("Deleting the data factory");
dataFactoryResource.Delete(WaitUntil.Completed);
Étapes suivantes
Dans cet exemple, le pipeline copie les données d’un emplacement vers un autre dans un stockage Blob Azure. Consultez les didacticiels pour en savoir plus sur l’utilisation de Data Factory dans d’autres scénarios.