Contrôle d’accès affiné sur le calcul mono-utilisateur
Important
Cette fonctionnalité est disponible en préversion publique.
Cet article présente la fonctionnalité de filtrage des données qui permet un contrôle d’accès affiné sur les requêtes qui s’exécutent sur le calcul mono-utilisateur (calcul à usage général ou calcul des travaux configuré avec le mode d’accès mono-utilisateur). Voir Modes d’accès aux fichiers.
Ce filtrage des données est effectué en arrière-plan à l’aide du calcul serverless.
Pourquoi certaines requêtes sur le calcul mono-utilisateur nécessitent-elles un filtrage des données ?
Unity Catalog vous permet de contrôler l’accès aux données tabulaires au niveau de la colonne et de la ligne (également appelé contrôle d’accès affiné) à l’aide des fonctionnalités suivantes :
Lorsque les utilisateurs interrogent des vues qui excluent les données des tables référencées ou des tables de requête qui appliquent des filtres et des masques, ils peuvent utiliser l’une des ressources de calcul suivantes sans limitations :
- Entrepôts SQL
- Calcul partagé
Toutefois, si vous utilisez le calcul mono-utilisateur pour exécuter de telles requêtes, le calcul et votre espace de travail doivent répondre à des exigences spécifiques :
La ressource de calcul mono-utilisateur doit se trouver sur Databricks Runtime 15.4 LTS ou version ultérieure.
L’espace de travail doit être activé pour le calcul serverless pour les travaux, les notebooks et les tables Delta Live.
Pour vérifier que votre région d’espace de travail prend en charge le calcul serverless, consultez Fonctionnalités avec une disponibilité régionale limitée.
Si votre ressource de calcul mono-utilisateur et votre espace de travail répondent à ces exigences, le filtrage des données est exécuté automatiquement chaque fois que vous interrogez une vue ou une table qui utilise un contrôle d’accès affiné.
Prise en charge des vues matérialisées, des tables de diffusion en continu et des vues standard
Outre les vues dynamiques, les filtres de lignes et les masques de colonne, le filtrage des données permet également d’effectuer des requêtes sur les vues et tables suivantes qui ne sont pas prises en charge sur le calcul mono-utilisateur exécutant Databricks Runtime 15.3 et versions antérieures :
-
Sur le calcul mono-utilisateur exécutant Databricks Runtime 15.3 et versions antérieures, l’utilisateur qui exécute la requête sur la vue doit avoir
SELECTsur les tables et vues référencées par la vue, ce qui signifie que vous ne pouvez pas utiliser les vues pour fournir un contrôle d’accès affiné. Sur Databricks Runtime 15.4 avec filtrage des données, l’utilisateur qui interroge la vue n’a pas besoin d’accéder aux tables et vues référencées.
Comment le filtrage des données fonctionne-t-il sur le calcul mono-utilisateur ?
Chaque fois qu’une requête accède aux objets de base de données suivants, la ressource de calcul mono-utilisateur transmet la requête au calcul serverless pour effectuer le filtrage des données :
- Vues intégrées sur des tables sur lesquelles l’utilisateur n’a pas le privilège
SELECT - Vues dynamiques
- Tableaux avec des filtres de lignes ou des masques de colonne définis
- Vues matérialisées et tables de diffusion en continu
Dans le diagramme suivant, un utilisateur a SELECT sur table_1, view_2 et table_w_rls, avec des filtres de lignes appliqués. L’utilisateur n’a pas SELECT sur table_2, qui est référencé par view_2.

La requête sur table_1 est entièrement gérée par la ressource de calcul mono-utilisateur, car aucun filtrage n’est nécessaire. Les requêtes sur view_2 et table_w_rls nécessitent le filtrage des données pour retourner les données auxquelles l’utilisateur a accès. Ces requêtes sont gérées par la capacité de filtrage des données sur le calcul serverless.
Quels sont les coûts encourus ?
Les clients sont facturés pour les ressources de calcul serverless utilisées pour effectuer des opérations de filtrage des données. Pour plus d’informations sur la tarification, consultez Niveaux et extensions de plateforme.
Vous pouvez interroger la table d’utilisation de facturation du système pour voir le montant qui vous a été facturé. Par exemple, la requête suivante décompose les coûts de calcul par utilisateur :
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Afficher le niveau de performance des requêtes lorsque le filtrage des données est engagé
L’interface utilisateur Spark pour le calcul mono-utilisateur affiche les métriques que vous pouvez utiliser pour comprendre le niveau de performance de vos requêtes. Pour chaque requête que vous exécutez sur la ressource de calcul, l’onglet SQL/Dataframe affiche la représentation du graphique de requête. Si une requête a été impliquée dans le filtrage des données, l’interface utilisateur affiche un nœud opérateur RemoteSparkConnectScan au bas du graphique. Ce nœud affiche les métriques que vous pouvez utiliser pour examiner le niveau de performance des requêtes. Consultez Afficher des informations de calcul dans l’interface utilisateur Apache Spark.
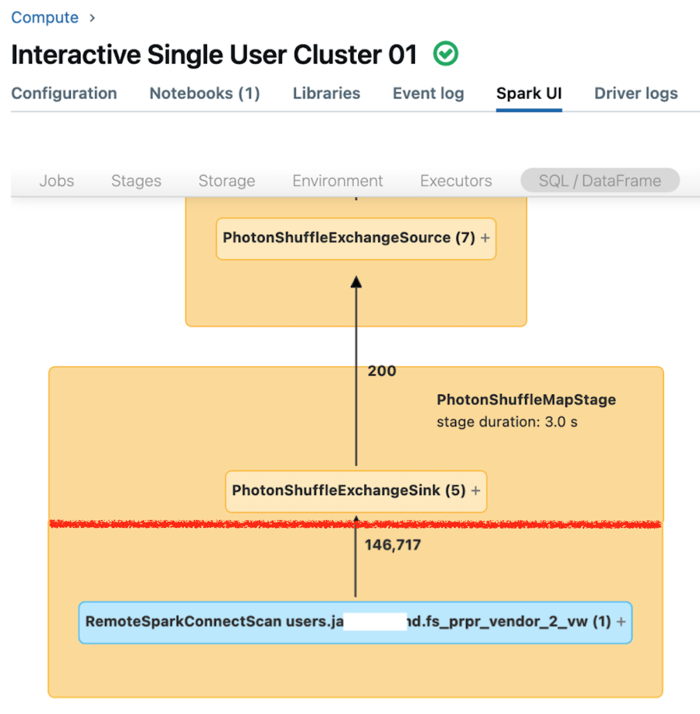
Développez le nœud d’opérateur RemoteSparkConnectScan pour voir les métriques qui répondent aux questions suivantes :
- Combien de temps le filtrage des données a-t-il pris ? Afficher le « durée totale d’exécution à distance ».
- Combien de lignes restent après le filtrage des données ? Afficher la « sortie des lignes ».
- Quelle quantité de données (en octets) a été retournée après le filtrage des données ? Afficher la « taille de sortie des lignes ».
- Combien de fichiers de données ont été supprimés de la partition et n’ont pas eu besoin d’être lus à partir du stockage ? Afficher les « fichiers supprimés » et la « taille des fichiers supprimés ».
- Combien de fichiers de données n’ont pas pu être supprimés et ont dû être lus à partir du stockage ? Afficher les « fichiers lus » et la « taille des fichiers lus ».
- Parmi les fichiers qui devaient être lus, combien étaient déjà présents dans le cache ? Afficher la « taille atteinte par le cache » et « taille manquée par le cache ».
Limites
Pendant la préversion publique, les limitations suivantes s’appliquent :
Aucune prise en charge pour les opérations d’écriture ou d’actualisation des tables sur les tables qui ont des filtres de lignes ou des masques de colonne appliqués.
Plus précisément, les opérations DML, telles que
INSERT,DELETE,UPDATE,REFRESH TABLEetMERGE, ne sont pas prises en charge. Vous pouvez uniquement lire (SELECT) à partir de ces tables.Les jointures autonomes sont bloquées par défaut lorsque le filtrage des données est appelé, mais vous pouvez les autoriser en définissant
spark.databricks.remoteFiltering.blockSelfJoinssur false sur le calcul sur lequel vous exécutez ces commandes.Avant d’activer les jointures autonomes sur une ressource de calcul mono-utilisateur, sachez qu’une requête de jointure autonome gérée par la capacité de filtrage des données peut retourner différents instantanés de la même table distante.