Qu’est-ce que l’entrepôt de données sur Azure Databricks ?
L’entrepôt de données fait référence à la collecte et au stockage de données à partir de plusieurs sources afin qu’elles soient rapidement accessibles pour la création de rapports et des insights métier. Cet article contient des concepts clés pour créer un entrepôt de données dans votre data lakehouse.
Entrepôt de données dans votre lakehouse
Databricks SQL et l’architecture de lakehouse apportent des capacités d’entrepôt de données cloud dans vos lacs de données. En utilisant des structures de données, des relations et des outils de gestion connus, vous pouvez modéliser un entrepôt de données économique et hautement performant qui s’exécute directement sur votre lac de données. Pour obtenir plus d’informations, consultez Qu’est-ce qu’un lakehouse ?
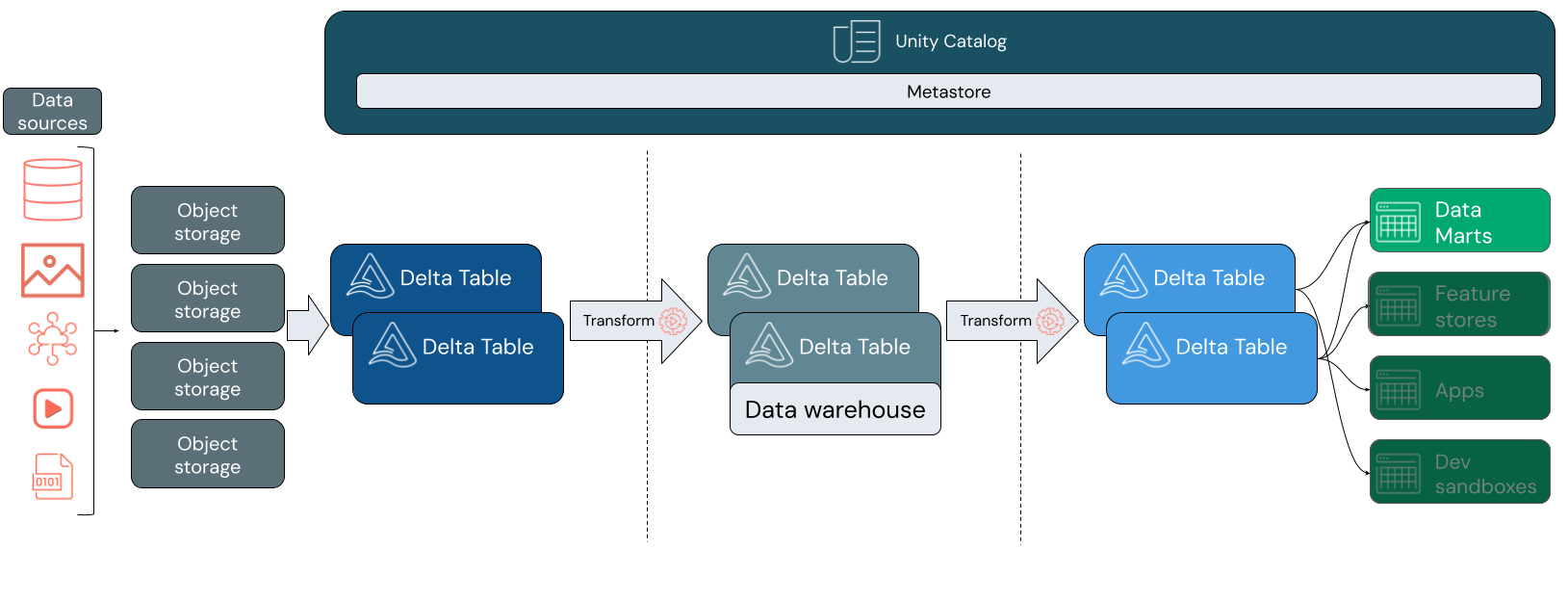
Comme avec un entrepôt de données classique, vous modélisez des données en fonction des exigences métier, puis vous les diffusez vers vos utilisateurs finaux pour les analyses et les rapports. Contrairement à l’entrepôt de données classique, vous pouvez éviter de cloisonner vos données d’analyse métier ou de créer des copies redondantes qui deviennent rapidement obsolètes.
La création d’un entrepôt de données au sein de votre lakehouse vous permet d’apporter toutes vos données dans un seul système et de tirer parti de fonctionnalités telles qu’Unity Catalog et Delta Lake.
Unity Catalog ajoute un modèle de gouvernance unifié afin que vous puissiez sécuriser et auditer l’accès aux données d’audit et fournir des informations de traçabilité sur des tables en aval. Delta Lake ajoute des transactions ACID et une évolution du schéma, parmi d’autres outils puissants pour conserver vos données fiables, évolutives et de haute qualité.
Présentation de Databricks SQL
Notes
Databricks SQL Serverless n’est pas disponible dans Azure Chine. Databricks SQL n’est pas disponible dans les régions Azure Government.
Databricks SQL est une collection de services qui apporte des capacités d’entrepôt de données et des performances dans vos lacs de données. Databricks SQL prend en charge des formats ouverts et SQL ANSI standard. Un éditeur SQL et des outils de tableau de bord dans la plateforme permettent aux membres d’une équipe de collaborer directement avec d’autres utilisateurs Databricks dans l’espace de travail. Databricks SQL intègre également divers outils pour que les analystes puissent créer des requêtes et des tableaux de bord dans leurs environnements préférés sans s’adapter à une nouvelle plateforme.
Databricks SQL fournit des ressources de calcul générales qui sont exécutées sur les tables du lakehouse. Databricks SQL est alimenté par des entrepôts SQL, anciennement appelés points de terminaison SQL, offrant des ressources de calcul SQL évolutives découplées du stockage.
Pour plus d’informations sur les valeurs et options par défaut de SQL Warehouse, consultez Se connecter à un entrepôt SQL Warehouse.
Databricks SQL s’intègre à Unity Catalog pour que vous puissiez découvrir, auditer et régir des ressources de données à partir d’un seul endroit. Pour découvrir plus d’informations, consultez Qu’est-ce que Unity Catalog ?
Modélisation des données sur Azure Databricks
Un lakehouse prend en charge divers styles de modélisation. L’image suivante montre comment les données sont organisées et modélisées lors de leur déplacement via différentes couches d’un lakehouse.
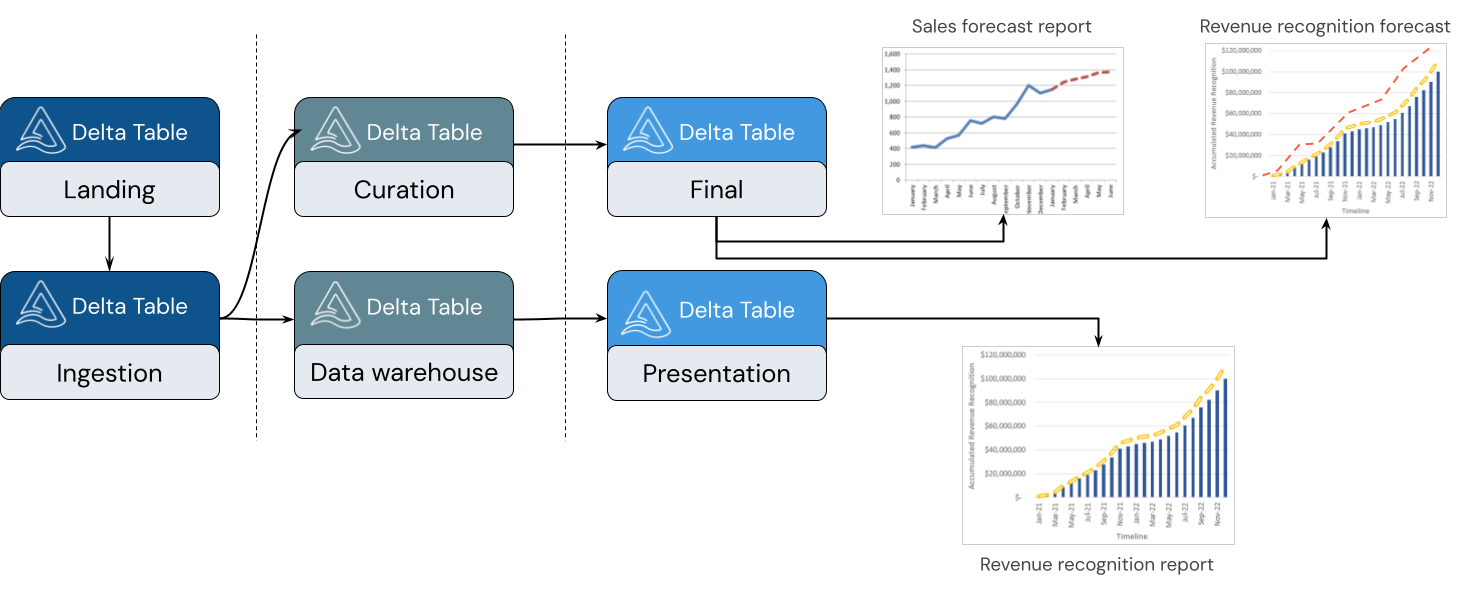
Architecture de médaillon
L’architecture du médaillon est un modèle de conception de données décrivant une série de couches de données affinées de manière incrémentielle qui fournit une structure de base dans le lakehouse. Les couches bronze, argent et or indiquent une qualité de données croissante à chaque niveau, l’or représentant la qualité la plus élevée. Pour plus d’informations, consultez Qu’est-ce que l’architecture de lakehouse en médaillon ?
Dans un lakehouse, chaque couche peut contenir une ou plusieurs tables. L’entrepôt de données est modélisé au niveau de la couche argent et alimente des datamarts spécialisés au niveau de la couche or.
Couche bronze
Les données peuvent entrer dans votre lakehouse dans n’importe quel format et via toute combinaison de transactions par lots ou diffusion en continu. La couche argent offre l’espace d’atterrissage pour l’ensemble de vos données brutes dans leur format d’origine. Ces données sont converties en tables Delta.
Couche argent
La couche argent réunit des données à partir de différentes sources. Pour la partie de l’entreprise qui se concentre sur les applications de science des données et d’apprentissage automatique, il s’agit de l’emplacement où vous commencez à organiser les ressources de données utiles. Ce processus est souvent marqué par un accent mis sur la vitesse et l’agilité.
La couche argent est également l’emplacement où vous pouvez intégrer avec précaution des données à partir de sources différentes pour créer un entrepôt de données s’alignant sur vos processus métier existants. Ces données suivent souvent un modèle Troisième forme normale (3NF) ou Coffre de données. La spécification des contraintes de clé étrangère et primaire permet aux utilisateurs finaux de comprendre les relations de tables lors de l’utilisation d’Unity Catalog. Votre entrepôt de données doit servir comme source unique de vérité pour vos datamarts.
L’entrepôt de données lui-même est un schéma lors de l’écriture ou atomique. Il est optimisé pour les modifications afin que vous puissiez rapidement modifier l’entrepôt de données pour qu’il corresponde à vos besoins actuels lorsque vos processus métier changent ou évoluent.
Couche or
La couche or constitue la couche de présentation qui peut contenir un ou plusieurs datamarts. Les datamarts sont souvent des modèles dimensionnels sous forme d’ensemble de tables liées qui capturent une perspective métier spécifique.
La couche or héberge également les bacs à sable de science des données et des services pour activer les analyses en libre-service et la science des données dans l’entreprise. La fourniture de ces bacs à sable et de leurs clusters de calcul distincts empêche les équipes commerciales de créer des copies de données en dehors du lakehouse.
Étape suivante
Pour découvrir plus d’informations sur les principes et les meilleures pratiques pour l’implémentation et l’exploitation d’un lakehouse en tirant parti de Databricks, consultez Présentation du data lakehouse well-architected.