Express.js application convertit du texte en parole avec Azure AI Speech
Dans ce tutoriel, ajoutez Azure AI Speech à une application Express.js existante pour ajouter une conversion de texte en parole à l’aide du service Azure AI Speech. La conversion de texte en paroles vous permet de fournir du contenu audio sans le coût associé à sa génération manuelle.
Ce tutoriel montre 3 façons différentes de convertir du texte en parole à partir d’Azure AI Speech :
- Le client JavaScript reçoit l’audio directement
- Le serveur JavaScript reçoit le contenu audio d’un fichier (*.MP3)
- Le serveur JavaScript reçoit le contenu audio d’un arrayBuffer en mémoire
Architecture de l'application
Ce tutoriel prend une application Express.js minimale et y ajoute des fonctionnalités en utilisant une combinaison des éléments suivants :
- nouvelle route pour l’API du serveur pour permettre la conversion de texte en paroles, en retournant un flux MP3
- nouvelle route pour un formulaire HTML pour vous permettre d’entrer vos informations
- nouveau formulaire HTML avec JavaScript, qui fournit un appel côté client au service Speech
Cette application fournit trois appels différents pour convertir de la parole en texte :
- Le premier appel du serveur crée un fichier sur le serveur, puis le retourne au client. En règle générale, vous utiliserez cette opération pour un texte long ou pour un texte dont vous savez qu’il doit être délivré plusieurs fois.
- Le deuxième appel de serveur est destiné au texte à court terme et est conservé en mémoire avant de revenir au client.
- L’appel du client montre un appel direct au service Speech en utilisant le SDK. Vous pouvez choisir d’effectuer cet appel si vous disposez d’une application cliente uniquement, sans serveur.
Prérequis
Node.js LTS installé sur votre ordinateur local.
Visual Studio Code installé sur votre machine locale.
L’extension Azure App Service pour VS Code (installée dans VS Code).
Git : utilisé pour l’envoi (push) vers GitHub, qui active l’action GitHub.
Utiliser Azure Cloud Shell à l’aide de bash

Si vous préférez, installez l’interface Azure CLI pour exécuter les commandes de référence de l’interface de ligne de commande.
- Si vous utilisez une installation locale, connectez-vous à Azure CLI à l’aide de la commande az login. Pour finir le processus d’authentification, suivez les étapes affichées dans votre terminal. Consultez Se connecter avec Azure CLI pour découvrir plus d’options de connexion.
- Lorsque vous y êtes invité, installez les extensions Azure CLI lors de la première utilisation. Pour plus d’informations sur les extensions, consultez Utiliser des extensions avec Azure CLI.
- Exécutez az version pour rechercher la version et les bibliothèques dépendantes installées. Pour effectuer une mise à niveau vers la dernière version, exécutez az upgrade.
Télécharger le dépôt d’exemples Express.js
En utilisant git, clonez le dépôt d’exemples Express.js sur votre ordinateur local.
git clone https://github.com/Azure-Samples/js-e2e-express-serverAccédez au nouveau répertoire de l’exemple.
cd js-e2e-express-serverOuvrez le projet dans Visual Studio Code.
code .Ouvrez un nouveau terminal dans Visual Studio Code et installez les dépendances du projet.
npm install
Installer le Kit de développement logiciel (SDK) Azure AI Speech pour JavaScript
À partir du terminal Visual Studio Code, installez le Kit de développement logiciel (SDK) Azure AI Speech.
npm install microsoft-cognitiveservices-speech-sdk
Créer un module Speech pour l’application Express.js
Pour intégrer le SDK Speech à l’application Express.js, créez un fichier dans le dossier
srcnomméazure-cognitiveservices-speech.js.Ajoutez le code suivant pour extraire les dépendances et créer une fonction pour convertir du texte en paroles.
// azure-cognitiveservices-speech.js const sdk = require('microsoft-cognitiveservices-speech-sdk'); const { Buffer } = require('buffer'); const { PassThrough } = require('stream'); const fs = require('fs'); /** * Node.js server code to convert text to speech * @returns stream * @param {*} key your resource key * @param {*} region your resource region * @param {*} text text to convert to audio/speech * @param {*} filename optional - best for long text - temp file for converted speech/audio */ const textToSpeech = async (key, region, text, filename)=> { // convert callback function to promise return new Promise((resolve, reject) => { const speechConfig = sdk.SpeechConfig.fromSubscription(key, region); speechConfig.speechSynthesisOutputFormat = 5; // mp3 let audioConfig = null; if (filename) { audioConfig = sdk.AudioConfig.fromAudioFileOutput(filename); } const synthesizer = new sdk.SpeechSynthesizer(speechConfig, audioConfig); synthesizer.speakTextAsync( text, result => { const { audioData } = result; synthesizer.close(); if (filename) { // return stream from file const audioFile = fs.createReadStream(filename); resolve(audioFile); } else { // return stream from memory const bufferStream = new PassThrough(); bufferStream.end(Buffer.from(audioData)); resolve(bufferStream); } }, error => { synthesizer.close(); reject(error); }); }); }; module.exports = { textToSpeech };- Paramètres - Le fichier extrait les dépendances pour utiliser le SDK, les flux, les mémoires tampons et le système de fichiers (fs). La fonction
textToSpeechprend quatre arguments. Si un nom de fichier avec un chemin local est envoyé, le texte est converti en fichier audio. Si vous n’envoyez pas de nom de fichier, un flux audio en mémoire est créé. - Méthode du SDK Speech - La méthode du SDK Speech synthesizer.speakTextAsync retourne des types différents selon la configuration qu’il reçoit.
La méthode retourne le résultat, qui diffère en fonction de ce que la méthode a été demandée :
- Créer un fichier
- Créer un flux en mémoire sous la forme d’un tableau de mémoires tampons
- Format audio - Le format audio sélectionné est MP3, mais d’autres formats existent ainsi que d’autres méthodes de configuration audio.
La méthode locale,
textToSpeech, wrappe et convertit la fonction de rappel du SDK en une promesse.- Paramètres - Le fichier extrait les dépendances pour utiliser le SDK, les flux, les mémoires tampons et le système de fichiers (fs). La fonction
Créer une route pour l’application Express.js
Ouvrez le fichier
src/server.js.Ajoutez le module
azure-cognitiveservices-speech.jsen tant que dépendance en haut du fichier :const { textToSpeech } = require('./azure-cognitiveservices-speech');Ajoutez une nouvelle itinéraire d’API pour appeler la méthode textToSpeech créée dans la section précédente du tutoriel. Ajoutez ce code après l’itinéraire
/api/hello.// creates a temp file on server, the streams to client /* eslint-disable no-unused-vars */ app.get('/text-to-speech', async (req, res, next) => { const { key, region, phrase, file } = req.query; if (!key || !region || !phrase) res.status(404).send('Invalid query string'); let fileName = null; // stream from file or memory if (file && file === true) { fileName = `./temp/stream-from-file-${timeStamp()}.mp3`; } const audioStream = await textToSpeech(key, region, phrase, fileName); res.set({ 'Content-Type': 'audio/mpeg', 'Transfer-Encoding': 'chunked' }); audioStream.pipe(res); });Cette méthode prend les paramètres obligatoires et facultatifs pour la méthode
textToSpeechà partir de la chaîne de requête. Si un fichier doit être créé, un nom de fichier unique est développé. La méthodetextToSpeechest appelée de manière asynchrone et transmet le résultat à l’objet de réponse (res).
Mettre à jour la page web du client avec un formulaire
Mettez à jour la page web HTML du client avec un formulaire qui recueille les paramètres obligatoires. Le paramètre facultatif est passé en fonction du contrôle audio que l’utilisateur sélectionne. Comme ce tutoriel fournit un mécanisme permettant d’appeler le service Azure Speech à partir du client, ce code JavaScript est également fourni.
Ouvrez le fichier /public/client.html et remplacez son contenu par ceci :
<!DOCTYPE html>
<html lang="en">
<head>
<title>Microsoft Cognitive Services Demo</title>
<meta charset="utf-8" />
</head>
<body>
<div id="content" style="display:none">
<h1 style="font-weight:500;">Microsoft Cognitive Services Speech </h1>
<h2>npm: microsoft-cognitiveservices-speech-sdk</h2>
<table width="100%">
<tr>
<td></td>
<td>
<a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/get-started" target="_blank">Azure
Cognitive Services Speech Documentation</a>
</td>
</tr>
<tr>
<td align="right">Your Speech Resource Key</td>
<td>
<input id="resourceKey" type="text" size="40" placeholder="Your resource key (32 characters)" value=""
onblur="updateSrc()">
</tr>
<tr>
<td align="right">Your Speech Resource region</td>
<td>
<input id="resourceRegion" type="text" size="40" placeholder="Your resource region" value="eastus"
onblur="updateSrc()">
</td>
</tr>
<tr>
<td align="right" valign="top">Input Text (max 255 char)</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:50px" maxlength="255"
onblur="updateSrc()">all good men must come to the aid</textarea></td>
</tr>
<tr>
<td align="right">
Stream directly from Azure Cognitive Services
</td>
<td>
<div>
<button id="clientAudioAzure" onclick="getSpeechFromAzure()">Get directly from Azure</button>
</div>
</td>
</tr>
<tr>
<td align="right">
Stream audio from file on server</td>
<td>
<audio id="serverAudioFile" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
<tr>
<td align="right">Stream audio from buffer on server</td>
<td>
<audio id="serverAudioStream" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script
src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js">
</script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var resultDiv;
// subscription key and region for speech services.
var resourceKey = null;
var resourceRegion = "eastus";
var authorizationToken;
var SpeechSDK;
var synthesizer;
var phrase = "all good men must come to the aid"
var queryString = null;
var audioType = "audio/mpeg";
var serverSrc = "/text-to-speech";
document.getElementById('serverAudioStream').disabled = true;
document.getElementById('serverAudioFile').disabled = true;
document.getElementById('clientAudioAzure').disabled = true;
// update src URL query string for Express.js server
function updateSrc() {
// input values
resourceKey = document.getElementById('resourceKey').value.trim();
resourceRegion = document.getElementById('resourceRegion').value.trim();
phrase = document.getElementById('phraseDiv').value.trim();
// server control - by file
var serverAudioFileControl = document.getElementById('serverAudioFile');
queryString += `%file=true`;
const fileQueryString = `file=true®ion=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioFileControl.src = `${serverSrc}?${fileQueryString}`;
console.log(serverAudioFileControl.src)
serverAudioFileControl.type = "audio/mpeg";
serverAudioFileControl.disabled = false;
// server control - by stream
var serverAudioStreamControl = document.getElementById('serverAudioStream');
const streamQueryString = `region=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioStreamControl.src = `${serverSrc}?${streamQueryString}`;
console.log(serverAudioStreamControl.src)
serverAudioStreamControl.type = "audio/mpeg";
serverAudioStreamControl.disabled = false;
// client control
var clientAudioAzureControl = document.getElementById('clientAudioAzure');
clientAudioAzureControl.disabled = false;
}
function DisplayError(error) {
window.alert(JSON.stringify(error));
}
// Client-side request directly to Azure Cognitive Services
function getSpeechFromAzure() {
// authorization for Speech service
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(resourceKey, resourceRegion);
// new Speech object
synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig);
synthesizer.speakTextAsync(
phrase,
function (result) {
// Success function
// display status
if (result.reason === SpeechSDK.ResultReason.SynthesizingAudioCompleted) {
// load client-side audio control from Azure response
audioElement = document.getElementById("clientAudioAzure");
const blob = new Blob([result.audioData], { type: "audio/mpeg" });
const url = window.URL.createObjectURL(blob);
} else if (result.reason === SpeechSDK.ResultReason.Canceled) {
// display Error
throw (result.errorDetails);
}
// clean up
synthesizer.close();
synthesizer = undefined;
},
function (err) {
// Error function
throw (err);
audioElement = document.getElementById("audioControl");
audioElement.disabled = true;
// clean up
synthesizer.close();
synthesizer = undefined;
});
}
// Initialization
document.addEventListener("DOMContentLoaded", function () {
var clientAudioAzureControl = document.getElementById("clientAudioAzure");
var resultDiv = document.getElementById("resultDiv");
resourceKey = document.getElementById('resourceKey').value;
resourceRegion = document.getElementById('resourceRegion').value;
phrase = document.getElementById('phraseDiv').value;
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
clientAudioAzure.disabled = false;
document.getElementById('content').style.display = 'block';
}
});
</script>
</body>
</html>
Lignes en surbrillance dans le fichier :
- Ligne 74 : Le Kit de développement logiciel (SDK) Azure Speech est extrait dans la bibliothèque cliente, à l’aide du
cdn.jsdelivr.netsite pour fournir le package NPM. - Ligne 102 : La
updateSrcméthode met à jour l’URL dessrccontrôles audio avec la chaîne de requête, y compris la clé, la région et le texte. - Ligne 137 : Si un utilisateur sélectionne le
Get directly from Azurebouton, la page web appelle directement Azure à partir de la page cliente et traite le résultat.
Créer une ressource Azure AI Speech
Créez la ressource Speech avec des commandes Azure CLI dans Azure Cloud Shell.
Connectez-vous à Azure Cloud Shell. Pour cela, vous devez vous authentifier dans un navigateur avec votre compte disposant de l’autorisation sur un abonnement Azure valide.
Créez un groupe de ressources pour votre ressource Speech.
az group create \ --location eastus \ --name tutorial-resource-group-eastusCréez une ressource Speech dans le groupe de ressources.
az cognitiveservices account create \ --kind SpeechServices \ --location eastus \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --sku F0Cette commande échoue si votre seule ressource Speech gratuite a déjà été créée.
Utilisez la commande pour obtenir les valeurs de clé pour la nouvelle ressource Speech.
az cognitiveservices account keys list \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --output tableCopiez une des clés.
Vous utilisez la clé en la collant dans le formulaire web de l’application Express pour vous authentifier auprès du service Azure Speech.
Exécuter l’application Express.js pour convertir du texte en paroles
Démarrez l’application avec la commande bash suivante.
npm startOuvrez l’application web dans un navigateur.
http://localhost:3000Collez votre clé Speech dans la zone de texte en surbrillance.
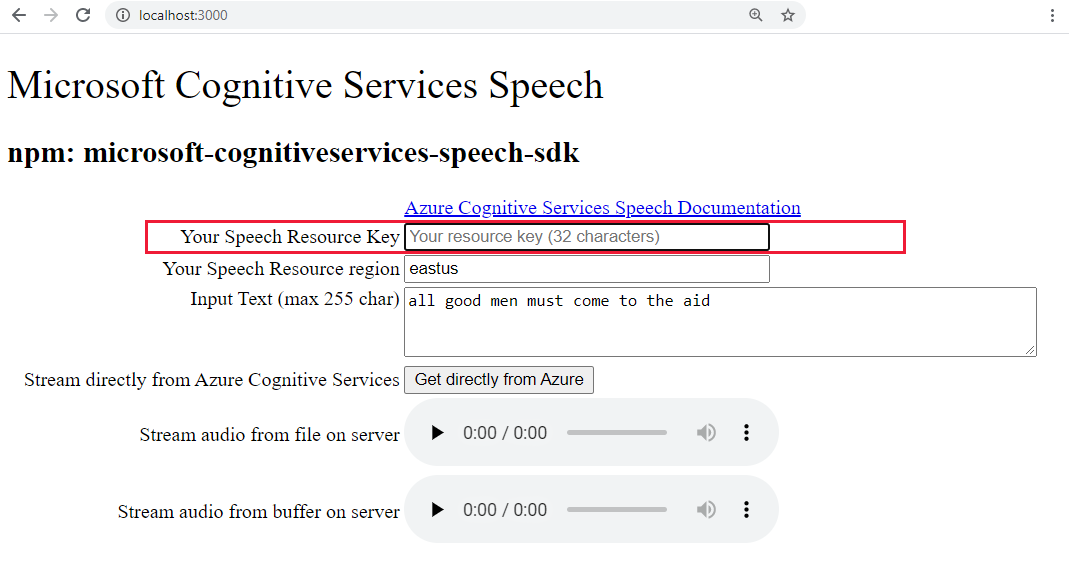
Si vous le souhaitez, remplacez le texte par un nouveau texte.
Sélectionnez un des trois boutons pour commencer la conversion au format audio :
- Recevoir directement d’Azure - appel côté client à Azure
- Contrôle audio pour le contenu audio à partir d’un fichier
- Contrôle audio pour le contenu audio à partir d’une mémoire tampon
Vous remarquerez peut-être un petit délai entre la sélection du contrôle et la lecture audio.
Créer un service Azure App dans Visual Studio Code
Dans la palette de commandes (Ctrl+Maj+P), tapez « créer le web » et sélectionnez Azure App Service : Créer une application web... Avancé. Vous utilisez la commande Avancé pour avoir un contrôle total sur le déploiement, y compris sur le groupe de ressources, le plan App Service et le système d’exploitation au lieu d’utiliser les valeurs par défaut de Linux.
Répondez aux invites de la façon suivante :
- Sélectionnez le compte de votre Abonnement.
- Entrez un nom globalement unique comme
my-text-to-speech-app.- Entrez un nom qui est unique dans tout Azure. Utilisez uniquement des caractères alphanumériques (« A-Z », « a-z » et « 0-9 ») et des traits d’union (« - »)
- Sélectionnez
tutorial-resource-group-eastuspour le groupe de ressources. - Sélectionnez une pile d’exécution d’une version qui inclut
NodeetLTS. - Sélectionnez le système d’exploitation Linux.
- Sélectionnez Créer un plan App Service et spécifiez un nom, comme
my-text-to-speech-app-plan. - Sélectionnez le niveau tarifaire gratuit F1. Si votre abonnement a déjà une application web gratuite, sélectionnez le niveau
Basic. - Pour la ressource Application Insights, sélectionnez Skip for now (Ignorer pour le moment).
- Sélectionnez la région
eastus.
Après un bref laps de temps, Visual Studio Code vous avertit que la création est terminée. Fermez la notification en utilisant le bouton X.
Déployer l’application Express.js locale sur App Service distant dans Visual Studio Code
Une fois l’application web en place, déployez votre code à partir de l’ordinateur local. Sélectionnez l’icône Azure pour ouvrir l’Explorateur Azure App Service, développez le nœud de votre abonnement, cliquez avec le bouton droit sur le nom de l’application web que vous venez de créer, puis sélectionnez Déployer sur l’application web.
S’il y a des invites pour le déploiement, sélectionnez le dossier racine de l’application Express.js, resélectionnez le compte de votre abonnement, puis sélectionnez le nom de l’application web
my-text-to-speech-appcréée précédemment.Si vous êtes invité à exécuter
npm installlors du déploiement sur Linux, sélectionnez Oui si vous êtes invité à mettre à jour votre configuration pour exécuternpm installsur le serveur cible.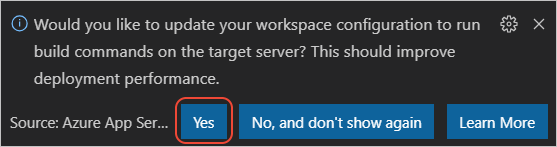
Une fois le déploiement terminé, sélectionnez Browse Website (Parcourir le site web) dans l’invite pour afficher l’application web que vous venez de déployer.
(Facultatif) : Vous pouvez apporter des modifications à vos fichiers de code, puis utiliser l’application déployer sur web, dans l’extension Azure App Service, pour mettre à jour l’application web.
Envoyer en streaming les journaux de service distants dans Visual Studio Code
Affichez les dernières lignes (« tail ») de toute sortie générée par l’application en cours d’exécution via des appels à console.log. Cette sortie s’affiche dans la fenêtre Sortie de Visual Studio Code.
Dans l’Explorateur Azure App Service, cliquez avec le bouton droit sur le nœud de votre nouvelle application, puis choisissez Démarrer le streaming des journaux.
Starting Live Log Stream ---
Actualisez la page web à plusieurs reprises dans le navigateur pour voir d’autres sorties de journal.
Supprimer les ressources en supprimant le groupe de ressources
Une fois que vous avez terminé ce tutoriel, vous devez supprimer le groupe de ressources qui comprend toutes ses ressources pour ne pas être facturé pour des utilisations supplémentaires.
Dans Azure Cloud Shell, utilisez la commande Azure CLI pour supprimer le groupe de ressources :
az group delete --name tutorial-resource-group-eastus -y
L’exécution de cette commande peut prendre quelques minutes.