Définir des variables
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2019
Les variables sont pratiques pour fournir les bits de données clés dans différentes parties du pipeline. L’utilisation la plus courante de variables consiste à définir une valeur que vous pouvez ensuite utiliser dans votre pipeline. Toutes les variables sont des chaînes et sont mutables. La valeur d’une variable peut passer d’une exécution à l’autre ou d’un travail à l’autre de votre pipeline.
Lorsque vous définissez la même variable à plusieurs emplacements avec le même nom, c’est la variable délimitée la plus localement qui l’emporte. Ainsi, une variable définie au niveau du travail peut remplacer une variable définie au niveau de l’index. Une variable définie au niveau de l’index remplace une variable définie au niveau racine du pipeline. Une variable définie au niveau racine du pipeline remplace une variable définie dans l’interface utilisateur des paramètres du pipeline. Pour en savoir plus sur l’utilisation des variables définies au niveau racine, au niveau de l'index et au niveau du travail, consultez Portée des variables.
Vous pouvez utiliser des variables avec des expressions pour attribuer des valeurs de manière conditionnelle et personnaliser davantage les pipelines.
Les variables sont différentes des paramètres d’exécution. Les paramètres d’exécution sont typés et disponibles pendant l’analyse des modèles.
Variables définies par l’utilisateur
Lorsque vous définissez une variable, vous pouvez utiliser différentes syntaxes (macro, expression de modèle ou runtime). La syntaxe que vous utilisez détermine l’emplacement dans le pipeline où votre variable s’affiche.
Dans les pipelines YAML, vous pouvez définir des variables au niveau de la racine, de l’index et du travail. Vous pouvez également spécifier des variables en dehors d’un pipeline YAML dans l’interface utilisateur. Lorsque vous définissez une variable dans l’interface utilisateur, cette variable peut être chiffrée et définie en tant que secret.
Les variables définies par l’utilisateur peuvent être définies en lecture seule. Il existe des restrictions de nommage pour les variables (par exemple, vous ne pouvez pas utiliser secret au début d’un nom de variable).
Vous pouvez utiliser un groupe de variables pour rendre les variables disponibles sur plusieurs pipelines.
Utilisez des modèles pour définir des variables dans un seul fichier afin de les utiliser dans plusieurs pipelines.
Variables multilignes définies par l’utilisateur
Azure DevOps prend en charge les variables multilignes, mais il existe quelques limitations.
Il est possible que les composants en aval, tels que les tâches de pipeline, ne gèrent pas correctement les valeurs de variable.
Azure DevOps ne modifie pas les valeurs de variable définies par l’utilisateur. Les valeurs de variable ont besoin d’être correctement formatées avant d’être passées en tant que variables multilignes. Pour formater votre variable, évitez les caractères spéciaux, n’utilisez pas de noms restreints et veillez à utiliser un format de fin de ligne qui fonctionne pour le système d’exploitation de votre agent.
Les variables multilignes se comportent différemment selon le système d’exploitation. Pour éviter cela, veillez à formater correctement les variables multilignes pour le système d’exploitation cible.
Azure DevOps ne modifie jamais les valeurs de variable, même si vous fournissez un formatage non pris en charge.
Variables système
En plus des variables définies par l’utilisateur, Azure Pipelines comporte des variables système avec des valeurs prédéfinies. Par exemple, la variable prédéfinie Build.BuildId donne l’ID de chaque build et peut être utilisée pour identifier différentes exécutions de pipeline. Vous pouvez utiliser la variable Build.BuildId dans des scripts ou des tâches lorsque vous avez besoin d’une valeur unique.
Si vous utilisez des pipelines de build YAML ou classiques, consultez les variables prédéfinies pour obtenir la liste complète des variables système.
Si vous utilisez des pipelines de mise en production classiques, consultez les variables de mise en production.
Les variables système sont définies avec leur valeur actuelle lorsque vous exécutez le pipeline. Certaines variables sont définies automatiquement. En tant qu’auteur ou utilisateur final du pipeline, vous modifiez la valeur d’une variable système avant l’exécution du pipeline.
Les variables système sont en lecture seule.
Variables d'environnement
Les variables d’environnement sont propres au système d’exploitation que vous utilisez. Elles sont injectées dans un pipeline d’une manière propre à la plateforme. Le format correspond à la façon dont les variables d’environnement sont formatées pour votre plateforme de script spécifique.
Sur les systèmes UNIX (macOS et Linux), les variables d’environnement ont le format $NAME. Sur Windows, le format est %NAME% pour Batch et $env:NAME dans PowerShell.
Les variables système et définies par l’utilisateur sont également injectées en tant que variables d’environnement pour votre plateforme. Lorsque les variables sont converties en variables d’environnement, leurs noms sont mis en majuscules et les points se transforment en traits de soulignement. Par exemple, le nom de variable any.variable devient $ANY_VARIABLE.
Il existe des restrictions de nommage pour les variables d’environnement (par exemple, vous ne pouvez pas utiliser secret au début d’un nom de variable).
Restrictions concernant le nommage des variables
Les variables définies par l’utilisateur et d’environnement peuvent se composer de lettres, de chiffres, de . et de caractères _. N’utilisez pas les préfixes de variable réservés par le système. Il s’agit de endpoint, input, secret, path et securefile. Toute variable commençant par l’une de ces chaînes (quelle que soit sa majusculisation) n’est pas disponible pour vos tâches et scripts.
Comprendre la syntaxe des variables
Azure Pipelines prend en charge trois façons différentes de référencer des variables : macro, expression de modèle et expression d’exécution. Vous pouvez utiliser chaque syntaxe dans un but différent et chacune d’elles présente certaines limitations.
Dans un pipeline, les variables d’expression de modèle (${{ variables.var }}) sont traitées au moment de la compilation, avant le démarrage du runtime. Les variables de syntaxe macro ($(var)) sont traitées pendant l’exécution avant l’exécution d’une tâche. Les expressions d’exécution ($[variables.var]) sont également traitées pendant l’exécution, mais sont destinées à être utilisées avec des conditions et des expressions. Lorsque vous utilisez une expression d’exécution, elle doit occuper tout le côté droit d’une définition.
Dans cet exemple, vous pouvez voir que l’expression de modèle a toujours la valeur initiale de la variable après la mise à jour de cette variable. La valeur de la variable de syntaxe macro est mise à jour. La valeur de l’expression de modèle ne change pas, car toutes les variables d’expression de modèle sont traitées au moment de la compilation avant l’exécution des tâches. En revanche, les variables de syntaxe macro sont évaluées avant l’exécution de chaque tâche.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Variables de syntaxe macro
La plupart des exemples de la documentation utilisent la syntaxe macro ($(var)). La syntaxe macro est conçue pour interpoler des valeurs de variable dans des entrées de tâche et dans d’autres variables.
Les variables avec la syntaxe macro sont traitées avant qu’une tâche ne s’exécute pendant l’exécution. L’exécution se produit après l’expansion du modèle. Lorsque le système rencontre une expression macro, il la remplace par le contenu de la variable. S’il n’existe aucune variable de ce nom, l’expression macro ne change pas. Par exemple, si $(var) ne peut pas être remplacé, $(var) ne sera pas remplacé du tout.
Les variables avec la syntaxe macro restent inchangées sans aucune valeur, car une valeur vide comme $() peut signifier quelque chose pour la tâche que vous exécutez et l’agent ne doit pas partir du principe que vous voulez que cette valeur soit remplacée. Par exemple, si vous utilisez $(foo) pour référencer une variable foo dans une tâche Bash, le remplacement de toutes les expressions $() dans l’entrée de la tâche peut interrompre vos scripts Bash.
Les variables macro sont développées uniquement lorsqu’elles sont utilisées pour une valeur, et non en tant que mot clé. Les valeurs s’affichent sur le côté droit d’une définition de pipeline. Ce qui suit est valide : key: $(value). Ce qui suit n’est pas valide : $(key): value. Les variables macro ne sont pas développées lorsqu’elles sont utilisées pour afficher un nom de travail inlined. Vous devez plutôt utiliser la propriété displayName.
Notes
Les variables avec la syntaxe macro sont développées uniquement pour stages, jobs et steps.
Vous ne pouvez pas, par exemple, utiliser une syntaxe macro à l’intérieur d’une resource ou d’un trigger.
Cet exemple utilise une syntaxe macro avec Bash, PowerShell et une tâche de script. La syntaxe utilisée pour appeler une variable avec la syntaxe macro est la même pour les trois.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Syntaxe d’expression de modèle
Vous pouvez utiliser la syntaxe d’expression de modèle pour développer à la fois les paramètres de modèle et les variables (${{ variables.var }}). Les variables de modèle sont traitées au moment de la compilation et remplacées avant le démarrage du runtime. Les expressions de modèle sont conçues pour réutiliser des parties du fichier YAML en tant que modèles.
Les variables de modèle fusionnent de manière silencieuse dans des chaînes vides quand une valeur de remplacement est introuvable. Contrairement aux macros et aux expressions d’exécution, les expressions de modèle peuvent apparaître sous forme de clés (côté gauche) ou de valeurs (côté droit). Ce qui suit est valide : ${{ variables.key }} : ${{ variables.value }}.
Syntaxe des expressions d’exécution
Vous pouvez utiliser la syntaxe des expressions d’exécution pour les variables développées au moment de l’exécution ($[variables.var]). Les variables d’expression d’exécution fusionnent de manière silencieuse dans des chaînes vides quand une valeur de remplacement est introuvable. Utilisez des expressions d’exécution dans des conditions de travail pour prendre en charge l’exécution conditionnelle de travaux ou d’index entiers.
Les variables d’expression d’exécution sont développées uniquement lorsqu’elles sont utilisées pour une valeur, et non en tant que mot clé. Les valeurs s’affichent sur le côté droit d’une définition de pipeline. Ce qui suit est valide : key: $[variables.value]. Ce qui suit n’est pas valide : $[variables.key]: value. L’expression d’exécution doit prendre l’intégralité du côté droit d’une paire clé-valeur. Par exemple, key: $[variables.value] est valide, mais key: $[variables.value] foo ne l’est pas.
| Syntaxe | Exemple | À quel moment son traitement a-t-il lieu ? | Où se développe-t-elle dans une définition de pipeline ? | Comment s’affiche-t-elle lorsqu’elle est introuvable ? |
|---|---|---|---|---|
| macro | $(var) |
au moment de l’exécution avant l’exécution d’une tâche | valeur (côté droit) | imprime $(var) |
| expression de modèle | ${{ variables.var }} |
temps de compilation | clé ou valeur (côté gauche ou droit) | chaîne vide |
| expression d’exécution | $[variables.var] |
runtime | valeur (côté droit) | chaîne vide |
Quelle syntaxe dois-je utiliser ?
Utilisez la syntaxe macro si vous fournissez une entrée pour une tâche.
Choisissez une expression d’exécution si vous utilisez des conditions et des expressions. Toutefois, n’utilisez pas d’expression d’exécution si vous ne souhaitez pas que votre variable vide soit imprimée (par exemple : $[variables.var]). Par exemple, si vous avez une logique conditionnelle qui s’appuie sur une variable ayant une valeur spécifique ou sans aucune valeur. Dans ce cas, vous devez utiliser une expression macro.
Si vous définissez une variable dans un modèle, utilisez une expression de modèle.
Définir des variables dans un pipeline
Dans le cas le plus courant, vous définissez les variables et vous les utilisez dans le fichier YAML. Cela vous permet d’effectuer un suivi des modifications apportées à la variable dans votre système de gestion de versions. Vous pouvez également définir des variables dans l’interface utilisateur des paramètres de pipeline (consultez l’onglet Classique) et les référencer dans votre fichier YAML.
Voici un exemple qui montre comment définir deux variables, configuration et platform, pour les utiliser plus tard dans les étapes. Pour utiliser une variable dans une instruction YAML, wrappez-la dans $(). Les variables ne peuvent pas être utilisées pour définir un repository dans une instruction YAML.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Étendues des variables
Dans le fichier YAML, vous pouvez définir une variable dans différentes étendues :
- Au niveau racine, pour la rendre disponible pour tous les travaux inclus dans le pipeline.
- Au niveau de l’index, pour la rendre disponible uniquement pour un index spécifique.
- Au niveau du travail, pour la rendre disponible uniquement pour un travail spécifique.
Lorsque vous définissez une variable au tout début d’un fichier YAML, elle est disponible pour tous les travaux et index du pipeline et il s’agit d’une variable globale. Les variables globales définies dans un fichier YAML ne sont pas visibles dans l’interface utilisateur des paramètres du pipeline.
Les variables au niveau du travail remplacent les variables au niveau racine et au niveau de l’index. Les variables au niveau de l’index remplacent les variables au niveau racine.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
La sortie des deux travaux ressemble à celle-ci :
# job1
value
value1
value1
# job2
value
value2
value
Spécifier des variables
Dans les exemples précédents, le mot clé variables est suivi d’une liste de paires clé-valeur.
Les clés sont les noms des variables et les valeurs correspondent à leurs valeurs.
Il existe une autre syntaxe, utile lorsque vous voulez utiliser des modèles de variables ou des groupes de variables.
Grâce aux modèles, les variables peuvent être définies dans un YAML et incluses dans un autre fichier YAML.
Les groupes de variables sont un ensemble de variables que vous pouvez utiliser dans plusieurs pipelines. Ils vous permettent de gérer et d’organiser des variables communes à différentes phases dans un seul emplacement.
Utilisez cette syntaxe pour les modèles de variables et les groupes de variables au niveau racine d'un pipeline.
Dans cette syntaxe alternative, le mot clé variables accepte une liste de spécificateurs de variable.
Les spécificateurs de variable sont name pour une variable régulière, group pour un groupe de variables et template pour inclure un modèle de variable.
L’exemple suivant illustre ces trois spécificateurs.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Découvrez-en plus sur la réutilisation des variables avec des modèles.
Accéder à des variables par le biais de l’environnement
Notez que les variables sont également mises à la disposition des scripts par le biais de variables d’environnement. La syntaxe qui permet d’utiliser ces variables d’environnement dépend du langage de script.
Le nom est en majuscules et . est remplacé par _. Le script est automatiquement inséré dans l’environnement du processus. Voici quelques exemples :
- Script de commandes par lot :
%VARIABLE_NAME% - Script PowerShell :
$env:VARIABLE_NAME - Script Bash :
$VARIABLE_NAME
Important
Les variables prédéfinies qui contiennent des chemins de fichier sont traduites dans le style approprié (style Windows C:\foo\ ou style Unix /foo/) en fonction du type d’hôte de l’agent et du type d’interpréteur de commandes. Si vous exécutez des tâches de script bash sur Windows, vous devez utiliser la méthode de variable d’environnement qui permet d’accéder à ces variables plutôt que la méthode de variable du pipeline pour vous assurer de disposer du style de chemin de fichier correct.
Définir des variables de secret
Conseil
Les variables secrètes ne sont pas automatiquement exportées en tant que variables d’environnement. Pour utiliser des variables secrètes dans vos scripts, mappez-les explicitement aux variables d’environnement. Pour plus d’informations, veuillez consulter la section Définir des variables secrètes.
Ne définissez pas de variables secrètes dans votre fichier YAML. Les systèmes d’exploitation journalisent souvent les commandes des processus qu’ils exécutent, et vous n’avez pas intérêt à ce que le journal inclue un secret que vous avez passé en tant qu’entrée. Utilisez l’environnement du script ou mappez la variable dans le bloc variables pour passer des secrets à votre pipeline.
Remarque
Azure Pipelines fait un effort pour masquer des secrets lors de l’émission de données dans des journaux de pipeline. Vous pouvez donc voir des variables supplémentaires et des données masquées dans des sorties et des journaux qui ne sont pas définis en tant que secrets.
Vous avez besoin de définir des variables secrètes dans l’interface utilisateur des paramètres de votre pipeline. Ces variables sont délimitées au pipeline dans lequel elles sont définies. Vous pouvez également définir des variables secrètes dans des groupes de variables.
Pour définir des secrets dans l’interface web, effectuez ces étapes :
- Accédez à la page Pipelines, sélectionnez le pipeline approprié, puis sélectionnez Modifier.
- Recherchez les variables définies pour ce pipeline.
- Ajoutez ou mettez à jour la variable.
- Sélectionnez l’option permettant de conserver ce secret de valeur pour stocker la variable de manière chiffrée.
- Enregistrez le pipeline.
Les variables secrètes sont chiffrées au repos avec une clé RSA de 2 048 bits. Les secrets sont disponibles sur l’agent pour être utilisés par les tâches et les scripts. Faites attention aux personnes autorisées à modifier votre pipeline.
Important
Nous nous efforçons de masquer l’affichage des secrets dans la sortie d’Azure Pipelines, mais vous devez tout de même prendre des précautions. N’émettez jamais de secrets comme sortie. Certains systèmes d’exploitation journalisent les arguments de ligne de commande. Ne passez jamais de secrets en ligne de commande. Au lieu de cela, nous vous suggérons de mapper vos secrets dans des variables d’environnement.
Nous ne masquons jamais les sous-chaînes de secrets. Si, par exemple, « abc123 » est défini en tant que secret, « abc » n’est pas masqué dans les journaux. Cela permet d’éviter de masquer les secrets à un niveau trop granulaire, ce qui rendrait les journaux illisibles. Pour cette raison, les secrets ne doivent pas contenir de données structurées. Si, par exemple, « { "foo" : "bar" } » est défini comme secret, « bar » n’est pas masqué dans les journaux.
Contrairement à une variable normale, elles ne sont pas automatiquement déchiffrées en variables d’environnement pour les scripts. Vous devez mapper explicitement les variables secrètes.
L’exemple suivant montre comment mapper et utiliser une variable secrète appelée mySecret dans des scripts PowerShell et Bash. Deux variables globales sont définies. GLOBAL_MYSECRET se voit attribuer la valeur d'une variable secrète mySecret, et GLOBAL_MY_MAPPED_ENV_VAR se voit attribuer la valeur d'une variable non secrète nonSecretVariable. Contrairement à une variable de pipeline normale, il n’existe aucune variable d’environnement appelée MYSECRET.
La tâche PowerShell exécute un script pour imprimer les variables.
$(mySecret): il s’agit d’une référence directe à la variable secrète, et cette méthode fonctionne.$env:MYSECRET: cette fonction tente d’accéder à la variable secrète en tant que variable d’environnement, ce qui ne fonctionne pas, car les variables secrètes ne sont pas automatiquement mappées aux variables d’environnement.$env:GLOBAL_MYSECRET: cette fonction tente d’accéder à la variable secrète via une variable globale, ce qui ne fonctionne pas non plus, car les variables secrètes ne peuvent pas être mappées de cette façon.$env:GLOBAL_MY_MAPPED_ENV_VAR: cette fonction accède à la variable non secrète via une variable globale, ce qui fonctionne.$env:MY_MAPPED_ENV_VAR: cette fonction accède à la variable secrète via une variable d’environnement spécifique à une tâche, ce qui est la méthode recommandée pour mapper les variables secrètes aux variables d’environnement.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
La sortie des deux tâches dans le script précédent ressemblerait à ceci :
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
Vous pouvez également utiliser des variables secrètes en dehors des scripts. Par exemple, vous pouvez mapper des variables secrètes à des tâches à l’aide de la définition variables. Cet exemple montre comment utiliser des variables secrètes $(vmsUser) et $(vmsAdminPass) dans une tâche de copie de fichiers Azure.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@4
inputs:
SourcePath: 'my/path'
azureSubscription: 'my-subscription'
Destination: 'AzureVMs'
storage: 'my-storage'
resourceGroup: 'my-rg'
vmsAdminUserName: $(VMS_USER)
vmsAdminPassword: $(VMS_PASS)
Référencer des variables secrètes dans des groupes de variables
Cet exemple montre comment référencer un groupe de variables dans votre fichier YAML et ajouter des variables dans le fichier YAML. Deux variables sont utilisées à partir du groupe de variables : user et token. La variable token est secrète, elle est mappée à la variable d’environnement $env:MY_MAPPED_TOKEN afin de pouvoir être référencée dans le fichier YAML.
Ce fichier YAML effectue un appel REST pour récupérer une liste de versions, puis il génère le résultat.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Important
Par défaut, avec les dépôts GitHub, les variables secrètes associées à votre pipeline ne sont pas disponibles pour les builds de demande de tirage (pull request) des duplications (forks). Pour plus d’informations, consultez Contributions des duplications.
Partager des variables entre des pipelines
Pour partager des variables entre plusieurs pipelines dans votre projet, utilisez l’interface web. Sous Bibliothèque, utilisez des groupes de variables.
Utiliser des variables de sortie provenant de tâches
Certaines tâches définissent des variables de sortie, que vous pouvez consommer dans les étapes, les travaux et les index en aval. Dans le fichier YAML, vous pouvez accéder aux variables entre les travaux et les index à l’aide de dépendances.
Lorsque vous référencez des travaux de matrice dans des tâches en aval, vous devez utiliser une syntaxe différente. Consultez Définir une variable de sortie multi-travaux. Vous devez également utiliser une syntaxe différente pour les variables dans les travaux de déploiement. Consultez Prise en charge des variables de sortie dans les travaux de déploiement.
Certaines tâches définissent des variables de sortie, que vous pouvez consommer dans les étapes et les travaux en aval au sein du même index. Dans le fichier YAML, vous pouvez accéder aux variables entre les travaux à l’aide de dépendances.
- Pour référencer une variable d’une autre tâche au sein du même travail, utilisez
TASK.VARIABLE. - Pour référencer une variable d’une tâche d’un autre travail, utilisez
dependencies.JOB.outputs['TASK.VARIABLE'].
Notes
Par défaut, chaque index d’un pipeline dépend de celui qui se trouve juste avant lui dans le fichier YAML. Si vous avez besoin de faire référence à un index qui ne précède pas immédiatement l’index actuel, vous pouvez remplacer cette valeur par défaut automatique en ajoutant une section dependsOn à l’index.
Notes
Les exemples suivants utilisent une syntaxe de pipeline standard. Si vous utilisez des pipelines de déploiement, la syntaxe d’une variable et celle d’une variable conditionnelle diffèrent. Pour plus d’informations sur la syntaxe spécifique à utiliser, consultez Travaux de déploiement.
Pour ces exemples, supposons que nous avons une tâche appelée MyTask, qui définit une variable de sortie appelée MyVar.
Découvrez-en plus sur la syntaxe dans Expressions – Dépendances.
Utiliser des sorties dans le même travail
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Utiliser des sorties dans un autre travail
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Utiliser des sorties dans une autre phase
Pour utiliser la production à partir d’un index différent, le format de référencement des variables est stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE']. Au niveau de l’index, mais pas au niveau du travail, vous pouvez utiliser ces variables dans des conditions.
Les variables de sortie sont disponibles uniquement dans l’index en aval suivant. Si plusieurs index consomment la même variable de sortie, utilisez la condition dependsOn.
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Vous pouvez également passer des variables entre des index avec une entrée de fichier. Pour cela, vous avez besoin de définir des variables dans le deuxième index au niveau du travail, puis de passer les variables en tant qu’entrées env:.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
La sortie des index dans le pipeline précédent ressemble à ceci :
Hello inline version
true
crushed tomatoes
Lister les variables
Vous pouvez lister toutes les variables incluses dans votre pipeline à l’aide de la commande az pipelines variable list. Pour commencer, consultez Bien démarrer avec l’interface CLI Azure DevOps.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Paramètres
- org : URL de l’organisation Azure DevOps. Vous pouvez configurer l’organisation par défaut à l’aide de
az devops configure -d organization=ORG_URL. Obligatoire en l’absence d’une configuration par défaut ou d’une récupération à l’aide degit config. Exemple :--org https://dev.azure.com/MyOrganizationName/. - pipeline-id : Obligatoire si le paramètre pipeline-name n’est pas fourni. ID du pipeline.
- pipeline-name : Obligatoire si pipeline-id n’est pas fourni, mais ignoré si pipeline-id est fourni. Nom du pipeline.
- project : Nom ou ID du projet. Vous pouvez configurer le projet par défaut en utilisant
az devops configure -d project=NAME_OR_ID. Obligatoire en l’absence d’une configuration par défaut ou d’une récupération à l’aide degit config.
Exemple
La commande suivante liste toutes les variables du pipeline portant l’ID 12 et affiche le résultat sous forme de tableau.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Définir des variables dans des scripts
Les scripts peuvent définir des variables qui sont consommées ultérieurement dans les étapes suivantes du pipeline. Toutes les variables définies par cette méthode sont traitées comme des chaînes. Pour définir une variable à partir d’un script, vous utilisez une syntaxe de commande et imprimez sur stdout.
Définir une variable délimitée à un travail à partir d’un script
Pour définir une variable à partir d’un script, vous utilisez la task.setvariablecommande de journalisation. Celle-ci met à jour les variables d’environnement pour les travaux suivants. Les travaux suivants ont accès à la nouvelle variable avec la syntaxe macro et dans les tâches en tant que variables d’environnement.
Lorsque issecret a la valeur true, la valeur de la variable est enregistrée sous forme de secret et masquée dans le journal. Pour plus d’informations sur les variables secrètes, consultez les commandes de journalisation.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
La variable de pipeline est également ajoutée à l’environnement des étapes suivantes. Vous ne pouvez pas utiliser la variable dans l’étape dans laquelle elle est définie.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
Sortie du pipeline précédent.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Définir une variable de sortie multi-travaux
Si vous souhaitez rendre une variable disponible pour les travaux futurs, vous devez la marquer comme variable de sortie à l’aide de isOutput=true. Ensuite, vous pouvez la mapper dans des travaux futurs en utilisant la syntaxe $[] et en incluant le nom d’étape qui définit la variable. Les variables de sortie multi-travaux fonctionnent uniquement pour les travaux inclus dans le même index.
Pour passer des variables à des travaux dans différents index, utilisez la syntaxe des dépendances d’index.
Notes
Par défaut, chaque index d’un pipeline dépend de celui qui se trouve juste avant lui dans le fichier YAML. Par conséquent, chaque index peut utiliser des variables de sortie issues de l’index précédent. Pour accéder à d’autres index, vous avez besoin de modifier le graphe des dépendances. Par exemple, si l’index 3 nécessite une variable de l’index 1, vous avez besoin de déclarer une dépendance explicite vis-à-vis de l’étape 1.
Lorsque vous créez une variable de sortie multi-travaux, vous devez affecter l’expression à une variable. Dans ce fichier YAML, $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] est affecté à la variable $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
Sortie du pipeline précédent.
this is the value
this is the value
Si vous définissez une variable d’un index à l’autre, utilisez stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
Si vous définissez une variable à partir d’une matrice ou d’une tranche, alors pour référencer cette variable lorsque vous y accédez à partir d’un travail en aval, vous devez inclure :
- Nom du travail.
- L’étape.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA1)"
name: echovar
Veillez à préfixer le nom du travail d’après les variables de sortie d’un travail de déploiement. Dans ce cas, le nom du travail est A :
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 Définir les variables
Définir les variables  Définir les variables
Définir les variables  Définir les variables
Définir les variables Définir des variables à l’aide d’expressions
Vous pouvez définir une variable à l’aide d’une expression. Nous avons déjà rencontré un cas de ce genre pour définir une variable sur la sortie d’un autre travail précédent.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
Vous pouvez utiliser toute expression prise en charge pour définir une variable. Voici un autre exemple de définition d’une variable pour jouer un rôle de compteur qui commence à 100, qui est incrémenté de 1 à chaque exécution et qui est réinitialisé à 100 tous les jours.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
Pour plus d’informations sur les compteurs, les dépendances et d’autres expressions, consultez les expressions.
Configurer des variables définissables pour les étapes
Vous pouvez définir settableVariables au sein d’une étape ou spécifier qu’aucune variable ne peut être définie.
Dans cet exemple, le script ne peut pas définir une variable.
steps:
- script: echo This is a step
target:
settableVariables: none
Dans cet exemple, le script autorise la variable sauce, mais pas la variable secretSauce. Un avertissement s’affiche dans la page d’exécution de pipeline.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Autoriser au moment de la mise en file d’attente
Si une variable apparaît dans le bloc variables d’un fichier YAML, sa valeur est fixe et ne peut pas être remplacée au moment de la mise en file d’attente. Une bonne pratique consiste à définir vos variables dans un fichier YAML, mais il arrive que cela ne soit pas judicieux. Par exemple, vous pouvez vouloir définir une variable de secret et ne pas souhaiter qu’elle soit exposée dans votre fichier YAML. Ou vous pouvez avoir besoin de définir manuellement une valeur de variable pendant l’exécution du pipeline.
Vous avez deux options pour définir des valeurs de temps d’attente. Vous pouvez définir une variable dans l’interface utilisateur et sélectionner l’option Permettre aux utilisateurs de remplacer cette valeur durant l’exécution du pipeline ou plutôt utiliser des paramètres de runtime. Si votre variable n’est pas secrète, une bonne pratique consiste à utiliser des paramètres de runtime.
Pour définir une variable au moment de la mise en file d’attente, ajoutez une nouvelle variable au sein de votre pipeline et sélectionnez l’option Remplacer.
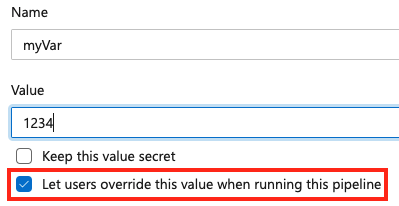
Pour autoriser la définition d’une variable au moment de la mise en file d’attente, vérifiez qu’elle n’apparaît pas également dans le bloc variables d’un pipeline ou d’un travail. Si vous définissez une variable à la fois dans le bloc variables d’un fichier YAML et dans l’interface utilisateur, la valeur du fichier YAML est prioritaire.

Développement de variables
Lorsque vous définissez une variable portant le même nom dans plusieurs étendues, la priorité suivante s’applique (la plus haute priorité en premier).
- Variable de niveau travail définie dans le fichier YAML
- Variable de niveau phase définie dans le fichier YAML
- Variable de niveau pipeline définie dans le fichier YAML
- Variable définie au moment de la mise en file d’attente
- Variable de pipeline définie dans l’interface utilisateur des paramètres de pipeline
Dans l’exemple suivant, la même variable a est définie au niveau du pipeline et au niveau du travail dans le fichier YAML. Elle est également définie dans un groupe de variables G et en tant que variable dans l’interface utilisateur Paramètres du pipeline.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
Lorsque vous définissez une variable portant le même nom dans la même étendue, la dernière valeur définie est prioritaire.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Remarque
Lorsque vous définissez une variable dans le fichier YAML, ne la définissez pas dans l’éditeur web comme définissable au moment de la mise en file d’attente. Actuellement, vous ne pouvez pas modifier les variables définies dans le fichier YAML au moment de la mise en file d’attente. Si vous avez besoin qu’une variable soit définissable au moment de la mise en file d’attente, ne la définissez pas dans le fichier YAML.
Les variables sont développées une fois au démarrage de l’exécution, puis une autre fois au début de chaque étape. Par exemple :
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
L’exemple précédent comporte deux étapes. L’expansion de $(a) se produit une fois au début du travail et une fois au début de chacune des deux étapes.
Étant donné que les variables sont développées au début d’un travail, vous ne pouvez pas les utiliser dans une stratégie. Dans l’exemple suivant, vous ne pouvez pas utiliser la variable a pour développer la matrice du travail, car la variable est uniquement disponible au début de chaque travail développé.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
Si la variable a est une variable de sortie d’un travail précédent, alors vous pouvez l’utiliser dans un travail futur.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Expansion récursive
Sur l’agent, les variables référencées à l’aide de la syntaxe $( ) sont développées de manière récursive.
Par exemple :
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"