Bases de données, topologies de déploiement et sauvegarde
Azure DevOps Server 2022 | Azure DevOps Server 2020 | Azure DevOps Server 2019
Vous pouvez protéger votre déploiement contre la perte de données en créant une planification régulière des sauvegardes pour les bases de données dont dépend Azure DevOps Server. Pour restaurer complètement votre déploiement Azure DevOps Server, sauvegardez d’abord toutes les bases de données Azure DevOps Server.
Si votre déploiement inclut SQL Server Reporting Services, vous devez également sauvegarder les bases de données qu’Azure DevOps utilise dans ces composants. Pour éviter les erreurs de synchronisation ou les erreurs d’incompatibilité des données, vous devez synchroniser toutes les sauvegardes avec le même horodatage. Le moyen le plus simple de garantir la réussite de la synchronisation consiste à utiliser des transactions marquées. En marquant régulièrement les transactions associées dans chaque base de données, vous établissez une série de points de récupération courants dans les bases de données. Pour obtenir des instructions détaillées sur la sauvegarde d’un déploiement à serveur unique qui utilise la création de rapports, consultez Créer une planification et un plan de sauvegarde.
Sauvegarde de bases de données
Protégez votre déploiement Azure DevOps contre la perte de données en créant des sauvegardes de base de données. Le tableau suivant et les illustrations associées montrent les bases de données à sauvegarder et fournissent des exemples de la façon dont ces bases de données peuvent être distribuées physiquement dans un déploiement.
| Type de base de données | Produit | Composant requis ? |
|---|---|---|
| Base de données de configuration | Azure DevOps Server | Oui |
| Base de données de l’entrepôt | Azure DevOps Server | Oui |
| Bases de données de collection de projets | Azure DevOps Server | Oui |
| Bases de données de création de rapports | SQL Server Reporting Services | Non |
| Bases de données d’analyse | SQL Server Analysis Services | Non |
Topologies de déploiement
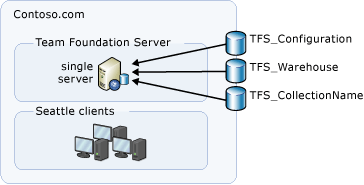
En fonction de votre configuration de déploiement, toutes les bases de données qui nécessitent une sauvegarde peuvent se trouver sur le même serveur physique, comme dans cet exemple de topologie.
Remarque
Cet exemple n’inclut pas les produits Reporting Services ou SharePoint. Vous n’avez donc pas besoin de sauvegarder les bases de données associées à la création de rapports, à l’analyse ou aux produits SharePoint.
En guise d’alternative, les bases de données peuvent être distribuées sur de nombreux serveurs et batteries de serveurs. Dans cet exemple de topologie, vous devez sauvegarder les bases de données suivantes, qui sont mises à l’échelle sur six serveurs ou batteries de serveurs :
base de données de configuration
base de données de l’entrepôt
bases de données de collection de projets situées sur le cluster SQL Server
base de données de collecte située sur le serveur autonome exécutant SQL Server
bases de données situées sur le serveur exécutant Reporting Services
base de données située sur le serveur exécutant Analysis Services
les bases de données administratives des produits SharePoint et les bases de données de collection de sites pour les deux applications web SharePoint
Si vos bases de données SharePoint sont mises à l’échelle sur plusieurs serveurs, vous ne pouvez pas utiliser la fonctionnalité Sauvegardes planifiées pour les sauvegarder. Vous devez configurer manuellement des sauvegardes pour ces bases de données et vous assurer que ces sauvegardes sont synchronisées avec les sauvegardes de base de données Azure DevOps Server. Pour plus d’informations, consultez Sauvegarder manuellement Azure DevOps Server.
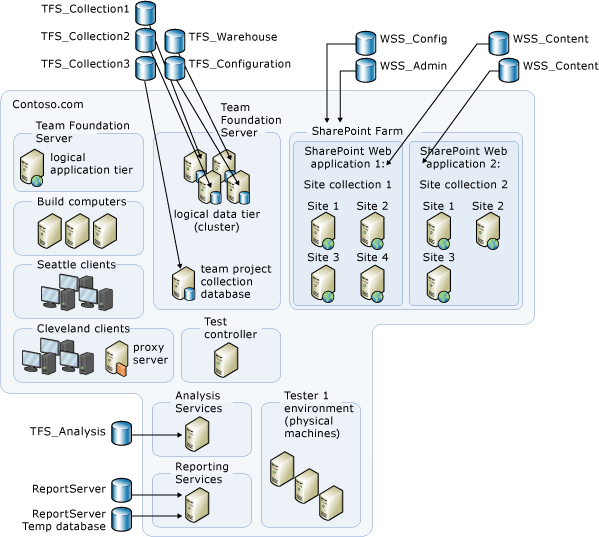
Dans ces deux exemples, vous n’avez pas besoin de sauvegarder les clients qui se connectent au serveur. Toutefois, vous devrez peut-être effacer manuellement les caches d’Azure DevOps Server sur les ordinateurs clients avant de pouvoir se reconnecter au déploiement restauré.
Bases de données à sauvegarder
La liste suivante fournit des détails supplémentaires sur ce que vous devez sauvegarder, en fonction de vos ressources de déploiement.
Important
Toutes les bases de données de la liste suivante sont des bases de données SQL Server. Bien que vous puissiez utiliser SQL Server Management Studio pour sauvegarder des bases de données individuelles à tout moment, vous devez éviter d’utiliser ces sauvegardes individuelles lorsque cela est possible. Vous pouvez rencontrer des résultats inattendus si vous effectuez une restauration à partir de sauvegardes individuelles, car les bases de données qu’Azure DevOps utilise sont toutes associées. Si vous sauvegardez une seule base de données, les données de cette base de données peuvent ne pas être synchronisées avec les données des autres bases de données.
- Bases de données pour Azure DevOps Server : le niveau de données logique pour Azure DevOps Server inclut plusieurs bases de données SQL Server, notamment la base de données de configuration, la base de données de l’entrepôt et une base de données pour chaque collection de projets dans le déploiement. Ces bases de données peuvent toutes se trouver sur le même serveur, réparties sur plusieurs instances du même déploiement SQL Server ou distribuées sur plusieurs serveurs. Quelle que soit leur distribution physique, vous devez sauvegarder toutes les bases de données dans le même horodatage pour vous assurer de la perte de données. Vous pouvez effectuer des sauvegardes de base de données manuellement ou automatiquement à l’aide de plans de maintenance qui s’exécutent à des moments ou intervalles spécifiques.
Important
La liste des bases de données Azure DevOps n’est pas statique. Une nouvelle base de données est créée chaque fois que vous créez une collection. Lorsque vous créez un regroupement, veillez à ajouter la base de données de ce regroupement à votre plan de maintenance.
- Bases de données pour Reporting Services et Analysis Services : si votre déploiement utilise SQL Server Reporting Services ou SQL Server Analysis Services pour générer des rapports pour Azure DevOps Server, vous devez sauvegarder les bases de données de création de rapports et d’analyse. Toutefois, vous devez toujours régénérer certaines bases de données après la restauration, telles que l’entrepôt.
- Clé de chiffrement pour le serveur de rapports : le serveur de rapports a une clé de chiffrement que vous devez sauvegarder. Cette clé protège les informations sensibles stockées dans la base de données du serveur de rapports. Vous pouvez sauvegarder manuellement cette clé à l’aide de l’outil de configuration de Reporting Services ou d’un outil en ligne de commande.
Préparation avancée des sauvegardes
Lorsque vous déployez Azure DevOps, vous devez conserver un enregistrement des comptes que vous créez et tous les noms d’ordinateurs, mots de passe et options de configuration que vous spécifiez. Vous devez également conserver une copie de tous les documents de récupération, documents et sauvegardes de base de données et de journaux des transactions à un emplacement sécurisé. Pour vous protéger contre un sinistre, tel qu’un incendie ou un tremblement de terre, vous devez conserver les doublons de vos sauvegardes de serveur dans un emplacement différent de l’emplacement des serveurs. Cette stratégie vous aidera à vous protéger contre la perte de données critiques. En guise de bonne pratique, vous devez conserver trois copies du support de sauvegarde et conserver au moins une copie hors site dans un environnement contrôlé.
Important
Effectuez régulièrement une restauration des données d’essai pour vérifier que vos fichiers sont correctement sauvegardés. Une restauration d’évaluation peut révéler des problèmes matériels qui n’apparaissent pas avec une vérification logicielle uniquement.
Lorsque vous sauvegardez et restaurez une base de données, vous devez sauvegarder les données sur un support avec une adresse réseau (par exemple, des bandes et des disques qui ont été partagés en tant que lecteurs réseau). Votre plan de sauvegarde doit inclure des dispositions pour la gestion des supports, telles que les tactiques suivantes :
- Plan de suivi et de gestion pour le stockage et le recyclage des jeux de sauvegarde.
- Planification du remplacement du support de sauvegarde.
- Dans un environnement multi-serveur, une décision d’utiliser des sauvegardes centralisées ou distribuées.
- Un moyen de suivre la vie utile des médias.
- Procédure pour réduire les effets de la perte d’un jeu de sauvegarde ou d’un support de sauvegarde (par exemple, une bande).
- Décision de stocker des jeux de sauvegarde sur site ou hors site et une analyse de la façon dont cette décision peut affecter le temps de récupération.
Étant donné que les données Azure DevOps sont stockées dans des bases de données SQL Server, vous n’avez pas besoin de sauvegarder les ordinateurs sur lesquels les clients d’Azure DevOps sont installés. Si une défaillance ou un incident multimédia impliquant ces ordinateurs se produisaient, vous pouvez réinstaller le logiciel client et vous reconnecter au serveur. En réinstallant le logiciel client, vos utilisateurs auront une alternative plus propre et plus fiable pour restaurer un ordinateur client à partir d’une sauvegarde.
Vous pouvez sauvegarder un serveur à l’aide des fonctionnalités de sauvegardes planifiées disponibles ou en créant manuellement des plans de maintenance dans SQL Server pour sauvegarder les bases de données liées à votre déploiement Azure DevOps. Les bases de données Azure DevOps fonctionnent en relation avec les autres, et si vous créez un plan manuel, vous devez les sauvegarder et les restaurer en même temps. Pour plus d’informations sur les stratégies de sauvegarde de bases de données, consultez Sauvegarde et restauration des bases de données SQL Server.
Types de sauvegardes
Comprendre les types de sauvegardes disponibles vous aide à déterminer les meilleures options pour sauvegarder votre déploiement. Par exemple, si vous travaillez avec un déploiement volumineux et que vous souhaitez vous protéger contre la perte de données tout en utilisant efficacement des ressources de stockage limitées, vous pouvez configurer des sauvegardes différentielles ainsi que des sauvegardes de données complètes. Si vous utilisez SQL Server Always On, vous pouvez effectuer des sauvegardes de votre base de données secondaire. Vous pouvez également essayer d’utiliser la compression de sauvegarde ou le fractionnement des sauvegardes sur plusieurs fichiers. Voici de brèves descriptions des options de sauvegarde :
Sauvegardes complètes de données (bases de données)
Une sauvegarde complète de la base de données est nécessaire pour la récupération de votre déploiement. Une sauvegarde complète inclut une partie du journal des transactions afin de pouvoir récupérer la sauvegarde complète. Les sauvegardes complètes sont autonomes dans le fait qu’elles représentent l’intégralité de la base de données telle qu’elle existait lorsque vous l’avez sauvegardée. Pour plus d’informations, consultez Sauvegardes complètes de base de données.
Sauvegardes de données différentielles (bases de données)
Une sauvegarde différentielle de base de données enregistre uniquement les données qui ont changé depuis la dernière sauvegarde complète de la base de données, appelée base différentielle. Les sauvegardes différentielles de base de données sont plus petites et plus rapides que les sauvegardes complètes de base de données. Cette option permet d’économiser du temps de sauvegarde au coût d’une complexité accrue. Pour les bases de données volumineuses, les sauvegardes différentielles peuvent se produire à des intervalles plus courts que les sauvegardes de base de données, ce qui réduit l’exposition à la perte de travail. Pour plus d’informations, consultez Sauvegardes de base de données différentielles.
Vous devez également sauvegarder régulièrement vos journaux de transactions. Ces sauvegardes sont nécessaires pour récupérer des données lorsque vous utilisez le modèle de sauvegarde de base de données complet. Si vous sauvegardez les journaux des transactions, vous pouvez récupérer la base de données au point de défaillance ou à un point antérieur dans le temps.
Sauvegardes du journal des transactions
Le journal des transactions est un enregistrement série de toutes les modifications qui se sont produites dans une base de données en plus de la transaction qui a effectué chaque modification. Le journal des transactions enregistre le début de chaque transaction, les modifications apportées aux données et, si nécessaire, suffisamment d’informations pour annuler les modifications apportées pendant cette transaction. Le journal augmente en permanence à mesure que les opérations journalisées se produisent dans la base de données.
En sauvegardant les journaux des transactions, vous pouvez récupérer la base de données à un point antérieur dans le temps. Par exemple, vous pouvez restaurer la base de données à un point avant que les données indésirables n’ont été entrées ou qu’une défaillance s’est produite. Outre les sauvegardes de base de données, les sauvegardes de journal des transactions doivent faire partie de votre stratégie de récupération. Pour plus d’informations, consultez Sauvegardes du journal des transactions (SQL Server).
Les sauvegardes du journal des transactions utilisent généralement moins de ressources que les sauvegardes complètes. Par conséquent, vous pouvez créer des sauvegardes de journal des transactions plus fréquemment que des sauvegardes complètes, ce qui réduit votre risque de perte de données. Toutefois, une sauvegarde du journal des transactions est parfois supérieure à une sauvegarde complète. Par exemple, une base de données avec un taux de transaction élevé entraîne une croissance rapide du journal des transactions. Dans ce cas, vous devez créer des sauvegardes de journal des transactions plus fréquemment. Pour plus d’informations, consultez Résoudre les problèmes liés à un journal des transactions saturé (Erreur de serveur SQL 9002).
Vous pouvez effectuer les types de sauvegardes de journal des transactions suivants :
- Une sauvegarde de journal pure contient uniquement des enregistrements de journal des transactions pour un intervalle, sans aucune modification en bloc.
- Une sauvegarde de journal en bloc contient des pages de journal et de données qui ont été modifiées par les opérations en bloc. La récupération jusqu'à une date et heure n'est pas possible.
- Une sauvegarde de la fin du journal est effectuée à partir d’une base de données éventuellement endommagée pour capturer les enregistrements de journal qui n’ont pas encore été sauvegardés. Une sauvegarde de la fin du journal est effectuée après un échec pour empêcher la perte de travail et peut contenir des données de journal pures ou de journal en bloc.
Étant donné que la synchronisation des données est essentielle pour la restauration réussie d’Azure DevOps Server, vous devez utiliser des transactions marquées dans le cadre de votre stratégie de sauvegarde si vous configurez manuellement des sauvegardes. Pour plus d’informations, consultez Créer une planification et un plan de sauvegarde et sauvegarder manuellement Azure DevOps Server.
Sauvegardes de service de la couche Application
La seule sauvegarde nécessaire pour la couche Application logique concerne la clé de chiffrement pour Reporting Services. Si vous utilisez la fonctionnalité Sauvegardes planifiées pour sauvegarder votre déploiement, cette clé est sauvegardée pour vous dans le cadre du plan. Vous pouvez supposer que vous devez sauvegarder des sites web utilisés comme portails de projet.
Bien que vous puissiez sauvegarder un niveau Application plus facilement qu’un niveau de données, il existe toujours plusieurs étapes pour restaurer une couche Application. Vous devez installer un autre niveau d’application pour Azure DevOps Server, rediriger les collections de projets afin d’utiliser le nouveau niveau d’application et rediriger les sites du portail pour les projets.
Noms de base de données par défaut
Si vous ne personnalisez pas les noms de vos bases de données, vous pouvez utiliser le tableau suivant pour identifier les bases de données utilisées dans votre déploiement d’Azure DevOps Server. Comme mentionné précédemment, tous les déploiements n’ont pas toutes ces bases de données. Par exemple, si vous n’avez pas configuré Azure DevOps Server avec Reporting Services, vous n’aurez pas les bases de données ReportServer ou ReportServerTempDB. De même, vous n’aurez pas la base de données pour System Center Virtual Machine Manager (SCVMM), VirtualManagerDB, sauf si vous configurez Azure DevOps Server pour prendre en charge La gestion des laboratoires. En outre, les bases de données qu’Azure DevOps Server utilise peuvent être distribuées sur plusieurs instances de SQL Server ou sur plusieurs serveurs.
Remarque
Par défaut, le préfixe TFS_ est ajouté aux noms des bases de données créées automatiquement lorsque vous installez Azure DevOps Server ou pendant son fonctionnement.
| Base de données | Description |
|---|---|
| TFS_Configuration | La base de données de configuration pour Azure DevOps Server contient le catalogue, les noms de serveurs et les données de configuration pour le déploiement. Le nom de cette base de données peut inclure des caractères supplémentaires entre TFS_ et Configuration, tels que le nom d’utilisateur de la personne qui a installé Azure DevOps Server. Par exemple, le nom de la base de données peut être TFS_UserNameConfiguration |
| TFS_Warehouse | La base de données de l’entrepôt contient les données permettant de créer l’entrepôt que Reporting Services utilise. Le nom de cette base de données peut inclure des caractères supplémentaires entre TFS_ et Warehouse, tels que le nom d’utilisateur de la personne qui a installé Azure DevOps Server. Par exemple, le nom de la base de données peut être TFS_UserNameWarehouse. |
| TFS_CollectionName | La base de données d’une collection de projets contient toutes les données des projets de cette collection. Ces données incluent le code source, les configurations de build et les configurations de gestion de laboratoire. Le nombre de bases de données de collection est égal au nombre de collections. Par exemple, si vous avez trois regroupements dans votre déploiement, vous devez sauvegarder ces trois bases de données de collection. Le nom de chaque base de données peut inclure des caractères supplémentaires entre TFS_ et CollectionName, tels que le nom d’utilisateur de la personne qui a créé la collection. Par exemple, le nom d’une base de données de collection peut être TFS_UserNameCollectionName. |
| TFS_Analysis | La base de données pour SQL Server Analysis Services contient les sources de données et les cubes de votre déploiement d’Azure DevOps Server. Le nom de cette base de données peut inclure des caractères supplémentaires entre TFS_ et Analysis, tels que le nom d’utilisateur de la personne qui a installé Analysis Services. Par exemple, le nom de la base de données peut être TFS_UserNameAnalysis. Remarque : Vous pouvez sauvegarder cette base de données, mais vous devez reconstruire l’entrepôt à partir de la base de données TFS_Warehouse restaurée. |
| ReportServer | La base de données de Reporting Services contient les rapports et les paramètres de rapport pour votre déploiement d’Azure DevOps Server. Remarque : Si Reporting Services est installé sur un serveur distinct d’Azure DevOps Server, cette base de données peut ne pas être présente sur le serveur de couche Données pour Azure DevOps Server. Dans ce cas, vous devez configurer, sauvegarder et restaurer séparément d’Azure DevOps Server. Vous devez synchroniser la maintenance des bases de données pour éviter les erreurs de synchronisation. |
| ReportServerTempDB | La base de données temporaire pour Reporting Services stocke temporairement les informations lorsque vous exécutez des rapports spécifiques. Remarque : Si Reporting Services est installé sur un serveur distinct d’Azure DevOps Server, cette base de données peut ne pas être présente sur le serveur de couche Données pour Azure DevOps Server. Dans ce cas, vous devez configurer, sauvegarder et restaurer séparément d’Azure DevOps Server. Toutefois, vous devez synchroniser la maintenance des bases de données pour éviter les erreurs de synchronisation. |
| VirtualManagerDB | La base de données d’administration pour SCVMM contient les informations que vous affichez dans la console d’administration SCVMM, telles que les machines virtuelles, les hôtes de machines virtuelles, les serveurs de bibliothèque de machines virtuelles et leurs propriétés. Remarque : Si SCVMM est installé sur un serveur distinct d’Azure DevOps Server, cette base de données peut ne pas être présente sur le serveur de couche Données pour Azure DevOps Server. Dans ce cas, vous devez configurer, sauvegarder et restaurer séparément d’Azure DevOps Server. Toutefois, vous devez utiliser des transactions marquées et synchroniser la maintenance des bases de données pour éviter les erreurs de synchronisation. |