Obtenir des recommandations Azure pour migrer votre base de données SQL Server
L’extension Migration Azure SQL pour Azure Data Studio vous permet d’évaluer vos besoins de base de données, d’obtenir des recommandations de référence SKU appropriée pour les ressources Azure et de migrer votre base de données SQL Server vers Azure.
Découvrez comment utiliser cette expérience unifiée en collectant des données de performances à partir de votre instance SQL Server source pour obtenir des recommandations Azure appropriées en termes de taille pour vos cibles Azure SQL.
Vue d’ensemble
Avant la migration vers Azure SQL, vous pouvez utiliser l’extension Migration Azure SQL dans Azure Data Studio pour vous permettre de générer des recommandations appropriées en termes de taille pour Azure SQL Database, Azure SQL Managed Instance et SQL Server sur des cibles Machines virtuelles Azure. L’outil vous permet de collecter les données de performances de votre instance SQL source (exécutée en local ou sur un autre cloud) et recommande une configuration de calcul et de stockage pour répondre aux besoins de votre charge de travail.
Le diagramme présente le workflow des recommandations Azure dans l’extension Migration Azure SQL pour Azure Data Studio :

Remarque
L’évaluation et la fonctionnalité de recommandations Azure de l’extension Migration Azure SQL pour Azure Data Studio prend également en charge les instances SQL Server sources s’exécutant sur Windows ou Linux.
Prérequis
Pour commencer à utiliser les recommandations Azure pour la migration de votre base de données SQL Server, vous devez suivre les prérequis suivants :
Installez l’extension de migration Azure SQL à partir de la place de marché Azure Data Studio.
Vérifiez que la connexion que vous utilisez pour connecter l’instance SQL Server source dispose des autorisations minimales.
Sources et cibles prises en charge
Les recommandations Azure peuvent être générées pour les versions de SQL Server suivantes :
- SQL Server 2008 et versions ultérieures sur Windows ou Linux sont prises en charge.
- SQL Server exécuté sur d’autres clouds peut être pris en charge, mais les résultats seront plus ou moins exacts.
Les recommandations Azure peuvent être générées pour les cibles Azure SQL suivantes :
- Azure SQL Database
- Familles de matériel : série Standard (Gen5)
- Niveaux de service : Usage général, Critique pour l’entreprise, Hyperscale
- Azure SQL Managed Instance
- Familles de matériel : série Standard (Gen5), série Premium, série Premium à mémoire optimisée
- Niveaux de service : Usage général, Critique pour l’entreprise
- SQL Server sur les machines virtuelles Azure
- Familles de machines virtuelles : Usage général, à mémoire optimisée
- Familles de stockage : SSD Premium
Collecte des données de performances
Avant de pouvoir générer des recommandations, les données de performances doivent être collectées à partir de votre instance SQL Server source. Au cours de cette étape de collecte de données, plusieurs vues système dynamiques (DMV) de votre instance SQL Server sont interrogées pour capturer les caractéristiques des performances de votre charge de travail. L’outil capture les métriques, notamment l’utilisation du processeur, de la mémoire, du stockage et des E/S, toutes les 30 secondes, puis enregistre les compteurs de performances localement sur votre ordinateur sous la forme d’un ensemble de fichiers CSV.
Niveau de l'instance
Ces données de performances sont collectées une fois par instance SQL Server :
| Dimension des performances | Description | Vue de gestion dynamique (DMV) |
|---|---|---|
SqlInstanceCpuPercent |
Quantité de processeur utilisée par le processus SQL Server, sous la forme d’un pourcentage | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Empreinte mémoire globale du processus SQL Server | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
Utilisation de la mémoire de SQL Server | sys.dm_os_process_memory |
Au niveau de la base de données
| Dimension des performances | Description | Vue de gestion dynamique (DMV) |
|---|---|---|
DatabaseCpuPercent |
Pourcentage total de processeur utilisé par une base de données | sys.dm_exec_query_stats |
CachedSizeInMb |
Taille totale en mégaoctets du cache utilisé par une base de données | sys.dm_os_buffer_descriptors |
Niveau du fichier
| Dimension des performances | Description | Vue de gestion dynamique (DMV) |
|---|---|---|
ReadIOInMb |
Nombre total de mégaoctets lus de ce fichier | sys.dm_io_virtual_file_stats |
WriteIOInMb |
Nombre total de mégaoctets écrits dans ce fichier | sys.dm_io_virtual_file_stats |
NumOfReads |
Nombre total de lectures émises sur ce fichier | sys.dm_io_virtual_file_stats |
NumOfWrites |
Nombre total d’écritures émises sur ce fichier | sys.dm_io_virtual_file_stats |
ReadLatency |
Latence de lecture des E/S sur ce fichier | sys.dm_io_virtual_file_stats |
WriteLatency |
Latence d’écriture des E/S sur ce fichier | sys.dm_io_virtual_file_stats |
Un minimum de 10 minutes de collecte de données est nécessaire avant qu’une recommandation puisse être générée, mais pour évaluer avec précision votre charge de travail, il est recommandé d’exécuter la collecte de données pendant une durée suffisamment longue pour capturer à la fois l’utilisation pendant les pics et en dehors.
Pour lancer le processus de collecte de données, commencez par vous connecter à votre instance SQL source dans Azure Data Studio, puis lancez l’Assistant Migration SQL. À l’étape 2, sélectionnez « Obtenir une recommandation Azure ». Sélectionnez « Collecter les données de performances maintenant », puis sélectionnez un dossier sur votre ordinateur où les données collectées seront enregistrées.
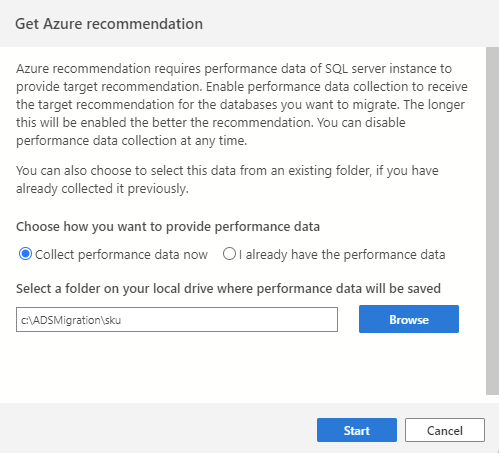
Le processus de collecte de données s’exécute pendant 10 minutes pour générer la première recommandation. Important : démarrez le processus de collecte des données quand la charge de travail de votre base de données active reflète une utilisation proche de vos scénarios de production.
Une fois la première recommandation générée, vous pouvez continuer à exécuter le processus de collecte des données pour affiner les recommandations. Cette option est particulièrement utile si vos modèles d’utilisation varient au fil du temps.
Le processus de collecte de données commence une fois que vous avez sélectionné Démarrer. Toutes les 10 minutes, les points de données collectés sont agrégés et la valeur maximale, la moyenne et la variance de chaque compteur sont écrites sur disque dans un ensemble de trois fichiers CSV.
En règle générale, vous voyez un ensemble de fichiers CSV avec les suffixes suivants dans le dossier sélectionné :
SQLServerInstance_CommonDbLevel_Counters.csv : contient les données de configuration statiques de la disposition et des métadonnées du fichier de base de données.SQLServerInstance_CommonInstanceLevel_Counters.csv : contient les données statiques de la configuration matérielle de l’instance de serveur.SQLServerInstance_PerformanceAggregated_Counters.csv : contient les données de performances agrégées qui sont fréquemment mises à jour.
Pendant ce temps, laissez Azure Data Studio ouvert, même si vous pouvez poursuivre d’autres opérations. À tout moment, vous pouvez arrêter le processus de collecte de données en revenant à cette page et en sélectionnant Arrêter la collecte de données.
Générer des recommandations de taille appropriée
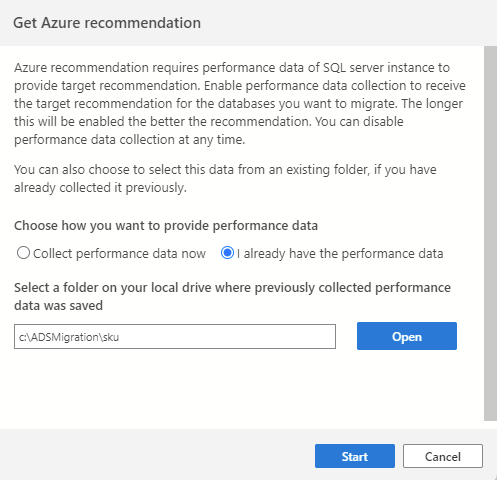
Si vous avez déjà collecté des données de performances au cours d’une session précédente ou à l’aide d’un autre outil (tel que l’Assistant Migration de base de données), vous pouvez importer les données de performances existantes en sélectionnant l’option J’ai déjà les données de performances. Sélectionnez le dossier dans lequel vos données de performances (trois fichiers .csv) sont enregistrées et sélectionnez Démarrer pour lancer le processus de recommandation.
L’étape 1 de l’Assistant Migration SQL vous demande de sélectionner un ensemble de bases de données à évaluer. Celles-ci sont les seules bases de données qui seront prises en compte pendant le processus de recommandation.
Toutefois, le processus de collecte des données de performances collecte les compteurs de performances de toutes les bases de données de l’instance SQL Server source, pas seulement celles qui ont été sélectionnées.
Cela signifie que les données de performances précédemment collectées peuvent être utilisées pour générer plusieurs fois des recommandations pour un autre sous-ensemble de bases de données en spécifiant une liste différente à l’étape 1.
Paramètres de recommandation
Plusieurs paramètres configurables peuvent affecter vos recommandations.

Sélectionnez l’option Modifier les paramètres pour ajuster ces paramètres en fonction de vos besoins.
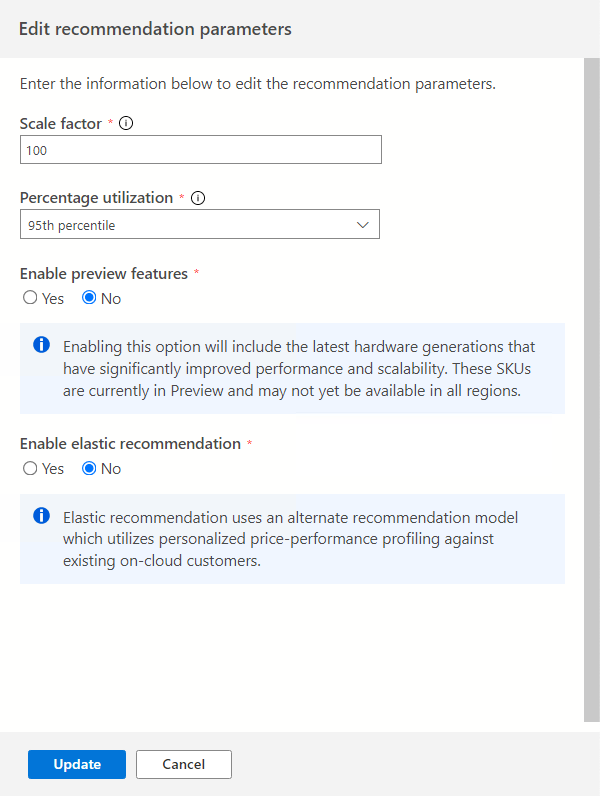
Facteur d’échelle :
Cette option vous permet de fournir une mémoire tampon à appliquer à chaque dimension de performances. Cette option prend en compte les problèmes, tels que l’utilisation saisonnière, l’historique des performances de courte durée et l’augmentation éventuelle de l’utilisation. Par exemple, si vous déterminez qu’une exigence de quatre vCores de processeur a un facteur d’échelle de 150 %, la véritable exigence de processeur est de six vCores.
Le volume du facteur d’échelle par défaut est de 100 %.
Utilisation en pourcentage :
Centile des points de données à utiliser pendant l’agrégation des données de performances.
La valeur par défaut est le 95e centile.
Activer les fonctionnalités en préversion :
Cette option permet de recommander des configurations qui peuvent ne pas être encore en disponibilité générale pour tous les utilisateurs de toutes les régions.
Cette option est désactivée par défaut.
Activer la recommandation élastique :
Cette option utilise un autre modèle de recommandation qui utilise un profil prix/performance personnalisé par rapport aux clients cloud existants.
Cette option est désactivée par défaut.
Le processus de collecte de données se termine si vous fermez Azure Data Studio. Les données collectées jusqu’à ce point sont enregistrées dans votre dossier.
Si vous fermez Azure Data Studio alors que la collecte de données est en cours, utilisez l’une des options suivantes pour redémarrer la collecte de données :
Rouvrez Azure Data Studio et importez les fichiers de données qui ont été enregistrés dans votre dossier local. Ensuite, générez une recommandation à partir des données collectées.
Rouvrez Azure Data Studio et recommencez la collecte de données en utilisant l’Assistant de migration.
Autorisations minimales
Pour interroger les vues système nécessaires pour la collecte de données de performances, des autorisations spécifiques sont requises pour la connexion SQL Server utilisée pour cette tâche. Vous pouvez créer un utilisateur avec des privilèges minimum pour la collecte de données d’évaluation et de performances à l’aide du script suivant :
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Scénarios et limitations non pris en charge
Les recommandations Azure n’incluent aucune estimation de prix, car celle-ci peut varier en fonction de la région, de la devise et des remises comme Azure Hybrid Benefit. Pour obtenir des estimations de prix, utilisez la Calculatrice de prix Azure ou créez une évaluation SQL dans Azure Migrate.
Les recommandations pour Azure SQL Database avec le modèle d’achat DTU ne sont pas prises en charge.
Actuellement, les recommandations Azure pour le niveau de calcul serverless Azure SQL Database et les pools élastiques ne sont pas prises en charge.
Résolution des problèmes
- Aucune recommandation générée
- Si aucune recommandation n’a été générée, cela peut signifier qu’aucune configuration pouvant répondre pleinement aux critères de performances de votre instance source n’a été identifiée. Pour voir les raisons pour lesquelles une taille, un niveau de service ou une famille de matériel en particulier a été disqualifié :
- Accédez aux journaux d’Azure Data Studio en vous rendant dans Aide > Afficher toutes les commandes > Ouvrir le dossier des journaux d’extension
- Accédez à Microsoft.mssql > SqlAssessmentLogs > et ouvrez SkuRecommendationEvent.log
- Le journal contient une trace de chaque configuration potentielle qui a été évaluée et la raison pour laquelle elle a été/n’a pas été considérée comme étant une configuration éligible :

- Essayez de regénérer la recommandation avec recommandation élastique activée. Cette option utilise un autre modèle de recommandation qui utilise un profil prix/performance personnalisé par rapport aux clients cloud existants.
- Si aucune recommandation n’a été générée, cela peut signifier qu’aucune configuration pouvant répondre pleinement aux critères de performances de votre instance source n’a été identifiée. Pour voir les raisons pour lesquelles une taille, un niveau de service ou une famille de matériel en particulier a été disqualifié :
