Utiliser Data Lake Tools pour Visual Studio afin de se connecter à Azure HDInsight et exécuter des requêtes Apache Hive
Apprenez à utiliser Microsoft Azure Data Lake et Stream Analytics Tools pour Visual Studio (Data Lake Tools). Utilisez l'outil pour vous connecter aux clusters Apache Hadoop d'Azure HDInsight et envoyer des requêtes Hive.
Pour en savoir plus sur l’utilisation de HDInsight, consultez la rubrique Prise en main de HDInsight.
Vous pouvez utiliser Data Lake Tools pour Visual Studio pour accéder à Azure Data Lake Analytics et à HDInsight. Pour plus d’informations sur Data Lake Tools, consultez le Développer des scripts U-SQL avec les outils Data Lake pour Visual Studio.
Prérequis
Pour suivre la procédure de cet article et utiliser Data Lake Tools for Visual Studio, vous avez besoin des éléments suivants :
Un cluster Azure HDInsight. Pour créer un cluster Azure HDInsight, consultez Bien démarrer avec Apache Hadoop dans Azure HDInsight. Pour exécuter des requêtes Apache Hive interactives, il vous faut un cluster HDInsight Interactive Query.
Visual Studio. Visual Studio Community (édition gratuite). Les instructions présentées ici concernent Visual Studio 2019.
Installation de Data Lake Tools pour Visual Studio
Suivez les instructions appropriées pour installer Data Lake Tools pour votre version de Visual Studio :
Pour Visual Studio 2017 ou Visual Studio 2019 :
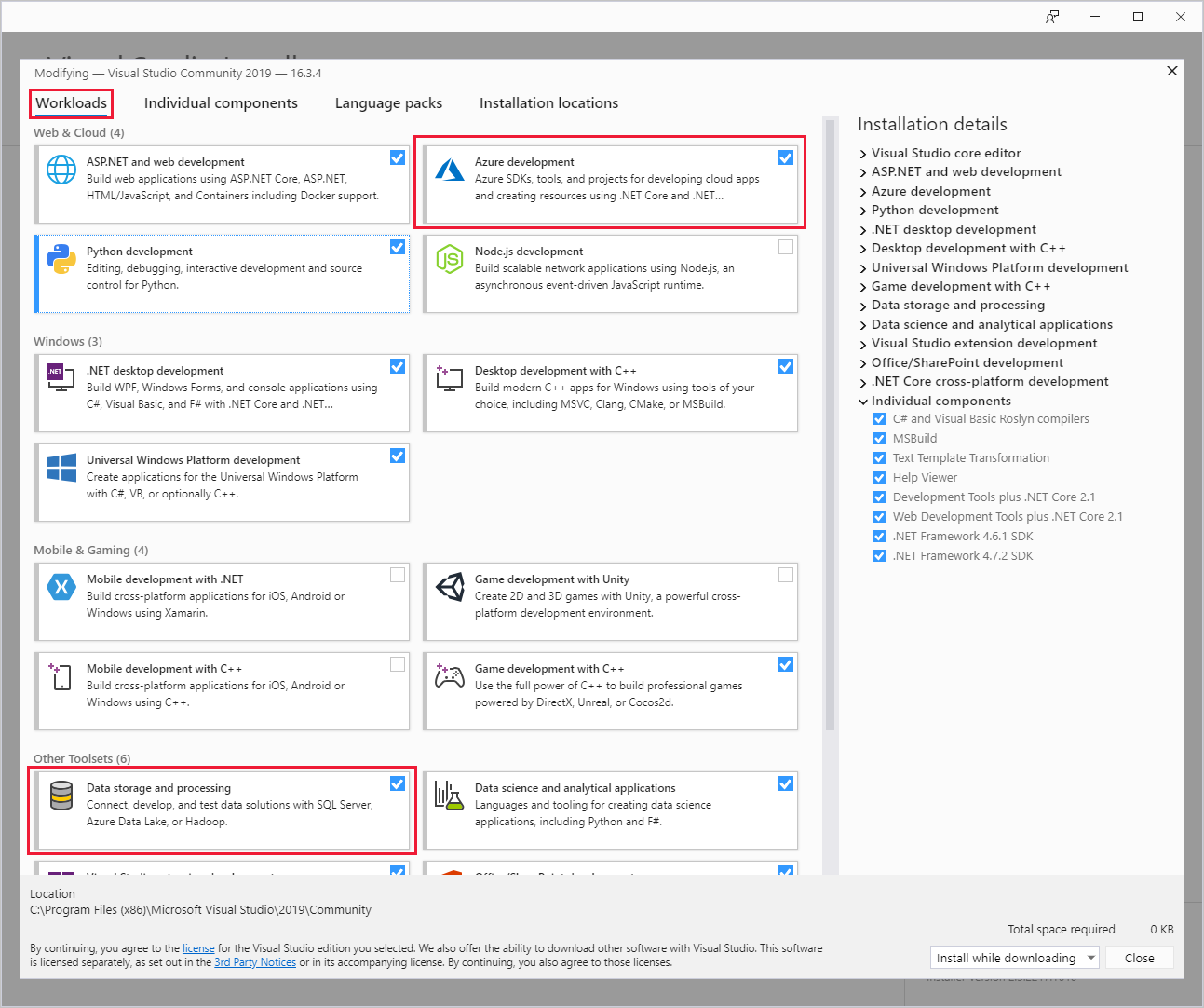
Lors de l’installation de Visual Studio, veillez à inclure la charge de travail Développement Azure ou la charge de travail Stockage et traitement des données.
Pour les installations Visual Studio existantes, accédez à la barre de menus de l’IDE et sélectionnez Outils>Obtenir des outils et des fonctionnalités pour ouvrir Visual Studio Installer. Dans l'onglet Charges de travail, sélectionnez au moins la charge de travail Développement Azure (sous Web et cloud). Ou sélectionnez la charge de travail Stockage et traitement des données (sous Autres ensembles d'outils).
Pour Visual Studio 2015 :
Téléchargez Data Lake Tools. Choisissez la version de Data Lake Tools qui correspond à celle de Visual Studio.
Mettre à jour Azure Data Lake Tools pour Visual Studio
Ensuite, assurez-vous de mettre à jour Data Lake Tools vers la version la plus récente.
Ouvrez Visual Studio.
Dans la fenêtre Démarrer, sélectionnez Continuer sans code.
Dans la barre de menus de l’IDE Visual Studio, choisissez Extensions>Gérer les extensions.
Dans la boîte de dialogue Gérer les extensions, développez le nœud Mises à jour.
Si la liste des mises à jour disponibles comprend Azure Data Lake et Stream Analytic Tools, sélectionnez-la. Cliquez ensuite sur le bouton Mettre à jour. Une fois que la boîte de dialogue Télécharger et installer s’affiche et disparaît, Visual Studio ajoute l’extension Azure Data Lake and Stream Analytic Tools à la planification des mises à jour.
Fermez toutes les fenêtres de Visual Studio. La boîte de dialogue du programme d’installation VSIX s’affiche.
Sélectionnez Licence pour lire les termes du contrat de licence, puis sélectionnez Fermer pour revenir à la boîte de dialogue du programme d’installation de VSIX.
Sélectionnez Modifier. L’installation de la mise à jour de l’extension commence. Après un certain temps, la boîte de dialogue change pour indiquer que les modifications ont été effectuées. Sélectionnez Fermez, puis redémarrez Visual Studio pour terminer l’installation.
Notes
Vous ne pouvez utiliser que la version 2.3.0.0 ou ultérieure de Data Lake Tools pour vous connecter aux clusters Interactive Query et exécuter des requêtes Hive interactives.
Se connecter aux abonnements Azure
Vous pouvez utiliser Data Lake Tools pour Visual Studio pour vous connecter à vos clusters HDInsight, effectuer des opérations de gestion de base et exécuter des requêtes Hive.
Notes
Pour plus d’informations sur la connexion à un cluster Hadoop générique, consultez Comment écrire et soumettre des requêtes Hive à l’aide de Visual Studio.
Connexion à un abonnement Azure
Pour vous connecter à votre abonnement Azure :
Ouvrez Visual Studio.
Dans la fenêtre Démarrer, sélectionnez Continuer sans code.
Dans la barre de menus de l’IDE, sélectionnez Afficher>Explorateur de serveurs.
Dans l’Explorateur de serveurs, faites un clic droit sur Azure, sélectionnez Se connecter à abonnement Microsoft Azure, puis terminez le processus de connexion. Dans l’Explorateur de serveurs, développez Azure>HDInsight pour afficher une liste des clusters HDInsight existants.
Si vous ne possédez aucun cluster, créez-en un dans le Portail Azure, avec Azure PowerShell ou à l’aide du Kit de développement logiciel (SDK) HDInsight. Pour plus d’informations, consultez Configurer des clusters dans HDInsight.
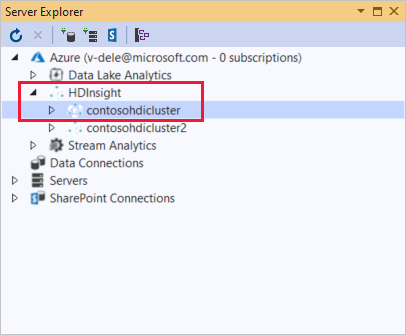
Développez un cluster HDInsight. Le cluster contient des nœuds pour les Bases de données Hive. Il contient aussi un compte de stockage par défaut, les éventuels autres comptes de stockage liés et le journal Hadoop Service. Vous pouvez développer davantage les entités.
Une fois connecté à votre abonnement Azure, vous êtes en mesure d’effectuer les tâches suivantes.
Se connecter à Azure à partir de Visual Studio
Pour vous connecter au portail Azure à partir de Visual Studio :
Dans l’Explorateur de serveurs, développez Azure>HDInsight et sélectionnez votre cluster.
Cliquez avec le bouton droit sur un cluster HDInsight, puis sélectionnez Gérer le cluster dans le Portail Microsoft Azure.
Poser des questions et envoyer des commentaires à partir de Visual Studio
Pour poser des questions et/ou envoyer des commentaires à partir de Visual Studio :
À partir de l’Explorateur de serveurs, sélectionnez Azure>HDInsight.
Faites un clic droit sur HDInsight, puis sélectionnez Forum MSDN pour poser des questions ou Envoyer des commentaires pour transmettre votre avis.
Lier ou modifier un cluster
Notes
Actuellement, le seul type de cluster HDInsight vers lequel vous pouvez établir un lien est un type Hive.
Lier un cluster HDInsight :
Cliquez avec le bouton droit sur HDInsight, puis sélectionnez Lier un cluster HDInsight pour afficher la boîte de dialogue Lier un cluster HDInsight.
Entrez une URL de connexion sous la forme
https://CLUSTERNAME.azurehdinsight.net. Le nom du cluster se renseigne automatiquement avec la partie du nom du cluster compris dans votre URL lorsque vous accédez à un autre champ. Entrez un Nom d’utilisateur et un Mot de passe, puis sélectionnez Suivant.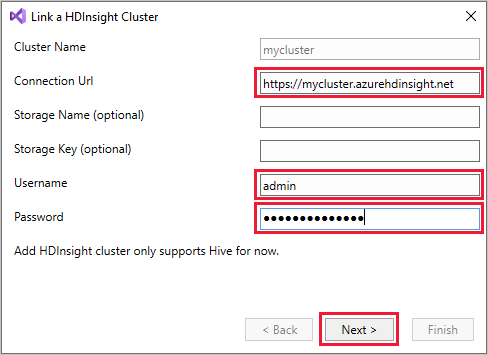
Sélectionnez Terminer. Si la liaison du cluster est réussie, le cluster est alors répertorié sous le nœud HDInsight.
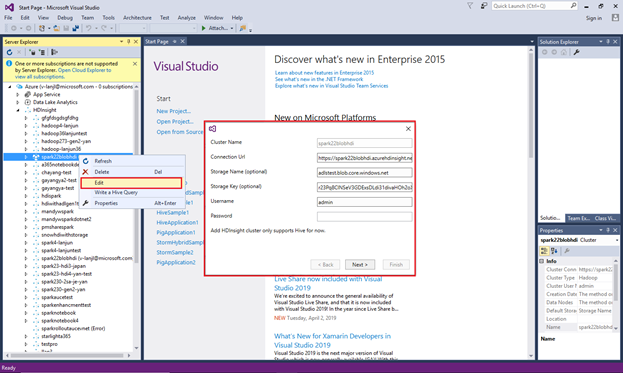
Pour mettre à jour un cluster lié, cliquez avec le bouton droit sur le cluster, puis sélectionnez Modifier. Vous pouvez ensuite mettre à jour les informations du cluster.
Explorer des ressources liées
Dans l’Explorateur de serveurs, vous pouvez voir le compte de stockage par défaut et les éventuels comptes de stockage liés. Développez le compte de stockage par défaut pour afficher les conteneurs dans le compte de stockage. Le compte de stockage par défaut et le conteneur par défaut sont marqués.
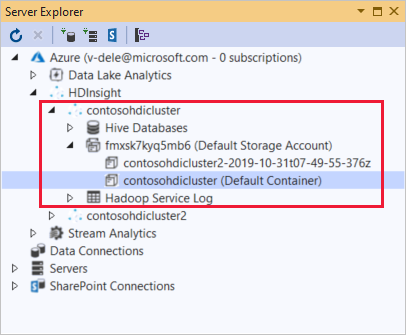
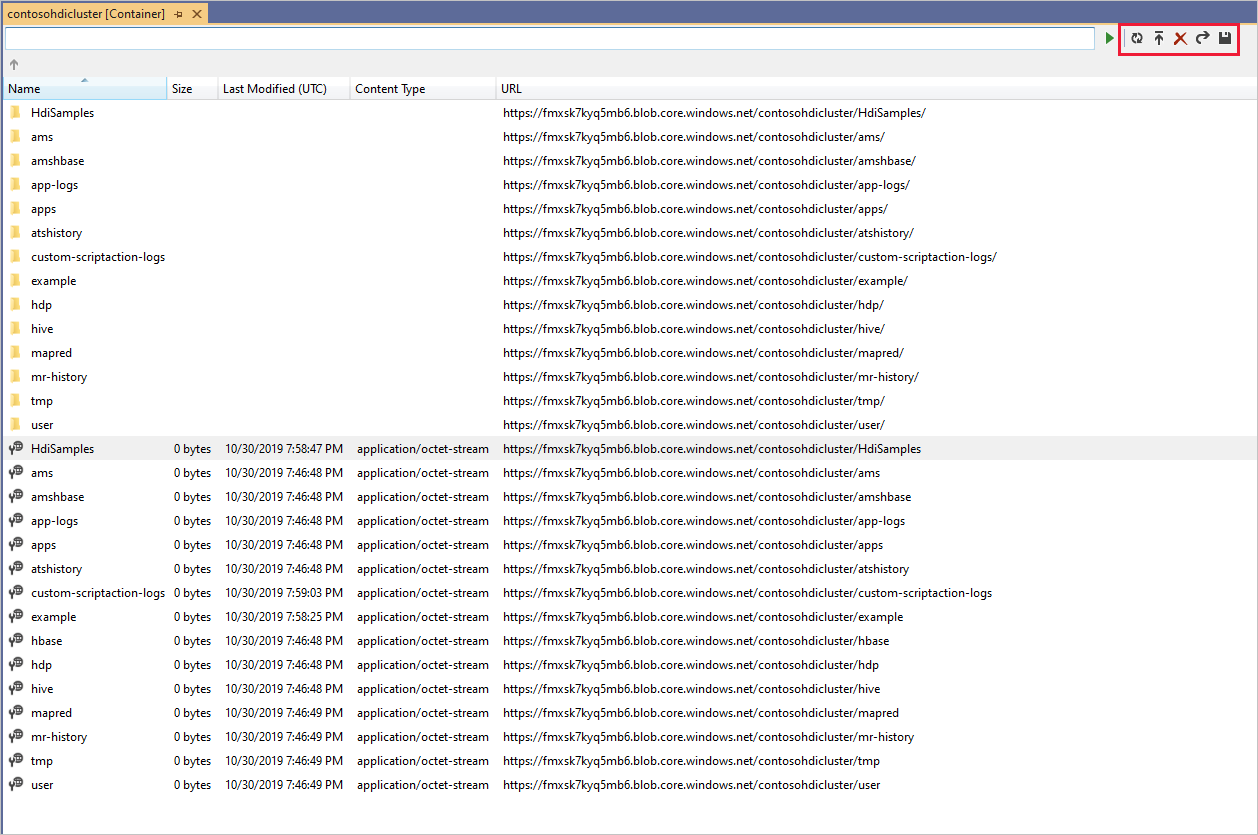
Cliquez avec le bouton droit sur un conteneur, puis sélectionnez Afficher le conteneur pour afficher le contenu du conteneur. Une fois le conteneur ouvert, vous pouvez utiliser les boutons de la barre d’outils pour actualiser la liste de contenu, charger un objet blob, supprimer les objets blob sélectionnés, ouvrir un objet blob et télécharger (Enregistrer sous) les objets blob sélectionnés.
Exécuter des requêtes Apache Hive interactives
Apache Hive est une infrastructure d’entrepôt de données construite sur Hadoop. Hive est utilisée pour le résumé, les requêtes et l’analyse des données. Vous pouvez utiliser Data Lake Tools pour Visual Studio pour exécuter des requêtes Hive à partir de Visual Studio. Pour plus d’informations sur Hive, consultez Présentation d’Apache Hive et HiveQL sur Azure HDInsight.
Interactive Query dans Azure HDInsight utilise Hive on LLAP dans Apache Hive 2.1. Interactive Query permet l’interactivité dans des requêtes d’entrepôt de données complexes sur des jeux de données volumineux stockés. L’exécution de requêtes Hive sur Interactive Query est beaucoup plus rapide que les programmes de traitement par lots Hive traditionnels.
Notes
Vous ne pouvez exécuter des requêtes Hive interactives que lorsque vous vous connectez à un cluster HDInsight Interactive Query.
Vous pouvez aussi utiliser Data Lake Tools pour Visual Studio afin de déterminer ce que contient la tâche Hive. Data Lake Tools pour Visual Studio collecte et fait apparaître les journaux d’activité Yarn de certaines tâches Hive.
À partir de l’Explorateur de serveurs, cliquez sur Azure>HDInsight et sélectionnez votre cluster. Ce nœud est le point de départ dans l’Explorateur de serveurs pour les sections suivantes.
Afficher hivesampletable
Tous les clusters HDInsight ont un exemple de tableau Hive par défaut appelé hivesampletable.
Depuis votre cluster, sélectionnez Bases de données Hive>par défaut>hivesampletable.
Pour afficher le schéma
hivesampletable:Développez hivesampletable. Les noms et les types de données des colonnes
hivesampletablesont affichés.Pour visualiser les données
hivesampletable:Cliquez avec le bouton droit de la souris sur hivesampletable, et sélectionnez Afficher les 100 premières rangées. La liste des 100 résultats s’affiche dans la fenêtre Table Hive : hivesampletable. Cette action revient à exécuter la requête Hive suivante à l’aide du pilote ODBC Hive :
SELECT * FROM hivesampletable LIMIT 100Vous pouvez personnaliser le nombre de lignes en modifiant le nombre de lignes ; vous pouvez choisir 50, 100, 200 ou 1 000 lignes dans la liste déroulante.
Créer des tables Hive
Vous pouvez utiliser des requêtes Hive ou utiliser la GUI pour créer une table Hive. Pour plus d’informations relatives à l’utilisation de requêtes Hive, consultez Créer et exécuter des requêtes Hive.
Depuis votre cluster, sélectionnez Bases de données Hive>par défaut.
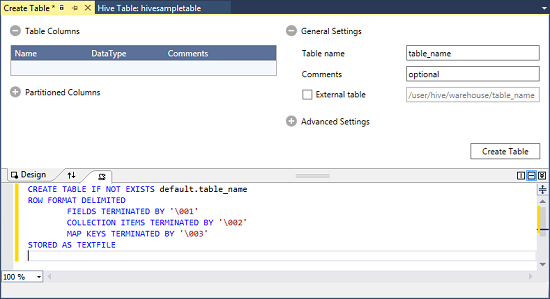
Faites un clic droit sur Par défaut, puis sélectionnez Créer une table.
Configurez la table.
Sélectionnez le bouton Créer une table pour envoyer le travail, ce qui entraîne la création de la nouvelle table Hive.
Créer et exécuter des requêtes Hive
Vous pouvez créer et exécuter des requêtes Hive de deux façons :
- Création de requêtes ad hoc
- Création d’une application Hive
Créer une requête ad-hoc
Pour créer et exécuter une requête ad-hoc :
Faites un clic droit sur le cluster dans lequel vous souhaitez exécuter la requête, puis sélectionnez Écrire une requête Hive.
Entrez une requête Hive.
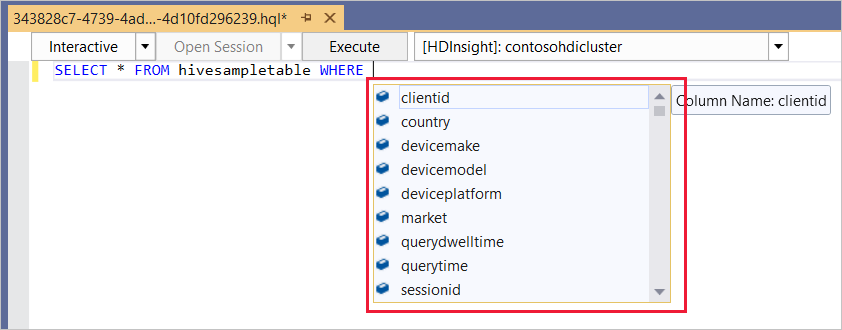
L’éditeur Hive prend en charge IntelliSense. Data Lake Tools pour Visual Studio prend en charge le chargement des métadonnées distantes pendant la modification d’un script Hive. Par exemple, si vous tapez
SELECT * FROM, IntelliSense répertorie tous les noms de table suggérés. Lorsqu’un nom de table est spécifié, IntelliSense répertorie les noms de colonne. Les outils prennent en charge la plupart des instructions DML, sous-requêtes et fonctions définies par l’utilisateur intégrées de Hive.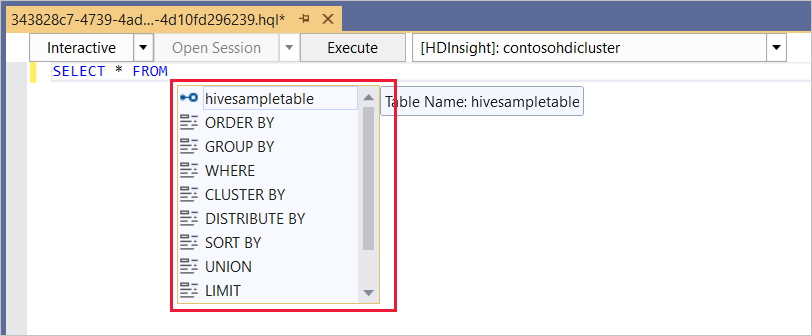
Remarque
IntelliSense propose uniquement les métadonnées du cluster sélectionné dans la barre d’outils HDInsight.
Voici un exemple de requête que vous pouvez utiliser :
SELECT devicemodel, COUNT(devicemodel) AS deviceCount FROM hivesampletable GROUP BY devicemodel ORDER BY devicemodelChoisissez le mode d’exécution :
Interactive
Dans la première liste déroulante, choisissez Interactif, puis sélectionnez Exécuter.

Batch
Dans la première liste déroulante, choisissez Batch, puis sélectionnez Envoyer. Ou sélectionnez l'icône déroulante située en regard de Envoyer et choisissez Avancé.
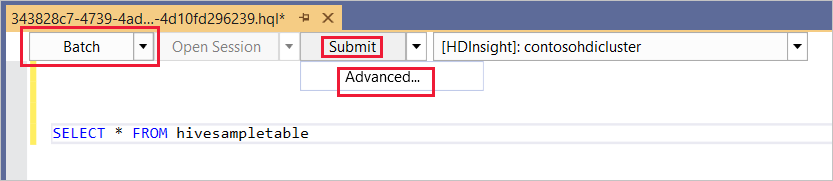
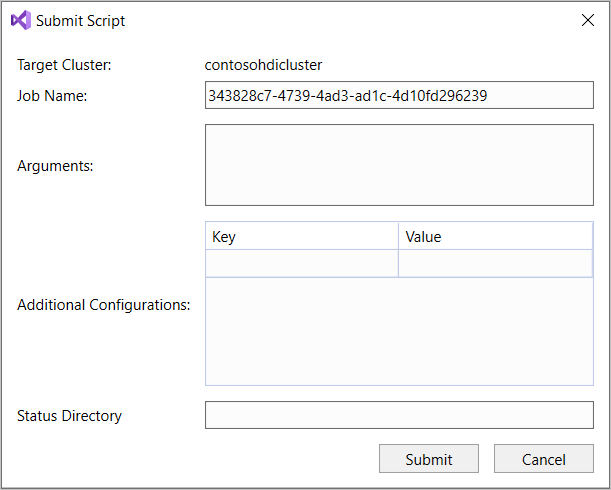
Si vous sélectionnez l’option d’envoi avancé, la boîte de dialogue Soumettre le script s’affiche. Configurez les éléments Nom de la tâche, Arguments, Configurations supplémentaires et Répertoire d’état pour le script.
Remarque
Vous ne pouvez pas soumettre de lots aux clusters de requêtes interactives. Vous devez utiliser le mode interactif.
Création d’une application Hive
Pour créer et exécuter une solution Hive :
Dans la barre de menus, choisissez Fichier>Nouveau>Projet.
Dans la fenêtre Créer un nouveau projet, sélectionnez la zone de recherche, puis tapez Hive. Choisissez ensuite Application Hive, puis sélectionnez Suivant.
Dans la fenêtre Configurer votre nouveau projet, entrez un Nom de projet, sélectionnez ou créez l’Emplacement du projet, puis sélectionnez Créer.
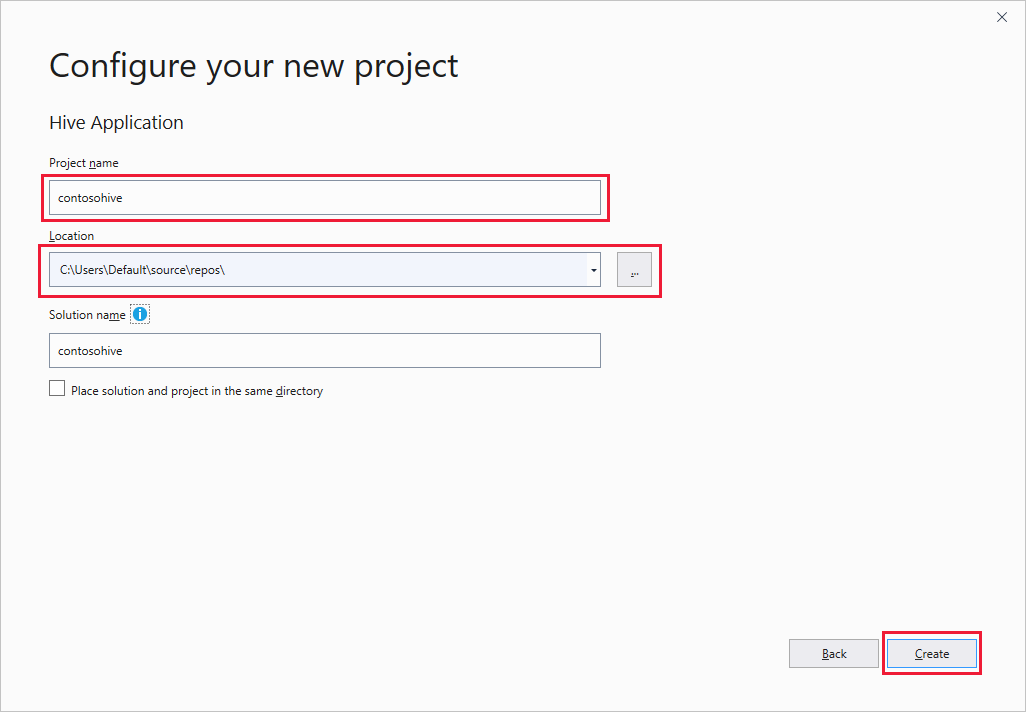
Dans l’Explorateur de solutions, double-cliquez sur le script Script.hql pour l’ouvrir.
Afficher le résumé et le résultat du travail
Le résumé du travail varie légèrement entre les modes Lot et Interactif.

Utilisez l’icône Actualiser pour mettre à jour l’état de la tâche jusqu’à ce qu’il passe à Terminé.
Pour les détails du travail en mode Lot, sélectionnez les liens en bas pour voir la Requête du travail, la Sortie du travail, le Journal du travail ou afficher les journaux Yarn.
Pour les détails du travail en mode Interactif, consultez les volets Sortie et Sortie HiveServer2.
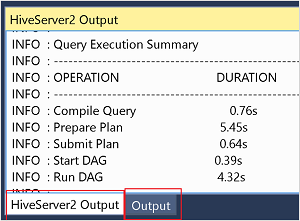
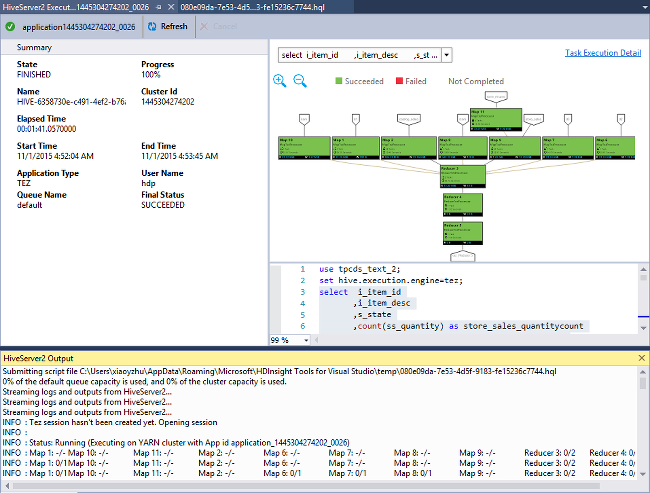
Afficher le graphique du travail
Actuellement, les graphiques des tâches ne sont affichés que pour les travaux Hive qui utilisent Tez comme moteur d’exécution. Pour plus d’informations sur l’activation de Tez, consultez Présentation d’Apache Hive et HiveQL sur Azure HDInsight. Voir aussi, Utiliser Apache Tez au lieu de Map Reduce.
Pour afficher tous les opérateurs à l’intérieur d’un vertex, double-cliquez sur les vertex du graphique de la tâche. Vous pouvez aussi pointer vers un opérateur spécifique pour afficher plus d’informations sur ce dernier.
Même si Tez est spécifié comme moteur d’exécution, il est possible que le graphique du travail n’apparaisse pas si aucune application Tez n’est lancée. Cela peut se produire parce que le travail ne contient pas d'instructions DML. Ou parce que les instructions DML peuvent revenir sans lancer d'application Tez. Par exemple, SELECT * FROM table1 ne lancera pas l’application Tez.
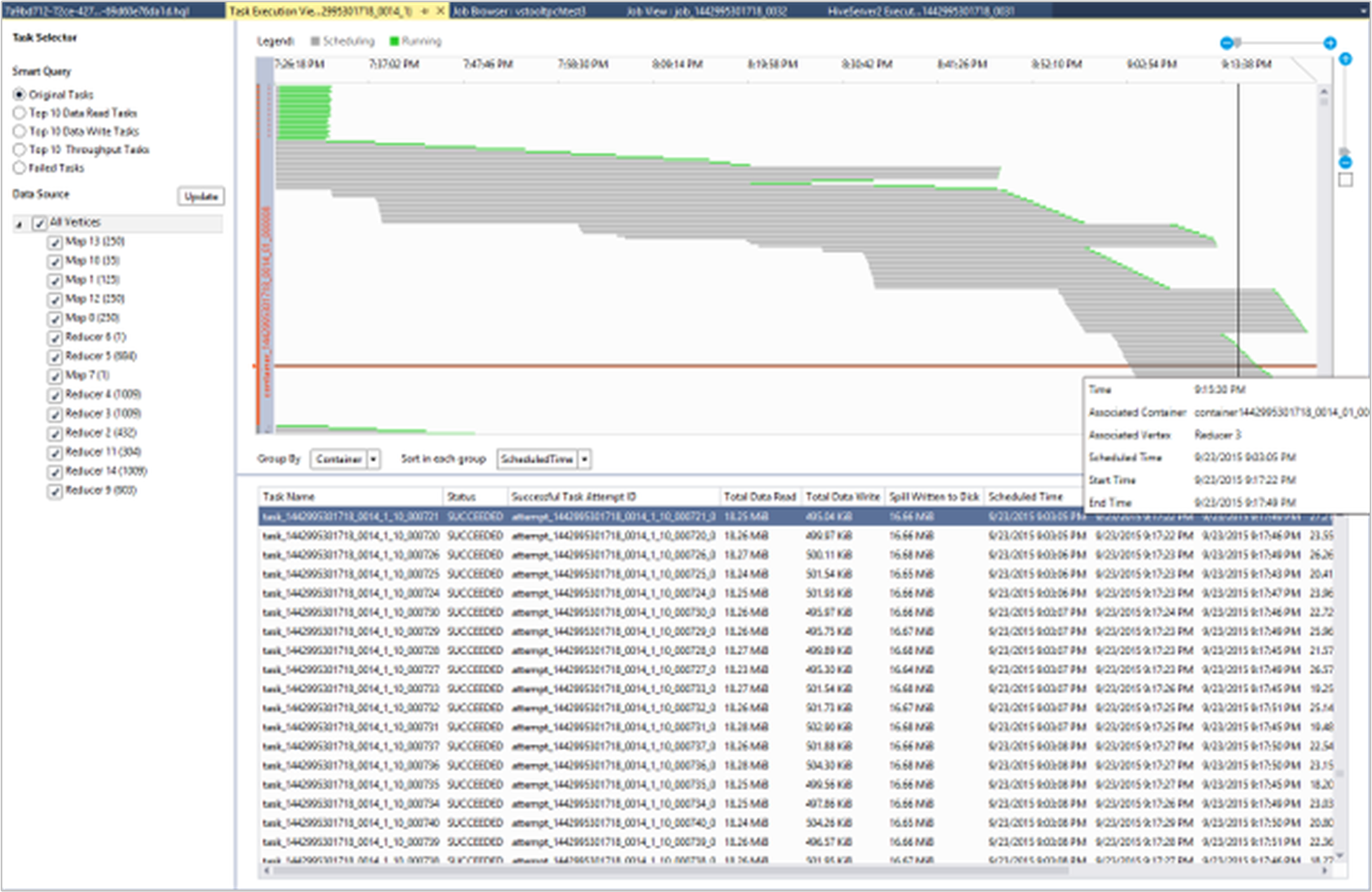
Afficher les détails de l’exécution de la tâche
Dans le graphique du travail, vous pouvez sélectionner Détail de l’exécution de la tâche pour obtenir des informations structurées et visuelles sur les travaux Hive. Vous pouvez aussi obtenir plus de détails de la tâche. En cas de problèmes de performances, vous pouvez utiliser la vue pour obtenir plus d’informations sur le problème. Par exemple, vous pouvez récupérer des informations sur le fonctionnement de chaque tâche, et des informations détaillées sur chaque tâche (lecture et écriture de données, heure de planification, de début et de fin, etc). Utilisez ces informations pour ajuster les configurations de tâche ou l’architecture du système basée sur les informations affichées.
Afficher les tâches Hive
Vous pouvez afficher les requêtes, la sortie, le journal d’activité et le journal Yarn des tâches Hive.
Dans la version la plus récente des outils, vous pouvez consulter le contenu de vos tâches Hive en collectant et en exposant les journaux d'activité YARN. Le journal YARN peut vous aider à examiner les problèmes de performances. Pour plus d’informations sur la collection des journaux d’activité YARN par HDInsight, consultez Accéder aux journaux d’activité d’applications YARN Apache Hadoop.
Pour afficher les tâches Hive :
Cliquez avec le bouton droit sur un cluster HDInsight, puis sélectionnez Afficher les travaux.
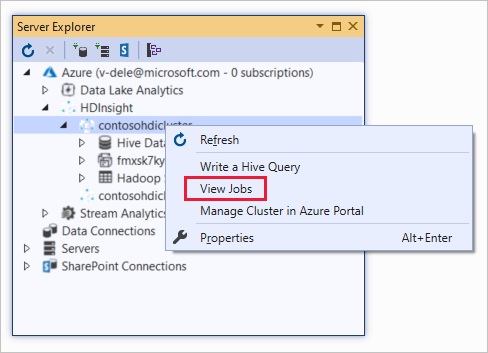
Une liste des tâches Hive exécutées sur le cluster s’affiche.
Sélectionnez une tâche. Dans la fenêtre Résumé de la tâche Hive, sélectionnez l’un des liens suivants :
- Requête de tâche
- Sortie de travail
- Journal de la tâche
- Journal Yarn
Exécuter des scripts Apache Pig
Dans la barre de menus, choisissez Fichier>Nouveau>Projet.
Dans la fenêtre Démarrer, sélectionnez la zone de recherche et entrez Pig. Sélectionnez ensuite Application Pig, puis Suivant.
Dans la fenêtre Configurer votre nouveau projet, entrez un Nom de projet, sélectionnez ou créez un Emplacement pour le projet. Sélectionnez ensuite Créer.
Dans le volet Explorateur de solutions IDE, double-cliquez sur le script Script.pig pour l’ouvrir.
Commentaires et problèmes connus
Un problème où les résultats démarrés avec des valeurs null ne s’affichaient pas a été résolu. Si vous êtes bloqué sur ce problème, contactez le support technique.
Le script HQL créé par Visual Studio est encodé selon le paramètre régional de l'utilisateur. Le script ne s’exécute pas correctement si vous le chargez dans un cluster en tant que fichier binaire.
Étapes suivantes
Dans cet article, vous avez appris à utiliser le package Data Lake Tools pour Visual Studio pour vous connecter à des clusters HDInsight de Visual Studio. Vous avez aussi appris à exécuter une requête Hive.