Écritures accélérées pour Apache HBase dans Azure HDInsight
Cet article fournit des informations sur la fonctionnalité Écritures accélérées pour Apache HBase dans Azure HDInsight et explique comment elle peut être utilisée efficacement pour améliorer les performances en écriture. Écritures accélérées utilise les disques managés SSD Premium Azure pour améliorer les performances du journal WAL (write-ahead log) Apache HBase. Pour en savoir plus sur Apache HBase, consultez Nouveautés d’Apache HBase dans Azure HDInsight.
Vue d’ensemble de l’architecture HBase
Dans HBase, une ligne se compose d’une ou plusieurs colonnes et est identifiée par une clé de ligne. Plusieurs lignes constituent une table. Les colonnes contiennent des cellules, qui sont des versions horodatées de la valeur de cette colonne. Les colonnes sont regroupées en familles de colonnes, et toutes les colonnes d’une même famille sont stockées dans des fichiers de stockage appelés HFiles.
Dans HBase, les régions servent à équilibrer la charge de traitement des données. HBase commence par stocker les lignes d’une table dans une seule région. Les lignes sont réparties sur plusieurs régions à mesure que le volume de données de la table augmente. Les serveurs de région peuvent gérer les demandes de plusieurs régions.
Journal WAL (write-ahead log) pour Apache HBase
HBase commence par écrire des mises à jour de données sur un type de journal de validation appelé journal WAL (write-ahead log). Une fois la mise à jour stockée dans le journal WAL (write-ahead log), celle-ci est écrite dans MemStore en mémoire. Quand les données en mémoire atteignent sa capacité maximale, celles-ci sont écrites sur le disque sous forme de HFile.
Si un RegionServer se bloque ou devient indisponible avant que MemStore ne soit vidé, le journal WAL (write-ahead log) peut être utilisé pour réexécuter les mises à jour. En l’absence de journal WAL, si un RegionServer tombe en panne avant d’avoir vidé les mises à jour dans un HFile, toutes ces mises à jour sont perdues.
Fonctionnalité Écritures accélérées pour Apache HBase dans Azure HDInsight
La fonctionnalité Écritures accélérées résout le problème des latences en écriture plus élevées en raison de l’utilisation des journaux WAL (write-ahead log) stockés dans le cloud. La fonctionnalité Écritures accélérées pour les clusters HDInsight Apache HBase associe des disques SSD managés Premium à chaque serveur de région (nœud Worker). Les journaux WAL (write-ahead log) sont ensuite écrits sur le système de fichiers DFS hadoop montés sur ces disques SSD managés Premium et non pas dans le stockage cloud. Les disques managés Premium utilisent des disques SSD et offrent d’excellentes performances d’E/S, ainsi qu’une tolérance de panne. Contrairement aux disques non managés, si une unité de stockage tombe en panne, elle n’affecte pas les autres unités de stockage du même groupe à haute disponibilité. Par conséquent, les disques managés offrent une faible latence en écriture et une meilleure résilience pour vos applications. Pour en savoir plus sur les disques managés Azure, consultez Présentation des disques managés Azure.
Comment activer la fonctionnalité Écritures accélérées pour HBase dans HDInsight
Pour créer un nouveau cluster HBase avec la fonctionnalité Écritures accélérées, suivez les étapes de Configurer des clusters dans HDInsight. Sous l’onglet De base, sélectionnez le type de cluster HBase, spécifiez une version du composant, puis cliquez sur la case à cocher en regard de Activer les écritures accélérées HBase. Puis, passez aux étapes restantes pour la création du cluster.
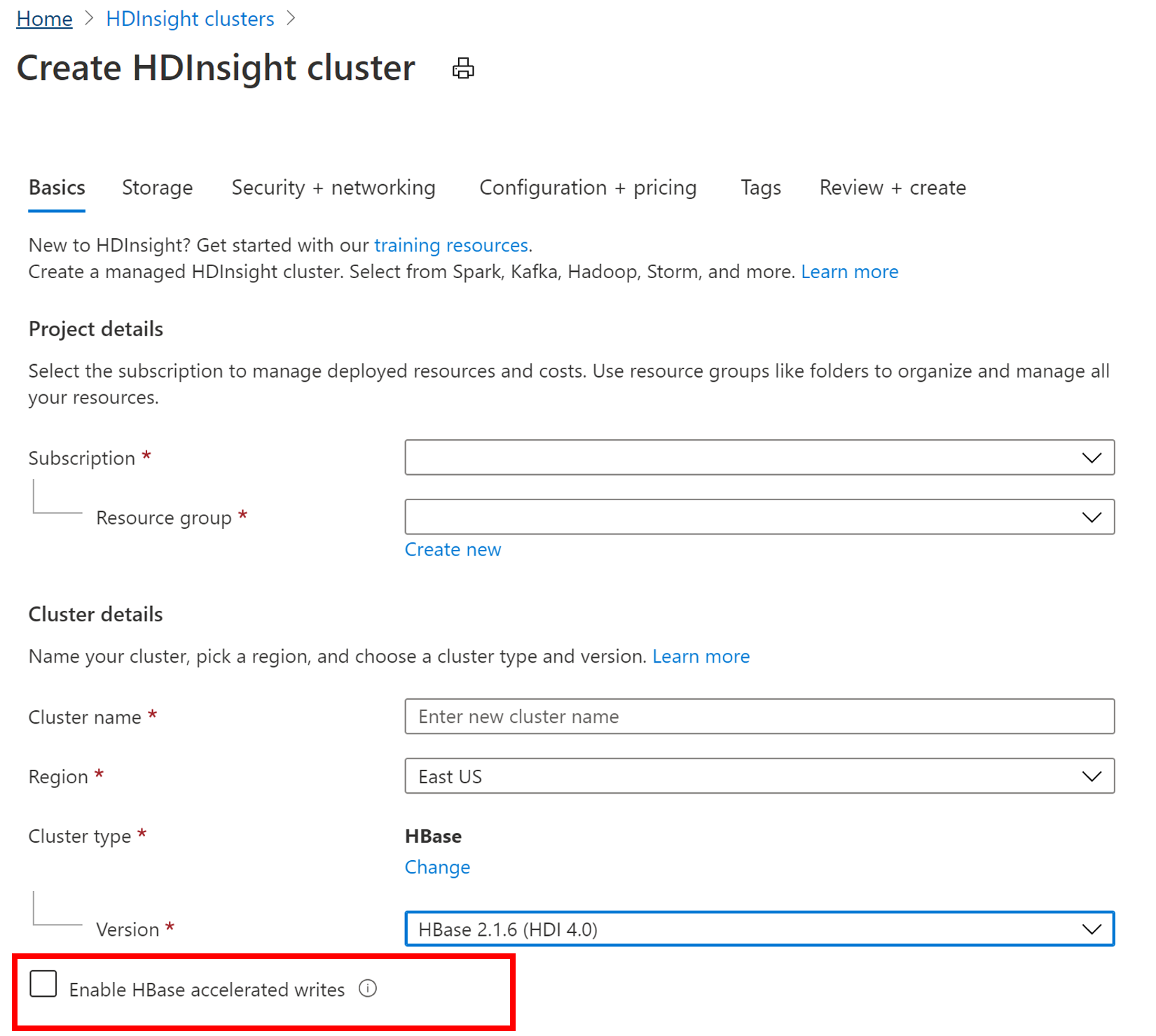
Vérifier que la fonctionnalité Écritures accélérées a été activée
Vous pouvez utiliser la Portail Azure pour vérifier si la fonctionnalité Écritures accélérées est activée sur un cluster HBASE.
- Recherchez votre cluster HBASE dans le Portail Azure.
- Sélectionnez le panneau Taille du cluster .
- Les disques Premium par nœud Worker s’affichent.
Mise à l’échelle des clusters HBASE
Pour préserver la durabilité des données, créez un cluster comportant au moins trois nœuds Worker. Une fois créé, vous ne pourrez plus réduire ne nombre de nœuds Worker du cluster.
Videz ou désactivez vos tables HBase avant de supprimer le cluster, afin de ne pas perdre les données du journal WAL (write-ahead log).
flush 'mytable'
disable 'mytable'
Suivez des étapes similaires lors de réduction d’échelle de votre cluster : videz vos tables et désactivez-les pour arrêter les données entrantes. Vous ne pouvez pas faire descendre en puissance votre cluster à moins de trois nœuds.
Ces étapes garantissent la réussite de la réduction d’échelle et évitent la possibilité qu’un namenode passe en mode sans échec en raison de la présence de fichiers temporaires ou sous-répliqués.
Si votre namenode passe en mode sans échec après un scale-down, utilisez des commandes HDFS pour re-répliquer les blocs sous-répliqués et sortir HDFS du mode sans échec. Cette re-réplication vous permettra de redémarrer HBase avec succès.
Étapes suivantes
- Documentation officielle relative à Apache HBase sur la fonctionnalité Journal WAL (write ahead log)
- Pour mettre à niveau votre cluster HDInsight Apache HBase de manière à utiliser la fonctionnalité Écritures accélérées, consultez Effectuer la migration d’un cluster Apache HBase vers une nouvelle version.