Tutoriel : Utiliser Apache HBase dans Azure HDInsight
Ce didacticiel montre comment créer un cluster Apache HBase dans Azure HDInsight, créer des tables HBase et les interroger à l’aide d’Apache Hive. Pour obtenir des informations générales sur HBase, voir Vue d’ensemble de HDInsight HBase.
Dans ce tutoriel, vous allez apprendre à :
- Créer un cluster Apache HBase
- Créer des tables HBase et insérer des données
- Utiliser Apache Hive pour interroger Apache HBase
- Utilisation des API REST HBase à l’aide de Curl
- Vérification du statut du cluster
Prérequis
Un client SSH. Pour plus d’informations, consultez Se connecter à HDInsight (Apache Hadoop) à l’aide de SSH.
Bash. Les exemples de cet article utilisent l’interpréteur de commandes Bash sur Windows 10 pour les commandes curl. Pour connaître les étapes d’installation, consultez Guide d’installation de sous-systèmes Windows pour Linux sur Windows 10. Vous pouvez également utiliser les autres interpréteurs de commandes Unix. Les exemples avec curl, avec de légères modifications, peuvent fonctionner sur une invite de commandes Windows. Vous pouvez utiliser l’applet de commande Windows PowerShell Invoke-RestMethod.
Créer un cluster Apache HBase
La procédure suivante utilise un modèle Azure Resource Manager pour créer un cluster HBase. Le modèle crée également le compte de Stockage Azure par défaut dépendant. Pour comprendre les paramètres utilisés dans la procédure et d’autres méthodes de création de cluster, consultez Création de clusters Hadoop basés sur Linux dans HDInsight.
Sélectionnez l’image suivante pour ouvrir le modèle dans le portail Azure. Ce modèle se trouve dans les modèles de démarrage rapide Azure.

Dans la boîte de dialogue Déploiement personnalisé, entrez les valeurs suivantes :
Propriété Description Abonnement Sélectionnez l’abonnement Azure utilisé pour créer le cluster. Resource group Créez un groupe d’administration Azure Resource ou utilisez un groupe existant. Emplacement Spécifiez l’emplacement du groupe de ressources. ClusterName Entrez un nom pour le cluster HBase. ID de connexion et mot de passe du cluster Le nom de connexion par défaut est admin.Nom d’utilisateur et mot de passe SSH Le nom d’utilisateur par défaut est sshuser.Tous les autres paramètres sont facultatifs.
Chaque cluster possède une dépendance de compte Stockage Azure. Après avoir supprimé un cluster, les données restent dans le compte de stockage. Le nom du compte de stockage par défaut du cluster est le nom du cluster suivi du suffixe « store ». Il est codé en dur dans la section des variables du modèle.
Sélectionnez J’accepte les conditions générales mentionnées ci-dessus, puis sélectionnez Acheter. La création d’un cluster prend environ 20 minutes.
Après la suppression d’un cluster HBase, vous pouvez créer un autre cluster HBase à l’aide du même conteneur d’objets blob par défaut. Le nouveau cluster utilise les tables HBase créées dans le cluster d’origine. Pour éviter toute incohérence, nous vous recommandons de désactiver les tables HBase avant de supprimer le cluster.
Créer des tables et insérer des données
Vous pouvez utiliser SSH pour vous connecter à des clusters HBase, puis utiliser Apache HBase Shell pour créer des tables HBase, et insérer et interroger des données.
Pour la plupart des utilisateurs, les données s’affichent sous la forme tabulaire :

Dans HBase (une implémentation de Cloud BigTable), certaines données ont l’aspect suivant :

Pour utiliser l’interpréteur de commandes HBase
Utilisez la commande
sshpour vous connecter à votre cluster HBase. Modifiez la commande suivante en remplaçantCLUSTERNAMEpar le nom de votre cluster, puis entrez la commande :ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUtilisez la commande
hbase shellpour démarrer l'interpréteur de commandes interactif HBase. Entrez la commande suivante dans votre connexion SSH :hbase shellUtilisez la commande
createpour créer une table HBase avec deux familles de colonnes. Les noms de table et de colonne respectent la casse. Entrez la commande suivante :create 'Contacts', 'Personal', 'Office'Utilisez la commande
listpour répertorier toutes les tables contenues dans HBase. Entrez la commande suivante :listUtilisez la commande
putpour insérer des valeurs dans une colonne et sur une ligne spécifiées d'une table particulière. Entrez les commandes suivantes :put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Utilisez la commande
scanpour analyser et renvoyer les données de la tableContacts. Entrez la commande suivante :scan 'Contacts'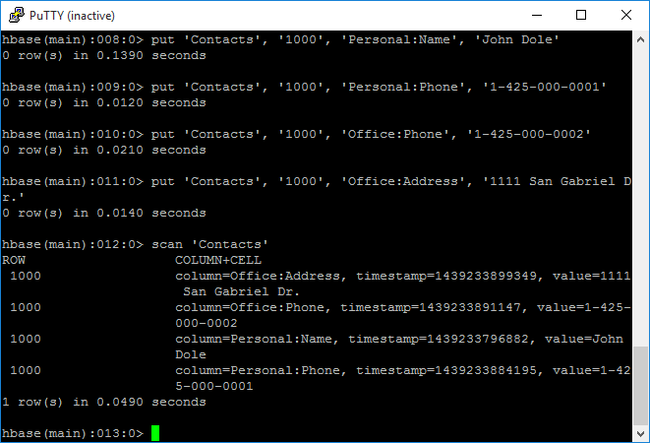
Utilisez la commande
getpour extraire le contenu d'une ligne. Entrez la commande suivante :get 'Contacts', '1000'Comme il n’y a qu’une seule ligne, vous obtenez des résultats semblables à ceux obtenus avec la commande
scan.Pour plus d'informations sur le schéma de la table HBase, consultez Introduction à la conception de schémas Apache HBase. Pour plus de commandes HBase, consultez le Guide de référence Apache HBase.
Utilisez la commande
exitpour arrêter l'interpréteur de commandes interactif HBase. Entrez la commande suivante :exit
Pour charger des données en bloc dans la table de contacts HBase
HBase propose plusieurs méthodes pour charger des données dans des tables. Pour en savoir plus, consultez la rubrique Chargement en bloc.
Vous trouverez un exemple de fichier de données dans un conteneur de blobs public, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. Le contenu du fichier de données est le suivant :
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
Si vous le souhaitez, vous pouvez créer un fichier texte et le télécharger dans votre propre compte de stockage. Pour obtenir des instructions, consultez Charger des données pour des tâches Apache Hadoop dans HDInsight.
Cette procédure utilise la table HBase Contacts créée dans la dernière procédure.
Depuis votre connexion SSH ouverte, exécutez la commande suivante pour transformer le fichier de données en StoreFiles et le stocker sur un chemin d’accès relatif spécifié par
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtExécutez la commande suivante pour charger les données à partir de
/example/data/storeDataFileOutputvers la table HBase :hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsVous pouvez ouvrir l’interpréteur de commandes HBase et utiliser la commande
scanpour répertorier le contenu de la table.
Utiliser Apache Hive pour interroger Apache HBase
Vous pouvez interroger les données des tables HBase à l’aide d’Apache Hive. Dans cette section, vous créez une table Hive qui correspond à la table HBase et l’utilise pour interroger les données de votre table HBase.
Dans votre session SSH ouverte, utilisez la commande suivante pour démarrer Beeline :
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminPour plus d’informations sur Beeline, consultez Utilisation de Hive avec Hadoop dans HDInsight via Beeline.
Exécutez le script HiveQL suivant pour créer une table Hive correspondant à la table HBase. Avant d’exécuter cette instruction, vérifiez que vous avez créé l’exemple de table référencé précédemment dans cet article en utilisant l’interpréteur de commandes HBase.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Exécutez le script HiveQL suivant pour interroger les données dans la table HBase :
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Pour quitter Beeline, utilisez
!exit.Pour quitter votre connexion SSH, utilisez
exit.
Séparer les clusters Hive et HBase
La requête Hive pour accéder aux données HBase n’a pas besoin d’être exécutée à partir du cluster HBase. Tout cluster fourni avec Hive (y compris Spark, Hadoop, HBase ou Interactive Query) peut être utilisé pour interroger des données HBase, à condition que les étapes suivantes soient effectuées :
- Les deux clusters doivent être attachés aux mêmes réseau et sous-réseau virtuels
- Copiez
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlà partir des nœuds principaux du cluster HBase vers les nœuds principaux et les nœuds Worker du cluster Hive.
Clusters sécurisés
Les données HBase peuvent également être interrogées à partir de Hive, au moyen de HBase activé pour ESP :
- Lorsque vous suivez un modèle à plusieurs clusters, les deux clusters doivent être activés pour ESP.
- Pour autoriser Hive à interroger des données HBase, assurez-vous que l’utilisateur
hiveest autorisé à accéder aux données HBase via le plug-in Apache Ranger pour HBase - Lorsque vous utilisez des clusters distincts activés pour ESP, le contenu de
/etc/hostsà partir des nœuds principaux du cluster HBase doit être ajouté à/etc/hostsdes nœuds principaux et des nœuds Worker du cluster Hive.
Remarque
Après la mise à l’échelle d’un des clusters, /etc/hosts doit être ajouté à nouveau
Utiliser l’API REST HBase via Curl
L’API REST est sécurisée à l’aide de l’authentification de base. Vous devrez toujours effectuer les demandes à l’aide du protocole Secure HTTP (HTTPS) pour vous assurer que vos informations d’identification sont envoyées en toute sécurité au serveur.
Pour activer l’API REST HBase dans le cluster HDInsight, ajoutez le script de démarrage personnalisé suivant à la section Action de script. Vous pouvez ajouter le script de démarrage lorsque vous créez le cluster ou après sa création. Pour Type de nœud, sélectionnez Serveurs de région afin de vous assurer que le script s’exécute uniquement dans les serveurs de région HBase. Le script démarre le proxy REST HBase sur le port 8090 sur les serveurs de région.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiPour faciliter l’utilisation, définissez la variable d’environnement. Modifiez les commandes suivantes en remplaçant
MYPASSWORDpar le mot de passe de connexion au cluster. RemplacezMYCLUSTERNAMEpar le nom de votre cluster HBase. Entrez ensuite les commandes.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEUtilisez la commande suivante pour répertorier les tables HBase existantes :
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Utilisez la commande suivante pour créer une table HBase avec deux familles de colonnes :
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vLe schéma est fourni au format JSON.
Utilisez la commande suivante pour insérer des données :
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vEncodez en Base64 les valeurs spécifiées dans le commutateur -d. Dans l’exemple :
MTAwMA==: 1 000
UGVyc29uYWw6TmFtZQ==: Personnel : Nom
Sm9obiBEb2xl: John Dole
false-row-key vous permet d’insérer plusieurs valeurs (par lot).
Utilisez la commande suivante pour obtenir une ligne :
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Remarque
L’analyse via le point de terminaison du cluster n’est pas encore prise en charge.
Pour plus d’informations sur HBase Rest, voir le Guide de référence Apache HBase.
Notes
Thrift n’est pas pris en charge par HBase dans HDInsight.
Lorsque vous utilisez Curl ou toute autre communication REST avec WebHCat, vous devez authentifier les requêtes en fournissant le nom d'utilisateur et le mot de passe de l’administrateur du cluster HDInsight. Vous devez également utiliser le nom du cluster dans l’URI (Uniform Resource Identifier) utilisé pour envoyer les demandes au serveur :
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Vous devez recevoir une réponse similaire à celle-ci :
{"status":"ok","version":"v1"}
Vérification du statut du cluster
HBase dans HDInsight est livré avec une interface utilisateur web pour la surveillance des clusters. Elle vous permet de demander des statistiques ou des informations sur les régions.
Pour accéder à l’interface utilisateur principale HBase
Connectez-vous à l’interface utilisateur web d’Ambari sur
https://CLUSTERNAME.azurehdinsight.net, oùCLUSTERNAMEest le nom de votre cluster HBase.Dans le menu de gauche, sélectionnez HBase.
Sélectionnez Liens rapides en haut de la page, pointez vers le lien de nœud Zookeeper actif, puis sélectionnez HBase Master UI. L’interface utilisateur est ouverte dans un autre onglet de navigateur :
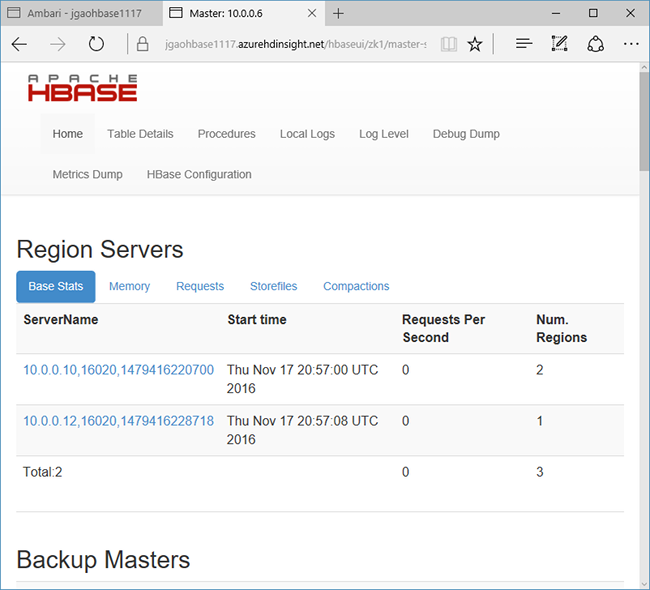
L’interface utilisateur principale HBase comporte les sections suivantes :
- serveurs de région
- serveurs de sauvegarde
- tables
- tâches
- attributs logiciels
Recréation de cluster
Après la suppression d’un cluster HBase, vous pouvez créer un autre cluster HBase à l’aide du même conteneur d’objets blob par défaut. Le nouveau cluster utilise les tables HBase créées dans le cluster d’origine. Toutefois, pour éviter toute incohérence, nous vous recommandons de désactiver les tables HBase avant de supprimer le cluster.
Vous pouvez utiliser la commande HBase disable 'Contacts'.
Nettoyer les ressources
Si vous ne comptez pas continuer à utiliser cette application, effectuez les étapes suivantes pour supprimer le cluster HBase que vous avez créé :
- Connectez-vous au portail Azure.
- Dans la zone Recherche située en haut, tapez HDInsight.
- Sous Services, sélectionnez Clusters HDInsight.
- Dans la liste des clusters HDInsight qui s’affiche, cliquez sur les points de suspension ... à côté du cluster que vous avez créé pour ce tutoriel.
- Cliquez sur Supprimer. Cliquez sur Oui.
Étapes suivantes
Dans ce tutoriel, vous avez appris à créer un cluster Apache HBase. Vous avez aussi découvert comment créer des tables et à afficher les données contenues dans ces tables à partir de l’interpréteur de commandes HBase. Vous avez également vu comment utiliser une requête Hive pour interroger les données des tables HBase, Et comment utiliser l’API REST C# HBase pour créer une table HBase et en extraire les données. Pour plus d'informations, consultez les rubriques suivantes :