Détecter un problème de travail lent ou défaillant sur un cluster HDInsight
En cas de ralentissement ou d’échec d’une application traitant des données sur un cluster HDInsight avec un code d’erreur, vous disposez de plusieurs options de résolution des problèmes. Si l’exécution de vos travaux prend plus de temps que prévu ou si vous constatez généralement des temps de réponse assez longs, il est possible que ces problèmes soient imputables à des défaillances en amont à de votre cluster (par exemple, les services sur lesquels s’exécute le cluster). Mais une mise à l’échelle insuffisante est la cause la plus courante de ces ralentissements. Lorsque vous créez un cluster HDInsight, sélectionnez les tailles de machine virtuelle appropriées.
Pour diagnostiquer un cluster lent ou défaillant, essayez de recueillir des informations sur tous les aspects de l’environnement, notamment les services Azure associés, la configuration du cluster ou encore les informations relatives à l’exécution du travail. Pour diagnostiquer les problèmes, le mieux est d’essayer de reproduire l’état d’erreur sur un autre cluster.
- Étape 1 : recueillir des données sur le problème.
- Étape 2 : valider l’environnement du cluster HDInsight.
- Étape 3 : contrôler l’état d’intégrité de votre cluster.
- Étape 4 : examiner la pile et les versions de l’environnement.
- Étape 5 : examiner les fichiers journaux du cluster.
- Étape 6 : vérifier les paramètres de configuration.
- Étape 7 : reproduire la défaillance sur un autre cluster.
Étape 1 : recueillir des données sur le problème
HDInsight fournit de nombreux outils que vous pouvez utiliser pour identifier et résoudre les problèmes liés aux clusters. Les étapes suivantes vous guident tout au long de l’utilisation de ces outils et vous fournissent des suggestions pour localiser le problème.
Identifier le problème
Pour identifier le problème, posez-vous les questions suivantes :
- Que devait-il normalement se passer ? Que s’est-il passé en réalité ?
- Quelle a été la durée d’exécution du processus ? Pendant combien de temps aurait-il dû s’exécuter ?
- Mes tâches se sont-elles toujours exécutées lentement sur ce cluster ? Leur exécution était-elle plus rapide sur un autre cluster ?
- À quel moment ce problème est-il initialement apparu ? À quelle fréquence s’est-il ensuite produit ?
- Ai-je modifié quelque chose dans la configuration de mon cluster ?
Détails du cluster
Voici quelques informations importantes à propos du cluster :
- Nom du cluster.
- Région du cluster : vérifiez les pannes dans la région.
- Type et version du cluster HDInsight.
- Type et nombre d’instances HDInsight spécifiés pour les nœuds de tête et de travail.
Le portail Azure peut fournir les informations suivantes :

Vous pouvez également utiliser Azure CLI :
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Une autre option consiste à utiliser PowerShell. Pour en savoir plus, consultez la page Gestion des clusters Apache Hadoop dans HDInsight au moyen d’Azure PowerShell.
Étape 2 : valider l’environnement du cluster HDInsight
Chaque cluster HDInsight s’appuie sur divers services Azure ainsi que sur des logiciels open source tels que Apache HBase et Apache Spark. Les clusters HDInsight peuvent également appeler d’autres services Azure, comme les réseaux virtuels Azure. Une défaillance de cluster peut être liée soit à l’un des services en cours d’exécution sur votre cluster, soit à un service externe. Un changement de configuration d’un service de cluster peut également provoquer une défaillance du cluster.
Détails sur le service
- Vérifiez les versions de bibliothèques open source.
- Recherchez les interruptions de service Azure.
- Recherchez les limites d’utilisation des services Azure.
- Vérifiez la configuration de sous-réseau du réseau virtuel Microsoft Azure.
Vérifier les paramètres de configuration du cluster avec l’interface utilisateur Ambari
Apache Ambari assure la gestion et la surveillance d’un cluster HDInsight grâce à une interface utilisateur web et à une API REST. Ambari est inclus sur les clusters HDInsight sous Linux. Sélectionnez le volet Tableau de bord du cluster sur la page HDInsight du portail Azure. Sélectionnez le volet Tableau de bord du cluster HDInsight pour ouvrir l’interface utilisateur Ambari, puis entrez les informations d’identification utilisée pour vous connecter au cluster.
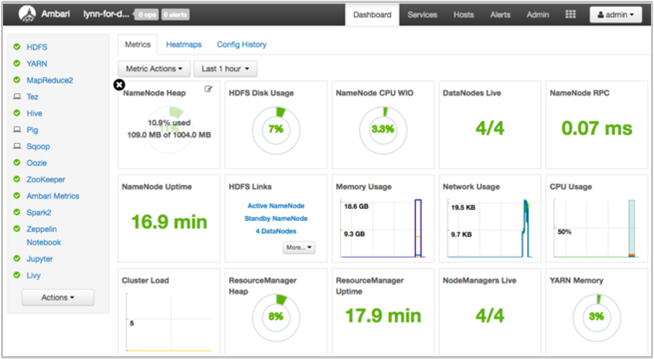
Pour ouvrir une liste de vues du service, sélectionnez Vues Ambari sur la page du portail Azure. Cette liste varie selon les bibliothèques installées. Elle peut contenir par exemple YARN Queue Manager, Hive View et Tez View. Sélectionnez le lien d’un service pour afficher des informations sur la configuration et le service.
Rechercher les interruptions de service Azure
HDInsight s’appuie sur plusieurs services Azure. Il exécute des serveurs virtuels dans Azure HDInsight, stocke des données et des scripts sur le stockage Blob Azure ou sur Azure Data Lake Storage, et indexe des fichiers journaux dans le stockage Table Azure. Bien que rares, les perturbation de ces services peuvent entraîner des problèmes dans HDInsight. Si votre cluster subit des ralentissements ou défaillances inattendus, consultez le Tableau de bord d’état Azure. L’état de chaque service est indiqué par région. Vérifiez la région de votre cluster, mais également les régions de tous les services associés.
Rechercher les limites d’utilisation des services Azure
Si vous démarrez un cluster volumineux ou si vous avez lancé simultanément un grand nombre de clusters, un cluster peut échouer si vous avez dépassé une limite de service Azure. Les limites de service varient selon votre abonnement Azure. Pour plus d’informations, consultez Abonnement Azure et limites, quotas et contraintes de service. Vous pouvez demander à Microsoft d’augmenter le nombre de ressources HDInsight disponibles (par exemple, les cœurs de machines virtuelles et les instances de machines virtuelles) en soumettant une demande d’augmentation des quotas de processeurs virtuels pour Resource Manager.
Vérifier la version
Comparez la version de votre cluster à la dernière version de HDInsight. Chaque version de HDInsight inclut des améliorations, par exemple de nouvelles applications ou fonctionnalités, des correctifs et des corrections de bogues. Il est possible que le problème que rencontre votre cluster a été résolu dans la dernière version. Si possible, exécutez à nouveau votre cluster en utilisant la dernière version de HDInsight et des bibliothèques associées tels que Apache HBase, Apache Spark ou autre.
Redémarrer vos services de cluster
Si votre cluster subit des ralentissements, pensez à redémarrer vos services par le biais de l’interface utilisateur Ambari ou d’Azure Classic CLI. Le cluster peut rencontrer des erreurs transitoires, auquel cas un redémarrage offre le moyen le plus rapide pour stabiliser votre environnement et éventuellement en améliorer les performances.
Étape 3 : contrôler l’état d’intégrité de votre cluster
Les clusters HDInsight sont composées de différents types de nœuds en cours d’exécution sur des instances de machine virtuelle. Chaque nœud peut être analysé pour identifier des problèmes de ressources insuffisantes, des problèmes de connectivité réseau et d’autres problèmes susceptibles de ralentir le cluster. Chaque cluster contient deux nœuds principaux et la plupart des types de cluster comportent à la fois des nœuds de travail et des nœuds de périphérie.
Vous trouverez une description des différents nœuds utilisés par chaque type de cluster dans la section Configurer des clusters dans HDInsight avec Apache Hadoop, Apache Spark, Apache Kafka, etc.
Les sections suivantes vous expliquent comment vérifier l’intégrité de chaque nœud et du cluster global.
Obtenir un instantané de l’intégrité du cluster à l’aide du tableau de bord de l’interface utilisateur Ambari
Le tableau de bord de l’interface utilisateur Ambari (https://<clustername>.azurehdinsight.net) fournit une vue d’ensemble de l’intégrité du cluster (temps de fonctionnement, utilisation de la mémoire, du réseau et du processeur, utilisation du disque HDFS, etc.). Utilisez la section Hôtes d’Ambari pour afficher les ressources au niveau d’un hôte. Vous pouvez également arrêter et redémarrer les services.
Vérifier votre service WebHCat
Il arrive souvent que les travaux Apache Hive, Apache Pig ou Apache Sqoop échouent en raison d’une défaillance du service WebHCat (ou Templeton). WebHCat est une interface REST qui permet d’exécuter un travail à distance, tel que Hive, Pig, Scoop et MapReduce. WebHCat convertit les demandes de soumission de travail en applications YARN Apache Hadoop et retourne un état dérivé de l’état de l’application YARN. Les sections suivantes décrivent les codes d’état HTTP WebHCat courants.
BadGateway (code d’état 502)
Ce code est un message générique provenant de nœuds de la passerelle et représente le code d’état d’échec le plus courant. Il peut être imputé à un arrêt du service WebHCat sur le nœud principal actif. Pour vérifier cette possibilité, utilisez la commande CURL suivante :
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari affiche une alerte indiquant les hôtes sur lesquels le service WebHCat est arrêté. Vous pouvez tenter de rétablir le service WebHCat en redémarrant le service sur son hôte.
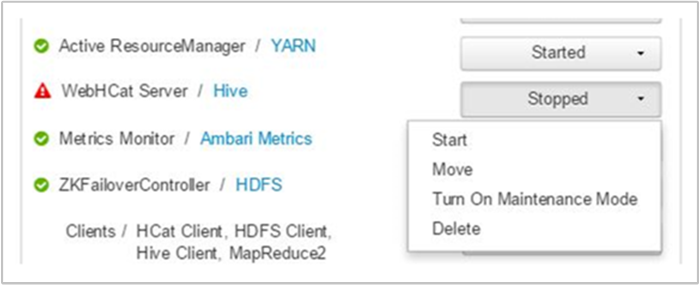
Si un serveur WebHCat ne répond toujours pas, consultez le journal des opérations pour vérifier les messages d’échec. Pour plus d’informations, vérifiez les fichiers stderr et stdout référencés sur le nœud.
Délai d’expiration de WebHCat
Une passerelle HDInsight renvoie 502 BadGateway lorsque les réponses dépassent un délai de deux minutes. WebHCat interroge les services YARN pour connaître l’état des travaux. Si YARN met plus de deux minutes à répondre, cette demande peut expirer.
Dans ce cas, consultez les journaux d’activité suivants dans le répertoire /var/log/webhcat :
- webhcat.log est le journal d’activité log4j sur lequel le serveur écrit des fichiers journaux
- webhcat-console.log est le stdout du serveur au démarrage
- webhcat-console-error.log est le stderr du processus serveur
Notes
Chaque webhcat.log est renouvelé tous les jours, ce qui génère des fichiers nommés webhcat.log.YYYY-MM-DD. Sélectionnez le fichier correspondant à l’intervalle de temps que vous examinez.
Les sections suivantes décrivent les causes possibles de l’expiration des délais d’attente WebHCat.
Délai d’expiration au niveau de WebHCat
Lorsque WebHCat est chargé et que plus de 10 sockets sont ouverts, il met davantage de temps à établir de nouvelles connexions de socket, ce qui peut entraîner un délai d’attente. Pour répertorier les connexions réseau vers et depuis WebHCat, utilisez netstat sur le nœud principal actif actuel :
netstat | grep 30111
30111 est le port qu’écoute WebHCat. Le nombre de sockets ouverts doit être inférieur à 10.
Si aucun socket n’est ouvert, la commande précédente ne produit aucun résultat. Pour vérifier si Templeton est activé et à l’écoute sur le port 30111, utilisez :
netstat -l | grep 30111
Délai d’expiration au niveau de YARN
Templeton appelle YARN pour exécuter des travaux, et la communication entre Templeton et YARN peut entraîner un délai d’attente.
Au niveau de YARN, il existe deux types de délais d’expiration :
L’envoi d’un travail YARN peut durer suffisamment longtemps pour provoquer l’expiration du délai d’attente.
Si vous ouvrez le fichier journal
/var/log/webhcat/webhcat.loget que vous recherchez un « travail en file d’attente », vous pouvez voir plusieurs entrées associées à une durée d’exécution trop longue (> 2000 ms), où les entrées indiquent une augmentation des temps d’attente.La durée des travaux en file d’attente continue d’augmenter car la vitesse à laquelle les nouveaux travaux sont envoyés est supérieure à la fréquence d’exécution des anciens travaux. Une fois que la mémoire de YARN est utilisée à 100 %,
joblauncher queuene peut plus emprunter de capacité à la file d’attente par défaut. Par conséquent, plus aucun nouveau travail ne peut être accepté dans la file d'attente du lanceur de travaux. Ce comportement peut provoquer un allongement des temps d’attente et provoquer une erreur de délai d’expiration, qui est généralement suivie de nombreuses autres erreurs du même type.L’illustration suivante montre la file d’attente du lanceur de travaux à un taux d’utilisation de 714,4 %. Ce taux est acceptable tant qu’il reste de la capacité disponible à emprunter à la file d’attente par défaut. Toutefois, lorsque le cluster est entièrement utilisé et que la mémoire YARN a atteint 100 % de sa capacité, les nouveaux travaux doivent attendre, ce qui finit par provoquer une expiration des délais d’attente.

Il existe deux façons de résoudre ce problème : vous pouvez soit réduire la vitesse d’envoi de nouveaux travaux, soit relever la vitesse de la consommation des anciens travaux en augmentant la capacité du cluster.
Le traitement YARN peut prendre beaucoup de temps, ce qui peut entraîner des délais d’attente.
Répertorier tous les travaux : ce type d’appel prend beaucoup de temps. Cet appel énumère les applications à partir du gestionnaire des ressources YARN, et pour chaque application exécutée, récupère l’état auprès de YARN JobHistoryServer. Cet appel peut expirer si le nombre de travaux atteint une valeur importante.
Répertorier les travaux de plus de sept jours : HDInsight YARN JobHistoryServer est configuré pour conserver les informations relatives aux travaux exécutés pendant une durée de sept jours (valeur
mapreduce.jobhistory.max-age-ms). Une tentative d’énumération des travaux supprimés conduit à l’expiration du délai d’attente.
Pour diagnostiquer ces problèmes :
- Déterminez l’intervalle de temps UTC pour résoudre les problèmes
- Sélectionnez le ou les fichier(s)
webhcat.logappropriés - Recherchez des messages d’avertissement et d’erreur pendant cette période
Autres défaillances de WebHCat
Code d’état HTTP 500
Lorsque WebHCat renvoie un code d’état 500, le message d’erreur contient généralement des détails relatifs à l’échec. Sinon, examinez
webhcat.logpour rechercher d’éventuels messages d’avertissement et d’erreur.Échecs des travaux
Il peut arriver que les interactions avec WebHCat réussissent, mais que les travaux échouent.
Templeton récupère la sortie de la console de travail en tant que
stderrdansstatusdir, ce qui est souvent utile pour le dépannage.stderrcontient l’identifiant d’application YARN de la requête réelle.
Étape 4 : examiner la pile et les versions de l’environnement
La page Pile et version de l’interface utilisateur Ambari fournit des informations sur la configuration des services du cluster et sur l’historique de version des services. Des versions incorrectes de la bibliothèque de services Hadoop peuvent être une cause de défaillance du cluster. Dans l’interface utilisateur Ambari, sélectionnez le menu Admin, puis Piles et versions. Sélectionnez l’onglet Versions sur la page pour afficher des informations sur la version du service :
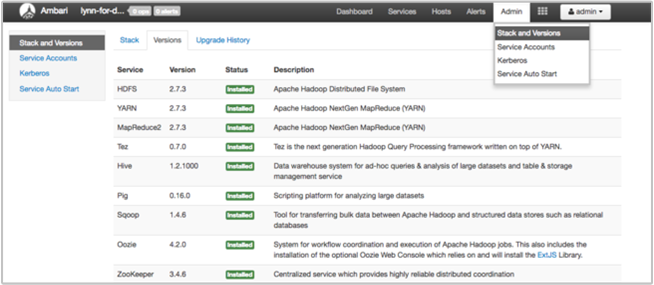
Étape 5 : examiner les fichiers journaux
De nombreux types de fichiers journaux d’activité sont générés à partir des nombreux services et composants qui composent un cluster HDInsight. Les fichiers journaux WebHCat ont été décrits précédemment. Il existe d’autres fichiers journaux utiles que vous pouvez examiner pour réduire les problèmes liés à votre cluster, comme décrit ci-dessous.
Les clusters HDInsight sont constitués de plusieurs nœuds, dont la plupart sont chargés d’exécuter les travaux soumis. Les travaux s’exécutent simultanément, mais les fichiers journaux peuvent uniquement afficher des résultats de façon linéaire. HDInsight exécute de nouvelles tâches, en mettant d’abord fin à celles qui ne parviennent pas à s’exécuter. Tous ces activités sont consignées dans les fichiers
stderretsyslog.Les fichiers journaux d’actions de script indiquent les erreurs ou les changements de configuration inattendus pendant le processus de création de votre cluster.
Les journaux d’activité d’étape Hadoop identifient les travaux Hadoop lancés dans le cadre d’une étape contenant des erreurs.
Vérifier les journaux d’activité d’actions de script
Les actions de script HDInsight exécutent des scripts sur le cluster manuellement ou à l’intervalle spécifié. Par exemple, des actions de script peuvent être utilisées pour installer des logiciels supplémentaires sur le cluster ou pour modifier les paramètres de configuration à partir des valeurs par défaut. La vérification des journaux d’activité d’actions de script peut donnent une idée des erreurs qui se sont produites pendant l’installation et la configuration du cluster. Vous pouvez consulter l’état d’une action de script en sélectionnant le bouton ops dans l’interface utilisateur Ambari, ou en accédant aux journaux d’activité à partir du compte de stockage par défaut.
Les journaux d’activité d’actions de script se trouvent dans le répertoire \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE.
Afficher les journaux d’activité HDInsight à l’aide des liens rapides d’Ambari
L’interface utilisateur HDInsight Ambari comprend un certain nombre de sections Liens rapides. Pour accéder aux liens vers les journaux d’un service donné de votre cluster HDInsight, ouvrez l’interface utilisateur Ambari de votre cluster, puis sélectionnez le lien du service dans la liste située à gauche. Sélectionnez la liste déroulante Liens rapides, puis le nœud HDInsight qui vous intéresse, et sélectionnez le lien vers le journal correspondant.
Par exemple, pour les journaux d’activité HDFS :
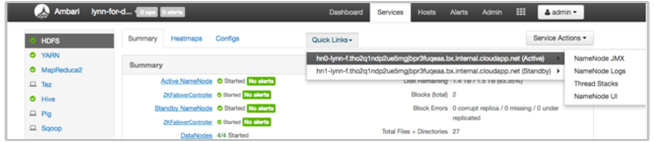
Afficher les fichiers journaux générés par Hadoop
Un cluster HDInsight génère des fichiers journaux d’activité qui sont écrits dans les tables Azure et dans le stockage Blob Azure. YARN crée ses propres journaux d’activité d’exécution. Pour plus d’informations, consultez la rubrique Gérer les journaux d’activité pour un cluster HDInsight.
Examiner les dumps de tas
Les dumps de tas contiennent un instantané de la mémoire de l’application, y compris les valeurs des variables à ce moment précis, ce qui peut être utile pour diagnostiquer des problèmes qui se produisent lors de l’exécution. Pour plus d’informations, consultez la page Activer les dumps de tas pour les services Apache Hadoop sur HDInsight sur Linux.
Étape 6 : vérifier les paramètres de configuration
Les clusters HDInsight sont préconfigurés avec les paramètres par défaut pour les services connexes, tels que Hadoop, Hive, HBase, etc. Selon le type de cluster, sa configuration matérielle, son nombre de nœuds, les types de travaux que vous exécutez et les données sur lesquelles vous travaillez (ainsi que la manière dont ces données sont traitées), vous devrez peut-être optimiser votre configuration.
Pour savoir en détail comment optimiser les configurations des performances dans la plupart des scénarios, consultez la section Optimiser les configurations de cluster avec Apache Ambari. Si vous utilisez Spark, consultez la section Optimiser les performances des tâches Apache Spark.
Étape 7 : reproduire la défaillance sur un autre cluster
Pour aider à diagnostiquer l’origine d’une erreur de cluster, démarrez un nouveau cluster avec la même configuration, puis soumettez de nouveau une à une les étapes du travail qui a échoué. Vérifiez les résultats de chaque étape avant de traiter l’étape suivante. Cette méthode vous donne la possibilité de corriger et de réexécuter une seule étape ayant échoué. Cette méthode présente également l’avantage de charger vos données d’entrée une seule fois.
- Créez un nouveau cluster de test avec la même configuration que le cluster défaillant.
- Envoyez la première étape du travail vers le cluster de test.
- Une fois le traitement de l’étape terminé, recherchez les erreurs dans les fichiers journaux d’étapes. Connectez-vous au nœud principal du cluster de test et consultez les fichiers journaux qui s’y trouvent. Les fichiers journaux d’étapes apparaissent uniquement si l’étape s’exécute pendant un certain temps, se termine ou échoue.
- Si la première étape a réussi, exécutez l’étape suivante. En cas d’erreurs, examinez l’erreur dans les fichiers journaux. S’il s’agit d’une erreur de code, corrigez-la et exécutez de nouveau l’étape.
- Continuez ainsi jusqu’à ce que toutes les étapes s’exécutent sans erreur.
- Une fois le débogage du cluster de test terminé, supprimez-le.
Étapes suivantes
- Gérer des clusters HDInsight à l’aide de l’interface utilisateur web d’Apache Ambari
- Analyse des journaux d’activité HDInsight
- Accéder à la connexion des applications Apache Hadoop YARN dans la version Linux de HDInsight
- Activer les dumps de tas pour les services Apache Hadoop sur HDInsight sur Linux
- Problèmes connus du cluster Apache Spark sur Azure HDInsight