Utiliser Apache Oozie avec Apache Hadoop pour définir et exécuter un workflow sur Azure HDInsight Linux
Découvrez comment utiliser Apache Oozie avec Apache Hadoop sur Azure HDInsight. Oozie est un workflow et un système de coordination qui gère les travaux Hadoop. Oozie est intégré dans la pile Hadoop et prend en charge les travaux suivants :
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Vous pouvez également utiliser Oozie pour planifier des travaux propres à un système, comme des programmes Java ou des scripts de l’interpréteur de commandes.
Notes
Une autre option pour définir des workflows avec HDInsight consiste à utiliser Azure Data Factory. Pour plus d’informations sur Data Factory, consultez Utiliser Apache Pig et Apache Hive avec Data Factory. Pour utiliser Oozie sur les clusters avec le Pack Sécurité Entreprise, consultez la section Exécuter Apache Oozie dans des clusters HDInsight Hadoop avec le Pack Sécurité Entreprise.
Prérequis
Un cluster Hadoop sur HDInsight. Consultez Bien démarrer avec HDInsight sur Linux.
Un client SSH. Consultez Connect to HDInsight (Apache Hadoop) using SSH (Se connecter à HDInsight (Apache Hadoop) avec SSH).
Une base de données Azure SQL. Consultez Démarrage rapide : Créer et interroger une base de données unique dans Azure SQL Database à l’aide du portail Microsoft Azure. Cet article utilise une base de données nommée oozietest.
Le schéma d'URI de votre principal espace de stockage de clusters.
wasb://pour Stockage Azure,abfs://pour Azure Data Lake Storage Gen2 ouadl://pour Azure Data Lake Storage Gen1. Si le transfert sécurisé est activé pour le stockage Azure, l’URI serawasbs://. Voir aussi transfert sécurisé.
Exemple de flux de travail
Le workflow utilisé dans ce document comporte deux actions. Les actions sont des définitions de tâches, telles que l’exécution de Hive, Sqoop, MapReduce ou d’autres processus :
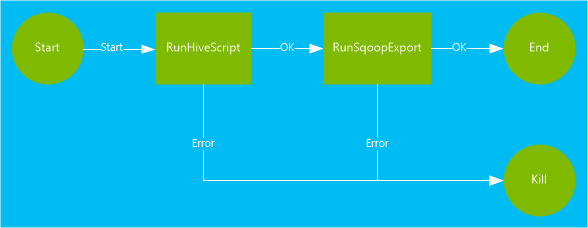
Une action Hive exécute un script HiveQL pour extraire des enregistrements à partir de
hivesampletable, élément inclus avec HDInsight. Chaque ligne de données décrit un accès depuis un appareil mobile spécifique. Le format d’enregistrement ressemble à ce qui suit :8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1Le script Hive utilisé dans ce document comptabilise le nombre total d’accès pour chaque plateforme (par exemple, Android ou iPhone) et stocke ces nombres dans une nouvelle table Hive.
Pour plus d’informations sur Hive, consultez [Utiliser Apache Hive avec HDInsight][hdinsight-use-hive].
Une action Sqoop exporte le contenu de la nouvelle table Hive vers une table créée dans Azure SQL Database. Pour plus d’informations sur Sqoop, consultez Utiliser Apache Sqoop avec HDInsight.
Notes
Pour obtenir la liste des versions Oozie prises en charge sur les clusters HDInsight, consultez Nouveautés des versions de cluster Hadoop fournies par HDInsight.
Création du répertoire de travail
Oozie s’attend à ce que vous stockiez toutes les ressources requises pour un travail dans le même répertoire. Cet exemple utilise wasbs:///tutorials/useoozie. Pour créer ce répertoire, suivez les étapes ci-dessous :
Modifiez le code ci-dessous pour remplacer
sshuserpar le nom d’utilisateur SSH du cluster, puis remplacezCLUSTERNAMEpar le nom du cluster. Entrez ensuite le code pour vous connecter au cluster HDInsight à l’aide de SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPour créer le répertoire, utilisez la commande suivante :
hdfs dfs -mkdir -p /tutorials/useoozie/dataNotes
Le paramètre
-pa provoqué la création de tous les répertoires dans le chemin d’accès. Le répertoiredataest utilisé pour contenir les données utilisées par le scriptuseooziewf.hql.Modifiez le code ci-dessous pour remplacer
sshuserpar votre nom d’utilisateur SSH. Pour vous assurer qu’Oozie peut emprunter l’identité de votre compte d’utilisateur, utilisez la commande suivante :sudo adduser sshuser usersNotes
Vous pouvez ignorer les erreurs indiquant que l’utilisateur est déjà membre du groupe
users.
Ajout d’un pilote de base de données
Ce workflow utilise Sqoop pour exporter des données vers la base de données SQL. Vous devez donc fournir une copie du pilote JDBC utilisé pour interagir avec la base de données SQL. Pour copier le pilote JDBC dans le répertoire de travail, utilisez la commande suivante à partir de la session SSH :
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Important
Vérifiez le pilote JDBC réel qui se trouve dans /usr/share/java/.
Si votre workflow utilisait d’autres ressources, par exemple un fichier jar contenant une application MapReduce, vous devez également les ajouter.
Définition de la requête Hive
Suivez les étapes ci-après pour créer un script de langage de requête Hive (HiveQL) qui définit une requête. Vous utiliserez la requête dans un workflow Oozie plus loin dans ce document.
À partir de la connexion SSH, utilisez la commande suivante pour créer un fichier nommé
useooziewf.hql:nano useooziewf.hqlUne fois que l’éditeur nano GNU est ouvert, utilisez la requête suivante comme contenu du fichier :
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Deux variables sont utilisées dans le script :
${hiveTableName}: contient le nom de la table à créer.${hiveDataFolder}: contient l’emplacement où stocker les fichiers de données pour la table.Le fichier de définition du workflow (workflow.xml dans cet article) transmet ces valeurs à ce script HiveQL au moment de l’exécution.
Pour enregistrer le fichier, sélectionnez Ctrl+X, entrez Y, puis sélectionnez Entrée.
Exécutez la commande suivante pour copier
useooziewf.hqlverswasbs:///tutorials/useoozie/useooziewf.hql:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlCette commande stocke le fichier
useooziewf.hqlsur le stockage compatible avec HDFS pour le cluster.
Définition du flux de travail
Les définitions de workflow Oozie sont écrites en langage de définition de processus Hadoop (hPDL), qui est un langage de définition de processus XML. Pour définir le flux de travail, procédez comme suit :
Pour créer et modifier un fichier, utilisez l’instruction suivante :
nano workflow.xmlUne fois que l’éditeur nano est ouvert, saisissez le code XML suivant comme contenu du fichier :
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>Deux actions sont définies dans le flux de travail :
RunHiveScript: il s’agit de l’action de départ, qui exécute le script Hiveuseooziewf.hql.RunSqoopExport: cette action exporte les données créées à partir du script Hive vers une base de données SQL à l’aide de Sqoop. Elle n’est exécutée que si l’actionRunHiveScripta abouti.Le workflow a plusieurs entrées, telle que
${jobTracker}. Vous remplacerez ces entrées par les valeurs que vous utilisez dans la définition du travail. Vous créerez la définition du travail plus loin dans ce document.Notez également l’entrée
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>dans la section Sqoop. Celle-ci indique à Oozie de rendre cette archive disponible pour Sqoop lors de l’exécution de cette action.
Pour enregistrer le fichier, sélectionnez Ctrl+X, entrez Y, puis sélectionnez Entrée.
Utilisez la commande suivante pour copier le fichier
workflow.xmlvers/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Créer une table
Notes
Il existe de nombreuses façons de se connecter à la base de données SQL pour créer une table. Les étapes suivantes utilisent FreeTDS à partir du cluster HDInsight.
Utilisez la commande suivante pour installer FreeTDS sur le cluster HDInsight :
sudo apt-get --assume-yes install freetds-dev freetds-binModifiez le code ci-dessous pour remplacer
<serverName>par votre nom de serveur SQL Server logique et<sqlLogin>par le compte de connexion du serveur. Entrez la commande pour vous connecter à la base de données SQL mentionnée dans les prérequis. Entrez le mot de passe à l’invite.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestVous obtenez un résultat qui ressemble à ce qui suit :
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>À l’invite de commandes
1>, entrez les lignes suivantes :CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOUne fois l’instruction
GOentrée, les instructions précédentes sont évaluées. Ces instructions créent une table nomméemobiledataqui est utilisée par le workflow.Pour vérifier que la table a été créée, utilisez les commandes suivantes :
SELECT * FROM information_schema.tables GOVous pouvez voir un résultat qui ressemble à ce qui suit :
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEQuittez l’utilitaire tsql en entrant
exità l’invite1>.
Création de la définition de travail
La définition du travail indique où se trouve le fichier workflow.xml. Elle indique également où se trouvent les autres fichiers utilisés par le workflow (par exemple, useooziewf.hql). En outre, elle définit les valeurs des propriétés utilisées dans le workflow et les fichiers associés.
Pour obtenir l’adresse complète du stockage par défaut, utilisez la commande suivante. Cette adresse est utilisée dans le fichier de configuration que vous allez créer.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlCette commande renvoie des informations similaires au code XML suivant :
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Notes
Si le cluster HDInsight utilise le stockage Azure comme stockage par défaut, le contenu de l’élément
<value>commence parwasbs://. Si Azure Data Lake Storage Gen1 est utilisé, il commence paradl://. Si Azure Data Lake Storage Gen2 est utilisé, il commence parabfs://.Enregistrez le contenu de l’élément
<value>, car il est utilisé dans les prochaines étapes.Modifiez le fichier xml ci-dessous comme suit :
Valeur d’espace réservé Valeur remplacée wasbs://mycontainer@mystorageaccount.blob.core.windows.net Valeur obtenue à l’étape 1. admin Votre ID de connexion pour le cluster HDInsight si vous n’êtes pas administrateur. serverName Nom du serveur Azure SQL Database. sqlLogin Compte de connexion du serveur Azure SQL Database. sqlPassword Mot de passe du compte de connexion du serveur Azure SQL Database. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>La plupart des informations de ce fichier sont utilisées pour remplir les valeurs utilisées dans les fichiers workflow.xml ou ooziewf.hql (comme
${nameNode}). Si le chemin d’accès est un cheminwasbs, vous devez utiliser le chemin d’accès complet. Ne le raccourcissez pas enwasbs:///. L’entréeoozie.wf.application.pathdéfinit où trouver le fichier workflow.xml. Ce fichier contient le workflow qui a été exécuté par ce travail.Pour créer la configuration de définition de travail Oozie, utilisez la commande suivante :
nano job.xmlUne fois que l’éditeur nano est ouvert, collez le code XML modifié en tant que contenu du fichier.
Pour enregistrer le fichier, sélectionnez Ctrl+X, entrez Y, puis sélectionnez Entrée.
Soumission et gestion du travail
Les étapes suivantes utilisent la commande Oozie pour soumettre et gérer des flux de travail Oozie sur le cluster. La commande Oozie est une interface conviviale sur l’ API REST Oozie.
Important
Lorsque vous utilisez la commande Oozie, vous devez utiliser le nom de domaine complet pour le nœud principal HDInsight. Ce nom de domaine complet est uniquement accessible à partir du cluster, ou, si le cluster se trouve sur un réseau virtuel Azure, à partir des autres machines sur le même réseau.
Pour obtenir l’URL du service Oozie, utilisez la commande suivante :
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlCette commande renvoie des informations similaires au code XML suivant :
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>La partie
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/ooziecorrespond à l’URL à utiliser avec la commande Oozie.Modifiez le code pour remplacer l’URL par celle obtenue précédemment. Pour créer une variable d’environnement pour l’URL, utilisez l’élément suivant afin de ne pas être obligé de le taper pour chaque commande :
export OOZIE_URL=http://HOSTNAMEt:11000/ooziePour envoyer le travail, utilisez le code suivant :
oozie job -config job.xml -submitCette commande charge les informations du travail à partir de
job.xmlet les envoie à Oozie, mais n’exécute pas le travail.Une fois la commande terminée, elle renvoie l’ID du travail (par exemple,
0000005-150622124850154-oozie-oozi-W). Cet ID est utilisé pour gérer le travail.Modifiez le code ci-dessous pour remplacer
<JOBID>par l’ID renvoyé à l’étape précédente. Pour vérifier le statut du travail, utilisez la commande suivante :oozie job -info <JOBID>Cette commande renvoie des informations qui ressemblent à ce qui suit :
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Ce travail a le statut
PREP, Cet état indique que le travail a été créé, mais qu’il n’a pas commencé.Modifiez le code ci-dessous pour remplacer
<JOBID>par l’ID renvoyé précédemment. Pour démarrer le travail, utilisez la commande suivante :oozie job -start <JOBID>Si vous vérifiez l’état après cette commande, il sera en cours d’exécution et des informations pour les actions au sein du travail seront renvoyées. L’exécution de ce travail nécessite quelques minutes.
Modifiez le code ci-dessous pour remplacer
<serverName>par votre nom de serveur et<sqlLogin>par le compte de connexion du serveur. Une fois la tâche terminée et réussie, vous pouvez vérifier que les données ont été générées et exportées vers la table de base de données SQL en utilisant la commande suivante. Entrez le mot de passe à l’invite.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestÀ l’invite de commandes
1>, entrez la requête suivante :SELECT * FROM mobiledata GOLes informations renvoyées sont semblables à ce qui suit :
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Pour plus d’informations sur la commande Oozie, consultez Outil en ligne de commande Apache Oozie.
API REST Oozie
L’API REST Oozie vous permet de créer vos propres outils fonctionnant avec Oozie. Les informations suivantes sont des informations spécifiques de HDInsight sur l’utilisation de l’API REST Oozie :
URI : vous pouvez accéder à l’API REST depuis l’extérieur du cluster à l’adresse
https://CLUSTERNAME.azurehdinsight.net/oozie.Authentification : pour l’authentification, utilisez l’API, le compte HTTP (admin) et le mot de passe du cluster. Par exemple :
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Pour plus d’informations sur l’utilisation de l’API REST Oozie, consultez API des services web Apache Oozie.
Interface utilisateur Web Oozie
L’interface utilisateur web Oozie fournit une vue web de l’état des travaux Oozie sur le cluster. Avec l’interface utilisateur web, vous pouvez afficher les informations suivantes :
- Statut de tâche
- Définition du travail
- Configuration
- Un graphique des actions exécutées sur le travail
- Les journaux d’activité du travail
Vous pouvez également afficher les détails pour les actions au sein d’un travail.
Pour accéder à l’interface utilisateur web Oozie, procédez comme suit :
Créez un tunnel SSH vers le cluster HDInsight. Pour plus d’informations, consultez Utilisation du tunneling SSH avec HDInsight.
Une fois qu’un tunnel a été créé, ouvrez l’interface utilisateur web Ambari dans votre navigateur web à l’aide de l’URI
http://headnodehost:8080.Sur le côté gauche de la page, sélectionnez Oozie>Liens rapides>Interface utilisateur web Oozie.
L’interface utilisateur web Oozie affiche par défaut les travaux du workflow en cours d’exécution. Pour voir tous les travaux du workflow, sélectionnez Tous les travaux.
Pour afficher plus d’informations sur un travail, sélectionnez le travail.
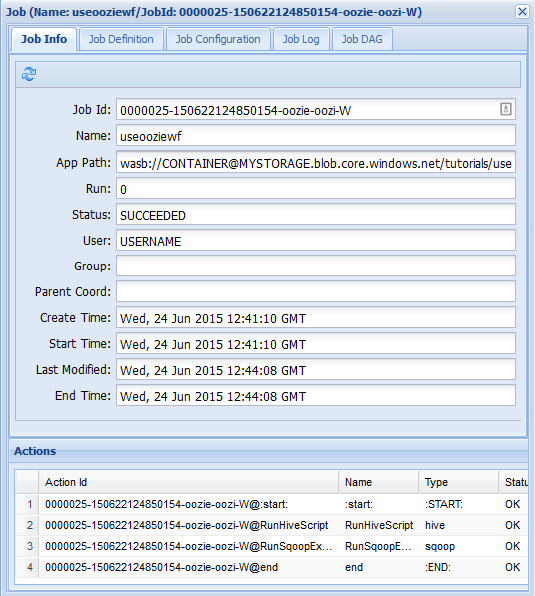
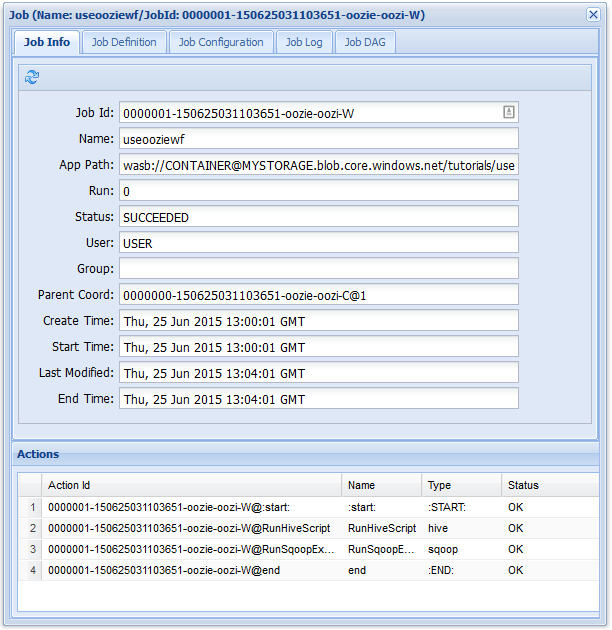
Sous l’onglet Infos travail, vous pouvez voir les informations de base sur le travail, ainsi que les actions individuelles au sein du travail. Vous pouvez utiliser les onglets en haut de la page pour afficher la définition du travail, la configuration du travail, accéder au journal du travail ou afficher un graphe orienté acyclique (DAG) du travail sous Job DAG (DAG du travail).
Journal de la tâche : Cliquez sur le bouton Obtenir les journaux d’activité pour obtenir tous les journaux d’activité de la tâche, ou utilisez le champ Entrer un filtre de recherche pour filtrer les journaux d’activité.
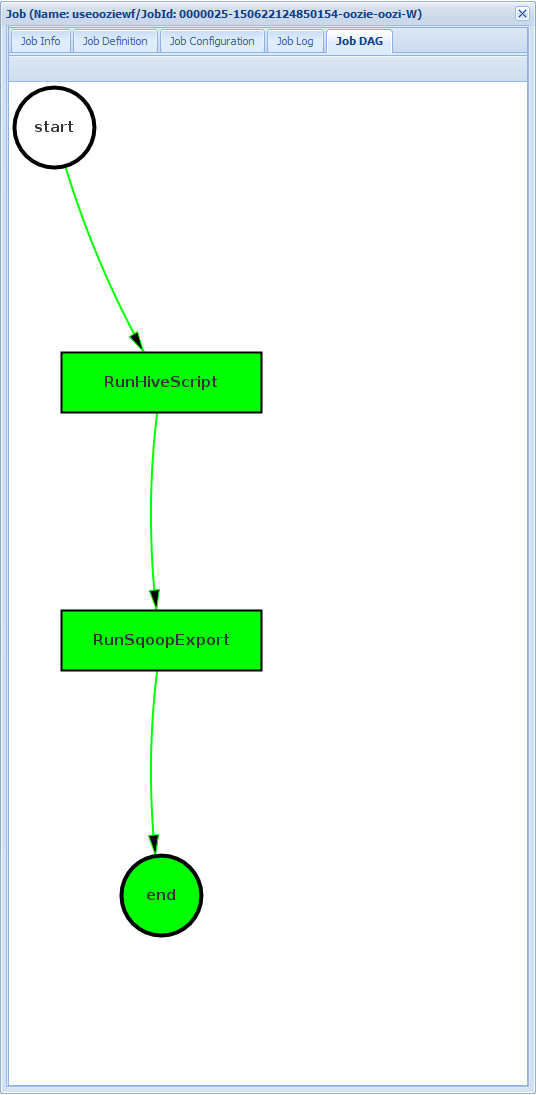
DAG de la tâche : le graphique orienté acyclique est une représentation graphique des chemins de données utilisés à travers le workflow.
Si vous sélectionnez l’une des actions sous l’onglet Infos travail, des informations sur l’action s’affichent. Par exemple, sélectionnez l’action RunSqoopExport.
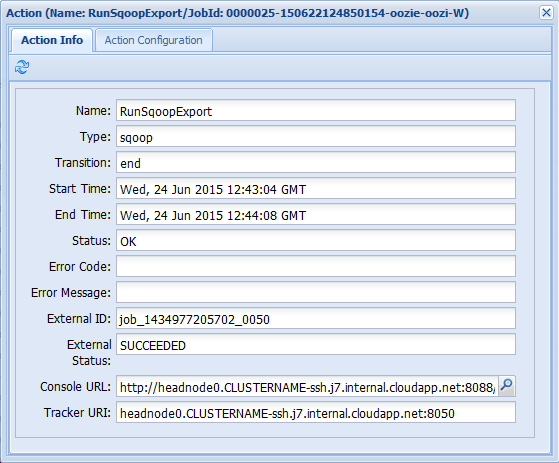
Vous pouvez voir les détails de l’action, notamment un lien vers l’URL de la console Utilisez ce lien pour afficher les informations de suivi pour le travail.
Planifier les travaux
Vous pouvez utiliser le coordinateur pour spécifier un début, une fin et la fréquence d’occurrence des travaux. Pour définir une planification pour le workflow, procédez comme suit :
Utilisez la commande suivante pour créer un fichier nommé coordinator.xml :
nano coordinator.xmlUtilisez le code XML suivant comme contenu du fichier :
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Notes
Les variables
${...}sont remplacées par des valeurs dans la définition du travail lors de l’exécution. Les variables sont les suivantes :${coordFrequency}: délai entre les instances de la tâche en cours d’exécution.${coordStart}: heure de début de la tâche.${coordEnd}: heure de fin de la tâche.${coordTimezone}: les tâches du coordinateur se trouvent dans un fuseau horaire fixe sans passage à l’heure d’été, généralement représenté par UTC. Ce fuseau horaire est appelé le fuseau horaire du traitement d’Oozie.${wfPath}: chemin du fichier workflow.xml.
Pour enregistrer le fichier, sélectionnez Ctrl+X, entrez Y, puis sélectionnez Entrée.
Pour copier le fichier dans le répertoire de travail pour ce travail, utilisez la commande suivante :
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlPour modifier le fichier
job.xmlcréé précédemment, utilisez la commande suivante :nano job.xmlEffectuez les modifications suivantes :
Pour ordonner à Oozie d’exécuter le fichier coordinateur au lieu du fichier de workflow, remplacez
<name>oozie.wf.application.path</name>par<name>oozie.coord.application.path</name>.Pour définir la variable
workflowPathutilisée par le coordinateur, ajoutez le code XML suivant :<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>Remplacez le texte
wasbs://mycontainer@mystorageaccount.blob.core.windowspar la valeur utilisée dans les autres entrées du fichier job.xml.Pour définir le début, la fin et la fréquence correspondant au coordinateur, ajoutez le code XML suivant :
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Ces valeurs définissent le début sur 12 h 00 le 10 mai 2018 et la fin sur le 12 mai 2018. L’intervalle d’exécution de ce travail est défini sur quotidien. La fréquence est exprimée en minutes, par conséquent, 24 heures x 60 minutes = 1 440 minutes. Enfin, le fuseau horaire est défini sur UTC.
Pour enregistrer le fichier, sélectionnez Ctrl+X, entrez Y, puis sélectionnez Entrée.
Pour envoyer et démarrer le travail, utilisez la commande suivante :
oozie job -config job.xml -runSi vous accédez à l’interface utilisateur web Oozie et sélectionnez l’onglet Travaux du coordinateur, vous obtenez des informations semblables à l’image suivante :

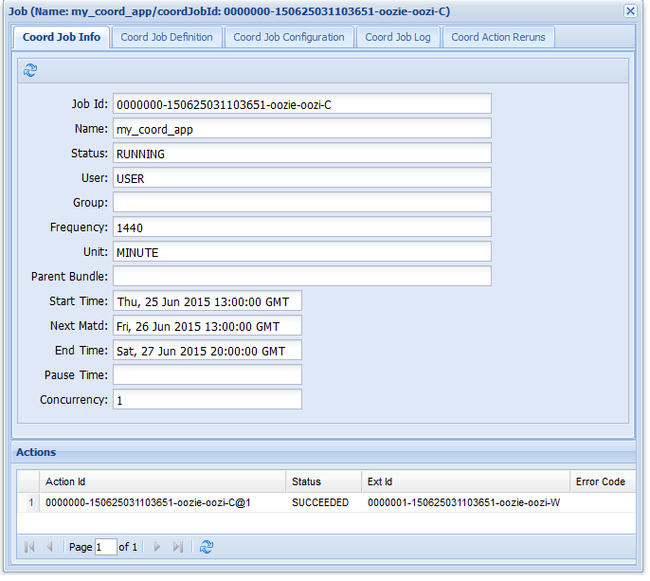
L’entrée Next Materialization (Matérialisation suivante) indique l’heure de la prochaine exécution du travail.
De même que pour le travail de workflow précédent, si vous sélectionnez l’entrée du travail dans l’interface utilisateur web, des informations sur le travail s’affichent :
Remarque
L’image affiche uniquement les exécutions réussies du travail, et non les actions individuelles dans le workflow planifié. Pour afficher les actions individuelles, sélectionnez l’une des entrées Action.
Étapes suivantes
Dans cet article, vous avez appris comment définir un workflow Oozie et comment exécuter un travail Oozie. Pour en savoir plus sur l’utilisation de HDInsight, consultez les articles suivants :