Utiliser Azure Toolkit for Eclipse afin de créer des applications Apache Spark pour un cluster HDInsight
Utilisez HDInsight Tools dans Azure Toolkit for Eclipse afin de développer des applications Apache Spark écrites en Scala et envoyez-les à un cluster Azure HDInsight Spark, directement à partir de l’environnement de développement intégré (IDE) Eclipse. Vous pouvez utiliser le plug-in HDInsight Tools de différentes manières :
- Pour développer une application Scala Spark et l’envoyer sur un cluster HDInsight Spark.
- Pour accéder à vos ressources de cluster Azure HDInsight Spark.
- Pour développer et exécuter une application Scala Spark localement.
Prérequis
Cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
IDE Eclipse. Cet article utilise l’environnement de développement intégré (IDE) Eclipse pour les développeurs Java.
Installer les plug-ins nécessaires
Installer le Kit de ressources Azure pour Eclipse
Pour plus d’informations sur l’installation, voir Installation du kit de ressources Azure pour Eclipse.
Installer le plug-in Scala
Quand vous ouvrez Eclipse, HDInsight Tools détecte automatiquement si vous avez installé le plug-in Scala. Sélectionnez OK pour continuer, puis suivez les instructions pour installer le plug-in à partir de la Place de marché Eclipse. Redémarrez l’IDE une fois l’installation terminée.
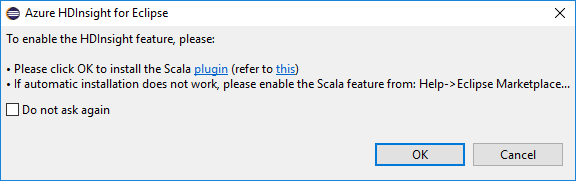
Confirmer les plug-ins
Accédez à Aide>Place de marché Eclipse.
Sélectionnez l’onglet Installé.
Vous devez voir au moins :
- Azure Toolkit for Eclipse <version>.
- IDE Scala <version>.
Connectez-vous à votre abonnement Azure :
Démarrez l’IDE Eclipse.
Accédez à Fenêtre>Afficher la vue>Autre>Se connecter.
Dans la boîte de dialogue Afficher la vue, accédez à Azure>Azure Explorer, puis sélectionnez Ouvrir.
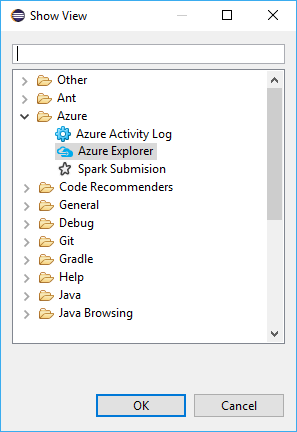
Dans Azure Explorer, cliquez avec le bouton droit sur le nœud Azure, puis sélectionnez Se connecter.
Dans la boîte de dialogue Connexion à Azure, choisissez la méthode d’authentification, sélectionnez Se connecter et effectuez le processus de connexion.

Une fois que vous êtes connecté, la boîte de dialogue Vos abonnements liste tous les abonnements Azure associés aux informations d’identification. Appuyez sur Sélectionner pour fermer la boîte de dialogue.

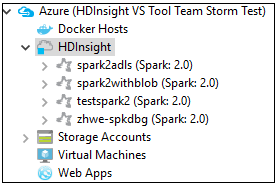
Dans Azure Explorer, accédez à Azure>HDInsight pour afficher les clusters HDInsight Spark figurant dans votre abonnement.
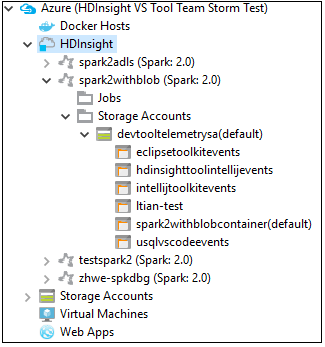
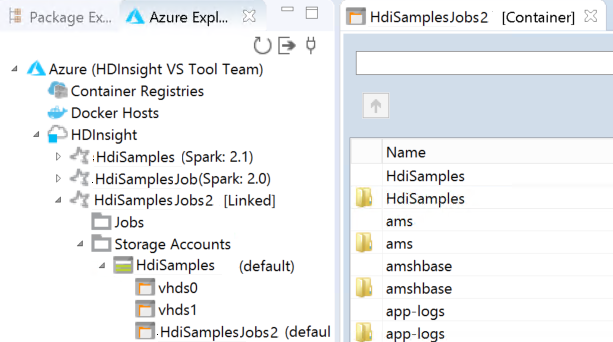
Vous pouvez développer davantage un nœud de nom de cluster pour voir les ressources (par exemple, les comptes de stockage) associées au cluster.
Lier un cluster
Vous pouvez lier un cluster normal en utilisant le nom d’utilisateur Ambari managé. De même, pour un cluster HDInsight joint à un domaine, vous pouvez effectuer une liaison à l’aide du domaine et du nom d’utilisateur, par exemple user1@contoso.com.
Dans Azure Explorer, cliquez avec le bouton droit sur HDInsight et sélectionnez Lier un cluster.

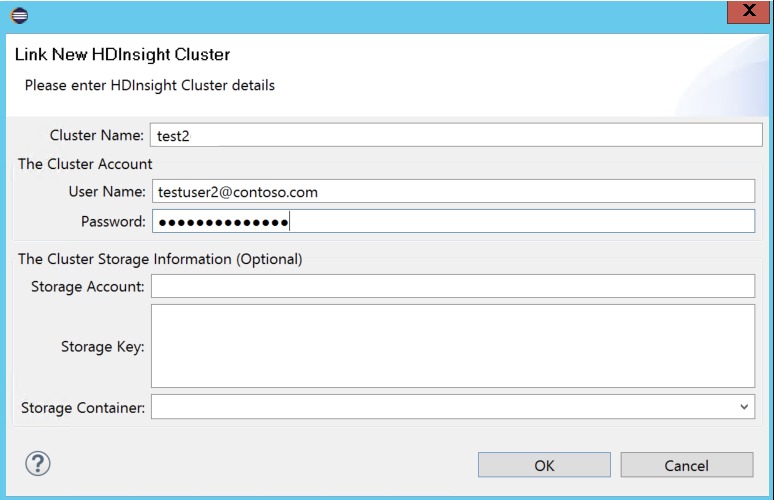
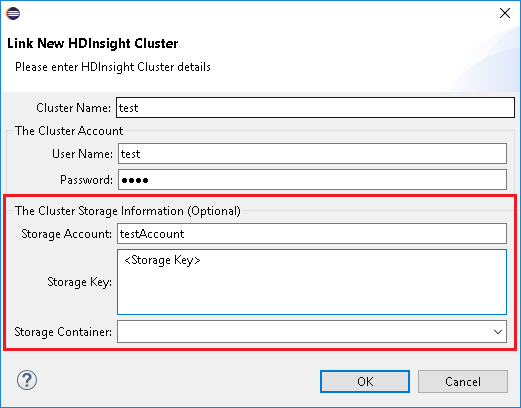
Entrez le nom du cluster, le nom d’utilisateur et le mot de passe, puis sélectionnez OK. Si vous le souhaitez, entrez un compte de stockage, une clé de stockage, puis sélectionnez un conteneur de stockage pour que l’explorateur de stockage fonctionne avec l’arborescence de gauche.
Remarque
Nous utilisons la clé de stockage liée, le nom d’utilisateur et le mot de passe si le cluster est à la fois connecté sur un abonnement Azure et lié à un cluster.
Pour l’utilisateur clavier uniquement, lorsque le focus actuel se trouve sur Clé de stockage, vous devez utiliser Ctrl+TAB pour vous concentrer sur le champ suivant de la boîte de dialogue.
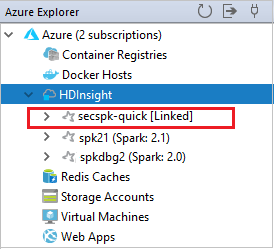
Vous pouvez voir le cluster lié sous HDInsight. Vous pouvez désormais soumettre une application à ce cluster lié.
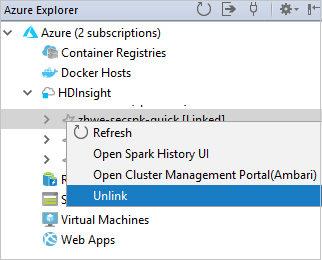
Vous pouvez également dissocier un cluster à partir de Azure Explorer.
Configuration d’un projet Spark Scala pour un cluster HDInsight Spark
Dans l’espace de travail IDE Eclipse, sélectionnez Fichier>Nouveau>Projet.
Dans l’Assistant Nouveau projet, sélectionnez Projet HDInsight>Spark sur HDInsight (Scala) . Sélectionnez ensuite Suivant.

Dans la boîte de dialogue New HDInsight Scala Project (Nouveau projet HDInsight Scala), indiquez les valeurs suivantes, puis sélectionnez Next (Suivant) :
- Entrez un nom pour le projet.
- Dans la zone JRE, vérifiez que l’option Use an execution environment JRE (Utiliser un environnement d’exécution JRE) est définie sur JavaSE-1.7 ou version ultérieure.
- Dans la zone Bibliothèque Spark, vous pouvez choisir l’option Utiliser Maven pour configurer le kit de développement logiciel (SDK) Spark. Notre outil intègre la version correcte pour les kits de développement logiciel (SDK) Spark et Scala. Vous pouvez aussi choisir l’option Ajouter le kit SDK Spark manuellement. Téléchargez et ajoutez le kit SDK Spark manuellement.
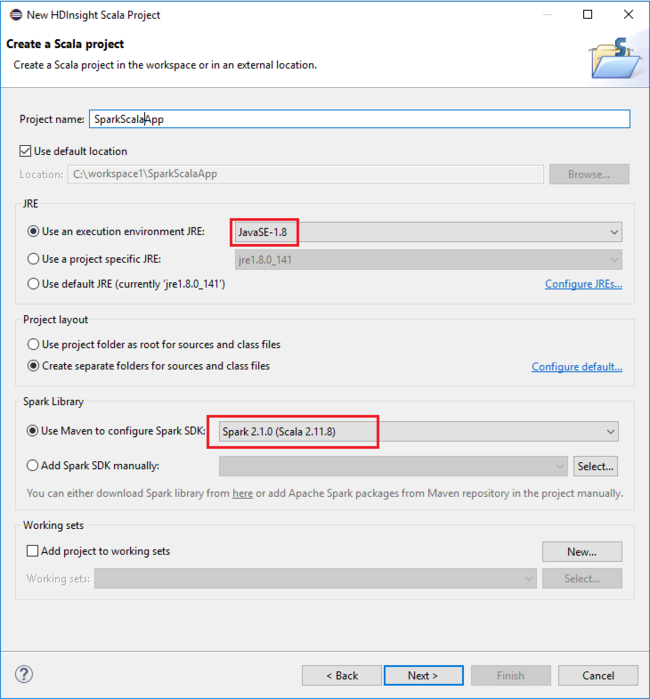
Dans la boîte de dialogue suivante, passez en revue les détails, puis sélectionnez Terminer.
Créer une application Scala pour un cluster HDInsight Spark
Dans l’Explorateur de package, développez le projet que vous avez créé précédemment. Cliquez avec le bouton droit sur src, sélectionnez Nouveau>Autre.
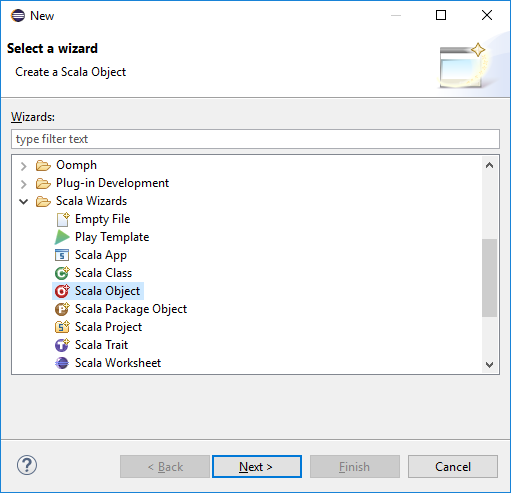
Dans la boîte de dialogue Sélectionner un Assistant, sélectionnez Assistants Scala>Objet Scala. Sélectionnez ensuite Suivant.
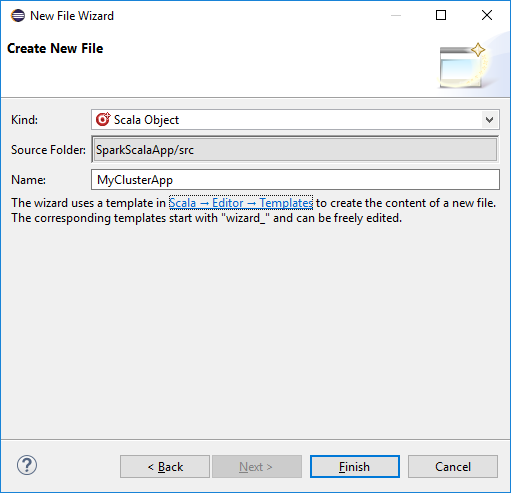
Dans la boîte de dialogue Create New File (Créer un fichier), entrez un nom pour l’objet, puis sélectionnez Finish (Terminer). Un éditeur de texte s’ouvre.
Dans l’éditeur de texte, remplacez le contenu actuel par le code ci-dessous :
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Exécutez l’application sur un cluster HDInsight Spark :
a. Dans Package Explorer (Explorateur de packages), cliquez avec le bouton droit sur le nom du projet, puis sélectionnez Submit Spark Application to HDInsight (Envoyer l’application Spark à HDInsight).
b. Dans la boîte de dialogue Spark Submission (Envoi Spark), entrez les valeurs suivantes, puis sélectionnez Submit (Envoyer) :
Pour Cluster Name(Nom du cluster), sélectionnez le cluster HDInsight Spark sur lequel vous souhaitez exécuter votre application.
Sélectionnez un artefact à partir du projet Eclipse ou choisissez-en un sur un disque dur. La valeur par défaut dépend de l’élément sur lequel vous cliquez avec le bouton droit dans l’Explorateur de package.
Dans la liste déroulante Main class name (Nom de la classe principale), l’Assistant Envoi affiche tous les noms des objets de votre projet. Sélectionnez-en un ou entrez-en un que vous souhaitez exécuter. Si vous avez sélectionné un artefact à partir d’un disque dur, vous devez entrer le nom de la classe principale manuellement.
Comme le code d’application dans cet exemple n’exige aucun argument de ligne de commande et qu’il ne référence pas de fichiers JAR ou d’autres fichiers, vous pouvez laisser les autres zones de texte vides.
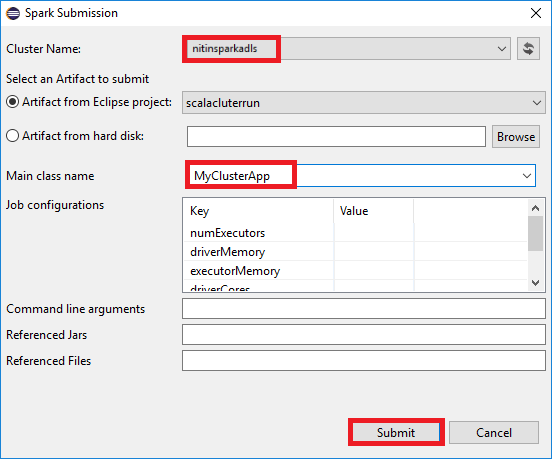
L’onglet Spark Submission (Envoi Spark) doit commencer à afficher la progression. Vous pouvez arrêter l’application en sélectionnant le bouton rouge dans la fenêtre Spark Submission (Envoi Spark). Vous pouvez également afficher les journaux d’activité pour cette exécution d’application spécifique en sélectionnant l’icône en forme de globe (indiquée par la zone bleue dans l’image).

Accéder aux clusters HDInsight Spark et les gérer à l’aide de HDInsight Tools dans le kit de ressources Azure pour Eclipse
Vous pouvez effectuer diverses opérations à l’aide de HDInsight Tools, y compris en accédant à la sortie du travail.
Accéder à la vue des travaux
Dans Azure Explorer, développez HDInsight puis le nom du cluster Spark, puis sélectionnez Travaux.

Sélectionnez le nœud Travaux. Si une version Java est antérieure à la version 1.8, HDInsight Tools vous rappelle automatiquement d’installer le plug-in E(fx)clipse. Sélectionnez OK pour continuer, puis suivez l’assistant d’installation pour l’installer depuis la Place de marché Eclipse et redémarrer Eclipse.
Ouvrez la vue des travaux à partir du nœud Tâches. Dans le volet droit, l’onglet Spark Job View (Affichage des travaux Spark) affiche toutes les applications qui ont été exécutées sur le cluster. Sélectionnez le nom de l’application pour laquelle vous souhaitez afficher plus de détails.
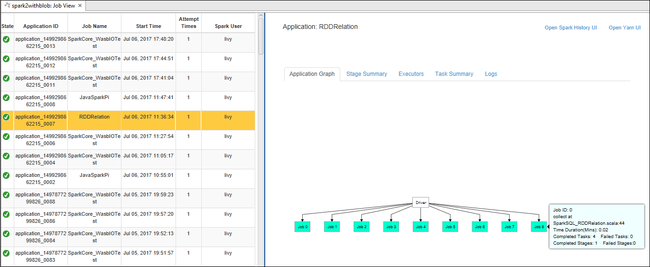
Vous pouvez alors effectuer une des actions suivantes :
Placez le curseur sur le graphe du travail. Il affiche des informations de base sur le travail en cours d’exécution. Sélectionnez le graphe de travail ; vous pouvez voir alors les étapes et les informations générées par chaque travail.
Sélectionnez l’onglet Journal pour afficher les journaux d’activité fréquemment utilisés, notamment les journaux d’activité Driver Stderr, Driver Stdout et Directory Info.

Ouvrez l’interface utilisateur de l’historique Spark et l’interface utilisateur Apache Hadoop YARN (au niveau de l’application) en sélectionnant les liens hypertexte en haut de la fenêtre.
Accéder au conteneur de stockage du cluster
Dans l’Explorateur Azure, développez le nœud racine HDInsight pour afficher la liste des clusters HDInsight Spark disponibles.
Développez le nom de cluster pour voir le compte de stockage et le conteneur de stockage par défaut du cluster.
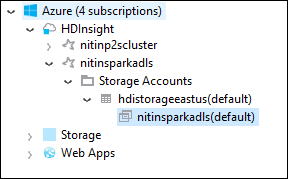
Sélectionnez le nom du conteneur de stockage associé au cluster. Dans le volet droit, double-cliquez sur le dossier HVACOut. Ouvrez l’un des fichiers part- pour afficher la sortie de l’application.
Accéder au serveur d’historique Spark
Dans l’Explorateur Azure, cliquez avec le bouton droit sur le nom de votre cluster Spark, puis sélectionnez Open Spark History UI (Ouvrir l’interface utilisateur de l’historique Spark). Lorsque vous y êtes invité, entrez les informations d’identification d’administrateur pour le cluster. Vous les avez spécifiées au moment de l’approvisionnement du cluster.
Dans le tableau de bord du serveur d’historique Spark, utilisez le nom de l’application pour rechercher l’application que vous venez d’exécuter. Dans le code précédent, vous définissez le nom de l’application en utilisant
val conf = new SparkConf().setAppName("MyClusterApp"). Le nom de votre application Spark était donc MyClusterApp.
Démarrer le portail Apache Ambari
Dans l’Explorateur Azure, cliquez avec le bouton droit sur le nom de votre cluster Spark, puis sélectionnez Open Cluster Management Portal (Ambari) (Ouvrir le portail de gestion des clusters [Ambari]).
Lorsque vous y êtes invité, entrez les informations d’identification d’administrateur pour le cluster. Vous les avez spécifiées au moment de l’approvisionnement du cluster.
Gérer les abonnements Azure
Par défaut, HDInsight Tools du kit de ressources Azure pour Eclipse répertorie les clusters Spark de tous vos abonnements Azure. Si nécessaire, vous pouvez spécifier les abonnements pour lesquels vous souhaitez accéder au cluster.
Dans Azure Explorer, cliquez avec le bouton droit sur le nœud racine Azure, puis sélectionnez Gérer les abonnements.
Dans la boîte de dialogue, décochez les cases concernant l’abonnement auquel vous ne souhaitez pas accéder, puis sélectionnez Fermer. Vous pouvez également sélectionner Se déconnecter si vous souhaitez vous déconnecter de votre abonnement Azure.
Exécuter une application Spark Scala localement
Vous pouvez utiliser HDInsight Tools du kit de ressources Azure pour Eclipse pour exécuter des applications Spark Scala localement sur votre poste de travail. En règle générale, ces applications n’ont pas besoin d’accéder aux ressources de cluster telles que le conteneur de stockage, et elles peuvent être exécutées et testées localement.
Configuration requise
Quand vous exécutez l’application Spark Scala locale sur un ordinateur Windows, vous pouvez obtenir une exception, comme l’explique le document SPARK-2356. Cette exception est liée à l’absence du fichier WinUtils.exe dans Windows.
Pour résoudre cette erreur, vous devez disposer de Winutils.exe dans un emplacement tel que C:\WinUtils\bin, puis ajouter la variable d’environnement HADOOP_HOME et définir sa valeur sur C\WinUtils.
Exécuter une application Spark Scala locale
Démarrez Eclipse et créez un projet. Dans la boîte de dialogue New Project (Nouveau projet), choisissez les options suivantes, puis sélectionnez Next (Suivant).
Dans l’Assistant Nouveau projet, sélectionnez Projet HDInsight>Spark on HDInsight Local Run Sample (Scala) (Exemple d’exécution locale de Spark sur HDInsight [Scala]). Sélectionnez ensuite Suivant.
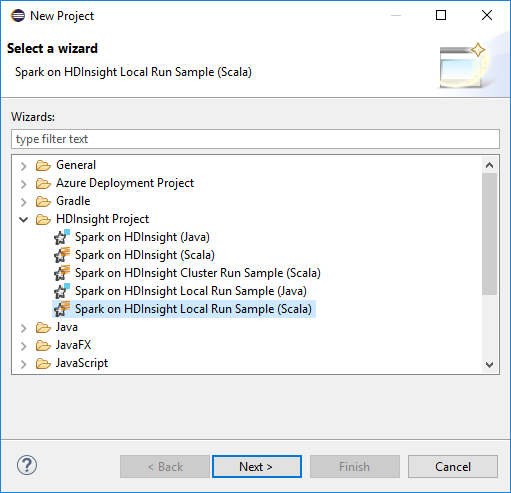
Pour fournir les détails du projet, suivez les étapes 3 à 6 indiquées dans la section précédente Configuration d’un projet Spark Scala pour un cluster HDInsight Spark.
Le modèle ajoute un exemple de code (LogQuery) sous le dossier src que vous pouvez exécuter localement sur votre ordinateur.
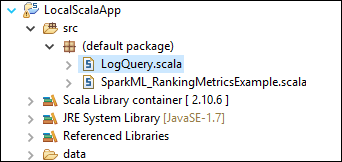
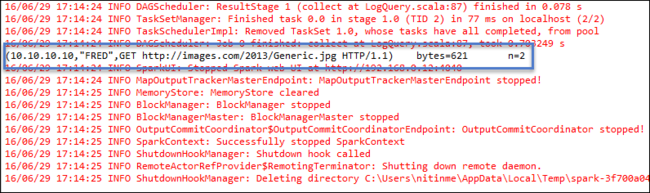
Cliquez avec le bouton droit sur LogQuery.scala et sélectionnez Exécuter en tant que>1 Application Scala. Un résultat ressemblant à ce qui suit apparaît sous l’onglet Console :
Rôle Lecteur seul
Lorsque les utilisateurs envoient du travail à un cluster avec l’autorisation de rôle Lecteur seul, les informations d’identification Ambari sont obligatoires.
Lier le cluster à partir du menu contextuel
Connectez-vous avec un compte membre du rôle Lecteur seul.
Dans Azure Explorer, développez HDInsight pour voir les clusters HDInsight de votre abonnement. Les clusters signalés par "Role:Reader" ont uniquement l’autorisation du rôle Lecteur seul.

Cliquez avec le bouton droit de la souris sur le cluster avec l’autorisation de rôle Lecteur seul. Sélectionnez Link this cluster dans le menu contextuel pour lier le cluster. Entrez le nom d’utilisateur et le mot de passe Ambari.
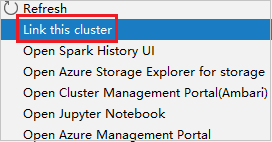
Si le cluster est correctement lié, HDInsight est actualisé. L’étape du cluster sera reliée.

Lier le cluster en développant le nœud Jobs (Travaux)
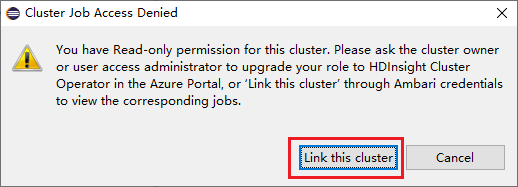
Cliquez sur le nœud Jobs (Travaux). La fenêtre contextuelle Cluster Job Access Denied (Accès refusé au travail du cluster) s’ouvre alors.
Cliquez sur Link this cluster pour lier le cluster.
Lier un cluster à partir de la fenêtre d’envoi de Spark
Créez un projet HDInsight.
Cliquez avec le bouton droit sur le package. Sélectionnez ensuite Submit Spark Application to HDInsight (Envoyer l’application Spark à HDInsight).
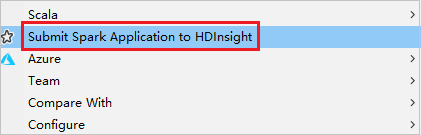
Sélectionnez un cluster doté de l’autorisation de rôle Lecteur seul pour Nom du cluster. Un message d’avertissement s’affiche. Cliquez sur Link this cluster pour lier le cluster.

Afficher les comptes de stockage
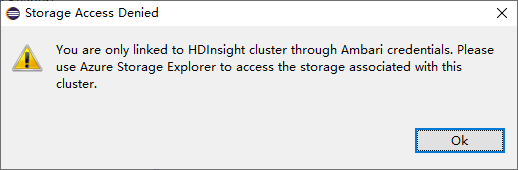
Pour les clusters possédant l’autorisation de rôle Lecteur seul, cliquez sur le nœud Storage Accounts (Comptes de stockage). La fenêtre contextuelle Storage Access Denied (Accès au stockage refusé) s’ouvre alors.
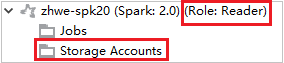

Pour les clusters liés, cliquez sur le nœud Storage Accounts. La fenêtre contextuelle Storage Access Denied s’ouvre alors.
Problèmes connus
Lorsque vous utilisez Lier un cluster, je vous conseille de fournir des informations d’identification de stockage.
Il existe deux modes pour soumettre les travaux. Si les informations d’identification de stockage sont fournies, le mode batch sera utilisé pour soumettre le travail. Sinon, le mode interactif sera utilisé. Si le cluster est occupé, l’erreur ci-dessous risque de se produire.


Voir aussi
Scénarios
- Apache Spark avec BI : effectuer une analyse interactive des données à l’aide de Spark sur HDInsight avec des outils décisionnels
- Apache Spark avec Machine Learning : Utiliser Spark dans HDInsight pour analyser la température d’un bâtiment à l’aide de données issues des systèmes de chauffage, de ventilation et de climatisation
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour prédire les résultats de l’inspection d’aliments
- Analyse des journaux de site web à l’aide d’Apache Spark dans HDInsight
Création et exécution d’applications
- Créer une application autonome avec Scala
- Exécuter des tâches à distance avec Apache Livy sur un cluster Apache Spark
Outils et extensions
- Utiliser le kit de ressources Azure pour IntelliJ pour créer et soumettre des applications Spark Scala
- Utiliser Azure Toolkit for IntelliJ pour déboguer des applications Apache Spark à distance par VPN
- Utiliser Azure Toolkit for IntelliJ pour déboguer des applications Apache Spark à distance par SSH
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Noyaux disponibles pour bloc-notes Jupyter dans un cluster Apache Spark pour HDInsight
- Utiliser des packages externes avec des blocs-notes Jupyter
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)