Configurer un environnement de développement Python pour Azure Machine Learning (v1)
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Apprenez à configurer un environnement de développement Python pour Azure Machine Learning.
Le tableau suivant présente chaque environnement de développement évoqué dans cet article, ainsi que ses avantages et inconvénients.
| Environnement | Avantages | Inconvénients |
|---|---|---|
| Environnement local | Contrôle total de votre environnement de développement et des dépendances. Exécutez avec n’importe quel outil de build, environnement ou IDE de votre choix. | La mise en route prend plus de temps. Les packages de Kit de développement logiciel (SDK) nécessaires doivent être installés, ainsi qu’un environnement si vous n’en avez pas encore. |
| Data Science Virtual Machine (DSVM) | Similaire à l’instance de calcul basée sur le cloud (Python et le kit de développement logiciel (SDK) sont préinstallés), mais avec d’autres outils connus de science des données et de Machine Learning préinstallés. Facile à mettre à l’échelle et à combiner avec d’autres outils et flux de travail personnalisés. | Expérience de démarrage plus lente que celle de l’instance de calcul basée sur le cloud. |
| Instance de calcul Azure Machine Learning | Méthode la plus simple pour la mise en route. Le Kit de développement logiciel (SDK) entier est déjà installé sur votre machine virtuelle d’espace de travail, et les didacticiels du Notebook sont pré-clonés et prêts pour exécution. | Manque de contrôle de votre environnement de développement et des dépendances. Coût supplémentaire pour la machine virtuelle Linux (la machine virtuelle peut être arrêtée lorsqu’elle n’est pas utilisée pour éviter des frais). Consultez les détails de la tarification. |
| Azure Databricks | Idéal pour l'exécution de flux de travail de Machine Learning intensifs à grande échelle sur la plateforme Apache Spark évolutive. | Excessif pour du Machine Learning expérimental ou des expériences et des flux de travail à plus petite échelle. Coût supplémentaire pour Azure Databricks. Consultez les détails de la tarification. |
Cet article fournit également des conseils d’utilisation pour les outils suivants :
Jupyter Notebook : si vous utilisez déjà Jupyter Notebook, le SDK contient des fonctionnalités supplémentaires que vous devez installer.
Visual Studio Code : si vous utilisez Visual Studio Code, l’extension Azure Machine Learning inclut une prise en charge du langage extensif Python et de caractéristiques permettant de travailler avec Azure Machine Learning beaucoup plus facilement et rapidement.
Prérequis
- Espace de travail Azure Machine Learning. SI vous n’en avez pas, vous pouvez créer un espace de travail Azure Machine Learning via le Portail Azure, Azure CLI et les modèles Azure Resource Manager.
Local et DSVM uniquement : Créer un fichier de configuration d’espace de travail
Le fichier de configuration d’espace de travail est un fichier JSON qui indique au SDK comment communiquer avec votre espace de travail Azure Machine Learning. Le fichier est nommé config.json, et il a le format suivant :
{
"subscription_id": "<subscription-id>",
"resource_group": "<resource-group>",
"workspace_name": "<workspace-name>"
}
Ce fichier JSON doit se trouver dans la structure de répertoire qui contient vos scripts Python ou vos blocs-notes Jupyter Notebook. Il peut se trouver dans le même répertoire, dans un sous-répertoire nommé .azureml ou dans un répertoire parent.
Pour utiliser ce fichier à partir de votre code, utilisez la méthode Workspace.from_config. Ce code charge les informations à partir du fichier et se connecte à votre espace de travail.
Créez un fichier de configuration d’espace de travail dans l’une des méthodes suivantes :
Portail Azure
Télécharger le fichier: Dans le portail Azure, sélectionnez Télécharger config.json à partir de la section Vue d’ensemble de votre espace de travail.
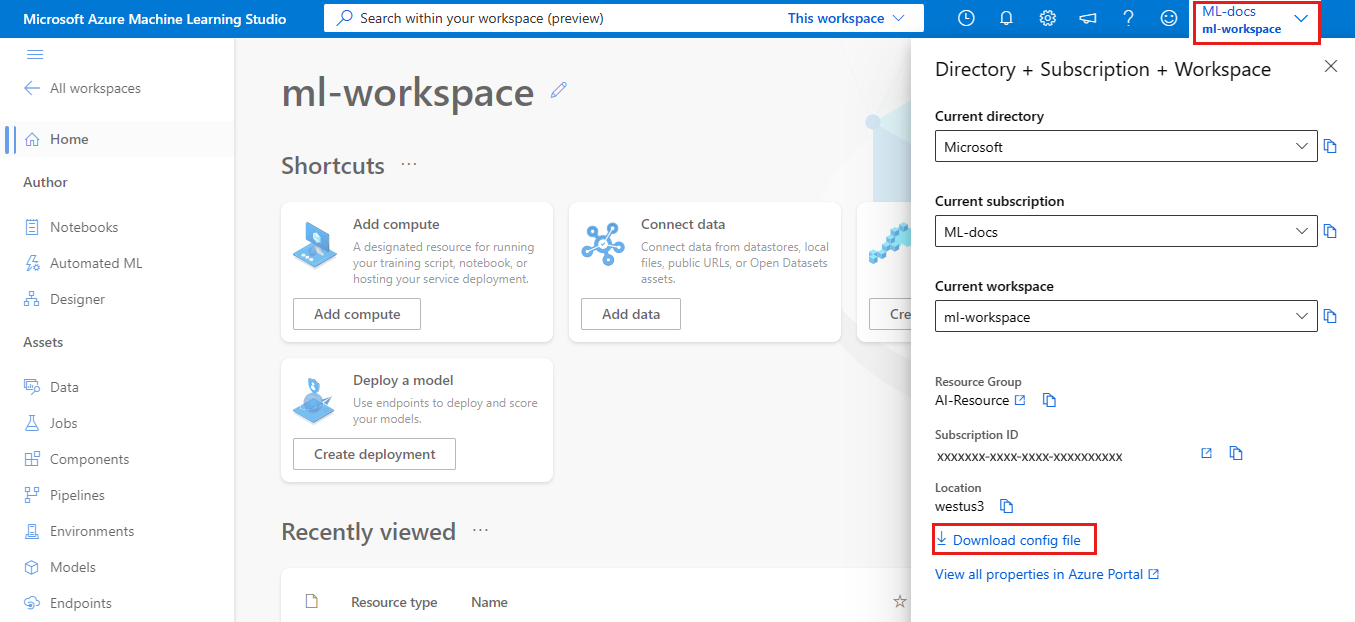
SDK Python Azure Machine Learning
Créez un script pour vous connecter à votre espace de travail Azure Machine Learning et utilisez la méthode
write_configpour générer votre fichier et l’enregistrer sous le nom .azureml/config.json. Assurez-vous de remplacer les valeurssubscription_id,resource_groupetworkspace_namepar les vôtres.S’APPLIQUE À :
SDK Python azureml v1from azureml.core import Workspace subscription_id = '<subscription-id>' resource_group = '<resource-group>' workspace_name = '<workspace-name>' try: ws = Workspace(subscription_id = subscription_id, resource_group = resource_group, workspace_name = workspace_name) ws.write_config() print('Library configuration succeeded') except: print('Workspace not found')
Ordinateur local ou environnement de machine virtuelle distante
Vous pouvez configurer un environnement sur un ordinateur local ou une machine virtuelle distante, telle qu’une instance de calcul Azure Machine Learning ou Data Science VM.
Pour configurer un environnement de développement local ou une machine virtuelle distante :
Créez un environnement virtuel Python (virtualenv, conda).
Notes
Bien que cela ne soit pas obligatoire, il est recommandé d’utiliser Anaconda ou Miniconda pour gérer les environnements virtuels Python et installer les packages.
Important
Si vous avez un environnement Linux ou macOS et utilisez un interpréteur de commandes autre que Bash (par exemple, zsh), des erreurs peuvent s’afficher lorsque vous exécutez certaines commandes. Pour contourner ce problème, utilisez la commande
bashpour démarrer un nouveau shell Bash et y exécuter les commandes.Activez votre environnement virtuel Python nouvellement créé.
Installez le Kit SDK Python d’Azure Machine Learning.
Pour configurer votre environnement local de sorte qu’il utilise votre espace de travail Azure Machine Learning, créez un fichier de configuration d’espace de travail ou utilisez un fichier existant.
Maintenant que votre environnement local est configuré, vous pouvez commencer à utiliser Azure Machine Learning. Pour commencer, consultez le guide de prise en main d’Azure Machine Learning pour Python.
Notebooks Jupyter
Lorsque vous exécutez un serveur Jupyter Notebook local, nous vous recommandons de créer un noyau IPython pour votre environnement virtuel Python. Cela permet de s’assurer du bon déroulement de l’importation du noyau et du package.
Activer les noyaux IPython spécifiques à l’environnement
conda install notebook ipykernelCréez un noyau pour votre environnement virtuel Python. Veillez à remplacer
<myenv>par le nom de votre environnement virtuel Python.ipython kernel install --user --name <myenv> --display-name "Python (myenv)"Démarrer le serveur Jupyter Notebook
Pour en savoir plus sur Azure Machine Learning et Jupyter Notebooks, consultez le référentiel de notebooks Azure Machine Learning. Consultez également le référentiel piloté par la communauté, AzureML-Examples.
Visual Studio Code
Pour utiliser Visual Studio Code dans le cadre du développement :
Installez Visual Studio Code.
Installer l’extension Azure Machine Learning de Visual Studio Code (préversion).
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Une fois l’extension Visual Studio Code installée, utilisez-la pour :
- Gérer vos ressources Azure Machine Learning
- Lancer Visual Studio Code, connecté à distance à une instance de calcul (préversion)
- Exécuter et déboguer des expériences
- Déployer des modèles entraînés (CLI v2).
Instance de calcul Azure Machine Learning
L’instance de calcul Azure Machine Learning est une station de travail Azure sécurisée et basée sur le cloud, qui fournit aux scientifiques des données un serveur Jupyter Notebook, un JupyterLab et un environnement de Machine Learning entièrement géré.
Vous n’avez rien à installer ou à configurer pour une instance de calcul.
créez à tout moment depuis votre espace de travail Azure Machine Learning. Indiquez juste un nom et spécifiez un type de machine virtuelle Azure. Essayez-le maintenant avec Créer des ressources pour commencer.
Pour en savoir plus sur les instances de calcul, notamment sur la manière d’installer des packages, consultez Créer et gérer une instance de calcul Azure Machine Learning.
Conseil
Pour éviter les frais associés à une instance de calcul inutilisée, arrêtez l’instance de calcul. Ou activez l’arrêt en cas d’inactivité pour l’instance de calcul.
En plus d’un serveur Jupyter Notebook et d’un JupyterLab, vous pouvez utiliser des instances de calcul dans la fonctionnalité de notebook intégrée à Azure Machine Learning Studio.
Vous pouvez également utiliser l’extension Azure Machine Learning Visual Studio Code pour vous connecter à une instance de calcul distante à l’aide de VS Code.
Machine virtuelle de science des données
Data Science VM est une image de machine virtuelle personnalisée que vous pouvez utiliser comme environnement de développement. Elle est conçue pour les travaux de science des données préconfigurés avec les outils et logiciels tels que :
- Des packages tels que TensorFlow, PyTorch, Scikit-learn, XGBoost et le Kit de développement logiciel (SDK) Azure Machine Learning.
- Des outils de science des données appréciés tels que Spark Standalone et Drill.
- Des outils Azure tels que Azure CLI, AzCopy et Explorateur Stockage.
- Des environnements de développement intégrés (IDE) tels que Visual Studio Code et PyCharm.
- Serveur Jupyter Notebook
Pour une liste d’outils complète, consultez le guide des outils Data Science VM.
Important
Si vous envisagez d’utiliser Data Science VM comme cible de calcul pour vos tâches d’apprentissage ou d’inférence, seule la version Ubuntu est prise en charge.
Pour utiliser Data Science VM comme environnement de développement :
Créez une Data Science VM au moyen de l’une des méthodes suivantes :
Utilisez le Portail Azure pour créer une DSVM Ubuntu ou Windows.
Utiliser Azure CLI
Pour créer une Data Science VM Ubuntu, utilisez la commande suivante :
# create a Ubuntu Data Science VM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully # If you need to create a new resource group use: "az group create --name YOUR-RESOURCE-GROUP-NAME --location YOUR-REGION (For example: westus2)" az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --generate-ssh-keys --authentication-type passwordPour créer une DSVM Windows, utilisez la commande suivante :
# create a Windows Server 2016 DSVM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:dsvm-windows:server-2016:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --authentication-type password
Activez l’environnement conda contenant le Kit SDK Azure Machine Learning.
Pour une Data Science VM Ubuntu :
conda activate py36Pour une Data Science VM Windows :
conda activate AzureML
Pour configurer la Data Science VM de manière à utiliser votre espace de travail Azure Machine Learning, créez un fichier de configuration d’espace de travail ou utilisez un fichier existant.
À l’instar des environnements locaux, vous pouvez utiliser Visual Studio Code et l’extension Visual Studio Code d’Azure Machine Learning pour interagir avec Azure Machine Learning.
Pour plus d’informations, consultez la page Machines virtuelles Science des données.
Étapes suivantes
- Entraînez et déployez un modèle sur Azure Machine Learning avec le jeu de données MNIST.
- Voir les informations de référence sur le Kit de développement logiciel (SDK) Azure Machine Learning pour Python.