Afficher le code d’apprentissage d’un modèle ML automatisé
Dans cet article, vous allez apprendre à afficher le code d’entraînement généré d’un modèle de machine learning automatisé entraîné.
La génération de code pour les modèles de machine learning automatisé entraînés vous permet de voir les détails suivants que le machine learning automatisé utilise afin d’entraîner et générer le modèle pour une exécution spécifique.
- Prétraitement des données
- Sélection de l’algorithme
- Caractérisation
- Hyperparamètres
Vous pouvez sélectionner n’importe quel modèle de machine learning automatisé entraîné, une exécution recommandée ou enfant, et afficher le code d’entraînement Python généré qui a créé ce modèle spécifique.
Avec le code d’entraînement du modèle généré, vous pouvez
- Apprendre quel processus de caractérisation et quels hyperparamètres l’algorithme de modèle utilise.
- Suivre/versionner/auditer les modèles entraînés. Stockez le code versionné pour suivre le code d’entraînement spécifique utilisé avec le modèle qui doit être déployé en production.
- Personnaliser le code d’entraînement en modifiant les hyperparamètres ou en appliquant vos compétences/expériences en algorithmes et en ML, et en réentraînant un nouveau modèle avec votre code personnalisé.
Le diagramme suivant illustre que vous pouvez générer le code pour les expériences ML automatisées avec tous les types de tâches. Commencez par sélectionner un modèle. Le modèle que vous avez sélectionné sera mis en surbrillance, puis Azure Machine Learning copiera les fichiers de code utilisés pour créer le modèle et les afficher dans le dossier partagé de vos classeurs. À partir de là, vous pouvez afficher et personnaliser le code selon vos besoins.
Prérequis
Un espace de travail Azure Machine Learning. Pour créer l’espace de travail, consultez Créer des ressources d’espace de travail.
Cet article suppose une connaissance de base en matière de configuration d’une expérience de Machine Learning automatisé. Suivez le didacticiel ou les procédures pour connaître les principaux modèles de conception des expériences de Machine Learning automatisé.
La génération de code de ML automatisée est disponible uniquement pour les expériences exécutées sur des cibles de calcul Azure Machine Learning distantes. La génération de code n’est pas prise en charge pour les exécutions locales.
Toutes les exécutions de ML automatisées déclenchées via Azure Machine Learning Studio, SDKv2 ou CLIv2 auront la génération de code activée.
Obtenir le code généré et les artefacts de modèle
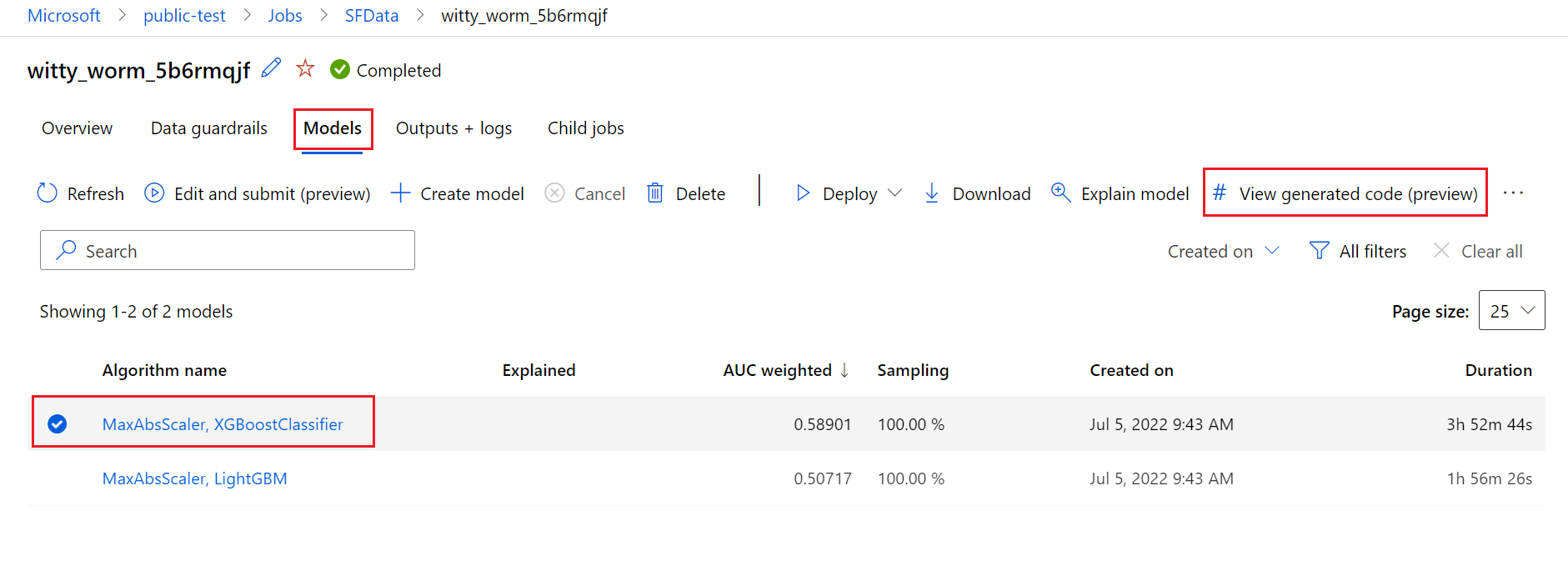
Par défaut, chaque modèle de ML automatisé entraîné génère son code d’entraînement une fois l’entraînement terminé. Le ML automatisé enregistre ce code dans le outputs/generated_code de l’expérience de ce modèle spécifique. Vous pouvez l’afficher dans l’interface utilisateur du studio Azure Machine Learning sous l’onglet Sorties + journaux du modèle sélectionné.
script.py Il s’agit du code d’entraînement du modèle que vous voudrez certainement analyser avec les étapes de caractérisation, de l’algorithme spécifique utilisé et des hyperparamètres.
script_run_notebook.ipynb Notebook avec le code réutilisable pour exécuter le code d’entraînement du modèle (script.py) dans le calcul Azure Machine Learning via Azure Machine Learning SDKv2.
Une fois l’exécution automatisée de l’apprentissage ML terminée, vous pouvez accéder aux fichiers script.py et script_run_notebook.ipynb via l’interface utilisateur Azure Machine Learning studio.
Pour ce faire, accédez à l'onglet Modèles de la page de l'exécution parent de l'expérience ML automatisée. Après avoir sélectionné l’un des modèles entraînés, vous pouvez sélectionner le bouton Afficher le code généré. Ce bouton vous redirige vers l’extension du portail Notebooks, où vous pouvez afficher, modifier et exécuter le code généré pour ce modèle sélectionné en particulier.
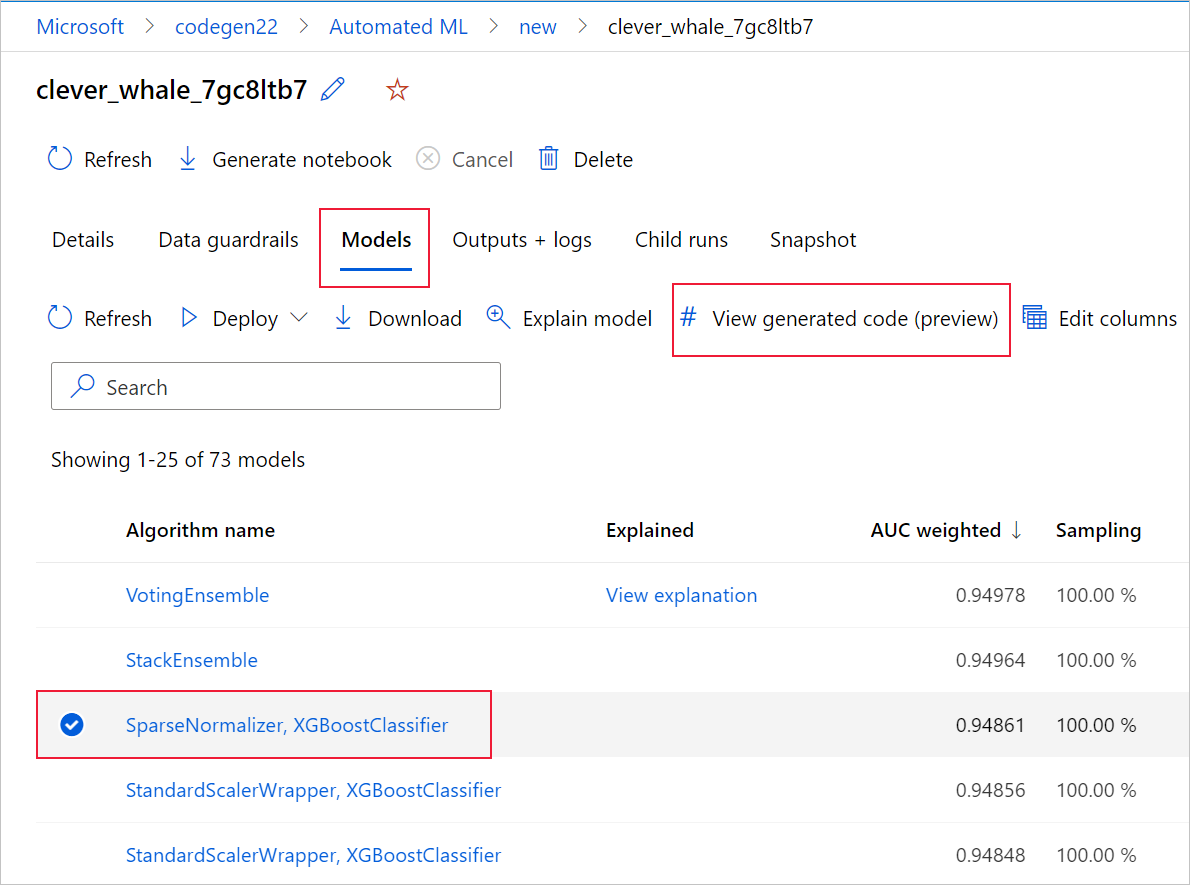
Vous pouvez accéder au code généré du modèle en haut de la page de l’exécution enfant une fois que vous accédez à cette page d’un modèle particulier.
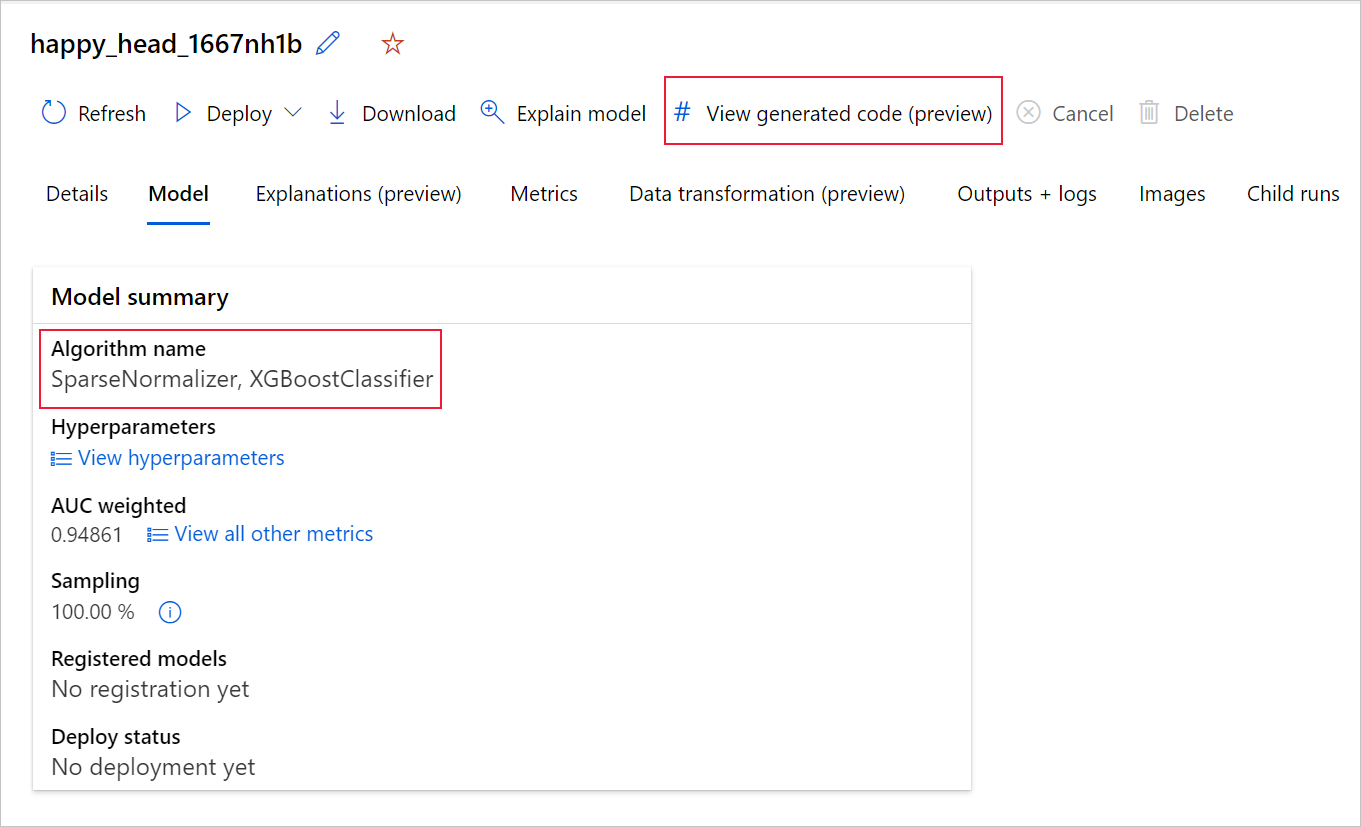
Si vous utilisez le SDKv2 Python, vous pouvez également télécharger les fichiers « script.py » et « script_run_notebook.ipynb » en récupérant la meilleure exécution via MLFlow et en téléchargeant les artefacts obtenus.
Limites
Il existe un problème connu lors de la sélection de View Generated Code. Cette action ne parvient pas à rediriger vers le portail Notebooks lorsque le stockage se trouve derrière un réseau virtuel. Pour contourner le problème, l'utilisateur peut télécharger manuellement les fichiers script.py et script_run_notebook.ipynb en accédant à l'onglet Sorties + Journaux sous le dossier sorties>générées_code. Ces fichiers peuvent être téléchargés manuellement dans le dossier des blocs-notes pour les exécuter ou les modifier. Suivez ce lien pour en savoir plus sur les réseaux virtuels dans Azure Machine Learning.
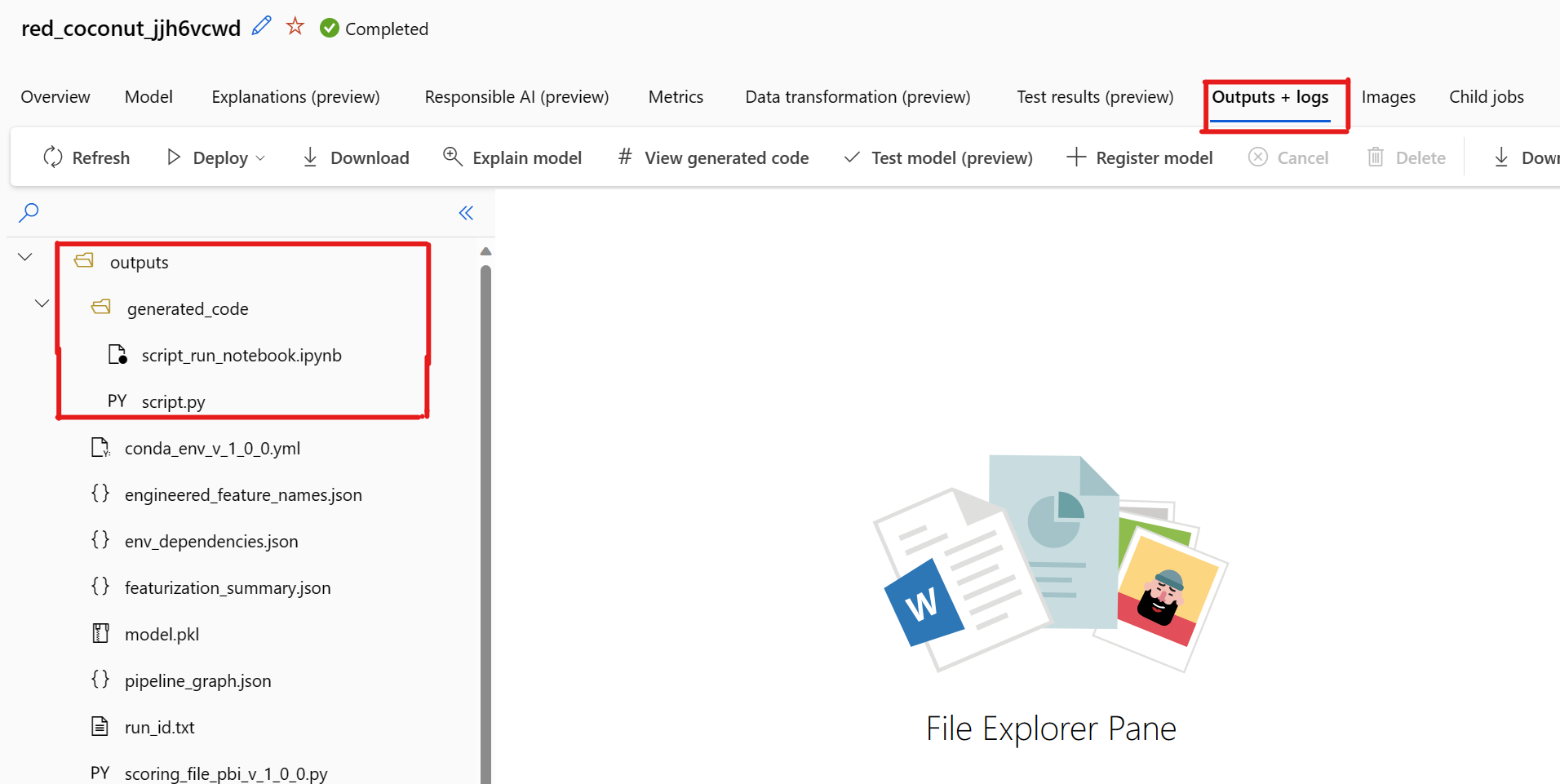
script.py
Le fichier script.py contient la logique principale nécessaire pour entraîner un modèle avec les hyperparamètres précédemment utilisés. Même s’il est destiné à être exécuté dans le contexte d’une exécution de script Azure Machine Learning, avec quelques modifications, le code d’entraînement du modèle peut également être exécuté en mode autonome dans votre propre environnement local.
Le script peut être divisé en plusieurs parties qui seraient grosso modo : chargement des données, préparation des données, caractérisation des données, spécification du préprocesseur/de l’algorithme et entraînement.
Chargement de données
La fonction get_training_dataset() charge le jeu de données précédemment utilisé. Elle part du principe que le script est exécuté dans une exécution de script Azure Machine Learning sous le même espace de travail que l’expérience d’origine.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
En cas d’exécution dans le cadre d’une exécution de script, Run.get_context().experiment.workspace récupère l’espace de travail approprié. Toutefois, si ce script est exécuté dans un autre espace de travail ou s’exécute localement, vous devez modifier le script pour spécifier explicitement l’espace de travail approprié.
Une fois que l’espace de travail a été récupéré, le jeu de données d’origine est récupéré par son ID. Un autre jeu de données avec exactement la même structure peut également être spécifié par l’ID ou le nom avec get_by_id() ou get_by_name(), respectivement. Vous pouvez rechercher l’ID ultérieurement dans le script, dans une section similaire à celle du code suivant.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Vous pouvez également choisir de remplacer cette fonction entière par votre propre mécanisme de chargement de données, les seules contraintes étant que la valeur de retour doit être un dataframe Pandas et que les données doivent avoir la même forme que dans l’expérience d’origine.
Code de préparation des données
La fonction prepare_data() nettoie les données, répartit les colonnes de pondération d’échantillonnage et de caractéristique, puis prépare les données pour l’entraînement.
Cette fonction peut varier en fonction du type de jeu de données et du type de tâche d’expérience : classification, régression, prévision de série chronologique, images ou tâches NLP.
L’exemple suivant montre qu’en général, le dataframe de l’étape de chargement des données est passé. La colonne d’étiquette et les pondérations d’échantillons sont extraites si elles sont spécifiées au départ, tandis que les lignes contenant NaN sont supprimées des données d’entrée.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Si vous souhaitez effectuer davantage de préparation de données, cela peut être fait dans cette étape en ajoutant votre code de préparation de données personnalisé.
Code de caractérisation des données
La fonction generate_data_transformation_config() spécifie l’étape de caractérisation dans le pipeline scikit-learn final. Les caractériseurs de l’expérience d’origine sont reproduits ici, avec leurs paramètres.
Par exemple, la transformation de données possible qui peut se produire dans cette fonction peut être basée sur des imputateurs comme SimpleImputer() et CatImputer(), ou des transformateurs comme StringCastTransformer() et LabelEncoderTransformer().
Voici un transformateur de type StringCastTransformer() qui peut être utilisé pour transformer un ensemble de colonnes. Dans ce cas, l’ensemble indiqué par column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Si vous avez de nombreuses colonnes qui doivent avoir la même fonctionnalité/transformation appliquée (par exemple, 50 colonnes dans plusieurs groupes de colonnes), ces colonnes sont traitées par regroupement en fonction du type.
Dans l’exemple suivant, notez que chaque groupe a un mappeur unique qui lui est appliqué. Ce mappeur est ensuite appliqué à chacune des colonnes de ce groupe.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Cette approche vous permet d’avoir un code plus rationalisé, en évitant d’avoir un bloc de code de transformateur pour chaque colonne, ce qui peut être particulièrement fastidieux lorsque vous avez des dizaines ou des centaines de colonnes dans votre jeu de données.
Avec les tâches de classification et de régression, [FeatureUnion] est utilisé pour les caractériseurs.
Pour les modèles de prévision de série chronologique, plusieurs caractériseurs prenant en charge les séries chronologiques sont collectés dans un pipeline scikit-learn, puis wrappés dans le TimeSeriesTransformer.
Toute caractérisation fournie par l’utilisateur pour les modèles de prévision de série chronologique se produit avant celles fournies par le ML automatisé.
Code de spécification de préprocesseur
La fonction generate_preprocessor_config(), si elle est présente, spécifie une étape de prétraitement à effectuer après la caractérisation dans le pipeline scikit-learn final.
Normalement, cette étape de prétraitement se compose uniquement de la standardisation/normalisation des données qui est effectuée avec sklearn.preprocessing.
Le ML automatisé spécifie uniquement une étape de prétraitement pour les modèles de classification et de régression sans ensemble.
Voici un exemple de code de préprocesseur généré :
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Code de spécification de l’algorithme et des hyperparamètres
Le code de spécification de l’algorithme et des hyperparamètres est probablement ce qui intéresse le plus de nombreux professionnels ML.
La fonction generate_algorithm_config() spécifie l’algorithme et les hyperparamètres réels pour l’entraînement du modèle comme dernière phase du pipeline scikit-learn final.
L’exemple suivant utilise un algorithme XGBoostClassifier avec des hyperparamètres spécifiques.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
Dans la plupart des cas, le code généré utilise des classes et des packages OSS (Open Source Software). Il existe des instances où des classes wrapper intermédiaires sont utilisées pour simplifier le code plus complexe. Par exemple, le classificateur XGBoost et d’autres bibliothèques couramment utilisées, comme les algorithmes LightGBM ou Scikit-Learn, peuvent être appliqués.
En tant que professionnel du ML, vous pouvez personnaliser le code de configuration de cet algorithme en modifiant ses hyperparamètres selon vos besoins en fonction de vos compétences et de votre expérience pour cet algorithme et de votre problème de ML particulier.
Pour les modèles ensemblistes, generate_preprocessor_config_N() (si nécessaire) et generate_algorithm_config_N() sont définis pour chaque apprenant dans le modèle ensembliste, où N représente le positionnement de chaque apprenant dans la liste du modèle ensembliste. Pour les modèles ensemblistes de piles, le méta-apprenant generate_algorithm_config_meta() est défini.
Code d’entraînement de bout en bout
La génération de code émet build_model_pipeline() et train_model() pour définir le pipeline scikit-learn et pour y appeler fit(), respectivement.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
Le pipeline scikit-learn comprend l’étape de caractérisation, un préprocesseur (s’il est utilisé) et l’algorithme ou le modèle.
Pour les modèles de prévision de séries chronologiques, le pipeline scikit-learn est wrappé dans un ForecastingPipelineWrapper, qui a une logique supplémentaire nécessaire pour gérer correctement les données de série chronologique en fonction de l’algorithme appliqué.
Pour tous les types de tâches, nous utilisons PipelineWithYTransformer dans les cas où la colonne d’étiquette doit être encodée.
Une fois que vous avez le pipeline scikit-learn, tout ce qui reste à appeler est la méthode fit() pour entraîner le modèle :
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
La valeur de retour de train_model() est le modèle ajusté/entraîné sur les données d’entrée.
Le code principal qui exécute toutes les fonctions précédentes est le suivant :
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Une fois que vous disposez du modèle entraîné, vous pouvez l’utiliser pour faire des prédictions avec la méthode predict(). Si votre expérience concerne un modèle de série chronologique, utilisez la méthode forecast() pour les prédictions.
y_pred = model.predict(X)
Enfin, le modèle est sérialisé et enregistré sous la forme d’un fichier .pkl nommé « model.pkl » :
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Le notebook script_run_notebook.ipynb constitue un moyen facile d’exécuter script.py sur un calcul Azure Machine Learning.
Ce notebook est semblable aux exemples de notebook de ML automatisé existants. Toutefois, il y a quelques différences clés, comme expliqué dans les sections suivantes.
Environnement
En règle générale, l’environnement d’entraînement pour une exécution de ML automatisé est défini automatiquement par le SDK. Toutefois, lors d’une exécution d’un script personnalisé comme le code généré, le ML automatisé ne conduisant plus le processus, l’environnement doit être spécifié pour que le travail de la commande aboutisse.
La génération de code réutilise l’environnement qui a été utilisé dans l’expérience de ML automatisé d’origine, si possible. Cela garantit que l’exécution du script d’entraînement n’échoue pas en raison de dépendances manquantes. Cela présente aussi l’avantage collatéral de ne pas avoir besoin de recréer les images Docker, ce qui permet de gagner du temps et d’économiser des ressources de calcul.
Si vous apportez des modifications à script.py qui nécessitent des dépendances supplémentaires ou si vous souhaitez utiliser votre propre environnement, vous devez mettre à jour l’environnement dans le script_run_notebook.ipynb en conséquence.
Soumettre l’expérimentation
Étant donné que le code généré n’est plus piloté par le ML automatisé, au lieu de créer et soumettre un travail AutoML, vous devez créer un Command Job et lui fournir le code généré (script.py).
L’exemple suivant contient les paramètres et les dépendances régulières nécessaires à l’exécution d’un travail de commande, comme un calcul, un environnement, etc.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning studio
Étapes suivantes
- Découvrez plus d’informations sur comment et où déployer un modèle.
- Découvrez comment activer les caractéristiques d’interprétabilité spécifiquement au sein d’expériences de ML automatisé.