Configurer une formation AutoML sans code pour les données tabulaires avec l’interface utilisateur du studio
Dans cet article, vous allez configurer des travaux de formation AutoML à l’aide d’AutoML d’Azure Machine Learning dans Azure Machine Learning studio. Cette approche vous permet de configurer le travail sans écrire une seule ligne de code. AutoML est un processus dans lequel Azure Machine Learning sélectionne le meilleur algorithme d’apprentissage automatique pour vos données spécifiques. Ce processus vous permet de générer rapidement des modèles d’apprentissage automatique. Pour plus d’informations, voir l’article sur la vue d’ensemble du processus AutoML.
Ce tutoriel fournit une vue d’ensemble générale de l’utilisation d’AutoML dans le studio. Les articles suivants fournissent des instructions détaillées pour l’utilisation de modèles d’apprentissage automatique spécifiques :
- Classification : Tutoriel : Effectuer l’apprentissage d’un modèle de classification avec AutoML dans le studio
- Prévision de séries chronologiques : Tutoriel : Prévoir la demande avec AutoML dans le studio
- Traitement du langage naturel (NLP) : Configurer AutoML pour effectuer l’apprentissage d’un modèle de traitement en langage naturel (Kit de développement logiciel (SDK) Azure CLI ou Python)
- Vision par ordinateur : Configurer AutoML pour effectuer l’apprentissage des modèles de vision par ordinateur (Kit de développement logiciel (SDK) Azure CLI ou Python)
- Régression : Effectuer l’apprentissage d’un modèle de régression avec AutoML (Kit de développement logiciel (SDK))
Prérequis
Un abonnement Azure. Vous pouvez créer un compte gratuit ou payant pour Azure Machine Learning.
Un espace de travail Azure Machine Learning ou une instance de calcul. Pour préparer ces ressources, consultez Démarrage rapide : Bien démarrer avec Azure Machine Learning.
La ressource de données à utiliser pour le travail de formation AutoML. Ce tutoriel explique comment sélectionner une ressource de données existante ou en créer une à partir d’une source de données, telle qu’un fichier local, une URL web ou un magasin de données. Pour plus d’informations, consultez Créer et gérer des ressources de données.
Important
Les données de formation doivent remplir ces deux exigences :
- Les données doivent être sous forme tabulaire.
- La valeur à prédire (colonne cible) doit être présente dans les données.
Créer une expérience
Créez et exécutez une expérience en procédant comme suit :
Connectez-vous à Azure Machine Learning studio, puis sélectionnez votre abonnement et votre espace de travail.
Dans le menu de gauche, sélectionnez AutoML dans la section Création :
La première fois que vous travaillez avec des expériences dans le studio, vous voyez une liste vide et des liens vers la documentation. Dans les autres cas, vous voyez une liste de vos expériences récentes AutoML, incluant les éléments créés avec le Kit de développement logiciel (SDK) Azure Machine Learning.
Sélectionnez Nouveau travail AutoML pour démarrer le processus Envoyer un travail AutoML.
Par défaut, le processus sélectionne l’option Effectuer l’apprentissage automatiquement dans l’onglet Méthode de formation et passe aux paramètres de configuration.
Dans l’onglet Paramètres de base, entrez les valeurs des paramètres requis, y compris le nom du travail et le nom de l’expérience. Vous pouvez également fournir des valeurs pour les paramètres facultatifs comme il vous convient.
Sélectionnez Suivant pour continuer.

Identifier la ressource de données
Dans l’onglet Type de tâche et données, vous spécifiez la ressource de données de l’expérience et le modèle Machine Learning à utiliser pour effectuer l’apprentissage des données.
Dans ce tutoriel, vous pouvez utiliser une ressource de données existante ou en créer une à partir d’un fichier sur votre ordinateur local. Les pages de l’interface utilisateur du studio changent en fonction de votre sélection pour la source de données et le type de modèle de formation.
Si vous choisissez d’utiliser une ressource de données existante, vous pouvez passer à la section Configurer un modèle de formation.
Pour créer une ressource de données, procédez comme suit :
Pour créer une ressource de données à partir d’un fichier sur votre ordinateur local, sélectionnez Créer.
Dans la page Type de données :
- Entrez le nom de la ressource de données.
- Pour Type, sélectionnez Tabulaire dans la liste déroulante.
- Cliquez sur Suivant.
Dans la page Source de données, sélectionnez À partir de fichiers locaux.
Machine Learning studio ajoute des options supplémentaires au menu de gauche pour que vous configuriez la source de données.
Sélectionnez Suivant pour passer à la page Type de stockage de destination, où vous spécifiez l’emplacement de Stockage Azure pour y charger votre ressource de données.
Vous pouvez spécifier le conteneur de stockage par défaut qui est automatiquement créé avec votre espace de travail ou choisir un conteneur de stockage à utiliser pour l’expérience.
- Pour Type de magasin de données, sélectionnez Stockage Blob Azure.
- Dans la liste des magasins de données, sélectionnez workspaceblobstore.
- Cliquez sur Suivant.
Dans la page Sélection de fichiers et de dossiers, utilisez le menu déroulant Charger des fichiers ou un dossier, puis sélectionnez l’option Charger des fichiers ou Charger un dossier.
- Accédez à l’emplacement des données à charger et sélectionnez Ouvrir.
- Une fois les fichiers chargés, sélectionnez Suivant.
Machine Learning studio valide et charge vos données.
Remarque
Si vos données se trouvent derrière un réseau virtuel, vous devez activer la fonction Ignorer la validation pour vous assurer que l’espace de travail peut accéder à vos données. Pour plus d’informations, consultez Utiliser Azure Machine Learning Studio dans un réseau virtuel Azure.
Vérifiez l’exactitude de vos données chargées sur la page Paramètres. Les champs de la page sont préremplis en fonction du type de fichier de vos données :
Champ Description Format de fichier Définit la disposition et le type des données stockées dans un fichier. Délimiteur Identifie un ou plusieurs caractères pour spécifier la limite entre des régions distinctes et indépendantes dans du texte brut ou d’autres flux de données. Encodage Identifie la table de schéma bits/caractères à utiliser pour lire votre jeu de données. En-têtes de colonne Indique la façon dont les éventuels en-têtes du jeu de données sont traités. Ignorer les lignes Indique le nombre éventuel de lignes ignorées dans le jeu de données. Sélectionnez Suivant pour passer à la page Schéma. Cette page est également préremplie en fonction de vos sélections Paramètres. Vous pouvez configurer le type de données pour chaque colonne, passer en revue les noms des colonnes et gérer celles-ci :
- Pour modifier le type de données d’une colonne, sélectionnez une option dans le menu déroulant Type.
- Pour exclure une colonne de la ressource de données, activez l’option Inclure correspondant à la colonne.
Sélectionnez Suivant pour passer à la page Vérifier. Passez en revue le résumé des paramètres de configuration du travail, puis sélectionnez Créer.
Configurer le modèle de formation
Lorsque la ressource de données est prête, Machine Learning studio retourne à l’onglet Type de tâche et données du processus Envoyer un travail AutoML. La nouvelle ressource de données est répertoriée sur la page.
Suivez ces étapes pour terminer la configuration du travail :
Développez le menu déroulant Sélectionner le type de tâche, puis choisissez le modèle de formation à utiliser pour l’expérience. Les options incluent la classification, la régression, la prévision des séries chronologiques, le traitement du langage naturel (NLP) ou la vision par ordinateur. Pour en savoir plus sur ces options, consultez les descriptions des types de tâches pris en charge.
Après avoir spécifié le modèle de formation, sélectionnez votre jeu de données dans la liste.
Sélectionnez Suivant pour passer à l’onglet Paramètres de tâche.
Dans la liste déroulante Colonne cible, sélectionnez la colonne à utiliser pour les prédictions de modèle.
Selon votre modèle de formation, configurez les paramètres requis suivants :
Classification : indiquez s’il faut Activer le Deep Learning.
Prévision des séries chronologiques : indiquez s’il faut Activer le Deep Learning et confirmez vos préférences pour les paramètres requis :
Utilisez la colonne Heure pour spécifier les données de temps à utiliser dans le modèle.
Choisissez d’activer une ou plusieurs options Détection automatique. Lorsque vous désélectionnez une option Détection automatique, par exemple Détection automatique de l’horizon de prévision, vous pouvez spécifier une valeur spécifique. La valeur Horizon de prévision indique le nombre d’unités de temps (minutes/heures/jours/semaines/mois/années) que le modèle peut prédire pour l’avenir. Plus le modèle devra prédire dans le futur, moins il sera précis.
Pour en savoir plus sur la configuration de ces paramètres, consultez Utiliser AutoML pour effectuer l’apprentissage d’un modèle de prévision des séries chronologiques.
Traitement du langage naturel : confirmez vos préférences pour les paramètres requis :
Utilisez l’option Sélectionner un sous-type pour configurer le type de sous-classification pour le modèle NLP. Vous pouvez choisir entre la classification multiclasse, la classification multi-étiquette et la reconnaissance d’entités nommées (NER).
Dans la section Paramètres de balayage, indiquez des valeurs pour le facteur Slack et l’algorithme d’échantillonnage.
Dans la section Espace de recherche, configurez l’ensemble des options de l’algorithme de modèle.
Pour en savoir plus sur la configuration de ces paramètres, consultez Configurer AutoML pour effectuer l’apprentissage d’un modèle de traitement en langage naturel (Kit de développement logiciel (SDK) Azure CLI ou Python).
Vision par ordinateur : indiquez s’il faut activer Balayage manuel et confirmez vos préférences pour les paramètres requis :
- Utilisez l’option Sélectionner un sous-type pour configurer le type de sous-classification pour le modèle de vision par ordinateur. Vous pouvez choisir entre la classification d’images (multiclasse) ou (multi-étiquette), la détection d’objet et la segmentation d’instance (polygone).
Pour en savoir plus sur la configuration de ces paramètres, consultez Configurer AutoML pour effectuer l’apprentissage des modèles de vision par ordinateur (Kit de développement logiciel (SDK) Azure CLI ou Python).
Spécifier des paramètres facultatifs
Machine Learning studio fournit des paramètres facultatifs que vous pouvez configurer en fonction de la sélection de votre modèle Machine Learning. Les sections suivantes décrivent les paramètres supplémentaires.
Configurer des paramètres supplémentaires
Vous pouvez sélectionner l’option Afficher des paramètres de configuration supplémentaires pour voir les actions à effectuer sur les données en préparation de la formation.
La page Configuration supplémentaire affiche les valeurs par défaut en fonction de la sélection et des données de votre expérience. Vous pouvez utiliser les valeurs par défaut ou configurer les paramètres suivants :
| Setting | Description |
|---|---|
| Métrique principale | Permet d’identifier la métrique principale du scoring de votre modèle. Pour plus d’informations, reportez-vous aux métriques de modèle. |
| Activer l’empilement d’ensembles | Permet l’apprentissage d’ensemble et améliore les résultats de Machine Learning et les performances prédictives en combinant plusieurs modèles. Pour plus d’informations, reportez-vous aux modèles d’ensemble. |
| Utiliser tous les modèles pris en charge | Utilisez cette option pour indiquer à AutoML s’il faut utiliser tous les modèles pris en charge dans l’expérience. Pour en savoir plus, consultez les algorithmes pris en charge pour chaque type de tâche. - Sélectionnez cette option pour configurer le paramètre Modèles bloqués. - Désélectionnez cette option pour configurer le paramètre Modèles autorisés. |
| Modèles bloqués | (Disponible lorsque l’option Utiliser tous les modèles pris en charge est sélectionnée) Utilisez la liste déroulante et sélectionnez les modèles à exclure du travail de formation. |
| Modèles autorisés | (Disponible lorsque l’option Utiliser tous les modèles pris en charge n’est pas sélectionnée) Utilisez la liste déroulante et sélectionnez les modèles à utiliser pour le travail de formation. Important : disponible uniquement pour les expériences du Kit de développement logiciel (SDK). |
| Expliquer le meilleur modèle | Choisissez cette option pour montrer automatiquement l’explicabilité sur le meilleur modèle créé par AutoML. |
| Étiquette de classe positive | Entrez l’étiquette AutoML à utiliser pour calculer les métriques binaires. |
Paramètres de configuration de la caractérisation
Vous pouvez sélectionner l’option Afficher les paramètres de caractérisation pour voir les actions à effectuer sur les données en préparation de la formation.
La page Caractérisation affiche les techniques de caractérisation par défaut pour vos colonnes de données. Vous pouvez activer/désactiver la caractérisation automatique et personnaliser les paramètres correspondants pour votre expérience.

Sélectionnez l’option Activer la caractérisation pour autoriser la configuration.
Important
Lorsque vos données contiennent des colonnes non numériques, la caractérisation est toujours activée.
Configurez chaque colonne disponible, comme vous le souhaitez. Le tableau suivant récapitule les personnalisations actuellement disponibles via le studio.
Colonne Personnalisation Type de caractéristique Modifiez le type valeur de la colonne sélectionnée. Imputer avec Sélectionnez la valeur à imputer aux valeurs manquantes dans vos données. 

Les paramètres de caractérisation n’affectent pas les données d’entrée nécessaires à l’inférence. Si vous excluez les colonnes de la formation, les colonnes exclues sont toujours requises en tant qu’entrée pour l’inférence sur le modèle.
Configurer des limites pour le travail
La section Limites fournit des options de configuration pour les paramètres suivants :
| Setting | Description | active |
|---|---|---|
| Nombre maximal d’essais | Spécifiez le nombre maximal d’essais au cours du travail AutoML, chacun ayant une combinaison différente d’algorithme et d’hyperparamètres. | Entier compris entre 1 et 1 000 |
| Nombre maximal d’essais simultanés | Spécifiez le nombre maximal de travaux d’essai qui peuvent être exécutés en parallèle. | Entier compris entre 1 et 1 000 |
| Nombre maximal de nœuds | Spécifiez le nombre maximal de nœuds que ce travail peut utiliser dans la cible de calcul sélectionnée. | 1 ou plus, selon la configuration du calcul |
| Seuil de score de métrique | Entrez la valeur seuil de la métrique d’itération. Lorsque l’itération atteint le seuil, le travail de formation se termine. N’oubliez pas que les modèles significatifs ont une corrélation supérieure à zéro. Sinon, le résultat est identique à d’une supposition. | Seuil de métrique moyen, compris entre les limites [0, 10] |
| Délai d’expiration de l’expérience (minutes) | Spécifiez la durée maximale d’exécution de l’expérience entière. Une fois que l’expérience a atteint la limite, le système annule le travail AutoML, y compris tous ses essais (travaux enfants). | Nombre de minutes |
| Délai d’expiration d’une itération (minutes) | Spécifiez la durée maximale pendant laquelle chaque travail d’évaluation peut s’exécuter. Une fois que le travail d’évaluation a atteint cette limite, le système annule l’essai. | Nombre de minutes |
| Autoriser l’arrêt anticipé | Utilisez cette option pour mettre fin au travail lorsque le score ne s’améliore pas à court terme. | Sélectionnez l’option permettant d’activer la fin anticipée du travail |
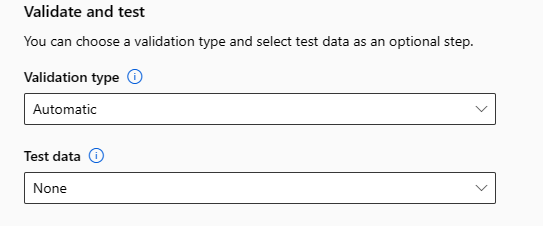
Valider et tester
La section Valider et tester fournit les options de configuration suivantes :
Spécifiez le type de validation à utiliser pour votre travail de formation. Si vous ne spécifiez pas explicitement un paramètre
validation_dataoun_cross_validations, AutoML applique les techniques par défaut en fonction du nombre de lignes fournies dans le jeu de données uniquetraining_data.Taille des données de formation Technique de validation Plus de 20 000 lignes Le fractionnement des données de formation/validation est appliqué. La valeur par défaut consiste à prendre 10 % du jeu de données d’apprentissage initial en tant que jeu de validation. Ce jeu de validation est ensuite utilisé pour le calcul des métriques. Moins de 20 000 lignes L’approche de validation croisée est appliquée. Le nombre de plis par défaut dépend du nombre de lignes.
- Jeu de données comptant moins de 1 000 lignes : 10 plis sont utilisés
- Jeu de données comptant 1 000 à 20 000 lignes : trois plis sont utilisésFournissez les données de test (version préliminaire) pour évaluer le modèle recommandé qu’AutoML génère à la fin de votre expérience. Lorsque vous fournissez un jeu de données de test, un travail de test est déclenché automatiquement à la fin de votre expérience. Ce travail de test est le seul travail exécuté sur le meilleur modèle recommandé par AutoML. Pour en savoir plus, voir Afficher les résultats d’un travail de test distant (préversion).
Important
Fournir un jeu de données de test pour évaluer les modèles générés est une fonctionnalité en préversion. Il s’agit d’une fonctionnalité expérimentale en préversion qui peut évoluer à tout moment.
Les données de test sont considérées comme distinctes de la formation et de la validation, afin de ne pas biaiser les résultats du travail de test du modèle recommandé. Pour en savoir plus, voir Données de formation, de validation et de test.
Vous pouvez fournir votre propre jeu de données de test ou choisir d’utiliser un pourcentage de votre jeu de données d’apprentissage. Les données de test doivent se présenter sous la forme d’un jeu de données tabulaires Azure Machine Learning.
Le schéma du jeu de données de test doit correspondre au jeu de données d’apprentissage. La colonne cible est facultative, mais si aucune colonne cible n’est indiquée, aucune mesure de test n’est calculée.
Le jeu de données de test ne doit pas être identique au jeu de données de formation ni au jeu de données de validation.
Les travaux de prévision ne prennent pas en charge le fractionnement formation/test.
Configurer la capacité de calcul
Pour configurer la capacité de calcul, procédez comme suit :
Sélectionnez Suivant pour passer à l’onglet Capacité de calcul.
Dans la liste déroulante Sélectionner le type de calcul, choisissez une option pour le profilage des données et le travail de formation. Les options incluent cluster de calcul, instance de calcul ou serverless.
Après avoir sélectionné le type de calcul, l’autre interface utilisateur de la page change en fonction de votre sélection :
Serverless : les paramètres de configuration s’affichent sur la page active. Passez à l’étape suivante pour obtenir des descriptions des paramètres à configurer.
Cluster de calcul ou Instance de calcul : choisissez parmi les options suivantes :
Dans la liste déroulante Sélectionner une capacité de calcul AutoML, sélectionnez une capacité de calcul existante pour votre espace de travail, puis Suivant. Passez à la section Exécuter une expérience et afficher les résultats.
Sélectionnez Nouveau pour créer une instance de calcul ou un cluster de calcul. Cette option permet d’ouvrir la page Créer une capacité de calcul. Passez à l’étape suivante pour obtenir des descriptions des paramètres à configurer.
Pour un calcul serverless ou un nouveau calcul, configurez les paramètres requis (*) :
Les paramètres de configuration diffèrent en fonction de votre type de calcul. Le tableau suivant récapitule les différents paramètres que vous devrez peut-être configurer :
Champ Description Nom de la capacité de calcul Entrez un nom unique qui identifie votre contexte de calcul. Lieu Spécifiez la région de la machine. Priorité de machine virtuelle Les machines virtuelles basse priorité sont moins chères, mais ne garantissent pas les nœuds de calcul. Type de machine virtuelle Sélectionnez l’UC ou le GPU pour le type de machine virtuelle. Niveau de machine virtuelle Sélectionnez la priorité de votre expérience. Taille de la machine virtuelle Sélectionnez la taille de la machine virtuelle pour votre calcul. Nombre minimal/maximal de nœuds Pour profiler des données, vous devez spécifier un ou plusieurs nœuds. Entrez le nombre maximal de nœuds pour votre calcul. La valeur par défaut est de six nœuds pour une Capacité de calcul Machine Learning Azure. Secondes d’inactivité avant le scale-down Spécifiez la durée d’inactivité avant que le cluster ne fasse l’objet d’un scale-down au nombre de nœuds minimal. Paramètres avancés Ces paramètres vous permettent de configurer un compte d’utilisateur et un réseau virtuel existant pour votre expérience. Après avoir configuré les paramètres requis, sélectionnez Suivant ou Créer, le cas échéant.
La création d’un calcul peut prendre quelques minutes. Une fois la création terminée, sélectionnez Suivant.
Exécuter une expérience et afficher les résultats
Sélectionnez Terminer pour exécuter votre expérience. Le processus de préparation de l’expérience peut prendre jusqu’à 10 minutes. Les travaux de formation peuvent prendre 2 à 3 minutes supplémentaires pour que chaque pipeline se termine. Si vous avez spécifié de générer le tableau de bord IAR pour le meilleur modèle recommandé, cela peut prendre jusqu’à 40 minutes.
Remarque
Les algorithmes utilisés par AutoML présentent un fonctionnement aléatoire inhérent qui peut provoquer de légères variations dans un score de métrique final de modèle recommandé, comme la précision. AutoML exécute également des opérations au niveau des données, telles que le fractionnement formation/test, le fractionnement formation/validation ou la validation croisée, le cas échéant. Si vous exécutez plusieurs fois une expérience avec les mêmes paramètres de configuration et la même métrique principale, vous constaterez probablement des variations dans chaque score de métrique finale d’expériences en raison de ces facteurs.
Afficher les détails de l'expérience
L’écran Détails du travail ouvre l’onglet Détails. Cet écran vous montre un récapitulatif du travail de l’expérience, notamment une barre d’état en haut à côté du numéro de travail.
L’onglet Modèles contient une liste des modèles créés affichés selon leur score de métrique. Par défaut, le modèle qui obtient la valeur la plus élevée d’après la métrique choisie figure en haut de la liste. À mesure que le travail de formation essaie d’autres modèles, les modèles testés sont ajoutés à la liste. Utilisez cette approche pour obtenir une comparaison rapide des métriques des modèles déjà produits.
Afficher les détails d’un travail d’apprentissage
Explorez les modèles terminés pour afficher les détails du travail de formation. Vous pouvez consulter les graphiques de métriques de performances de modèles spécifiques dans l’onglet Métriques. Pour en savoir plus, voir Évaluer les résultats de l’expérience de Machine Learning automatisé. Sur cette page, vous trouverez des détails sur toutes les propriétés du modèle, ainsi que le code, les travaux enfants et les images associés.
Afficher les résultats d’un travail d’apprentissage distant (préversion)
Si vous avez spécifié un jeu de données de test ou si vous avez opté pour un fractionnement formation/test au cours de la configuration de votre expérience, dans le formulaire Valider et tester, AutoML teste automatiquement le modèle recommandé par défaut. Par conséquent, AutoML calcule les métriques de test pour déterminer la qualité du modèle recommandé et de ses prédictions.
Important
Le test de vos modèles avec un jeu de données de test pour évaluer les modèles générés est une fonctionnalité en préversion. Il s’agit d’une fonctionnalité expérimentale en préversion qui peut évoluer à tout moment.
Cette fonctionnalité n’est pas disponible pour les scénarios AutoML suivants :
- Tâches de vision par ordinateur
- Formation à la prévision d’un grand nombre de modèles et de séries chronologiques hiérarchiques (préversion)
- Tâches de prévision pour lesquelles le deep learning des réseaux neuronaux (DNN) est activé
- Exécution de travaux de ML automatisé à partir de calculs locaux ou de clusters Azure Databricks
Pour afficher les métriques de travail de test du modèle recommandé, procédez comme suit :
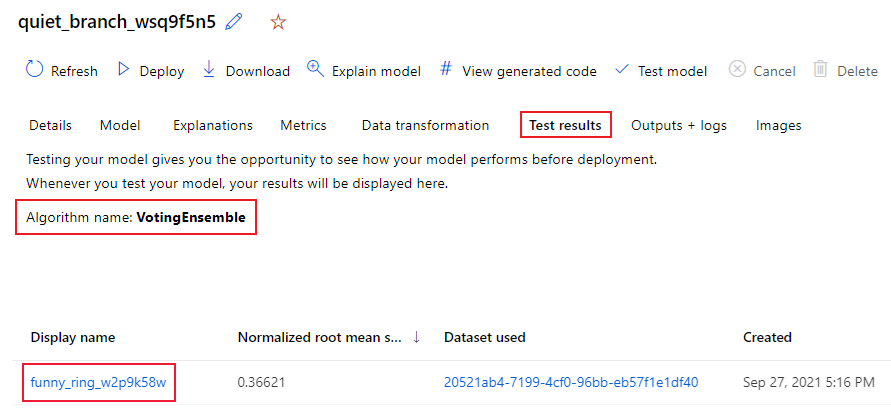
Dans le studio, accédez à la page Modèles, puis sélectionnez le meilleur modèle.
Sélectionnez l’onglet résultats des tests ( préversion).
Sélectionnez le travail souhaité, puis affichez l’onglet Métriques :
Pour afficher les prédictions de test utilisées pour calculer les métriques de test, procédez comme suit :
En bas de la page, sélectionnez le lien sous Jeu de données de sorties pour ouvrir le jeu de données.
Dans la page jeux de données, sélectionnez l’onglet Explorer pour afficher les prédictions de du travail de test.
Vous pouvez également afficher et télécharger le fichier de prédiction à partir de l’onglet Sorties + journaux. Développez le dossier Prédictions pour localiser votre fichier prediction.csv.
Le travail de test de modèle génère le fichier predictions.csv qui est stocké dans le magasin de données par défaut créé avec l’espace de travail. Ce magasin données est visible par tous les utilisateurs d’un même abonnement. Les travaux de tests ne sont pas recommandées pour des scénarios où les informations utilisées ou créées par le travail de test doivent rester privées.
Tester un modèle AutoML existant (version préliminaire)
Une fois votre expérience terminée, vous pouvez tester les modèles générés par AutoML pour vous.
Important
Le test de vos modèles avec un jeu de données de test pour évaluer les modèles générés est une fonctionnalité en préversion. Cette capacité est une caractéristique expérimentale en préversion qui peut évoluer à tout moment.
Cette fonctionnalité n’est pas disponible pour les scénarios AutoML suivants :
- Tâches de vision par ordinateur
- Formation à la prévision d’un grand nombre de modèles et de séries chronologiques hiérarchiques (préversion)
- Tâches de prévision pour lesquelles le deep learning des réseaux neuronaux (DNN) est activé
- Exécution de travaux de ML automatisé à partir de calculs locaux ou de clusters Azure Databricks
Pour tester un autre modèle AutoML généré, et non le modèle recommandé, procédez comme suit :
Sélectionnez un travail d’expérience AutoML existant.
Accédez à l’onglet Modèles du travail et sélectionnez le modèle terminé que vous souhaitez tester.
Sur la page Détails du modèle, sélectionnez l’option Tester le modèle (version préliminaire) pour ouvrir le volet Tester le modèle.
Dans le volet Modèle de test, sélectionnez le cluster de calcul et un jeu de données de test que vous souhaitez utiliser pour votre travail de test.
Sélectionnez l’option Test. Le schéma du jeu de données de test doit correspondre au jeu de données de formation, mais la Colonne cible est facultative.
En cas de création réussie d’un travail de test de modèle, la page Détails affiche un message de réussite. Sélectionnez l’onglet Résultats des tests pour afficher la progression du travail.
Pour afficher les résultats du travail de test, ouvrez la page Détails et suivez les étapes de la section Afficher les résultats d’un travail de test distant (préversion).
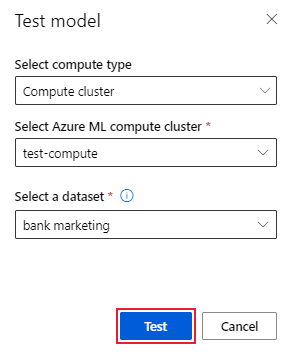
Tableau de bord IA responsable (préversion)
Pour mieux comprendre votre modèle, vous pouvez voir différents insights sur votre modèle en utilisant le tableau de bord IA responsable. Cette interface utilisateur vous permet d’évaluer et de déboguer votre meilleur modèle AutoML. Le tableau de bord IA responsable évalue des erreurs de modèle et des problèmes d’impartialité, diagnostique pourquoi ces erreurs se produisent en évaluant vos données de formation et/ou de test, et observe les explications du modèle. Ensemble, ces insights peuvent vous aider à établir une confiance avec votre modèle et à réussir les processus d’audit. Les tableaux de bord IA responsable ne peuvent pas être générés pour un modèle AutoML existant. Le tableau de bord est créé uniquement pour le meilleur modèle recommandé lorsqu’un nouveau travail AutoML est créé. Les utilisateurs doivent continuer à utiliser les Explications de modèle (préversion) jusqu’à ce que la prise en charge des modèles existants soit assurée.
Pour générer un tableau de bord IA responsable pour un modèle particulier, procédez comme suit :
Lors de l’envoi d’un travail AutoML, passez à la section Paramètres de tâche dans le menu de gauche et sélectionnez l’option Afficher des paramètres de configuration supplémentaires.
Dans la page Configuration supplémentaire, sélectionnez l’option Expliquer le meilleur modèle :
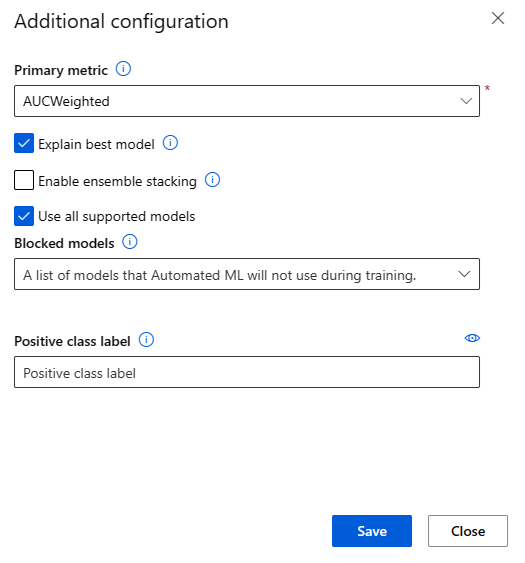
Basculez vers l’onglet Capacité de calcul, puis sélectionnez l’option Serverless pour votre calcul :
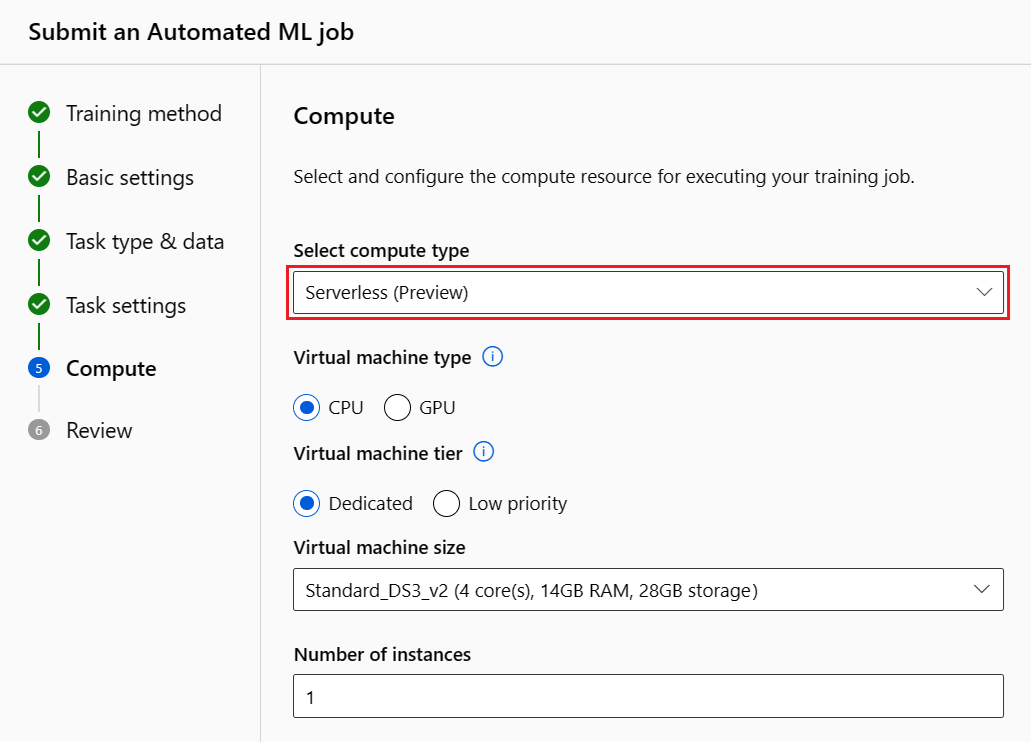
À l’issue de l’opération, accédez à la page Modèles de votre travail AutoML qui contient la liste de vos modèles formés. Sélectionnez le lien Afficher le tableau de bord IA responsable :

Le tableau de bord IA responsable s’affiche pour le modèle sélectionné :

Dans le tableau de bord, vous voyez quatre composants activés pour le meilleur modèle AutoML :
Composant Que montre le composant ? Comment lire le graphique ? Analyse des erreurs Utilisez l’analyse des erreurs lorsque vous devez :
- Acquérir une compréhension approfondie de la manière dont les défaillances de modèle sont distribuées dans un jeu de données et dans plusieurs dimensions d’entrée et de caractéristique
- Décomposer les métriques de performances agrégées pour découvrir automatiquement les cohortes erronées afin de documenter vos étapes d’atténuation cibléesGraphiques d’analyse des erreurs Vue d’ensemble du modèle et impartialité Utilisez ce composant pour :
- Obtenir une compréhension approfondie des performances de votre modèle entre différentes cohortes de données
- Comprendre les problèmes d’impartialité de votre modèle en examinant les métriques de disparité Ces métriques peuvent évaluer et comparer le comportement du modèle dans des sous-groupes identifiés en termes de fonctionnalités sensibles (ou non sensibles).Vue d’ensemble du modèle et graphiques d’impartialité Explications de modèle Utilisez le composant d’explication de modèle pour générer des descriptions compréhensibles par l’humain des prédictions d’un modèle Machine Learning en examinant :
- Explications globales : par exemple, quelles caractéristiques affectent le comportement général d’un modèle de demande de prêt ?
Explications locales : par exemple, pourquoi la demande de prêt d’un client a-t-elle été approuvée ou rejetée ?Graphique d’explicabilité du modèle Analyse des données Utilisez l’analyse des erreurs quand vous devez effectuer les opérations suivantes :
- Explorer vos statistiques de jeu de données en sélectionnant différents filtres pour segmenter vos données en différentes dimensions (également appelées cohortes)
- Comprendre la distribution de votre jeu de données entre différentes cohortes et différents groupes de caractéristiques
- Déterminer si vos résultats liés à l’impartialité, à l’analyse des erreurs et à la causalité (dérivés d’autres composants de tableau de bord) sont le résultat de la distribution de votre jeu de données
- Déterminer les zones où collecter davantage de données pour atténuer les erreurs résultant de problèmes de représentation, de bruit d’étiquette, de bruit de caractéristique, de biais d’étiquette et de facteurs similairesGraphiques Data Explorer Vous pouvez créer des cohortes (sous-groupes de points de données partageant des caractéristiques spécifiées) sur lesquelles concentrer votre analyse dans chaque composant sur différentes cohortes. Le nom de la cohorte actuellement appliquée au tableau de bord est toujours affiché en haut à gauche de votre tableau de bord. L’affichage par défaut dans votre tableau de bord est votre jeu de données complet, intitulé Toutes les données par défaut. Pour plus d’informations, consultez les Contrôles globaux de votre tableau de bord.


Modifier et envoyer des travaux (préversion)
Lorsque vous souhaitez créer une expérience basée sur les paramètres d’une expérience existante, AutoML fournit l’option Modifier et envoyer dans l’interface utilisateur du studio. Cette fonctionnalité est limitée aux expériences lancées à partir de l’interface utilisateur de Studio et nécessite que le schéma de données de la nouvelle expérience corresponde à celui de l’expérience d’origine.
Important
La possibilité de copier, modifier et envoyer une nouvelle expérience basée sur une expérience existante est une fonctionnalité en préversion. Il s’agit d’une fonctionnalité expérimentale en préversion qui peut évoluer à tout moment.
L’option Modifier et envoyer ouvre l’Assistant Créer un travail AutoML avec les paramètres de données, de calcul et d’expérience préremplis. Vous pouvez configurer les options de chaque onglet de l’Assistant et modifier les sélections en fonction des besoins de votre nouvelle expérience.
Déployer votre modèle
Une fois le meilleur modèle obtenu, vous pouvez le déployer en tant que service web pour prédire de nouvelles données.
Remarque
Pour déployer un modèle généré par le biais du package automl avec le Kit de développement logiciel (SDK) Python, vous devez enregistrer votre modèle dans l’espace de travail.
Après avoir enregistré le modèle, vous pouvez le localiser dans le studio en sélectionnant Modèles dans le menu de gauche. Dans la page de présentation du modèle, vous pouvez sélectionner l’option Déployer et passer à l’étape 2 de cette section.
AutoML vous aide à déployer le modèle sans écrire de code.
Lancez le déploiement à l’aide de l’une des méthodes suivantes :
Déployez le meilleur modèle avec les critères de métrique que vous avez définis :
Une fois l’expérience terminée, sélectionnez Travail 1 et accédez à la page du travail parent.
Sélectionnez le modèle figurant dans la section Résumé du meilleur modèle, puis Déployer.
Déployez une itération de modèle spécifique à partir de cette expérience :
- Sélectionnez le modèle souhaité dans l’onglet Modèles, puis Déployer.
Renseignez le volet Déployer le modèle :
Champ Valeur Nom Entrez un nom unique pour votre déploiement. Description Entrez une description pour mieux identifier l’objet du déploiement. Type de capacité de calcul Sélectionnez le type de point de terminaison que vous souhaitez déployer : service Azure Kubernetes (AKS) ou Azure Container instance (ACI). Nom de la capacité de calcul (S’applique à AKS uniquement) Sélectionnez le nom du cluster AKS sur lequel vous voulez effectuer le déploiement. Activer l’authentification Sélectionnez cette option pour l’authentification basée sur des jetons ou sur des clés. Utiliser les ressources d’un déploiement personnalisé Activez les ressources personnalisées si vous voulez charger votre propre script de scoring et votre fichier d’environnement. Dans le cas contraire, AutoML fournit ces ressources par défaut. Pour plus d’informations, consultez Déployer et scorer un modèle Machine Learning en utilisant un point de terminaison en ligne. Important
Les noms de fichiers doivent comprendre entre 1 et 32 caractères. Le nom doit commencer et se terminer par des caractères alphanumériques, et peut inclure dans l’intervalle des tirets, des traits de soulignement, des points et des caractères alphanumériques. Les espaces ne sont pas autorisés.
Le menu Avancé offre des fonctionnalités de déploiement par défaut, comme la collecte de données et des paramètres d’utilisation des ressources. Vous pouvez utiliser les options de ce menu pour remplacer ces valeurs par défaut. Pour plus d’informations, consultez Superviser des points de terminaison en ligne.
Sélectionnez Déployer. Le déploiement peut prendre environ 20 minutes.
Une fois le déploiement démarré, l’onglet Résumé du modèle s’ouvre. Vous pouvez surveiller la progression du déploiement dans la section État du déploiement.
Vous disposez maintenant d’un service web opérationnel pour générer des prédictions ! Vous pouvez tester les prédictions en interrogeant le service à partir des exemples d’IA de bout en bout dans Microsoft Fabric.