Gestion de la continuité d’activité dans Azure
Azure gère l’un des programmes de gestion de la continuité des activités les plus aboutis et les plus respectés du secteur. L’objectif de la continuité des activités dans Azure est de générer et d’anticiper la capacité de récupération et de résilience pour tous les services récupérables indépendamment, qu’il s’agisse d’un service soit orienté client (faisant partie d’une offre Azure) ou d’un service de plateforme de support interne.
Pour comprendre la continuité des activités, il est important de noter que de nombreuses offres sont constituées de plusieurs services. Dans Azure, chaque service est identifié de manière statique par le biais d’outils et est l’unité de mesure utilisée pour la confidentialité, la sécurité, l’inventaire, la gestion du risque de la continuité des activités et d’autres fonctions. Pour mesurer correctement les capacités d’un service, les trois éléments personnes, processus et technologies sont inclus pour chaque service, quel que soit le type de service.
Par exemple :
- Si un processus métier est basé sur des personnes, comme un support technique ou une équipe, la prestation de service est ce que font ces personnes. Les personnes utilisent des processus et de la technologie pour exécuter le service.
- En cas de technologie en tant que service, comme les machines virtuelles Azure, la prestation de service regroupe la technologie, ainsi que les personnes et les processus qui prennent en charge son fonctionnement.
Modèle de responsabilité partagée
La plupart des offres qu’Azure fournit vous obligent à configurer la récupération d’urgence dans plusieurs régions et ne sont pas responsables de Microsoft. Tous les services Azure ne répliquent pas automatiquement les données. Tous ne se retirent pas non plus automatiquement d’une région défaillante pour effectuer une réplication croisée vers une autre région compatible. Dans ces cas, vous êtes responsable de la configuration de la récupération et de la réplication.
Microsoft s’assure que l’infrastructure et les services de plateforme de base sont disponibles. Toutefois, dans certains scénarios, l’utilisation exige que vous dupliquez vos déploiements et stockage dans une capacité multirégion, si vous choisissez de le faire. Ces exemples illustrent le modèle de responsabilité partagée. Il s’agit d’un pilier fondamental de votre stratégie de récupération d’urgence et de continuité des activités.
Répartition des responsabilités
Dans un centre de données local, vous être propriétaire de la pile entière. Quand vous migrez des ressources vers le cloud, certaines responsabilités sont transférées à Microsoft. Le schéma suivant illustre les domaines et la division des responsabilité entre vous et Microsoft, selon le type de déploiement.
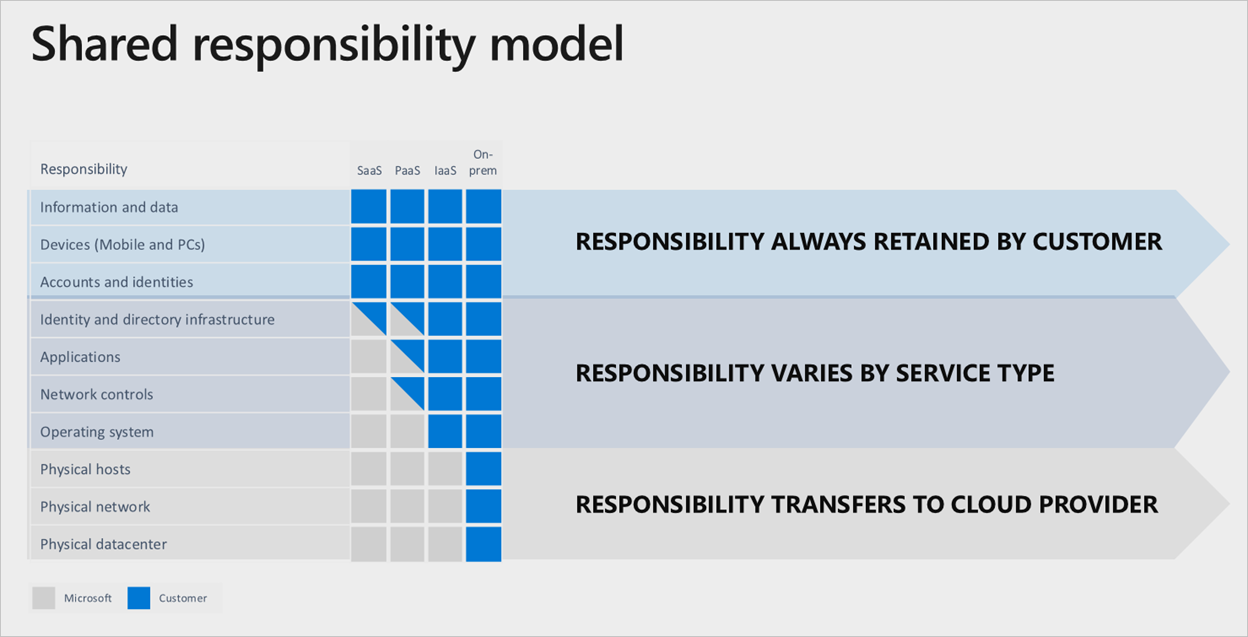
Un bon exemple du modèle de responsabilité partagée est le déploiement de machines virtuelles. Si vous souhaitez configurer la réplication interrégion pour la résilience en cas d’échec de région, vous devez déployer un ensemble de machines virtuelles en double dans une autre région activée. Azure ne réplique pas automatiquement ces services en cas de défaillance. Il vous incombe de déployer les ressources nécessaires. Vous devez avoir un processus de modification manuelle des régions primaires, ou vous devez utiliser un gestionnaire de trafic pour détecter et basculer automatiquement.
Les services de récupération d’urgence activés par le client ont tous une documentation publique pour vous guider. Pour obtenir un exemple de documentation publique pour la récupération d’urgence activée par le client, consultez Azure Data Lake Analytics.
Pour plus d’informations sur le modèle de responsabilité partagée, consultez Centre de gestion de la confidentialité Microsoft.
Conformité de la continuité des activités : responsabilité au niveau du service
Chaque service doit effectuer des enregistrements de récupération d’urgence de continuité des activités dans l’outil Gestionnaire de continuité des activités Azure. Les propriétaires de services peuvent utiliser l’outil pour travailler au sein d’un modèle fédéré afin de compléter et d’incorporer les exigences qui incluent :
Propriétés du service : définit le service et comment la récupération d’urgence et la résilience sont réalisées, et identifie le tiers responsable de la récupération d’urgence (pour la technologie). Pour plus d’informations sur la propriété de la récupération, consultez la discussion sur le modèle de responsabilité partagée dans la section et le schéma ci-dessus.
Analyse de l’impact sur l’activité : cette analyse aide le propriétaire du service à définir l’objectif de délai de récupération (RTO) et l’objectif de point de récupération (RPO) en fonction de l’importance du service dans une table d’impacts. Les impacts opérationnels, juridiques, réglementaires, sur l’image de marque et financiers sont utilisés comme objectifs de récupération.
Remarque
Microsoft ne publie pas de RTO ou de RPO pour les services, car ces données sont destinées uniquement à des mesures internes. Toutes les promesses et mesures du client sont basées sur le contrat SLA, car il couvre une plage plus large par rapport au RTO ou au RPO, qui ne sont applicables qu’en cas de perte catastrophique.
Dépendances : chaque service mappe les dépendances (autres services) dont il a besoin pour fonctionner, quel que soit son importance, et est mappé au runtime, nécessaire uniquement pour la récupération, ou les deux. S’il existe des dépendances de stockage, d’autres données sont mappées qui définissent ce qui est stocké et si des instantanés jusqu’à une date et heure sont requis, par exemple.
Force de travail : comme indiqué dans la définition d’un service, il est important de connaître l’emplacement et la quantité de personnel pouvant prendre en charge le service, de s’assurer qu’aucun point de défaillance n’est présent, et si les employés importants sont dispersés pour éviter les défaillances par la colocalisation dans un même emplacement.
Fournisseurs externes : Microsoft conserve une liste complète des fournisseurs externes et les capacités des fournisseurs considérés comme critiques sont mesurées. Si elles sont identifiées par un service en tant que dépendance, les capacités des fournisseurs sont comparées aux besoins du service afin de garantir qu’une panne tierce n’interrompt pas les services Azure.
Évaluation de la récupération : cette évaluation est propre au programme de gestion de la continuité des activités Azure. Cette évaluation mesure plusieurs éléments clés pour créer un score de résilience :
- Possibilité de basculer : bien qu’il puisse y avoir un processus, cela peut ne pas être le premier choix pour les pannes à long terme.
- Automatisation du basculement.
- Automatisation de la décision de basculer.
Le temps de basculement le plus fiable et le plus bref est un service automatisé qui ne nécessite aucune décision humaine. Un service automatisé utilise la surveillance des pulsations ou des transactions synthétiques pour déterminer si un service est en panne et démarrer la correction immédiatement.
Plan et test de récupération : Azure exige que chaque service dispose d’un plan de récupération détaillé et teste ce plan comme si le service avait échoué en raison d’une panne catastrophique. Les plans de récupération doivent être écrits de manière à ce qu’une personne disposant de compétences et d’un accès similaires puisse effectuer les tâches. Un plan écrit évite d’avoir à se reposer sur des experts en la matière.
Les tests sont effectués de plusieurs façons, notamment des tests automatiques dans un environnement de production ou de quasi-production, et dans le cadre des exercices dans une région complète Azure dans des groupes de régions de test. Ces régions activées sont identiques aux régions de production, mais peuvent être désactivées sans affecter vos services. Les tests sont considérés comme intégrés, car tous les services sont affectés simultanément.
Activation du client : lorsque vous êtes responsable de la configuration de la reprise d’activité après sinistre, Azure doit disposer d’instructions sur la documentation publique. Pour tous ces services, des liens sont fournis vers la documentation et les détails sur le processus.
Vérifier votre conformité de la continuité des activités
Lorsqu’un service a terminé son enregistrement de gestion de la continuité des activités, vous devez l’envoyer pour approbation. Il est assignée à un expert en matière de gestion de la continuité des activités, qui révise l’intégralité et la qualité de l’enregistrement. Si l’enregistrement remplit toutes les conditions requises, il est approuvé. Si ce n’est pas le cas, il est rejeté avec une demande de retravail. Ce processus garantit que les deux parties conviennent que la conformité de la continuité des activités a été respectée et que le travail est uniquement sanctionné par le propriétaire du service. Les équipes de conformité et d’audit internes d’Azure effectuent également un échantillonnage aléatoire périodique pour s’assurer que les meilleures données sont envoyées.
Test des services
Microsoft et Azure effectuent des tests intensifs pour la récupération d’urgence et la préparation des zones de disponibilité. Les services sont auto-testés dans un environnement de production ou de pré-production pour illustrer la récupération indépendante des services qui ne dépendent pas des basculements de plateformes majeures.
Pour s’assurer que les services peuvent être restaurés de la même façon dans un scénario où la région connaît véritablement une défaillance, les tests de type « pull-the-plug » sont effectués dans des environnements de test qui sont des régions entièrement déployées correspondant à la production. Par exemple, les clusters, les racks et les unités d’alimentation sont littéralement éteints pour simuler un échec total de la région.
Au cours de ces tests, Azure utilise le même processus de production pour la détection, la notification, la réponse et la récupération. Personne ne s’attend à un exercice et les ingénieurs en charge de la récupération sont les ressources en service standard. Cette planification évite de dépendre d’experts en la matière qui peuvent ne pas être disponibles pendant un événement réel.
Inclus dans ces tests sont des services dans lesquels vous êtes responsable de la configuration de la reprise d’activité après la documentation publique de Microsoft. Les équipes de service créent des instances de type client pour montrer que la récupération d’urgence activée par le client fonctionne comme prévu et que les instructions fournies sont exactes.
Pour plus d’informations sur les certifications, consultez le Centre de gestion de la confidentialité Microsoft et la section sur la conformité.