Tutoriel REST : Utiliser des ensembles de compétences pour générer du contenu pouvant faire l’objet d’une recherche dans Recherche Azure AI
Dans ce tutoriel, découvrez comment appeler des API REST qui créent un pipeline d’enrichissement par IA pour l’extraction de contenu et les transformations lors de l’indexation.
Les ensembles de compétences ajoutent un traitement IA au contenu brut, ce qui rend ce contenu plus uniforme et le rendant disponible pour faire l’objet d’une recherche. Une fois que vous savez comment fonctionnent les ensembles de compétences, vous pouvez prendre en charge un large éventail de transformations : de l’analyse d’images, au traitement en langage naturel, au traitement personnalisé que vous fournissez en externe.
Dans ce tutoriel, vous allez voir comment :
- Définissez des objets dans un pipeline d’enrichissement.
- Créez un ensemble de compétences. Appeler la reconnaissance optique de caractères (OCR), la détection de langage, la reconnaissance d’entités et l’extraction de phrases clés.
- Exécutez le pipeline. Créez et chargez un index de recherche.
- Vérifiez les résultats en utilisant la recherche en texte intégral.
Si vous n’avez pas d’abonnement Azure, ouvrez un compte gratuit avant de commencer.
Vue d’ensemble
Ce tutoriel utilise un client REST et les API REST Recherche Azure AI pour créer une source de données, un index, un indexeur et un ensemble de compétences.
L’indexeur pilote chaque étape du pipeline, en commençant par l’extraction de contenu d’exemples de données (texte non structuré et images) dans un conteneur d’objets blob sur Stockage Azure.
Une fois le contenu extrait, l’ensemble de compétences exécute des compétences intégrées de Microsoft pour rechercher et extraire des informations. Ces compétences incluent la reconnaissance optique de caractères (OCR) sur des images, la détection de la langue d’un texte, l’extraction des expressions clés et la reconnaissance d’entités (organisations). Les nouvelles informations créées par l’ensemble de compétences sont envoyées aux champs d’un index. Une fois l’index rempli, vous pouvez utiliser les champs dans des requêtes, des facettes et des filtres.
Prérequis
Remarque
Vous pouvez utiliser un service de recherche gratuit pour ce tutoriel. Le niveau gratuit vous limite à trois index, trois indexeurs et trois sources de données. Ce didacticiel crée une occurrence de chaque élément. Avant de commencer, veillez à disposer de l’espace suffisant sur votre service pour accepter les nouvelles ressources.
Télécharger les fichiers
Téléchargez un fichier zip du référentiel des exemples de données et extrayez le contenu. Découvrez comment.
Charger des exemples de données dans Stockage Azure
Dans Stockage Azure, créez un conteneur et nommez-le cog-search-demo.
Obtenez une chaîne de connexion de stockage pour pouvoir formuler une connexion dans Recherche Azure AI.
À gauche, sélectionnez Clés d’accès.
Copiez la chaîne de connexion pour la clé un ou la clé deux. La chaîne de connexion est similaire à l’exemple suivant :
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI services
L’enrichissement par IA intégré s’appuie sur Azure AI services, notamment le service de langage et Azure AI Vision pour le traitement des images et du langage naturel. Pour les petites charges de travail comme ce tutoriel, vous pouvez utiliser l’allocation gratuite de vingt transactions par indexeur. Pour les charges de travail plus volumineuses, attachez une ressource multirégion Azure AI Services à un ensemble de compétences pour la tarification de paiement à l’utilisation.
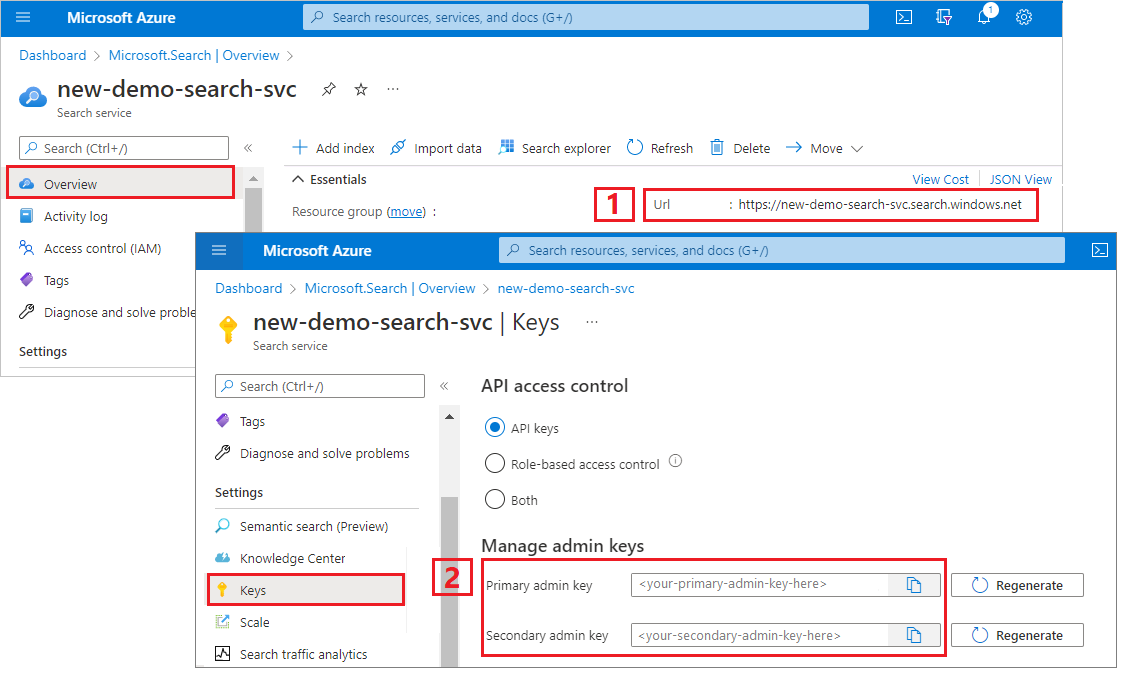
Copier l’URL et la clé API d’un service de recherche
Pour ce tutoriel, les connexions à Recherche Azure AI nécessitent un point de terminaison et une clé API. Vous pouvez obtenir ces valeurs à partir du Portail Azure.
Connectez-vous au Portail Azure, accédez à la page Vue d’ensemble du service de recherche et copiez l’URL. Voici un exemple de point de terminaison :
https://mydemo.search.windows.net.Sous Paramètres>Clés, copiez une clé d’administration. Les clés d’administration sont utilisées pour ajouter, modifier et supprimer des objets. Il existe deux clés d’administration interchangeables. Copiez l’une ou l’autre.
Configurer votre fichier REST
Démarrez Visual Studio Code et ouvrez le fichier skillset-tutorial.rest. Consultez Démarrage rapide : Recherche de texte à l’aide de REST si vous avez besoin d’aide avec le client REST.
Fournissez des valeurs pour les variables : point de terminaison de service de recherche, clé API d’administrateur de service de recherche, nom d’index, chaîne de connexion à votre compte Stockage Azure et nom du conteneur d’objets blob.
Créer le pipeline
L’enrichissement par IA est piloté par l’indexeur. Cette partie de la procédure pas à pas crée quatre objets : source de données, définition d’index, ensemble de compétences, indexeur.
Étape 1 : Création d'une source de données
Appelez la commande Créer une source de données pour définir la chaîne de connexion au conteneur d’objets blob dans lequel se trouvent les exemples de fichiers de données.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Étape 2 : Créer un ensemble de compétences
Appelez la commande Créer un ensemble de compétences pour spécifier les étapes d’enrichissement appliquées à votre contenu. Les compétences s’exécutent en parallèle, sauf en cas de dépendance.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Points essentiels :
Le corps de la demande spécifie les compétences intégrées suivantes :
Compétence Description Reconnaissance optique de caractères Reconnaît le texte et les nombres dans les fichiers image. Fusion de texte Crée du « contenu fusionné » recombinant des éléments de contenu précédemment séparés, ce qui est utile pour des documents contenant des images incorporées (PDF, DOCX, etc.). Les images et le texte sont séparés durant la phase de craquage de document. La compétence de fusion les recombine en insérant le texte reconnu, les légendes des images ou les étiquettes créées pendant l’enrichissement à l’emplacement du document d’où l’image a été extraite. Quand vous utilisez du contenu fusionné dans un ensemble de compétences, ce nœud inclut tout le texte dans le document, y compris celui de documents texte qui ne subissent jamais d’OCR ou d’analyse d’image. Détection de langue Détecte la langue et génère en sortie un nom ou un code de langue. Dans les jeux de données multilingues, un champ de langue peut être utile pour les filtres. Reconnaissance d’entités Extrait les noms des personnes, des organisations et des emplacements à partir du contenu fusionné. Fractionnement de texte Divise le contenu fusionné volumineux en plus petits blocs avant d’appeler la compétence d’extraction de phrases clés. L’extraction de phrases clés accepte des entrées de 50 000 caractères au maximum. Certains fichiers d’exemple doivent être fractionnés pour satisfaire cette limite. Extraction d’expressions clés Extrait les principales expressions clés. Chaque compétence s’exécute sur le contenu du document. Au cours du traitement, Azure AI Search interprète chaque document pour lire le contenu de fichiers de différents formats. Le texte trouvé originaire du fichier source est placé dans un champ
contentgénéré, un pour chaque document. Par conséquent, l’entrée devient"/document/content".Pour l’extraction d’expressions clés, comme nous utilisons la compétence de division de texte pour découper des fichiers volumineux en pages, le contexte de la compétence d’extraction d’expressions clés est
"document/pages/*"(pour chaque page du document) au lieu de"/document/content".
Remarque
Les sorties peuvent être mappées à un index, utilisées comme entrée d’une compétence en aval, ou les deux, comme c’est le cas avec le code de langue. Dans l’index, un code de langue est utile pour le filtrage. Pour plus d’informations sur les principes de base des ensembles de compétences, consultez Guide pratique pour définir un ensemble de compétences.
Étape 3 : Création d'un index
Appelez la commande Créer un index pour fournir le schéma utilisé pour créer des index inversés et d’autres constructions dans Azure AI Search.
Le plus grand composant d’un index est la collection de champs, où le type de données et les attributs déterminent le contenu et le comportement dans Azure AI Search. Assurez-vous que vous disposez de champs pour votre sortie nouvellement générée.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Étape 4 : Créer et exécuter un indexeur
Appelez la commande Créer un indexeur pour piloter le pipeline. Les trois composants que vous avez créés jusqu’à présent (source de données, ensemble de compétences, index) sont les entrées d’un indexeur. La création de l’indexeur sur Azure AI Search est l’événement qui met en mouvement la totalité du pipeline.
Attendez-vous à ce que cette étape prenne plusieurs minutes. Même si le jeu de données est petit, les compétences analytiques exigent des calculs intensifs.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Points essentiels :
Le corps de la demande comprend des références aux objets précédents, les propriétés de configuration requises pour le traitement d’image et deux types de mappages de champs.
Les éléments
"fieldMappings"sont traités avant l’ensemble de compétences, en envoyant le contenu de la source de données aux champs cibles dans un index. Vous utilisez des mappages de champs pour envoyer du contenu existant non modifié à l’index. Si les noms et types de champ sont identiques aux deux extrémités, aucun mappage n’est nécessaire.Les éléments
"outputFieldMappings"sont pour les champs créés par des compétences, après l’exécution de l’ensemble de compétences. Les références àsourceFieldNamedansoutputFieldMappingsn’existent pas tant que l’enrichissement ou le craquage de document ne les a pas créées. L’élémenttargetFieldNameest un champ dans un index, défini dans le schéma d’index.Le paramètre
"maxFailedItems"reçoit la valeur -1, ce qui indique au moteur d’indexation d’ignorer les erreurs au cours de l’importation des données. C’est acceptable car très peu de documents figurent dans la source de données de démonstration. Pour une source de données plus volumineuse, vous définiriez une valeur supérieure à 0.L’instruction
"dataToExtract":"contentAndMetadata"indique à l’indexeur d’extraire automatiquement les valeurs de la propriété de contenu de l’objet blob et les métadonnées de chaque objet.Le paramètre
imageActionindique à l’indexeur d’extraire du texte d’images trouvées dans la source de données. La configuration"imageAction":"generateNormalizedImages", associée à la compétence de reconnaissance optique des caractères et à la compétence de fusion de texte, indique à l’indexeur d’extraire le texte des images (par exemple, le mot « stop » d’un panneau de signalisation Stop) et de l’incorporer dans le champ de contenu. Ce comportement s’applique aux images incorporées (par exemple, une image dans un PDF) ainsi qu’aux fichiers image autonomes (par exemple, un fichier JPG).
Remarque
La création d’un indexeur appelle le pipeline. En cas de problèmes pour atteindre les données, mapper les entrées et les sorties, ou ordonner les opérations, ceux-ci apparaissent à ce stade. Pour réexécuter le pipeline avec des modifications de code ou de script, vous pouvez être amené à supprimer d’abord des objets. Pour plus d’informations, consultez Réinitialiser et réexécuter.
Surveiller l’indexation
L’indexation et l’enrichissement commencent dès que vous envoyez la demande de création d’indexeur. En fonction de la complexité et des opérations de l’ensemble de compétences, l’indexation peut prendre un certain temps.
Pour déterminer si l’indexeur est toujours en cours d’exécution, appelez la commande Obtenir l’état de l’indexeur afin de vérifier l’état de l’indexeur.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Points essentiels :
Les avertissements sont courants dans certains scénarios et n’indiquent pas toujours un problème. Par exemple, si un conteneur d’objets blob comprend des fichiers image et que le pipeline ne gère pas les images, vous obtenez un avertissement indiquant que les images n’ont pas été traitées.
Cet exemple comprend un fichier PNG sans texte. Les cinq compétences textuelles (détection de la langue, extraction de phrases clés et reconnaissance d’entité pour les emplacements, les organisations et les personnes) ne peuvent pas s’exécuter sur ce fichier. La notification résultante apparaît dans l’historique d’exécution.
Vérifier les résultats
Maintenant que vous avez créé un index dans lequel figure du contenu généré par IA, appelez la commande Rechercher dans des documents afin d’exécuter des requêtes pour voir les résultats.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Les filtres peuvent vous aider à limiter les résultats aux éléments qui vous intéressent :
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Ces requêtes illustrent quelques-unes des façons dont vous pouvez travailler avec la syntaxe de requête et les filtres sur les nouveaux champs créés par Azure AI Search. Pour obtenir plus d’exemples de requêtes, consultez Exemples dans l’API REST de recherche de documents, Exemples de requêtes de syntaxe simple et Exemples complets de requêtes Lucene.
Réinitialiser et réexécuter
Durant les premières phases du développement, il est courant d’effectuer des itérations sur la conception. La réinitialisation et la réexécution aident à l’itération.
Éléments importants à retenir
Ce tutoriel montre les étapes de base pour utiliser les API REST pour créer un pipeline d’enrichissement par IA : une source de données, un ensemble de compétences, un index et un indexeur.
Les compétences intégrées ont été introduites, ainsi que la définition d’un ensemble de compétences et les mécanismes de chaînage de compétences via des entrées et des sorties. Vous avez également appris que outputFieldMappings est requis dans la définition de l’indexeur pour acheminer les valeurs enrichies du pipeline dans un index de recherche, sur un service d’Azure AI Search.
Enfin, vous avez appris à tester les résultats et réinitialiser le système pour des itérations ultérieures. Vous avez appris qu’émettre des requêtes par rapport à l’index retourne la sortie créée par le pipeline d’indexation enrichie.
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources une par une, ou choisir de supprimer le groupe de ressources afin de supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer les ressources dans le portail à l’aide des liens Toutes les ressources ou Groupes de ressources situés dans le volet de navigation de gauche.
Étapes suivantes
Maintenant que vous êtes familiarisé avec tous les objets d’un pipeline d’enrichissement par IA, examinez de plus près les définitions des ensembles de compétences et les compétences individuelles.