Ajouter des profils de scoring pour surévaluer les scores de recherche
Les profils de score vous permettent d’améliorer le classement des documents correspondants en fonction de critères. Dans cet article, découvrez comment spécifier et affecter un profil de score qui améliore un score de recherche en fonction des paramètres que vous fournissez.
Vous pouvez utiliser des profils de score pour la recherche par mot clé, la recherche vectorielle et la recherche hybride. Toutefois, les profils de score s’appliquent uniquement aux champs non vectoriels. Vous devez donc vérifier si votre index comporte des champs de texte ou numériques pouvant être utilisés dans un profil de score. La prise en charge des profils de score pour la recherche vectorielle et la recherche hybride est disponible dans les API REST 2024-05-01-preview et 2024-07-01 ainsi que dans les packages du kit Azure SDK qui ciblent ces versions.
Points clés sur les profils de score
Les paramètres des profils de score sont les suivants :
Champs pondérés, où une correspondance est trouvée dans un champ de chaîne spécifique. Par exemple, vous souhaitez peut-être que les correspondances trouvées dans un champ « résumé » soient plus pertinentes que les mêmes correspondances trouvées dans un champ « contenu ».
Fonctions pour les données numériques, notamment les dates, les plages et les coordonnées géographiques. Il existe également une fonction Tags qui opère sur un champ fournissant une collection arbitraire de chaînes. Vous pouvez choisir cette approche à la place de celle des champs pondérés si vous souhaitez améliorer un score selon qu’une correspondance est trouvée ou non dans un champ de balises.
Vous pouvez créer plusieurs profils, puis modifier la logique de requête pour choisir le profil à utiliser.
Vous pouvez avoir jusqu’à 100 profils de score dans un index (consultez Limites de service), mais vous ne pouvez spécifier qu’un seul profil à la fois dans une requête donnée.
Remarque
Les concepts de pertinence ne vous sont pas familiers ? Pour plus d’informations, consultez Pertinence et scoring dans Recherche Azure AI. Vous pouvez également regarder cet extrait vidéo sur YouTube pour en savoir plus sur la relation entre les profils de score et les résultats classés par l’algorithme BM25.
Définition d’un profil de scoring
Un profil de score est un objet nommé défini dans un schéma d’index. Un profil de score est composé de champs, de fonctions et de paramètres pondérés.
La définition suivante montre un profil simple nommé « géo ». Cet exemple surévalue les résultats dont le champ hotelName contient le terme recherché. Il utilise également la fonction distance pour favoriser les résultats qui se trouvent dans un rayon de 10 kilomètres de l’emplacement actuel. Si quelqu'un effectue une recherche sur le terme « inn » dans un rayon de 10 km par rapport à la position actuelle, les documents d'hôtels dont le nom contient cette chaîne de caractères apparaissent en tête des résultats de la recherche.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Pour utiliser ce profil de scoring, votre requête est formulée de façon à spécifier le paramètre scoringProfile dans la requête. Si vous utilisez l’API REST, les requêtes sont spécifiées via des requêtes GET et POST. Dans l’exemple suivant, « currentLocation » a un délimiteur d’un tiret unique (-). Il est suivi des coordonnées longitude et latitude, où la longitude est une valeur négative.
GET /indexes/hotels/docs?search+inn&scoringProfile=geo&scoringParameter=currentLocation--122.123,44.77233&api-version=2024-07-01
Notez les différences de syntaxe lors de l’utilisation de POST. Dans POST, « scoringParameters » est au pluriel et il s’agit d’un tableau.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
Cette requête recherche le terme « inn » et transmet l’emplacement actuel. Notez que cette requête inclut d’autres paramètres, tels que scoringParameter. Les paramètres de requête, notamment « scoringParameter », sont décrits dans Recherche dans des documents (API REST).
Pour accéder à des scénarios supplémentaires, consultez Exemple étendu pour la recherche vectorielle et la recherche hybride et Exemple étendu pour la recherche par mot clé.
Fonctionnement du scoring de recherche dans Recherche Azure AI
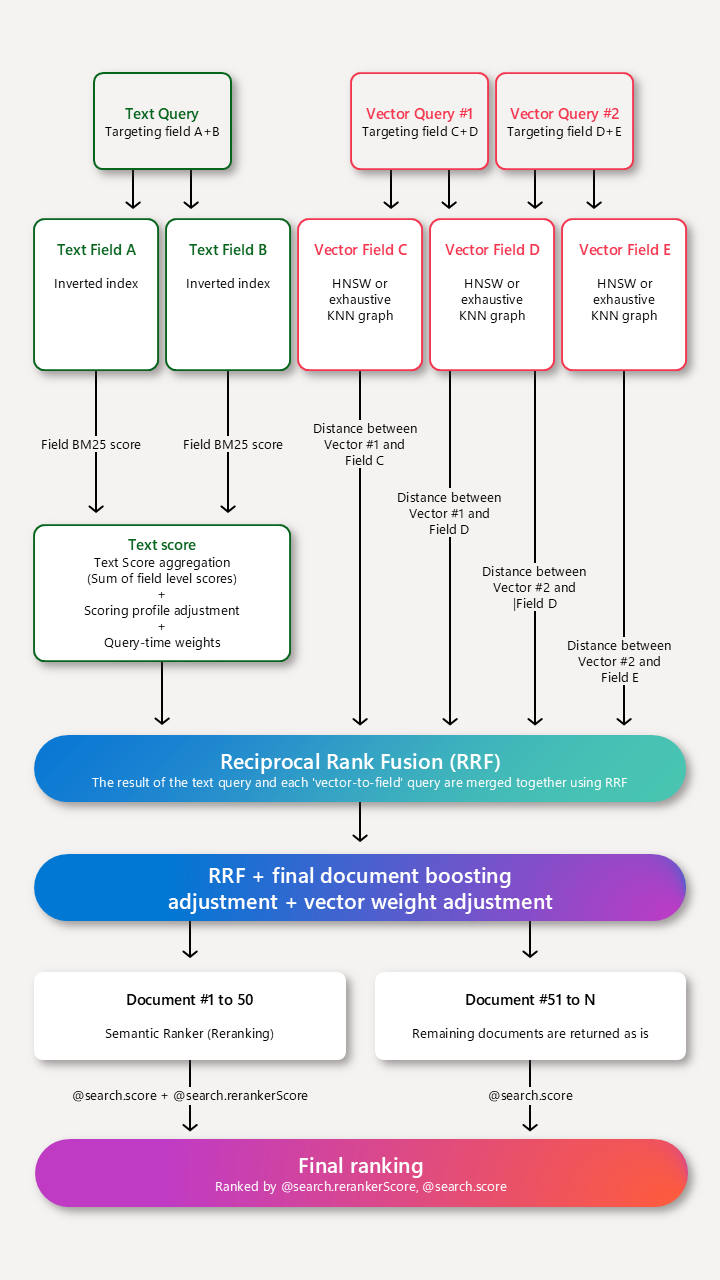
Les profils de score complètent l’algorithme de scoring par défaut en améliorant les scores des correspondances qui répondent aux critères du profil. Les fonctions de scoring s’appliquent à la recherche par mot clé, aux requêtes vectorielles pures et aux requêtes hybrides.
Quand vous utilisez des profils de score ou toute autre fonctionnalité d’amélioration dans Recherche Azure AI, l’algorithme RRF (fonction de classement réciproque) attribue le score, notamment pour les requêtes textuelles et vectorielles autonomes. Une fois l’algorithme RRF appliqué, tous les ajustements de scoring/d’amélioration, de classement sémantique et de pondération vectorielle sont effectués.
Conseil
Vous pouvez utiliser le paramètre featuresMode (préversion) pour demander des détails de scoring supplémentaires (dont les scores au niveau des champs) avec les résultats de la recherche.
Ajouter un profil de score à un index de recherche
Commencez par une définition d’index. Vous pouvez ajouter et mettre à jour des profils de scoring sur un index existant sans avoir à le régénérer. Utilisez une requête de création ou mise à jour d’index pour publier une révision.
Collez le modèle fourni dans cet article.
Fournissez un nom qui respecte les conventions d’affectation de noms.
Spécifiez les critères de surévaluation. Un même profil peut contenir des champs de texte pondérés, des fonctions, ou les deux.
Vous devez travailler de manière itérative, en utilisant un jeu de données qui vous aidera à prouver ou à réfuter l’efficacité d’un profil donné.
Les profils de scoring peuvent être définis dans le portail Azure, comme le montre la capture d’écran suivante, ou par programmation via les API REST ou les Kits de développement logiciel (SDK) Azure, comme la classe ScoringProfile du SDK Azure pour .NET.

Utiliser des champs de texte pondérés
Utilisez des champs de texte pondérés quand le contexte du champ est important, et que les requêtes incluent des champs de chaîne searchable. Par exemple, si une requête comprend le terme « aéroport », vous souhaiterez peut-être que « aéroport » ait plus de poids dans le champ Description que dans le champ HotelName.
Les champs pondérés sont des paires nom-valeur composées d’un champ searchable et d’un nombre positif utilisé en tant que multiplicateur. Si le score original du champ HotelName est de 3, le score surévalué pour ce champ est de 6, ce qui contribue à un score global plus élevé pour le document parent lui-même.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Utiliser les fonctions
Utilisez des fonctions lorsque les pondérations relatives simples sont insuffisantes ou ne s’appliquent pas, comme dans le cas de « distance » et de « freshness », qui sont des calculs sur des données numériques. Vous pouvez spécifier plusieurs fonctions par profil de scoring. Pour plus d’informations sur les types de données EDM utilisés dans Recherche Azure AI, consultez Types de données pris en charge.
| Fonction | Description | Cas d’utilisation |
|---|---|---|
| distance | Permet d’apporter une amélioration en fonction de la proximité ou de l’emplacement géographique. Cette fonction peut être utilisée uniquement avec des champs Edm.GeographyPoint . |
À utiliser pour les scénarios « rechercher à proximité ». |
| freshness | Permet d’apporter une amélioration en fonction des valeurs d’un champ DateHeure (Edm.DateTimeOffset). Définissez boostingDuration pour spécifier une valeur représentant une période durant laquelle l’amélioration a lieu. |
À utiliser pour apporter une amélioration en fonction de dates plus récentes ou plus anciennes. Classez les éléments tels que les événements de calendrier ayant des dates futures de telle sorte que les éléments plus proches du moment présent puissent avoir un meilleur classement que les éléments plus éloignés dans le futur. Une extrémité de la plage est fixée à l’heure actuelle. Pour améliorer une plage de périodes dans le passé, utilisez une valeur boostingDuration positive. Pour surévaluer une plage d’heures à venir, utilisez un attribut boostingDuration négatif. |
| magnitude | Permet de modifier les classements en fonction de la plage de valeurs d’un champ numérique. La valeur doit être un entier ou un nombre à virgule flottante. Pour des évaluations de 1 à 4, il s'agit de 1. Pour des marges de plus de 50 %, il s'agit de 50. Cette fonction peut être utilisée uniquement avec les champs Edm.Double et Edm.Int. Pour la fonction magnitude, vous pouvez inverser la plage (de la valeur la plus élevée à la valeur la plus basse) si vous souhaitez obtenir le modèle inverse (par exemple, pour surévaluer les articles les moins chers davantage que les articles les plus chers). Dans une gamme de prix allant de $100USD à $1USD, vous devez définir boostingRangeStart sur 100 et boostingRangeEnd sur 1 pour privilégier les éléments dont le prix est plus bas. |
À utiliser pour apporter une amélioration en fonction de la marge bénéficiaire, des évaluations, du nombre de clics, du nombre de téléchargements, du prix le plus élevé, du prix le plus bas ou du nombre de téléchargements. Lorsque deux éléments sont pertinents, l’élément associé à l’évaluation la plus élevée s’affiche en premier. |
| tag | Permet d’apporter une amélioration en fonction des balises communes aux documents de recherche et aux chaînes de requête. Les balises sont fournies dans un tagsParameter. Cette fonction peut être utilisée uniquement avec des champs de type Edm.String et Collection(Edm.String). |
À utiliser quand vous avez des champs de balises. Si une balise donnée dans la liste est elle-même une liste délimitée par des virgules, vous pouvez utiliser un normaliseur de texte sur le champ pour supprimer les virgules au moment de la requête (mapper le caractère virgule avec un espace). Cette approche va « aplatir » la liste afin que tous les termes soient une chaîne unique et longue de termes délimités par des virgules. |
Règles d'utilisation des fonctions
- Les fonctions peuvent uniquement être appliquées aux champs ayant l’attribut
filterable. - Le type de fonction (« freshness », « magnitude », « distance », « tag ») doit être en lettres minuscules.
- Les fonctions ne peuvent pas contenir de valeurs null ou vides.
- Les fonctions ne peuvent avoir qu’un seul champ par définition de fonction. Pour utiliser la magnitude deux fois dans le même profil, fournissez deux définitions de la magnitude, une pour chaque champ.
Modèle
Cette section présente la syntaxe et le modèle de profils de calcul de score. Pour obtenir une description des propriétés, consultez les informations de référence sur l’API REST.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Définition d'interpolations
Les interpolations définissent la forme de la pente utilisée pour le scoring. Le score allant d'élevé à faible, la pente est toujours décroissante, mais l’interpolation détermine la courbe de la pente descendante. Les interpolations utilisables sont les suivantes :
| Interpolation | Description |
|---|---|
linear |
Pour les éléments compris dans la plage des valeurs maximale et minimale, l’amélioration est appliquée de manière décroissante et constante. L'interpolation de type Linear est l'interpolation par défaut pour un profil de calcul de score. |
constant |
Pour les éléments compris dans la plage des valeurs de début et de fin, une amélioration constante est appliquée aux résultats du classement. |
quadratic |
Par rapport à une interpolation linéaire dont l’amélioration décroît de manière constante, une interpolation quadratique décroît initialement plus lentement, puis à mesure qu’elle s’approche de la fin de la plage, elle décroît à un intervalle beaucoup plus élevé. Cette option d’interpolation n’est pas autorisée dans les fonctions de scoring d’étiquettes. |
logarithmic |
Par rapport à une interpolation linéaire dont l’amélioration décroît de manière constante, une interpolation logarithmique décroît initialement plus rapidement, puis à mesure qu’elle s’approche de la fin de la plage, elle décroît à un intervalle beaucoup plus réduit. Cette option d’interpolation n’est pas autorisée dans les fonctions de scoring d’étiquettes. |

Définir boostingDuration pour la fonction freshness
boostingDuration est un attribut de la fonction freshness. Il permet de définir une période d'expiration après laquelle la valorisation s'arrête pour un document spécifique. Par exemple, pour valoriser une ligne de produits ou une marque pendant une période promotionnelle de 10 jours, vous spécifiez la période de 10 jours en tant que « P10D » pour les documents correspondants.
boostingDuration doit être au format « dayTimeDuration » XSD (sous-ensemble limité d'une valeur de durée ISO 8601). Le modèle appliqué est : « P[nD][T[nH][nM][nS]] ».
Le tableau suivant fournit plusieurs exemples.
| Durée | boostingDuration |
|---|---|
| 1 jour | « P1D » |
| 2 jours et 12 heures | « P2DT12H » |
| 15 minutes | « PT15M » |
| 30 jours, 5 heures 10 minutes, et 6 334 secondes | « P30DT5H10M6.334S » |
Pour plus d'exemples, consultez Schéma XML : types de données (site Web W3.org).
Exemple étendu pour la recherche vectorielle et la recherche hybride
Consultez ce billet de blog et ce notebook pour accéder à une démonstration de l’utilisation des profils de score et de l’amélioration des documents dans le cadre des scénarios basés sur les vecteurs et l’IA générative.
Exemple étendu pour la recherche par mot clé
L’exemple suivant montre le schéma d’un index comprenant deux profils de scoring (boostGenre, newAndHighlyRated). Toute requête sur cet index qui comprend un profil comme paramètre de requête utilise le profil pour évaluer le jeu de résultats.
Le profil boostGenre utilise des champs de texte pondérés, surévaluant les correspondances trouvées dans les champs albumTitle, genre, et artistName. Ces champs sont respectivement multipliés par 1,5, 5 et 2. Pourquoi la pondération du champ genre est-elle beaucoup plus élevée que celle des autres champs ? Si la recherche est effectuée sur des données relativement homogènes (comme c’est le cas de « genre » dans musicstoreindex), il se peut que vous ayez besoin d’une variance plus importante dans les pondérations relatives. Par exemple, dans musicstoreindex, « rock » apparaît à la fois comme genre et dans des descriptions de genre formulées de façon identique. Si vous souhaitez que le genre ait une pondération plus élevée que la description du genre, la pondération relative du champ Genre doit être sensiblement plus importante.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}