Didacticiel : Optimiser l’indexation à l’aide de l’API Push
Recherche Azure AI prend en charge deux approches de base pour importer des données dans un index de recherche : envoyer (push) vos données dans l’index de manière programmatique ou extraire (pull) les données en pointant un indexeur Recherche Azure AI vers une source de données prise en charge.
Ce tutoriel explique comment indexer efficacement des données à l'aide du modèle d'envoi (push) en utilisant le traitement par lot des demandes et en utilisant une stratégie de nouvelle tentative de backoff exponentiel. Vous pouvez Télécharger et exécuter l’exemple d’application. Cet article explique les aspects clés de l'application et les facteurs à prendre en compte lors de l'indexation des données.
Ce tutoriel utilise C# et la bibliothèque Azure.Search.Documents à partir du Kit de développement logiciel (SDK) Azure pour .NET en vue d'effectuer les tâches suivantes :
- Création d'un index
- Tester différentes tailles de lot pour déterminer la taille la plus efficace
- Indexer les lots de façon asynchrone
- Utiliser plusieurs threads pour augmenter les vitesses d’indexation
- Utiliser une stratégie de nouvelle tentative de backoff exponentiel pour réessayer des documents ayant échoué
Prérequis
Les services et outils suivants sont indispensables dans ce tutoriel.
Un abonnement Azure. Si vous n’en avez pas, vous pouvez créer un compte gratuit.
Visual Studio, toute édition. L’exemple de code et les instructions ont été testés dans l’édition Communauté gratuite.
Télécharger les fichiers
Le code source pour ce didacticiel se trouve dans le dossier optimize-data-indexing/v11 du référentiel GitHub Azure-Samples/azure-search-dotnet-scale.
Considérations importantes
Les facteurs qui affectent les vitesses d’indexation sont répertoriés ci-après. Pour plus d’informations, consultez Indexer des jeux de données volumineux.
- Niveau de service et nombre de partitions/réplicas : l’ajout de partitions ou la mise à niveau de votre niveau de service augmente les vitesses d’indexation.
- Complexité du schéma d’index : l’ajout de champs et de propriétés de champ réduit les vitesses d’indexation. Les index plus petits sont plus rapides à indexer.
- Taille de lot : la taille de lot optimale varie en fonction du schéma et du jeu de données de votre index.
- Nombre de threads/workers : un seul thread ne tire pas pleinement parti des vitesses d’indexation.
- Stratégie de nouvelle tentative : une stratégie de nouvelle tentative de backoff exponentiel est une meilleure pratique pour optimiser l’indexation.
- Vitesse de transfert des données du réseau : la vitesse de transfert des données peut être un facteur limitatif. Indexez les données à partir de votre environnement Azure pour augmenter la vitesse de transfert des données.
Étape 1 : Créer un service Recherche Azure AI
Pour suivre ce didacticiel, vous avez besoin d’un service Recherche Azure AI, que vous pouvez créer dans le portail Azure. Vous pouvez également rechercher un service existant sous votre abonnement actuel. Nous vous recommandons d’utiliser le même niveau que celui que vous prévoyez d’utiliser en production pour pouvoir tester et optimiser avec précision les vitesses d’indexation.
Obtenir une clé d’administration et une URL pour Recherche Azure AI
Ce tutoriel utilise l'authentification basée sur des clés. Copiez une clé API d'administrateur pour coller dans le fichier appsettings.json.
Connectez-vous au portail Azure. Obtenez l’URL du point de terminaison à partir de la page Vue d’ensemble de votre service de recherche. Voici un exemple de point de terminaison :
https://mydemo.search.windows.net.Dans Paramètres>Clés, obtenez une clé d’administration pour avoir des droits d’accès complets sur le service. Il existe deux clés d’administration interchangeables, fournies pour assurer la continuité de l’activité au cas où vous deviez en remplacer une. Vous pouvez utiliser la clé primaire ou secondaire sur les demandes d’ajout, de modification et de suppression d’objets.
Étape 2 : Configurer votre environnement
Démarrez Visual Studio et ouvrez OptimizeDataIndexing.sln.
Dans l’Explorateur de solutions, ouvrez appsettings.json pour fournir les informations de connexion de votre service.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Étape 3 : Explorer le code
Une fois que vous avez mis à jour appSettings.json, l’exemple de programme dans OptimizeDataIndexing.sln doit être prêt pour la génération et l’exécution.
Ce code est dérivé de la section C# de Démarrage rapide : Recherche en texte intégral à l’aide des Kits de développement logiciel (SDK) Azure. Vous trouverez des informations plus détaillées sur les principes de base de l’utilisation du kit de développement logiciel (SDK) .NET dans cet article.
Cette application console C#/.NET simple effectue les tâches suivantes :
- Crée un index basé sur la structure de données de la classe
HotelC# (qui référence également la classeAddress). - Teste différentes tailles de lot pour déterminer la taille la plus efficace
- Indexe les données de façon asynchrone
- Utilisation de plusieurs threads pour augmenter les vitesses d’indexation
- Utilisation d’une stratégie de nouvelle tentative d’interruption exponentielle pour réessayer les éléments ayant échoué
Avant d’exécuter le programme, prenez une minute pour étudier le code et les définitions d’index de cet exemple. Le code qui convient se trouve dans plusieurs fichiers :
- Hotel.cs et Address.cs contiennent le schéma qui définit l’index
- DataGenerator.cs contient une classe simple pour faciliter la création de grandes quantités de données d’hôtel
- ExponentialBackoff.cs contient du code pour optimiser le processus d'indexation, comme décrit dans cet article
- Program.cs contient des fonctions qui créent et suppriment l’index de Recherche Azure AI, indexent des lots de données et testent différentes tailles de lot
Création de l'index
Cet exemple de programme utilise le Kit de développement logiciel (SDK) Azure pour .NET pour définir et créer un index Recherche Azure AI. Il tire parti de la classe FieldBuilder pour générer une structure d’index à partir d’une classe de modèle de données C#.
Le modèle de données est défini par la classe Hotel, qui contient également des références à la classe Address. La classe FieldBuilder explore plusieurs définitions de classe pour générer une structure de données complexes pour l’index. Des étiquettes de métadonnées sont utilisées pour définir les attributs de chaque champ, par exemple s’il peut faire l’objet d’une recherche ou d’un tri.
Les extraits de code suivants tirés du fichier Hotel.cs montrent comment spécifier un champ unique et une référence à une autre classe de modèle de données.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
Dans le fichier Program.cs, l’index est défini avec un nom et une collection de champs générés par la méthode FieldBuilder.Build(typeof(Hotel)), puis créé comme suit :
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Générer des données
Une classe simple est implémentée dans le fichier DataGenerator.cs pour générer des données à des fins de test. Le seul but de cette classe est de faciliter la génération d’un grand nombre de documents avec un ID unique pour l’indexation.
Pour obtenir une liste de 100 000 hôtels avec des ID uniques, exécutez les lignes de code suivantes :
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Deux tailles d’hôtels sont disponibles pour le test dans cet exemple : small et large.
le schéma de votre index a un effet sur les vitesses d'indexation. Pour cette raison, il est judicieux de convertir cette classe pour générer des données qui correspondent le mieux au schéma de votre index après avoir suivi ce tutoriel.
Étape 4 : Tester les tailles de lot
La Recherche Azure AI prend en charge les API suivantes pour charger un ou plusieurs documents dans un index :
L’indexation de documents par lots améliore considérablement les performances d’indexation. Ces lots peuvent comporter jusqu’à 1 000 documents, ou jusqu’à 16 Mo par lot.
La détermination de la taille de lot optimale pour vos données est un composant clé de l’optimisation des vitesses d’indexation. Les deux principaux facteurs qui influencent la taille de lot optimale sont les suivants :
- Le schéma de votre index
- La taille de vos données
Étant donné que la taille de lot optimale dépend de votre index et de vos données, la meilleure approche consiste à tester différentes tailles de lot pour déterminer ce qui produit les vitesses d’indexation les plus rapides pour votre scénario.
La fonction suivante illustre une approche simple pour tester les tailles de lot.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Étant donné que tous les documents ne sont pas de la même taille (même si c’est le cas dans cet exemple), nous estimons la taille des données que nous envoyons au service de recherche. Pour ce faire, utilisez la fonction suivante qui convertit d’abord l’objet en JSON, puis détermine sa taille en octets. Cette technique nous permet de déterminer les tailles de lot les plus efficaces en termes de vitesses d’indexation en Mo/s.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
La fonction requiert un SearchClient, plus le nombre de tentatives que vous souhaitez tester pour chaque taille de lot. Dans la mesure où les temps d’indexation peuvent varier d’un lot à l’autre, testez chaque lot trois fois par défaut pour que les résultats soient plus significatifs d’un point de vue statistique.
await TestBatchSizesAsync(searchClient, numTries: 3);
Lorsque vous exécutez la fonction, vous devez voir une sortie dans votre console semblable à l’exemple suivant :
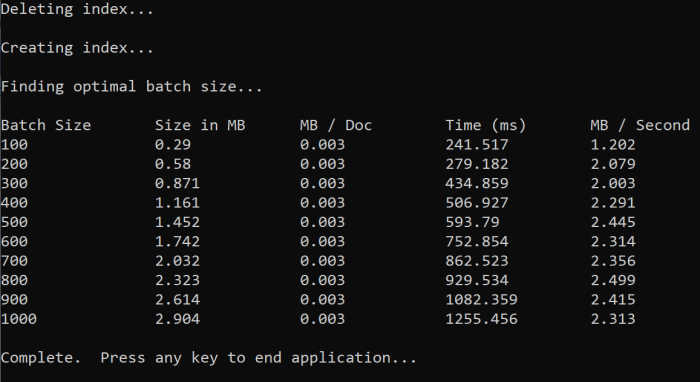
Identifiez la taille de lot la plus efficace, puis utilisez cette taille de lot à l’étape suivante du didacticiel. Vous pouvez voir un plateau de Mo/s sur différentes tailles de lot.
Étape 5 : Indexer les données
Maintenant que vous avez identifié la taille de lot que vous envisagez d’utiliser, l’étape suivante consiste à commencer à indexer les données. Pour indexer les données efficacement, cet exemple :
- utilise plusieurs threads/workers
- Implémente une stratégie de nouvelle tentative de backoff exponentiel
Supprimez les marques de commentaire des lignes 41 à 49, puis réexécutez et le programme. Lors de cette exécution, l'exemple génère et envoie des lots de documents, jusqu'à 100 000 si vous exécutez le code sans modifier les paramètres.
Utiliser plusieurs threads/workers
Pour tirer pleinement parti des vitesses d'indexation de la Recherche Azure AI, utilisez plusieurs threads pour envoyer simultanément des demandes d'indexation par lots au service.
Plusieurs des considérations clés mentionnées précédemment peuvent affecter le nombre optimal de threads. Vous pouvez modifier cet exemple et effectuer des tests avec différents nombres de threads pour déterminer le nombre de threads optimal pour votre scénario. Toutefois, tant que plusieurs threads s’exécutent simultanément, vous devriez être en mesure de bénéficier de la majeure partie des gains d’efficacité.
Au fur et à mesure que les requêtes atteignent le service de recherche, vous risquez de rencontrer des codes d’état HTTP indiquant que la requête n’a pas abouti. Pendant l’indexation, deux codes d’état HTTP courants sont :
- 503 Service indisponible : cette erreur signifie que le système est surchargé et que votre requête ne peut pas être traitée pour le moment.
- 207 Multi-état : Cette erreur signifie que certains documents ont réussi, mais qu’au moins un a échoué.
Implémenter une stratégie de nouvelle tentative d’interruption exponentielle
En cas d’échec, les requêtes doivent être retentées à l’aide d’une stratégie de nouvelle tentative d’interruption exponentielle.
Le kit de développement logiciel (SDK) .NET de la Recherche Azure AI relance automatiquement les requêtes qui génèrent les erreurs 503 et autres requêtes ayant échoué. Cependant, vous devez implémenter votre propre logique pour réessayer en cas de code 207. Les outils open source comme Polly peuvent être utiles dans une stratégie de nouvelle tentative.
Dans cet exemple, nous implémentons notre propre stratégie de nouvelle tentative d’interruption exponentielle. Nous commençons par définir certaines variables, dont maxRetryAttempts et la valeur delay initiale pour une requête ayant échoué :
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Les résultats de l’opération d’indexation sont stockés dans la variable IndexDocumentResult result. Cette variable est importante, car elle vous permet de vérifier si des documents du lot ont échoué, comme illustré dans l’exemple suivant. En cas de défaillance partielle, un nouveau lot est créé en fonction de l'ID des documents ayant échoué.
Les exceptions RequestFailedException doivent également être interceptées, car elles indiquent que la demande a complètement échoué et doit également retentée.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
À partir de là, encapsulez le code de backoff exponentiel dans une fonction afin qu’il puisse être facilement appelé.
Une autre fonction est ensuite créée pour gérer les threads actifs. Par souci de simplicité, cette fonction n’est pas incluse ici, mais se trouve dans ExponentialBackoff.cs. La fonction peut être appelée à l’aide de la commande suivante, où hotels correspond aux données que nous voulons télécharger, 1000 à la taille du lot et 8 au nombre de threads simultanés :
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Lorsque vous exécutez la fonction, vous devez voir une sortie :
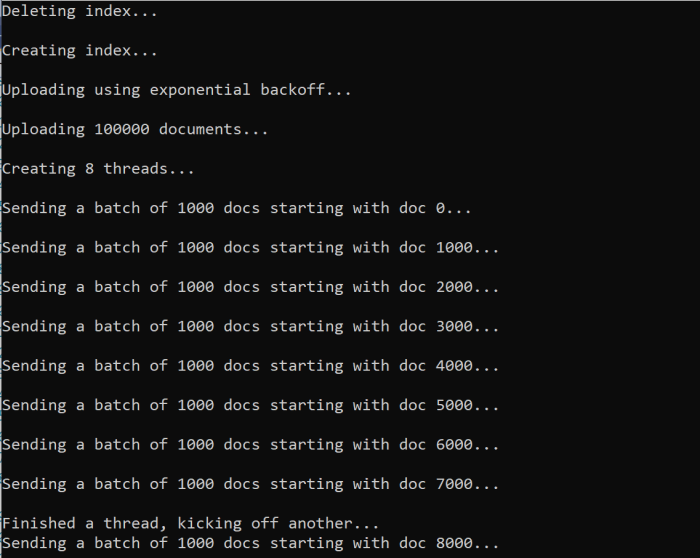
En cas d’échec d’un lot de documents, une erreur s’affiche pour indiquer qu’un échec s’est produit et que le lot est retenté :
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Une fois l’exécution de la fonction terminée, vous pouvez vérifier que tous les documents ont été ajoutés à l’index.
Étape 6 : Explorer l’index
Vous pouvez explorer l’index de recherche rempli après l’exécution du programme de manière programmatique ou à l’aide de l’Explorateur de recherche dans le portail.
Par programme
Il existe deux options principales pour vérifier le nombre de documents dans un index : l’API Nombre de documents et l’API Obtention de statistiques d'index. Les deux chemins d'accès nécessitent du temps de traitement. Ne soyez donc pas alarmés si le nombre de documents retournés est initialement inférieur à celui prévu.
Nombre de documents
L'opération Count Documents récupère le nombre de documents dans un index de recherche :
long indexDocCount = await searchClient.GetDocumentCountAsync();
Obtention de statistiques d'index
L'opération Get Index Statistics retourne un nombre de documents pour l'index actuel, ainsi que l'utilisation du stockage. La mise à jour des statistiques d’index prend plus de temps que celle du nombre de documents.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Portail Azure
Dans le portail Azure, ouvrez le volet de navigation gauche, recherchez l’index optimize-indexing dans la liste Index.

Le Nombre de documents et la Taille de stockage sont basés sur l'API Obtention de statistiques d'index et peuvent nécessiter plusieurs minutes pour se mettre à jour.
Réinitialiser et réexécuter
Dans les premières étapes expérimentales de développement, l’approche la plus pratique pour les itérations de conception consiste à supprimer les objets d’Azure AI Search et à autoriser votre code à les reconstruire. Les noms des ressources sont uniques. La suppression d’un objet vous permet de le recréer en utilisant le même nom.
L’exemple de code pour ce tutoriel recherche les index existants et les supprime pour vous permettre de réexécuter votre code.
Vous pouvez également utiliser le portail pour supprimer des index.
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources une par une, ou choisir de supprimer le groupe de ressources afin de supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer les ressources dans le portail à l’aide des liens Toutes les ressources ou Groupes de ressources situés dans le volet de navigation de gauche.
Étape suivante
Pour en savoir plus sur l'indexation de grandes quantités de données, essayez le tutoriel suivant.