Tutoriel : Implémenter le modèle de capture de lac de données pour mettre à jour une table Delta Databricks
Ce tutoriel vous montre comment gérer des événements dans un compte de stockage doté d’un espace de noms hiérarchique.
Vous allez créer une petite solution qui permet à un utilisateur de remplir une table Databricks Delta en chargeant un fichier de valeurs séparées par des virgules (CSV) qui décrit une commande client. Vous allez créer cette solution en associant un abonnement Event Grid, une fonction Azure et un travail dans Azure Databricks.
Ce didacticiel présente les procédures suivantes :
- Créer un abonnement Event Grid qui appelle une fonction Azure
- Créer une fonction Azure qui reçoit une notification d’un événement, puis exécute le travail dans Azure Databricks
- Créer un travail Databricks qui insère une commande client dans une table Databricks Delta hébergée dans le compte de stockage
Pour créer cette solution, nous allons procéder dans l’ordre inverse et commencer par l’espace de travail Azure Databricks.
Prérequis
Créez un compte de stockage qui possède un espace de noms hiérarchique (Azure Data Lake Storage Gen2). Ce tutoriel utilise un compte de stockage nommé
contosoorders.Consultez Créer un compte de stockage à utiliser avec Azure Data Lake Storage Gen2.
Vérifiez que le rôle Contributeur aux données Blob du stockage est attribué à votre compte d’utilisateur.
Créez un principal de service et une clé secrète client, puis accordez au principal de service l’accès au compte de stockage.
Consultez Tutoriel : Se connecter à Azure Data Lake Storage Gen2 (étapes 1 à 3). Après avoir effectué ces étapes, veillez à coller les valeurs d’ID de locataire, d’ID d’application et de clé secrète client dans un fichier texte. Vous en aurez besoin bientôt.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Créer une commande client
Tout d’abord, créez un fichier CSV qui décrit une commande client, puis chargez ce fichier dans le compte de stockage. Vous utiliserez les données de ce fichier ultérieurement pour remplir la première ligne de la table Databricks Delta.
Accédez à votre nouveau compte de stockage dans le portail Azure.
Sélectionnez Navigateur de stockage->Conteneurs d’objets blob->Ajouter un conteneur et créez un conteneur nommé data.
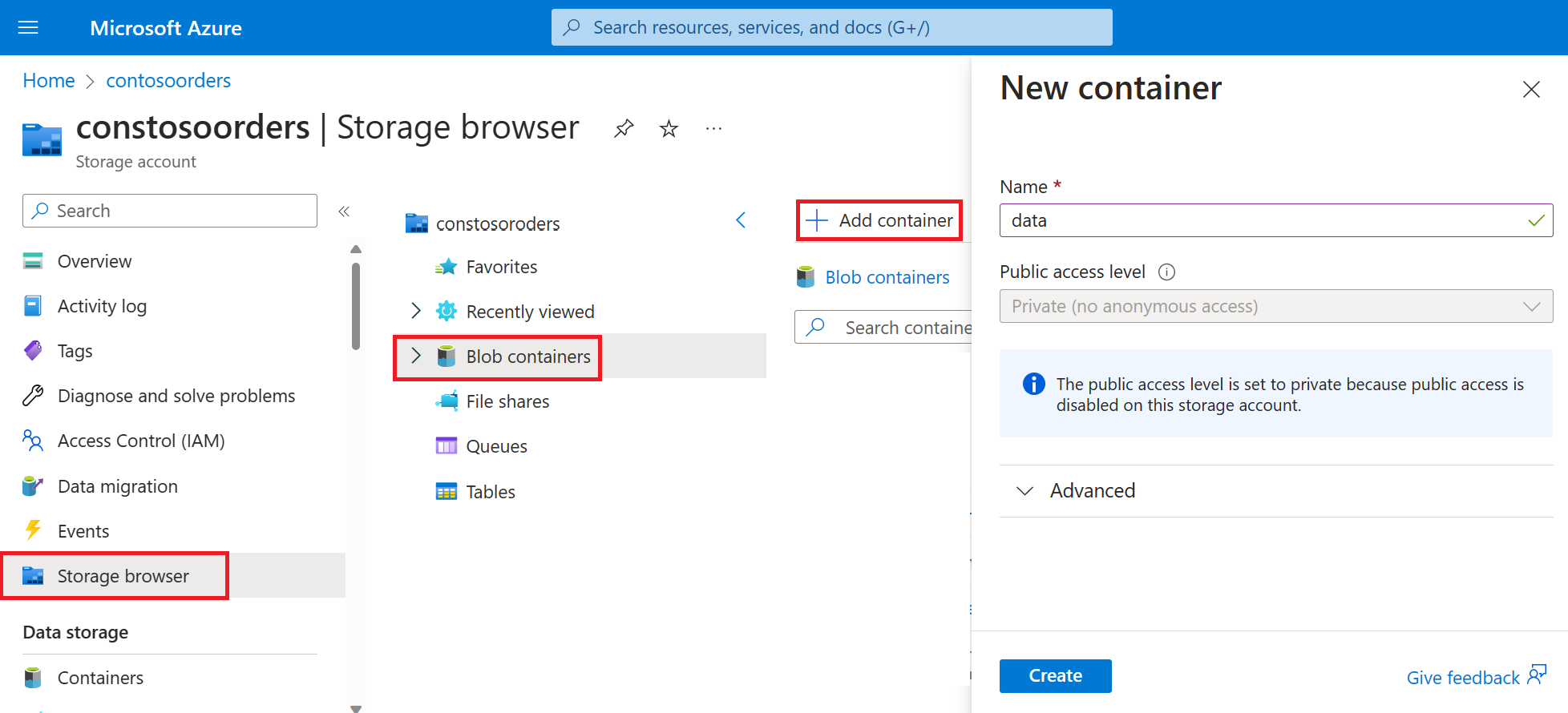
Dans le conteneur data, créez un répertoire nommé input.
Dans un éditeur de texte, collez le texte suivant.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomEnregistrez ce fichier sur votre ordinateur local et nommez-le data.csv.
Dans le navigateur de stockage, chargez ce fichier dans le dossier input.
Créer un travail dans Azure Databricks
Dans cette section, vous allez effectuer les tâches suivantes :
- Créer un espace de travail Azure Databricks.
- Créez un bloc-notes.
- Créer et remplir une table Databricks Delta
- Ajouter du code qui insère des lignes dans la table Databricks Delta
- Créer un travail
Créer un espace de travail Azure Databricks
Dans cette section, vous créez un espace de travail Azure Databricks en utilisant le portail Azure.
Créer un espace de travail Azure Databricks. Nommez cet espace de travail
contoso-orders. Consultez Créer un espace de travail Azure Databricks.Créer un cluster. Nommez le cluster
customer-order-cluster. Voir Créez un cluster.Créez un bloc-notes. Nommez le notebook
configure-customer-tableet choisissez Python comme langage par défaut du notebook. Consultez Création d’un notebook.
Créer et remplir une table Databricks Delta
Dans le notebook que vous avez créé, copiez et collez le bloc de code suivant dans la première cellule, mais n’exécutez pas ce code pour l’instant.
Dans ce bloc de code, remplacez les valeurs d’espace réservé
appId,passwordettenantpar celles que vous avez collectées au moment de la finalisation des prérequis de ce tutoriel.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Ce code crée un widget nommé source_file. Vous créerez plus tard une fonction Azure qui appelle ce code et transmet un chemin de fichier à ce widget. Ce code authentifie également votre principal de service auprès du compte de stockage et crée des variables que vous allez utiliser dans d’autres cellules.
Notes
Dans un environnement de production, songez à stocker votre clé d’authentification dans Azure Databricks. Ensuite, ajoutez une clé de recherche à votre bloc de code au lieu de la clé d’authentification.
Par exemple, au lieu d’utiliser la ligne de codespark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"), vous pouvez utiliser la ligne de code suivante :spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Après avoir effectué ce tutoriel, consultez l’article Azure Data Lake Storage Gen2 sur le site web Azure Databricks pour voir des exemples de cette approche.Appuyez sur les touches Maj +Entrée pour exécuter le code de ce bloc.
Copiez le bloc de code suivant et collez-le dans une autre cellule, puis appuyez sur les touches Maj + Entrée pour l’exécuter.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Ce code crée la table Databricks Delta dans votre compte de stockage, puis charge des données initiales à partir du fichier CSV que vous avez chargé précédemment.
Une fois ce bloc de code correctement exécuté, supprimez-le de votre notebook.
Ajouter du code qui insère des lignes dans la table Databricks Delta
Copiez le bloc de code suivant et collez-le dans une autre cellule, mais n’exécutez pas cette cellule pour l’instant.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Ce code insère des données dans une vue de table temporaire à partir d’un fichier CSV. Le chemin vers ce fichier CSV est fourni par le widget d’entrée que vous avez créé lors d’une étape antérieure.
Copiez et collez le bloc de code suivant dans une autre cellule. Ce code fusionne le contenu de la vue de la table temporaire avec la table Databricks Delta.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Création d’un travail
Créez un travail qui exécute le notebook que vous avez créé précédemment. Vous créerez plus tard une fonction Azure qui exécute ce travail quand un événement est déclenché.
Sélectionnez Nouveau->Travail.
Donnez un nom au travail, choisissez le notebook que vous avez créé et le cluster. Sélectionnez ensuite Créer pour créer le travail.
Création d’une fonction Azure
Créez une fonction Azure qui exécute le travail.
Dans votre espace de travail Azure Databricks, cliquez sur votre nom d’utilisateur Azure Databricks dans la barre supérieure, puis dans la liste déroulante, sélectionnez Paramètres utilisateur.
Sous l’onglet Jetons d’accès, sélectionnez Générer un nouveau jeton.
Copiez le jeton qui apparaît et cliquez sur Terminé.
Dans le coin supérieur de l’espace de travail Databricks, cliquez sur l’icône représentant un personnage, puis sur Paramètres utilisateur.

Sélectionnez le bouton Générer un nouveau jeton, puis le bouton Générer.
Veillez à conserver une copie du jeton en lieu sûr. Votre fonction Azure a besoin de ce jeton pour s’authentifier auprès de Databricks et ainsi pouvoir exécuter la tâche.
Dans le menu du portail Azure ou dans la page Accueil, sélectionnez Créer une ressource.
Dans la page Nouveau, sélectionnez Calcul>Application de fonction.
Sous l’onglet Informations de base de la page Créer une application de fonction, choisissez un groupe de ressources, puis modifiez ou vérifiez les paramètres suivants :
Paramètre Valeur Nom de l’application de fonction contosoorder Pile d’exécution .NET Publier Code Système d'exploitation Windows Type de plan Consommation (serverless) Sélectionnez Examiner + créer, puis sélectionnez Créer.
Lorsque le déploiement est terminé, sélectionnez Accéder à la ressource pour ouvrir la page de vue d’ensemble de l’application de fonction.
Dans le groupe Paramètres, sélectionnez Configuration.
Dans la page Paramètres de l’application, cliquez sur le bouton Nouveau paramètre d’application pour ajouter chaque paramètre.

Ajoutez les paramètres suivants :
Nom du paramètre Valeur DBX_INSTANCE La région de votre espace de travail Databricks. Par exemple : westus2.azuredatabricks.netDBX_PAT Le jeton d’accès personnel que vous avez généré précédemment. DBX_JOB_ID L’identificateur du travail en cours d’exécution. Sélectionnez Enregistrer pour valider ces paramètres.
Dans le groupe Fonctions, sélectionnez Fonctions, puis Créer.
Choisissez le déclencheur Azure Event Grid.
Si vous y êtes invité, installez l’extension Microsoft.Azure.WebJobs.Extensions.EventGrid. Si vous devez l’installer, vous devrez choisir le déclencheur Azure Event Grid une nouvelle fois pour créer la fonction.
Le volet Nouvelle fonction s’affiche.
Dans le volet Nouvelle fonction, nommez la fonction UpsertOrder, puis sélectionnez le bouton Créer.
Remplacez le contenu du fichier de code par le code ci-après, puis sélectionnez le bouton Enregistrer :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Ce code analyse les informations sur l’événement de stockage qui a été déclenché, puis crée un message de requête avec l’URL du fichier qui a déclenché l’événement. La fonction transfère une valeur au widget source_file que vous avez créé précédemment dans le message. Le code de fonction envoie le message au travail Databricks et utilise le jeton que vous avez obtenu précédemment pour l’authentification.
Créer un abonnement Event Grid
Dans cette section, vous allez créer un abonnement Event Grid qui appelle la fonction Azure quand des fichiers sont chargés vers le compte de stockage.
Sélectionnez Intégration, puis dans la page Intégration, sélectionnez Déclencheur Event Grid.
Dans le volet Modifier le déclencheur, nommez l’événement
eventGridEvent, puis sélectionnez Créer un abonnement à un événement.Notes
Le nom
eventGridEventcorrespond au paramètre nommé qui est transmis à la fonction Azure.Sous l’onglet Informations de base de la page Créer un abonnement à un événement, modifiez ou vérifiez les paramètres suivants :
Paramètre Valeur Nom contoso-order-event-subscription Type de rubrique Compte de stockage Ressource source contosoorders Nom de la rubrique système <create any name>Filtrer les types d’événements Blob créé et blob supprimé Cliquez sur le bouton Créer.
Tester l’abonnement Event Grid
Créez un fichier nommé
customer-order.csv, collez les informations suivantes dans ce fichier, puis enregistrez-le sur votre ordinateur local.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneDans l’Explorateur Stockage, chargez ce fichier dans le dossier input de votre compte de stockage.
Le chargement d’un fichier déclenche l’événement Microsoft.Storage.BlobCreated. Event Grid informe tous les abonnés de cet événement. Dans le cas présent, la fonction Azure est le seul abonné. La fonction Azure analyse les paramètres d’événement pour déterminer l’événement qui s’est produit. Elle transfère ensuite l’URL du fichier au travail Databricks. Le travail Databricks lit le fichier, puis ajoute une ligne à la table Databricks Delta qui se trouve dans votre compte de stockage.
Pour vérifier si le travail a réussi, consultez les exécutions de votre travail. Vous verrez un état d’achèvement. Pour plus d’informations sur l’affichage des exécutions d’un travail, consultez Afficher les exécutions d’un travail.
Exécutez cette requête dans une nouvelle cellule de classeur pour voir la table Delta mise à jour.
%sql select * from customer_dataLa table retournée présente l’enregistrement le plus récent.

Pour mettre à jour cet enregistrement, créez un fichier nommé
customer-order-update.csv, collez les informations suivantes dans ce fichier, puis enregistrez-le sur votre ordinateur local.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneCe fichier csv est quasiment identique au précédent, sauf que la quantité de la commande est passée de
228à22.Dans l’Explorateur Stockage, chargez ce fichier dans le dossier input de votre compte de stockage.
Réexécutez la requête
selectpour voir la table delta mise à jour.%sql select * from customer_dataLa table retournée présente l’enregistrement mis à jour.

Nettoyer les ressources
Lorsque vous n’en avez plus besoin, supprimez le groupe de ressources et toutes les ressources associées. Pour ce faire, sélectionnez le groupe de ressources du compte de stockage, puis sélectionnez Supprimer.