Tutoriel : Analyser les rapports d’inventaire d’objets blob
En comprenant comment vos objets blob et conteneurs sont stockés, organisés et utilisés en production, vous pouvez mieux optimiser les compromis entre les coûts et les performances.
Ce tutoriel vous montre comment générer et visualiser des statistiques telles que la croissance des données au fil du temps, les données ajoutées au fil du temps, le nombre de fichiers modifiés, les tailles d’instantanés d’objets blob, les modèles d’accès sur chaque niveau et la façon dont les données sont distribuées actuellement et au fil du temps (par exemple : données entre les niveaux, les types de fichiers, dans les conteneurs et les types d’objets blob).
Dans ce tutoriel, vous allez apprendre à :
- Générer un rapport d’inventaire d’objets blob
- Configurer un espace de travail Synapse
- Configurer Synapse Studio
- Générer des données analytiques dans Synapse Studio
- Visualiser les résultats dans Power BI
Prérequis
Abonnement Azure : créer un compte gratuitement
Un compte de stockage Azure : créez un compte de stockage
Vérifiez que le rôle Contributeur aux données Blob du stockage est attribué à l’identité d’utilisateur.
Générer un rapport d’inventaire
Activez les rapports d’inventaire des objets blob à votre compte de stockage. Voir Activer les rapports d’inventaire d’objets blob de stockage Azure.
Vous devrez peut-être attendre jusqu’à 24 heures après avoir activé les rapports d’inventaire pour que votre premier rapport soit généré.
Configurer un espace de travail Synapse
Créer un espace de travail Azure Synapse. Voir Créer un espace de travail Azure Synapse.
Notes
Dans le cadre de la création de l’espace de travail, vous allez créer un compte de stockage qui a un espace de noms hiérarchique. Azure Synapse stocke les tables Spark et les journaux d’application dans ce compte. Azure Synapse fait référence à ce compte en tant que compte de stockage principal. Pour éviter toute confusion, cet article utilise le terme compte de rapport d’inventaire pour faire référence au compte qui contient des rapports d’inventaire.
Dans l’espace de travail Synapse, attribuez le rôle Contributeur à votre identité d’utilisateur. Voir Azure RBAC : Rôle de Propriétaire de l'espace de travail.
Donnez à l’espace de travail Synapse l’autorisation d’accéder aux rapports d’inventaire dans votre compte de stockage en accédant à votre compte de rapport d’inventaire, puis en attribuant le rôle Contributeur aux données Blob de stockage à l’identité managée système de l’espace de travail. Voir Attribuer des rôles Azure à l’aide du portail Azure.
Accédez au compte de stockage principal et attribuez le rôle Contributeur au stockage Blob à votre identité d’utilisateur.
Configurer Synapse Studio
Ouvrez votre espace de travail Synapse dans Synapse Studio. Consultez Ouvrir Synapse Studio.
Dans Synapse Studio, assurez-vous que le rôle Administrateur Synapse est attribué à votre identité. Voir Synapse RBAC : Rôle d'Administrateur Synapse de l'espace de travail.
Créer un pool Apache Spark. Consultez Créer un pool Apache Spark serverless.
Configurer et exécuter l’exemple de notebook
Dans cette section, vous allez générer des données statistiques que vous allez visualiser dans un rapport. Pour simplifier ce didacticiel, cette section utilise un exemple de fichier de configuration et un exemple de notebook PySpark. Le notebook contient une collection de requêtes qui s’exécutent dans Azure Synapse Studio.
Modifier et charger l’exemple de fichier de configuration
Téléchargez le fichier BlobInventoryStorageAccountConfiguration.json .
Mettez à jour les espaces réservés suivants de ce fichier :
Définissez
storageAccountNamesur le nom de votre compte de rapport d’inventaire.Définissez
destinationContainersur le nom du conteneur qui contient les rapports d’inventaire.Définissez
blobInventoryRuleNamesur le nom de la règle de rapport d’inventaire qui a généré les résultats que vous souhaitez analyser.Définissez
accessKeysur la clé de compte du compte de rapport d’inventaire.
Chargez ce fichier dans le conteneur de votre compte de stockage principal que vous avez spécifié lorsque vous avez créé l’espace de travail Synapse.
Importer l’exemple de notebook PySpark
Téléchargez l’exemple de notebook ReportAnalysis.ipynb .
Notes
Veillez à enregistrer ce fichier avec l’extension
.ipynb.Ouvrez votre espace de travail Synapse dans Synapse Studio. Consultez Ouvrir Synapse Studio.
Dans Synapse Studio, sélectionnez l’onglet Développer.
Sélectionnez le grand signe plus (+) pour ajouter un élément.
Sélectionnez Importer, accédez à l’exemple de fichier que vous avez téléchargé, sélectionnez ce fichier, puis sélectionnez Ouvrir.
La boîte de dialogue Properties (Propriétés) s’affiche.
Dans la boîte de dialogue Propriétés , sélectionnez le lien Configurer la session .
La boîte de dialogue Configurer la session s’ouvre.
Dans la liste déroulante Attacher à de la boîte de dialogue Configurer la session, sélectionnez le pool Spark que vous avez créé précédemment dans cet article. Ensuite, sélectionnez le bouton Appliquer.
Modifier le notebook Python
Dans la première cellule du notebook Python, définissez la valeur de la variable
storage_accountsur le nom du compte de stockage principal.Mettez à jour la valeur de la variable
container_nameavec le nom du conteneur dans ce compte que vous avez spécifié lors de la création de l’espace de travail Synapse.Cliquez sur le bouton Publier.
Exécuter le notebook PySpark
Dans le notebook PySpark, sélectionnez Exécuter tout.
Le démarrage de la session Spark prend quelques minutes et quelques minutes supplémentaires pour traiter les rapports d’inventaire. La première exécution peut prendre un certain temps s’il existe de nombreux rapports d’inventaire à traiter. Les exécutions suivantes traitent uniquement les nouveaux rapports d’inventaire créés depuis la dernière exécution.
Notes
Si vous apportez des modifications au bloc-notes que le bloc-notes est en cours d’exécution, veillez à publier ces modifications à l’aide du bouton Publier .
Vérifiez que le notebook s’est correctement exécuté en sélectionnant l’onglet Données .
Une base de données nommée reportdata doit apparaître sous l’onglet Espace de travail du volet Données . Si cette base de données n’apparaît pas, vous devrez peut-être actualiser la page web.
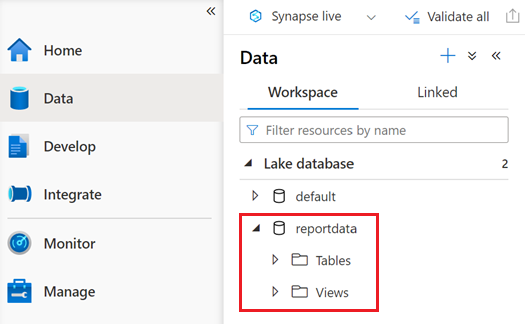
La base de données contient un ensemble de tables. Chaque table contient des informations obtenues en exécutant les requêtes à partir du notebook PySpark.
Pour examiner le contenu d’une table, développez le dossier Tables de la base de données reportdata . Cliquez ensuite avec le bouton droit sur une table, sélectionnez Sélectionner un script SQL, puis sélectionnez Sélectionner les 100 premières lignes.
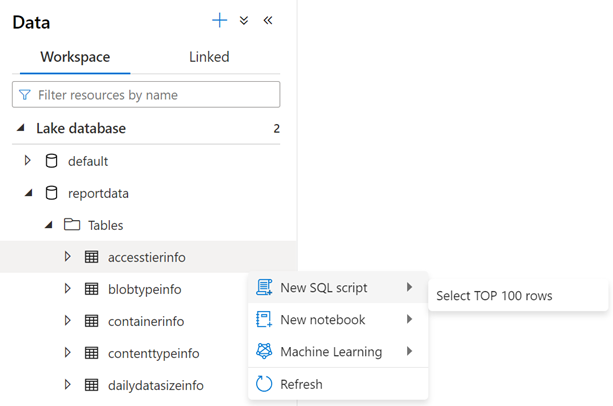
Vous pouvez modifier la requête en fonction des besoins, puis sélectionner Exécuter pour afficher les résultats.
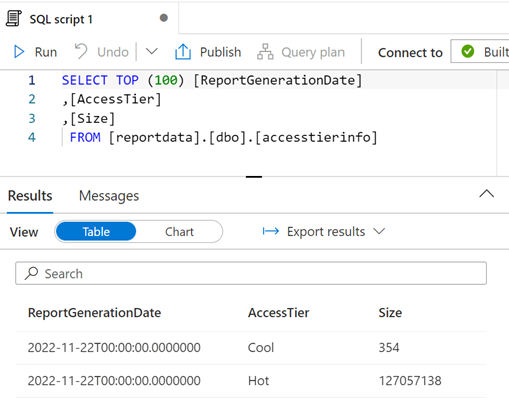
Visualiser les données
Téléchargez l’exemple de fichier de rapport ReportAnalysis.pbit .
Ouvrez Power BI Desktop. Pour obtenir des conseils d’installation, consultez Obtenir Power BI Desktop.
Dans Power BI, sélectionnez Fichier, Ouvrir un rapport, puis Parcourir les rapports.
Dans la boîte de dialogue Ouvrir, remplacez le type de fichier par Fichiers de modèle Power BI (*.pbit).

Accédez à l’emplacement du fichier ReportAnalysis.pbit que vous avez téléchargé, puis sélectionnez Ouvrir.
Une boîte de dialogue s’affiche et vous demande de fournir le nom de l’espace de travail Synapse et le nom de la base de données.
Dans la boîte de dialogue, définissez le champ synapse_workspace_name sur le nom de l’espace de travail et définissez le champ database_name sur
reportdata. Ensuite, sélectionnez le bouton Charger .
Un rapport s’affiche qui fournit des visualisations des données récupérées par le bloc-notes. Les images suivantes montrent les types de graphiques et de graphiques qui apparaissent dans ce rapport.
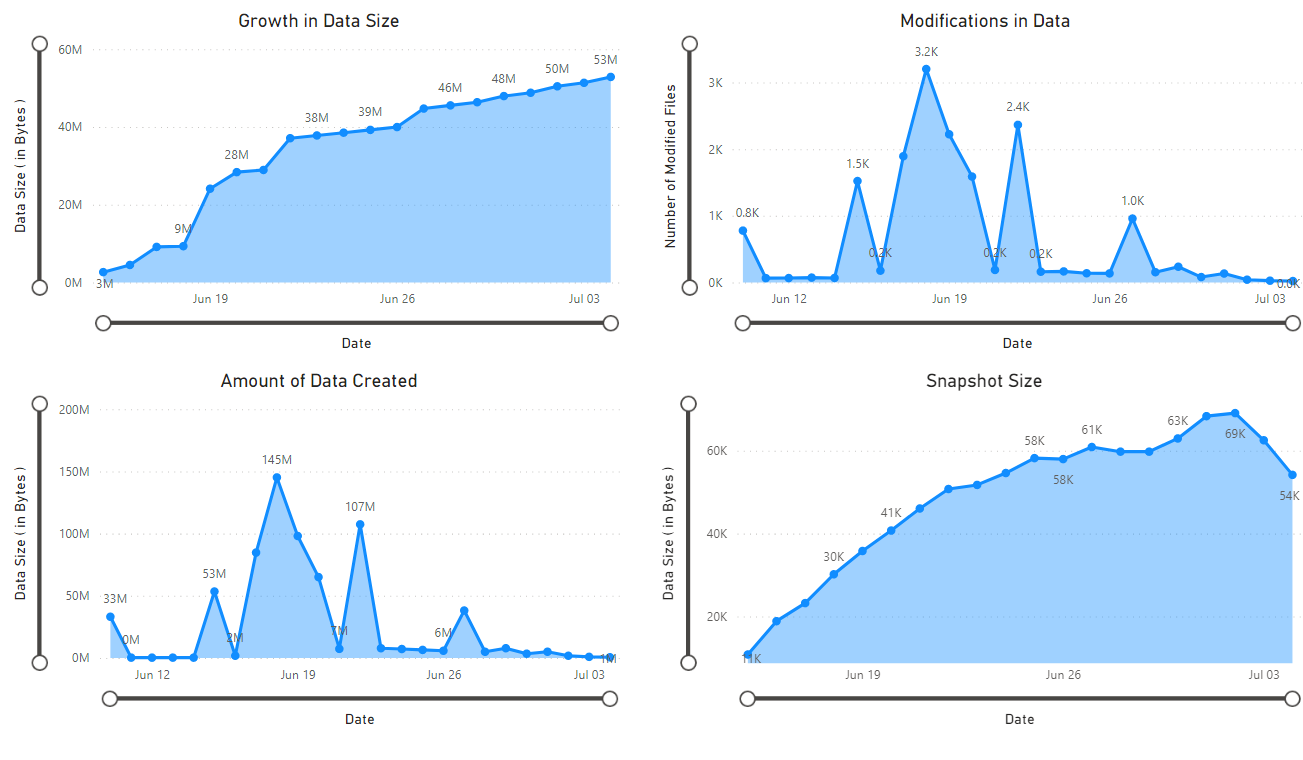
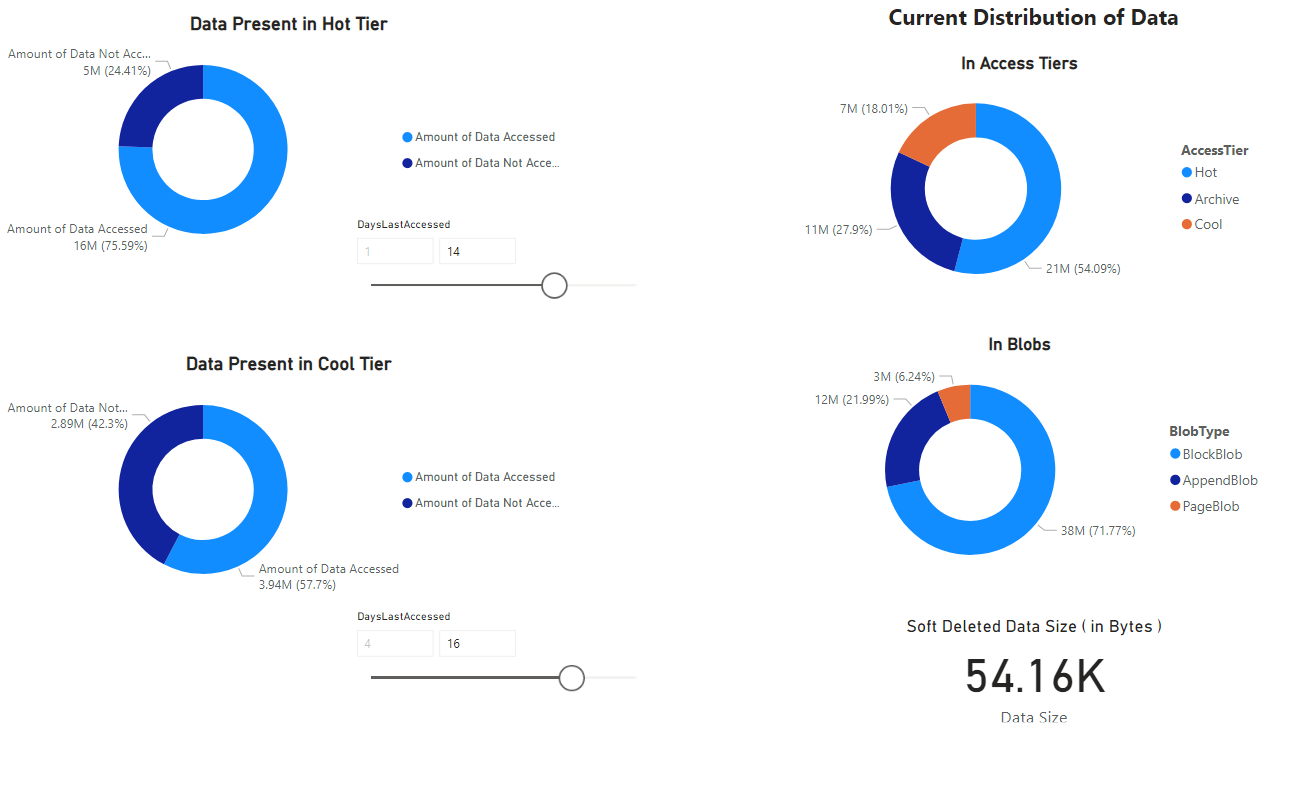
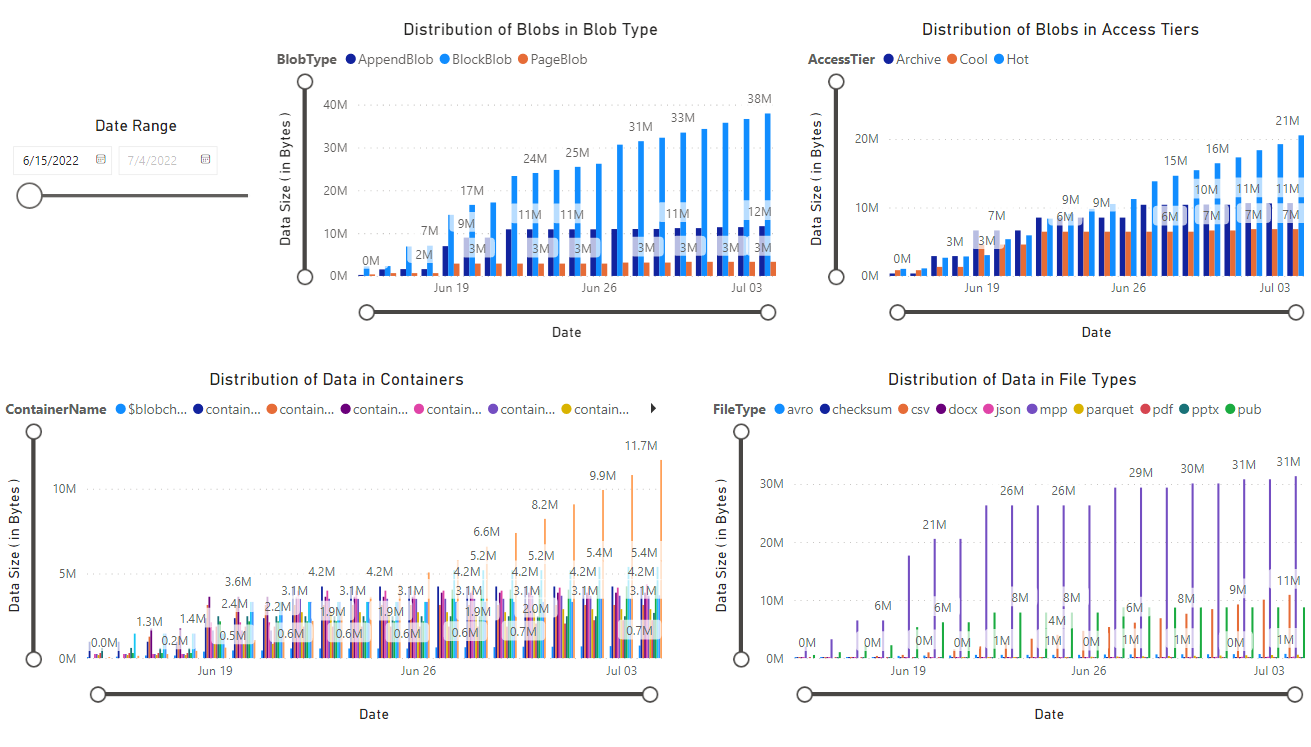
Étapes suivantes
Configurez un pipeline Azure Synapse pour continuer à exécuter votre notebook à intervalles réguliers. De cette façon, vous pouvez traiter de nouveaux rapports d’inventaire au fur et à mesure qu’ils sont créés. Après l’exécution initiale, chacune des exécutions suivantes analyse les données incrémentielles, puis met à jour les tables avec les résultats de cette analyse. Pour obtenir des conseils, consultez Intégrer avec des pipelines.
Découvrez les façons d’analyser des conteneurs individuels dans votre compte de stockage. Reportez-vous aux articles suivants :
Tutoriel : Calculer des statistiques de conteneur à l’aide de Databricks
Découvrez les façons d’optimiser vos coûts en fonction de l’analyse de vos objets blob et conteneurs. Reportez-vous aux articles suivants :
Planifier et gérer les coûts du Stockage Blob Azure
Estimer le coût de l’archivage des données
Optimiser les coûts en gérant automatiquement le cycle de vie des données