Déplacer un espace de travail Azure Synapse Analytics d’une région à une autre
Cet article est un guide pas à pas qui vous montre comment déplacer un espace de travail Azure Synapse Analytics d’une région Azure vers une autre.
Notes
Les étapes décrites dans cet article ne déplacent pas réellement l’espace de travail. Les étapes vous montrent comment créer un espace de travail dans une nouvelle région à l’aide d’Azure Synapse Analytics - sauvegardes et artefacts dédiés du pool SQL de la région source.
Prérequis
- Intégrez l’espace de travail Azure Synapse de la région source avec Azure DevOps ou GitHub. Pour plus d’informations, consultez Contrôle de code source dans Synapse Studio.
- Les modules Azure PowerShell et Azure CLI doivent être installés sur le serveur sur lequel les scripts sont exécutés.
- Assurez-vous que tous les services dépendants, par exemple, Azure Machine Learning, le stockage Azure et les hubs de liaison privée Azure, sont recréés dans la région cible ou déplacés vers la région cible si le service prend en charge un déplacement de région.
- Déplacer un Stockage Azure vers une autre région. Pour plus d’informations, consultez Déplacer un compte Stockage Azure vers une autre région.
- Vérifiez que le nom du pool SQL dédié et le nom du pool Apache Spark sont identiques dans la région source et l’espace de travail de la région cible.
Scénarios d’un déplacement dans une région
- Nouvelles exigences en matière de conformité : les organisations requièrent que les données et les services soient placés dans la même région dans le cadre de nouvelles exigences de conformité.
- Disponibilité d’une nouvelle région Azure : scénarios dans lesquels une nouvelle région Azure est disponible et où les besoins du projet ou commerciaux requièrent un déplacement de l’espace de travail et d’autres ressources Azure vers la nouvelle région Azure disponible.
- Région sélectionnée incorrecte : une région incorrecte a été sélectionnée lors de la création des ressources Azure.
Étapes pour déplacer un espace de travail Azure Synapse vers une autre région
Le déplacement d’un espace de travail Azure Synapse d’une région vers une autre est un processus à plusieurs étapes. Les étapes principales sont les suivantes :
- Créez un nouvel espace de travail Azure Synapse dans la région cible, ainsi qu’un pool Spark avec les mêmes configurations que celles utilisées dans l’espace de travail de la région source.
- Restaurez le pool SQL dédié dans la région cible à l’aide de points de restauration ou de géo-sauvegardes.
- Recréez toutes les connexions requises sur le nouveau Serveur SQL logique.
- Créez des objets et des bases de données de pool SQL et Spark sans serveur.
- Ajoutez un Principal de Service Azure DevOps au rôle d’Éditeur d’artefact Synapse de contrôle de l’accès en fonction du rôle (RBAC) Azure synapse si vous utilisez un pipeline de version Azure DevOps pour déployer les artefacts.
- Déployez l’artefact de code (Scripts SQL , Blocs-notes), les services liés, les pipelines, les jeux de données, les déclencheurs de définitions de tâche Spark et les informations d’identification des pipelines de version Azure DevOps vers l’espace de travail Azure Synapse de la région cible.
- Ajoutez des utilisateurs ou des groupes Microsoft Entra aux rôles RBAC Azure Synapse. Attribution d’un accès Contributeur de Stockage Blob à l’identité managée affectée par le système (SA-MI) sur le Stockage Azure et le Coffre de clés Azure Key si vous vous authentifiez à l’aide de l’identité managée.
- Attribuez les rôles de lecteur de Stockage blob ou de contributeur de Stockage blob à des utilisateurs requis Microsoft Entra sur le stockage attaché par défaut ou sur le compte Stockage contenant des données à interroger à l’aide d’un pool SQL serverless.
- Recréer un runtime d’intégration auto-hébergé (SHIR).
- Téléchargez manuellement toutes les bibliothèques et fichiers jar nécessaires dans l’espace de travail Azure Synapse cible.
- Créez tous les points de terminaison privés managés si l’espace de travail est déployé dans un réseau virtuel managé.
- Testez le nouvel espace de travail sur la région cible et mettez à jour toutes les entrées DNS qui pointent vers l’espace de travail de la région source.
- Si une connexion de point de terminaison privée est créée sur l’espace de travail source, créez-en une dans l’espace de travail de la région cible.
- Vous pouvez supprimer l’espace de travail dans la région source après l’avoir testé minutieusement et router toutes les connexions à l’espace de travail de la région cible.
Préparation
Étape 1 : créer un espace de travail Azure Synapse dans une région cible
Dans cette section, vous allez créer l’espace de travail Azure Synapse à l’aide d’Azure PowerShell, de l’interface CLI Azure et du portail Azure. Vous allez créer un groupe de ressources avec un compte Azure Data Lake Storage Gen2 qui sera utilisé comme stockage par défaut pour l’espace de travail dans le cadre du script PowerShell et du script CLI. Si vous souhaitez automatiser le processus de déploiement, appelez ces scripts PowerShell ou CLI à partir du pipeline de mise en production DevOps.
Portail Azure
Pour créer un espace de travail à partir du portail Azure, suivez les étapes de Démarrage rapide : créer un espace de travail Synapse.
Azure PowerShell
Le script suivant crée le groupe de ressources et l’espace de travail Azure Synapse à l’aide des applets de commande New-AzResourceGroup et New-AzSynapseWorkspace.
Créer un groupe de ressources
$storageAccountName= "<YourDefaultStorageAccountName>"
$resourceGroupName="<YourResourceGroupName>"
$regionName="<YourTargetRegionName>"
$containerName="<YourFileSystemName>" # This is the file system name
$workspaceName="<YourTargetRegionWorkspaceName>"
$sourceRegionWSName="<Your source region workspace name>"
$sourceRegionRGName="<YourSourceRegionResourceGroupName>"
$sqlUserName="<SQLUserName>"
$sqlPassword="<SQLStrongPassword>"
$sqlPoolName ="<YourTargetSQLPoolName>" #Both Source and target workspace SQL pool name will be same
$sparkPoolName ="<YourTargetWorkspaceSparkPoolName>"
$sparkVersion="2.4"
New-AzResourceGroup -Name $resourceGroupName -Location $regionName
Créer un compte Data Lake Storage Gen2
#If the Storage account is already created, then you can skip this step.
New-AzStorageAccount -ResourceGroupName $resourceGroupName `
-Name $storageAccountName `
-Location $regionName `
-SkuName Standard_LRS `
-Kind StorageV2 `
-EnableHierarchicalNamespace $true
Créer un espace de travail Azure Synapse
$password = ConvertTo-SecureString $sqlPassword -AsPlainText -Force
$creds = New-Object System.Management.Automation.PSCredential ($sqlUserName, $password)
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds
Si vous souhaitez créer l’espace de travail avec un Réseau virtuel managé, ajoutez le paramètre supplémentaire « ManagedVirtualNetwork » au script. Pour en savoir plus sur les options disponibles, consultez Configuration de réseau virtuel managé.
#Creating a managed virtual network configuration
$config = New-AzSynapseManagedVirtualNetworkConfig -PreventDataExfiltration -AllowedAadTenantIdsForLinking ContosoTenantId
#Creating an Azure Synapse workspace
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds `
-ManagedVirtualNetwork $config
Azure CLI
Ce script de l’interface CLI Azure crée un groupe de ressources, un compte Data Lake Storage Gen2 et un système de fichiers. Ensuite, il crée l’espace de travail Azure synapse.
Créer un groupe de ressources
az group create --name $resourceGroupName --location $regionName
Créer un compte Data Lake Storage Gen2
Le script suivant permet de créer un compte de stockage et un conteneur.
# Checking if name is not used only then creates it.
$StorageAccountNameAvailable=(az storage account check-name --name $storageAccountName --subscription $subscriptionId | ConvertFrom-Json).nameAvailable
if($StorageAccountNameAvailable)
{
Write-Host "Storage account Name is available to be used...creating storage account"
#Creating a Data Lake Storage Gen2 account
$storageAccountProvisionStatus=az storage account create `
--name $storageAccountName `
--resource-group $resourceGroupName `
--location $regionName `
--sku Standard_GRS `
--kind StorageV2 `
--enable-hierarchical-namespace $true
($storageAccountProvisionStatus| ConvertFrom-Json).provisioningState
}
else
{
Write-Host "Storage account Name is NOT available to be used...use another name -- exiting the script..."
EXIT
}
#Creating a container in a Data Lake Storage Gen2 account
$key=(az storage account keys list -g $resourceGroupName -n $storageAccountName|ConvertFrom-Json)[0].value
$fileShareStatus=(az storage share create --account-name $storageAccountName --name $containerName --account-key $key)
if(($fileShareStatus|ConvertFrom-Json).created -eq "True")
{
Write-Host f"Successfully created the fileshare - '$containerName'"
}
Créer un espace de travail Azure Synapse
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $containerName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName
Pour activer un réseau virtuel managé, incluez le paramètre --enable-managed-virtual-network dans le script précédent. Pour plus d’options, consultez réseau virtuel de l’espace de travail managé.
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $FileShareName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName `
--enable-managed-virtual-network true `
--allowed-tenant-ids "Contoso"
Étape 2 : créer une règle de pare-feu d’espace de travail Azure Synapse
Une fois l’espace de travail créé, ajoutez les règles de pare-feu pour l’espace de travail. Limitez les adresses IP à une certaine plage. Vous pouvez ajouter un pare-feu à partir du portail Azure ou à l’aide de PowerShell ou de l’interface CLI.
Portail Azure
Sélectionnez les options de pare-feu et ajoutez la plage d’adresses IP comme indiqué dans la capture d’écran suivante.

Azure PowerShell
Exécutez les commandes PowerShell suivantes pour ajouter des règles de pare-feu en spécifiant les adresses IP de début et de fin. Mettez à jour la plage d’adresses IP conformément à vos besoins.
$WorkspaceWeb = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Web
$WorkspaceDev = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Dev
# Adding firewall rules
$FirewallParams = @{
WorkspaceName = $workspaceName
Name = 'Allow Client IP'
ResourceGroupName = $resourceGroup
StartIpAddress = "0.0.0.0"
EndIpAddress = "255.255.255.255"
}
New-AzSynapseFirewallRule @FirewallParams
Exécutez le script suivant pour mettre à jour les paramètres de contrôle SQL de l’identité managée de l’espace de travail :
Set-AzSynapseManagedIdentitySqlControlSetting -WorkspaceName $workspaceName -Enabled $true
Azure CLI
az synapse workspace firewall-rule create --name allowAll --workspace-name $workspaceName `
--resource-group $resourceGroupName --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255
Exécutez le script suivant pour mettre à jour les paramètres de contrôle SQL de l’identité managée de l’espace de travail :
az synapse workspace managed-identity grant-sql-access `
--workspace-name $workspaceName --resource-group $resourceGroupName
Etape 3 : Créer un pool Apache Spark
Créez le pool Spark avec la même configuration que celle utilisée dans l’espace de travail de la région source.
Portail Azure
Pour créer un pool Spark à partir du portail Azure, consultez Démarrage rapide : créer un nouveau pool Apache Spark sans serveur à l’aide du portail Azure.
Vous pouvez également créer le pool Spark à partir de Synapse Studio en suivant les étapes décrites dans Démarrage rapide : créer un pool de Apache Spark sans serveur à l’aide de Synapse Studio.
Azure PowerShell
Le script suivant crée un pool Spark avec deux workers et un nœud de pilote, ainsi qu’un petit cluster avec 4 cœurs et 32 Go de RAM. Mettez à jour les valeurs pour qu’elles correspondent au pool Spark de l’espace de travail de votre région source.
#Creating a Spark pool with 3 nodes (2 worker + 1 driver) and a small cluster size with 4 cores and 32 GB RAM.
New-AzSynapseSparkPool `
-WorkspaceName $workspaceName `
-Name $sparkPoolName `
-NodeCount 3 `
-SparkVersion $sparkVersion `
-NodeSize Small
Azure CLI
az synapse spark pool create --name $sparkPoolName --workspace-name $workspaceName --resource-group $resourceGroupName `
--spark-version $sparkVersion --node-count 3 --node-size small
Déplacer
Etape 4 : Restaurer un pool SQL dédié
Restauration à partir de sauvegardes géo-redondantes
Pour restaurer les pools SQL dédiés à partir de la géo-sauvegarde à l’aide du portail Azure et de PowerShell, consultez Géo-restauration d’un pool SQL dédié dans Azure Synapse Analytics.
Restaurer à l’aide de points de restauration à partir du pool SQL dédié de l’espace de travail de la région source
Restaurez le pool SQL dédié dans l’espace de travail de la région cible à l’aide du point de restauration du pool SQL dédié de l’espace de travail de la région source. Vous pouvez utiliser le portail Azure, Synapse Studio ou PowerShell pour effectuer une restauration à partir de points de restauration. Si la région source n’est pas accessible, vous ne pouvez pas effectuer de restauration à l’aide de cette option.
Synapse Studio
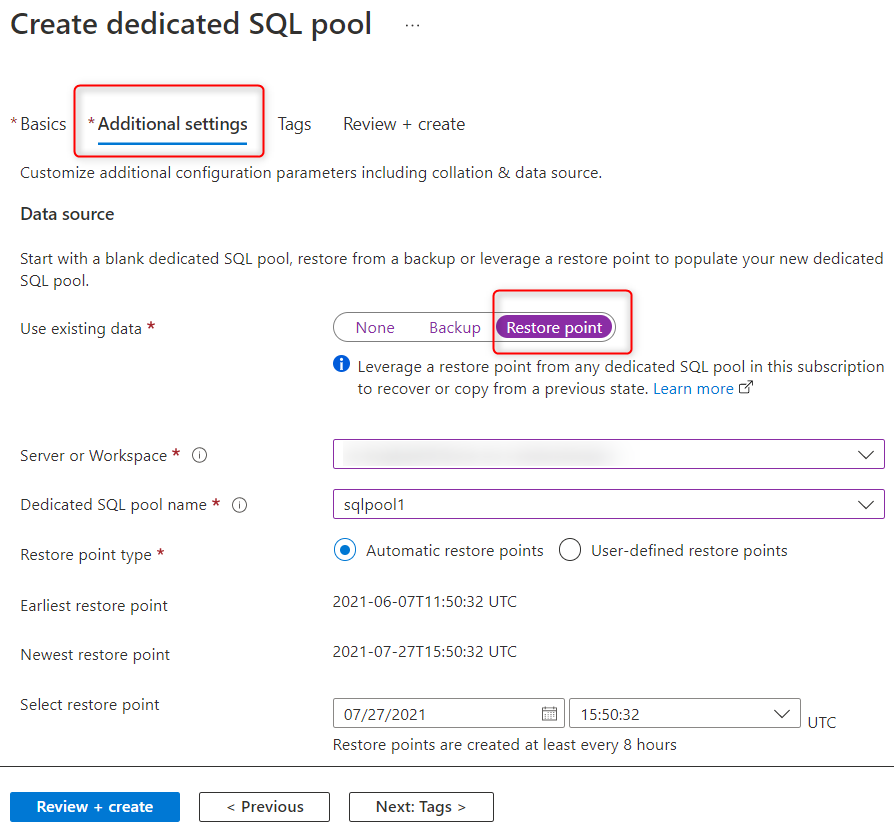
A partir de Synapse Studio, vous pouvez restaurer le pool SQL dédié à partir de n’importe quel espace de travail de l’abonnement à l’aide de points de restauration. Lorsque vous créez le pool SQL dédié, sous Paramètres supplémentaires, sélectionnez Point de restauration et sélectionnez l’espace de travail comme indiqué dans la capture d’écran suivante. Si vous avez créé un point de restauration défini par l’utilisateur, utilisez-le pour restaurer le pool SQL. Dans le cas contraire, vous pouvez sélectionner le dernier point de restauration automatique.
Azure PowerShell
Exécutez le script PowerShell suivant pour restaurer l’espace de travail. Ce script utilise le dernier point de restauration du pool SQL dédié de l’espace de travail source pour restaurer le pool SQL sur l’espace de travail cible. Avant d’exécuter le script, mettez à jour le niveau de performance de DW100c vers la valeur requise.
Important
Le nom du pool SQL dédié doit être le même sur les deux espaces de travail.
Obtenez les points de restauration :
$restorePoint=Get-AzSynapseSqlPoolRestorePoint -WorkspaceName $sourceRegionWSName -Name $sqlPoolName|Sort-Object -Property RestorePointCreationDate -Descending `
| SELECT RestorePointCreationDate -ExpandProperty RestorePointCreationDate -First 1
Transformez l’ID de ressource du pool SQL Azure Synapse en ID de base de données SQL, car la commande n’accepte pour l’instant que l’ID de base de données SQL.
Par exemple : /subscriptions/<SubscriptionId>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Sql/servers/<WorkspaceName>/databases/<DatabaseName>
$pool = Get-AzSynapseSqlPool -ResourceGroupName $sourceRegionRGName -WorkspaceName $sourceRegionWSName -Name $sqlPoolName
$databaseId = $pool.Id `
-replace "Microsoft.Synapse", "Microsoft.Sql" `
-replace "workspaces", "servers" `
-replace "sqlPools", "databases"
$restoredPool = Restore-AzSynapseSqlPool -FromRestorePoint `
-RestorePoint $restorePoint `
-TargetSqlPoolName $sqlPoolName `
-ResourceGroupName $resourceGroupName `
-WorkspaceName $workspaceName `
-ResourceId $databaseId `
-PerformanceLevel DW100c -AsJob
Le code suivant suit l’état de l’opération de restauration :
Get-Job | Where-Object Command -In ("Restore-AzSynapseSqlPool") | `
Select-Object Id,Command,JobStateInfo,PSBeginTime,PSEndTime,PSJobTypeName,Error |Format-Table
Une fois le pool SQL dédié restauré, créez toutes les connexions SQL dans Azure Synapse. Pour créer toutes les connexions, suivez les étapes dans Créer une connexion.
Étape 5 : Créer un pool SQL serverless, une base de données de pool Spark et des objets
Vous ne pouvez ni sauvegarder ni restaurer les bases de données du pool SQL sans serveur et des pools Spark. En guise de solution de contournement possible, vous pouvez :
- Créez des blocs-notes et des scripts de SQL, qui comportent le code permettant de recréer tous les pools Spark requis, les bases de données des pools SQL sans serveur, les tables, les rôles et les utilisateurs avec toutes les attributions de rôles. Vérifiez ces artefacts pour Azure DevOps ou GitHub.
- Si le nom du compte Stockage est modifié, assurez-vous que les artefacts de code pointent vers le nom de compte de stockage correct.
- Créer des pipelines, qui appellent ces artefacts de code dans une séquence spécifique. Lorsque ces pipelines sont exécutés sur l’espace de travail de la région cible, les bases de données SQL Spark, les bases de données du pool SQL sans serveur, les sources de données externes, les vues, les rôles, les utilisateurs et les autorisations seront créés dans l’espace de travail de la région cible.
- Lorsque vous intégrez l’espace de travail de la région source à Azure DevOps, ces artefacts de code feront partie du référentiel. Ultérieurement, vous pouvez déployer ces artefacts de code dans l’espace de travail de la région cible à l’aide du pipeline de mise en production DevOps, comme indiqué à l’étape 6.
- Dans l’espace de travail de la région cible, déclenchez ces pipelines manuellement.
Étape 6 : Déployer des artefacts et des pipelines à l’aide de CI/CD
Pour savoir comment intégrer un espace de travail Azure Synapse avec Azure DevOps ou GitHub et comment déployer les artefacts dans l’espace de travail d’une région cible, suivez les étapes dans Intégration continue et de livraison continue (CI/CD) pour un espace de travail Azure Synapse.
Une fois que l’espace de travail est intégré à Azure DevOps, vous trouverez une branche portant le nom workspace_publish. Cette branche contient le modèle d’espace de travail qui inclut des définitions pour les artefacts tels que les Blocs-notes, les Scripts SQL, les Jeux de données, les Services liés, les Pipelines, les Déclencheurs et la définition de tâche Spark.
Cette capture d’écran du référentiel Azure DevOps affiche les fichiers de modèle de l’espace de travail pour les artefacts et autres composants.
Vous pouvez utiliser le modèle d’espace de travail pour déployer des artefacts et des pipelines dans un espace de travail à l’aide du pipeline de mise en production Azure DevOps.
Si l’espace de travail n’est pas intégré à GitHub ou Azure DevOps, vous devez recréer ou écrire manuellement des scripts PowerShell ou Azure CLI personnalisés pour déployer tous les artefacts, pipelines, services liés, informations d’identification, déclencheurs et définitions Spark dans l’espace de travail de la région cible.
Notes
Ce processus nécessite que vous ayez à mettre à jour les pipelines et les artefacts de code pour inclure toutes les modifications apportées à Spark et aux pools SQL sans serveur, aux objets et aux rôles dans les espaces de travail de la région source.
Étape 7 : Créer un runtime d’intégration partagé
Pour créer un SHIR, suivez les étapes dans Créer et configurer un runtime d’intégration auto-hébergé.
Étape 8 : Affecter un rôle Azure à une identité managée
Affectez l'Storage Blob Contributoraccès à l’identité gérée du nouvel espace de travail sur le compte Data Lake Storage Gen2 attaché par défaut. Attribuez également l’accès à d’autres comptes de stockage où SA-MI est utilisée pour l’authentification. Attribuez à Storage Blob Contributor ou Storage Blob Reader l’accès aux utilisateurs et groupes Microsoft Entra pour tous les comptes de stockage requis.
Portail Azure
Suivez les étapes décrites dans Accorder des autorisations à l’identité managée de l’espace de travail pour affecter un rôle Contributeur de données d’objets Blob de stockage à l’identité managée de l’espace de travail.
Azure PowerShell
Affectez un rôle de Contributeur de données blob de stockage à l’identité managée de l’espace de travail.
Attribuez le rôle Contributeur aux données blob du stockage à l’identité managée de l’espace de travail sur le compte de stockage. L’exécution de New-AzRoleAssignment génère des erreurs avec le message Exception of type 'Microsoft.Rest.Azure.CloudException' was thrown., mais crée les autorisations requises sur le compte de stockage.
$workSpaceIdentityObjectID= (Get-AzSynapseWorkspace -ResourceGroupName $resourceGroupName -Name $workspaceName).Identity.PrincipalId
$scope = "/subscriptions/$($subscriptionId)/resourceGroups/$($resourceGroupName)/providers/Microsoft.Storage/storageAccounts/$($storageAccountName)"
$roleAssignedforManagedIdentity=New-AzRoleAssignment -ObjectId $workSpaceIdentityObjectID `
-RoleDefinitionName "Storage Blob Data Contributor" `
-Scope $scope -ErrorAction SilentlyContinue
Azure CLI
Obtenez le nom du rôle, l’ID de ressource et l’ID de principal de l’identité managée de l’espace de travail, puis ajoutez le rôle Contributeur aux données blob du stockage à SA-MI.
# Getting Role name
$roleName =az role definition list --query "[?contains(roleName, 'Storage Blob Data Contributor')].{roleName:roleName}" --output tsv
#Getting resource id for storage account
$scope= (az storage account show --name $storageAccountName|ConvertFrom-Json).id
#Getting principal ID for workspace managed identity
$workSpaceIdentityObjectID=(az synapse workspace show --name $workspaceName --resource-group $resourceGroupName|ConvertFrom-Json).Identity.PrincipalId
# Adding Storage Blob Data Contributor Azure role to SA-MI
az role assignment create --assignee $workSpaceIdentityObjectID `
--role $roleName `
--scope $scope
Étape 9 : Attribuer des rôles RBAC Azure Synapse
Ajoutez tous les utilisateurs qui ont besoin d’accéder à l’espace de travail cible avec des rôles et des autorisations distincts. Le script PowerShell et CLI suivant ajoute un utilisateur Microsoft Entra au rôle Administrateur Synapse dans l’espace de travail de la région cible.
Pour obtenir tous les noms de rôle RBAC Azure Synapse, consultez rôles RBAC Azure Synapse.
Synapse Studio
Pour ajouter ou supprimer des affectations Azure Synapse RBAC à partir de Synapse Studio, suivez les étapes dans Gestion des attributions de rôles Azure Synapse RBAC dans Synapse Studio.
Azure PowerShell
Le script PowerShell suivant ajoute l’attribution de rôle Administrateur Synapse à un utilisateur ou un groupe Microsoft Entra. Vous pouvez utiliser-RoleDefinitionId au lieu de-RoleDefinitionName avec la commande suivante pour ajouter les utilisateurs à l’espace de travail :
New-AzSynapseRoleAssignment `
-WorkspaceName $workspaceName `
-RoleDefinitionName "Synapse Administrator" `
-ObjectId aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb
Get-AzSynapseRoleAssignment -WorkspaceName $workspaceName
Pour obtenir les ObjectIds et RoleIds dans l’espace de travail de la région source, exécutez la commande Get-AzSynapseRoleAssignment. Affectez les mêmes rôles RBAC Azure Synapse aux utilisateurs ou groupes Microsoft Entra dans l’espace de travail de la région cible.
Au lieu d’utiliser -ObjectId comme paramètre, vous pouvez utiliser -SignInName en indiquant l’adresse e-mail ou le nom d’utilisateur principal de l’utilisateur. Pour en savoir plus sur les options disponibles, consultez applet de commande RBAC Azure Synapse - PowerShell.
Azure CLI
Obtenez l’ID d’objet de l’utilisateur et affectez les autorisations RBAC Azure Synapse requises à l’utilisateur Microsoft Entra. Vous pouvez fournir l’adresse e-mail de l’utilisateur (username@contoso.com) pour le paramètre --assignee.
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Administrator" --assignee adasdasdd42-0000-000-xxx-xxxxxxx
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Contributor" --assignee "user1@contoso.com"
Pour en savoir plus sur les options disponibles, consultez RBAC - CLI Azure Synapse.
Etape 10 : Télécharger des packages de l’espace de travail
Télécharger tous les packages d’espace de travail requis vers le nouvel espace de travail. Pour automatiser le processus de téléchargement des packages de l’espace de travail, consultez Bibliothèque cliente des artefacts Microsoft Azure Synapse Analytics.
Étape 11 : Autorisations
Pour configurer le contrôle d’accès pour l’espace de travail Azure Synapse de la région cible, suivez les étapes décrites dans Comment configurer le contrôle d’accès pour votre espace de travail Azure Synapse.
Étape 12 : Créer des points de terminaison privés managés
Pour recréer les points de terminaison privés managés à partir de l’espace de travail de la région source dans votre espace de travail de la région cible, consultez Créer un point de terminaison privé managé vers votre source de données.
Abandonner
Si vous souhaitez abandonner l’espace de travail de la région cible, supprimez-le. Pour ce faire, sélectionnez le groupe de ressources à partir de votre tableau de bord dans le portail, puis sélectionnez Supprimer en haut de la page Groupe de ressources.
Nettoyage
Pour valider les modifications et terminer le déplacement de l’espace de travail, supprimez l’espace de travail de la région source après avoir testé l’espace de travail dans la région cible. Pour ce faire, sélectionnez le groupe de ressources qui a l’espace de travail de la région source à partir de votre tableau de bord dans le portail, puis sélectionnez Supprimer en haut de la page Groupe de ressources.
Étapes suivantes
- En savoir plus sur les réseaux virtuels managés par Azure Synapse.
- En savoir plus sur les Points de terminaison privés managés Azure Synapse.
- En savoir plus sur la Connexion aux ressources de l’espace de travail à partir d’un réseau restreint.