Tutoriel : Créer une application d’apprentissage automatique avec Apache Spark MLlib et Azure Synapse Analytics
Cet article explique comment utiliser Apache Spark MLlib pour créer une application d’apprentissage automatique qui effectue une analyse prédictive simple sur un jeu de données ouvert Azure. Spark fournit des bibliothèques d’apprentissage automatique intégrées. Cet exemple utilise un classification par régression logistique.
SparkML et MLlib sont des bibliothèques Spark de base qui fournissent de nombreux utilitaires utiles pour les tâches de machine learning. Certains de ces utilitaires conviennent pour les tâches suivantes :
- classification ;
- régression ;
- Clustering
- Modélisation de rubrique
- Décomposition de valeur singulière (SVD) et analyse des composants principaux (PCA)
- Hypothèse de test et de calcul des exemples de statistiques
Comprendre la classification et la régression logistique
Une classification, tâche de Machine Learning très courante, est le processus de tri de données d’entrée par catégories. La fonction d’un algorithme de classification consiste à déterminer comment affecter des étiquettes aux données d’entrée que vous fournissez. Par exemple, vous pouvez imaginer un algorithme de machine learning qui accepte des informations de stock en entrée et classe le stock en deux catégories : le stock à vendre et le stock à conserver.
Une régression logistique est un algorithme que vous utilisez pour effectuer une classification. L’API de régression logistique de Spark est utile pour la classification binaireou pour classer les données d’entrée dans un des deux groupes. Pour plus d’informations sur la régression logistique, consultez Wikipedia.
En résumé, le processus de régression logistique génère une fonction logistique dont vous pouvez vous servir pour prédire la probabilité qu’un vecteur d’entrée appartient à un groupe ou à l’autre.
Exemple d’analyse prédictive sur les données des taxis de New York
Dans cet exemple, vous utilisez Spark pour effectuer une analyse prédictive sur les données de pourboires liés aux courses de taxi à New York. Les données sont disponibles dans Azure Open Datasets. Ce sous-ensemble du jeu de données contient des données sur les courses de taxis jaunes, qui incluent des informations sur chaque course, les heures et lieux de départ et d’arrivé, le prix et d’autres attributs intéressants.
Important
Des frais supplémentaires peuvent s’appliquer pour l’extraction de ces données à partir de leur emplacement de stockage.
Dans les étapes suivantes, vous allez développer un modèle pour prédire si un voyage particulier inclut ou non un pourboire.
Créer un modèle de machine learning Apache Spark
Créez un notebook en utilisant le noyau PySpark. Pour obtenir des instructions, consultez Créer un notebook.
Importez les types requis pour cette application. Copiez et collez le code suivant dans une cellule vide, puis appuyez sur Maj+Entrée. Vous pouvez aussi exécuter la cellule à l’aide de l’icône de lecture bleue située à gauche du code.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorGrâce au noyau PySpark, il est inutile de créer des contextes explicitement. Le contexte Spark est créé automatiquement pour vous lorsque vous exécutez la première cellule de code.
Construire le DataFrame d’entrée
Comme les données brutes sont au format Parquet, vous pouvez utiliser le contexte Spark pour extraire le fichier en mémoire directement en tant que DataFrame. Même si le code des étapes suivantes utilise les options par défaut, il est possible de forcer le mappage des types de données et d’autres attributs de schéma si nécessaire.
Exécutez les lignes suivantes pour créer un DataFrame Spark en collant le code dans une nouvelle cellule. Cette étape récupère les données via l’API Open Datasets. L’extraction de toutes ces données génère environ 1,5 milliard de lignes.
Selon la taille de votre pool Apache Spark serverless, il est possible que les données brutes soient trop volumineuses ou que leur exploitation prenne trop de temps. Vous pouvez filtrer ces données pour en réduire le volume. L’exemple de code suivant utilise
start_dateetend_datepour appliquer un filtre qui retourne un seul mois de données.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())L’inconvénient du filtrage simple est que, du point de vue statistique, il peut introduire un biais dans les données. Une autre approche consiste à utiliser l’échantillonnage intégré dans Spark.
Le code suivant réduit le jeu de données à environ 2 000 lignes, s’il est appliqué après le code précédent. Vous pouvez utiliser cette étape d’échantillonnage à la place du filtre simple ou en association avec celui-ci.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Il est désormais possible d’examiner les données pour voir ce qui a été lu. Selon la taille du jeu de données, il est normalement préférable d’examiner les données avec un sous-ensemble plutôt qu’avec le jeu complet.
Le code suivant offre deux façons d’afficher les données. La première est basique. La deuxième offre une expérience de grille beaucoup plus riche ainsi que la possibilité de visualiser les données sous forme graphique.
#sampled_taxi_df.show(5) display(sampled_taxi_df)Selon la taille du jeu de données généré et la nécessité ou non d’expérimenter ou d’exécuter le notebook plusieurs fois, vous pouvez mettre en cache le jeu de données localement dans l’espace de travail. Il existe trois façons d'effectuer une mise en cache explicite :
- Enregistrez le DataFrame localement en tant que fichier.
- Enregistrez le DataFrame en tant que table ou vue temporaire.
- Enregistrez le DataFrame en tant que table permanente.
Les deux premières approches sont incluses dans les exemples de code suivants.
Le chemin d’accès aux données varie selon que vous créez une table ou une vue temporaire, mais il ne dure que le temps de la session de l’instance Spark.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Préparer les données
Les données dans leur forme brute sont souvent inadaptées pour une transmission directe à un modèle. Vous devez effectuer une série d’actions sur les données pour les rendre utilisables par le modèle.
Dans le code suivant, vous effectuez quatre classes d’opérations :
- suppression des valeurs hors norme ou incorrectes par filtrage ;
- suppression des colonnes superflues ;
- création de colonnes dérivées des données brutes pour un assurer un fonctionnement plus efficace du modèle. Cette opération est parfois appelée caractérisation.
- étiquetage. Comme vous procédez à une classification binaire (y aura-t-il ou non un pourboire à l’issue d’une course donnée), il est nécessaire de convertir le montant du pourboire en valeur 0 ou 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Vous effectuez ensuite une deuxième passe sur les données pour ajouter les caractéristiques finales.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Créer un modèle de régression logistique
La dernière tâche consiste à convertir les données étiquetées en format analysable par régression logistique. L’entrée dans un algorithme de régression logistique doit être un jeu de paires de vecteurs étiquette/caractéristique, où le vecteur caractéristique est un vecteur de nombres qui représentent le point d’entrée.
Vous devez donc convertir les colonnes catégoriques en nombres. Plus précisément, vous devez convertir les colonnes trafficTimeBins et weekdayString en représentations entières. Cette conversion peut être effectuée en suivant plusieurs approches. L’exemple ci-dessous suit l’approche OneHotEncoder, qui est courante.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Cette action génère un nouveau DataFrame dont les colonnes sont toutes dans un format adapté à l’entraînement d’un modèle.
Entraîner un modèle de régression logistique
La première tâche consiste à diviser le jeu de données en un jeu d’entraînement et un jeu de test ou de validation. La division est ici arbitraire. Faites des essais avec différents paramètres de division pour voir s’ils ont un effet sur le modèle.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Maintenant qu’il existe deux DataFrames, la tâche suivante consiste à créer la formule du modèle et à l’exécuter sur le DataFrame d’entraînement. Vous pouvez ensuite effectuer une validation par rapport au DataFrame de test. Faites des essais avec différentes versions de la formule du modèle pour voir l’impact de différentes combinaisons.
Notes
Pour enregistrer le modèle, affectez le rôle Contributeur de données d’objet blob de stockage à l’étendue de la ressource serveur d’Azure SQL Database. Pour connaître les étapes détaillées, consultez Attribuer des rôles Azure à l’aide du portail Azure. Seuls les membres dotés de privilèges de propriétaire peuvent effectuer cette étape.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
La sortie de cette cellule est :
Area under ROC = 0.9779470729751403
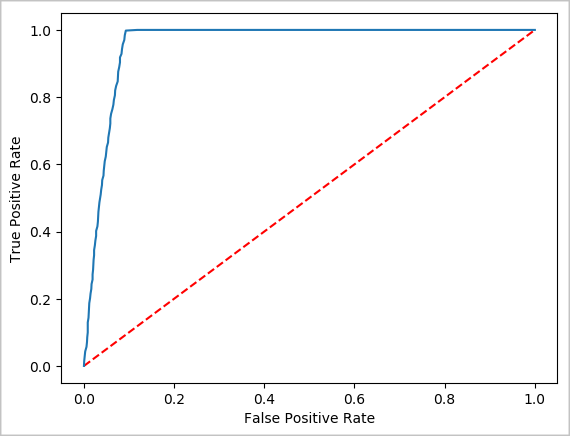
Créer une représentation visuelle de la prédiction
Vous pouvez désormais construire une visualisation finale pour faciliter l’examen des résultats de ce test. La courbe ROC est une façon d’examiner les résultats.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Arrêter l’instance Spark
Une fois l’exécution de l’application terminée, arrêtez le notebook pour libérer les ressources en fermant l’onglet. Vous pouvez aussi sélectionner Terminer la session dans le panneau d’état au bas du notebook.