Résilience des données SharePoint et OneDrive dans Microsoft 365
Dans Microsoft 365, OneDrive repose sur la plateforme de fichiers SharePoint. Dans cet article, seul SharePoint est utilisé pour faire référence aux deux produits. Cet article s’applique également à tous les autres produits qui stockent des données dans SharePoint, tels que les pièces jointes cloud, les fichiers partagés dans Teams, les enregistrements et transcriptions de réunions Teams, les composants de boucle et les tableaux blancs.
Il existe deux ressources principales qui composent le stockage de contenu principal de SharePoint :
- Stockage Blob : le contenu utilisateur chargé dans SharePoint est stocké dans stockage Azure. SharePoint a créé un plan de résilience personnalisé en plus du stockage Azure pour garantir une duplication en quasi-temps réel du contenu utilisateur et un système réellement actif/actif.
- Métadonnées : les métadonnées relatives à chaque fichier sont stockées dans Azure SQL Database. Azure SQL offre une histoire complète de continuité d’activité que SharePoint utilise et les détails sont abordés plus loin dans cet article.
L’ensemble complet de contrôles pour garantir la résilience des données est expliqué dans d’autres sections.
Résilience du stockage d’objets blob
SharePoint dispose d’une solution personnalisée pour le stockage des données client dans stockage Azure. Chaque fichier est écrit simultanément dans une région de centre de données primaire et secondaire. Si les écritures dans l’une ou l’autre région Azure échouent, l’enregistrement du fichier échoue. Une fois le contenu écrit dans le Stockage Azure, les sommes de contrôle sont stockées séparément avec les métadonnées et sont utilisées pour garantir que l’écriture validée est identique au fichier d’origine lors de toutes les lectures ultérieures. Cette même technique est utilisée dans tous les flux de travail pour empêcher la propagation de toute altération qui doit se produire. Dans chaque région, le stockage localement redondant (LRS) Azure offre un haut niveau de fiabilité.
SharePoint utilise Append-Only stockage, ce qui signifie que Microsoft peut uniquement ajouter de nouveaux objets blob et ne peut jamais en modifier les anciens jusqu’à ce qu’ils soient définitivement supprimés. Ce processus garantit que les fichiers ne peuvent pas être modifiés ou endommagés après un enregistrement initial, ce qui protège contre les attaquants qui tentent d’endommager les anciennes versions. Étant donné que la protection de l’intégrité des versions est intégrée à l’architecture de SharePoint, les versions précédentes du contenu du fichier peuvent être récupérées, en fonction des paramètres d’administrateur individuels.
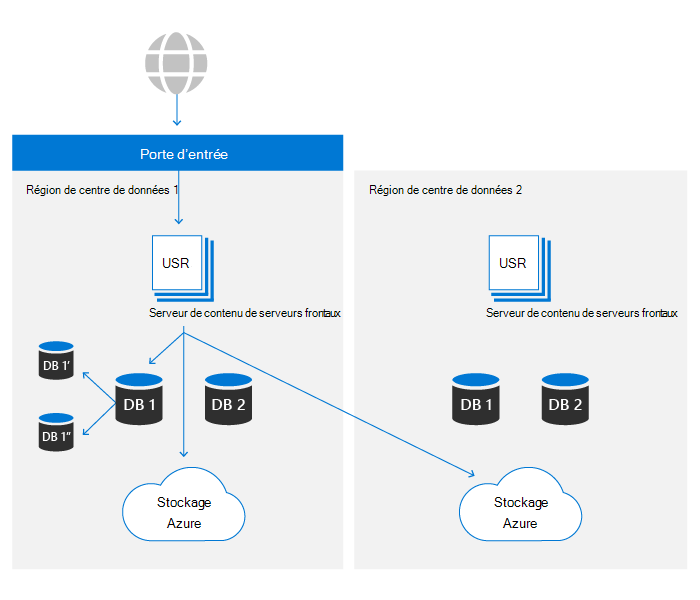
Les environnements SharePoint dans les deux centres de données peuvent accéder aux conteneurs de stockage dans les deux régions Azure. Pour des raisons de performances, le conteneur de stockage dans le même centre de données local est toujours préférable. Toutefois, les demandes de lecture qui ne voient pas les résultats dans un seuil souhaité ont le même contenu demandé au centre de données distant pour garantir que les données sont toujours disponibles.
Résilience des métadonnées
Les métadonnées SharePoint sont également essentielles pour accéder au contenu utilisateur, car elles stockent l’emplacement et les clés d’accès au contenu stocké dans stockage Azure. Ces bases de données sont stockées dans Azure SQL, qui dispose d’un plan de continuité d’activité complet.
SharePoint utilise le modèle de réplication fourni par Azure SQL et a créé une technologie d’automatisation propriétaire pour déterminer qu’un basculement est nécessaire et lancer l’opération si nécessaire. Par conséquent, il appartient à la catégorie « Basculement manuel de base de données » du point de vue d’Azure SQL. Les dernières métriques pour la récupération de base de données Azure SQL sont disponibles ici.
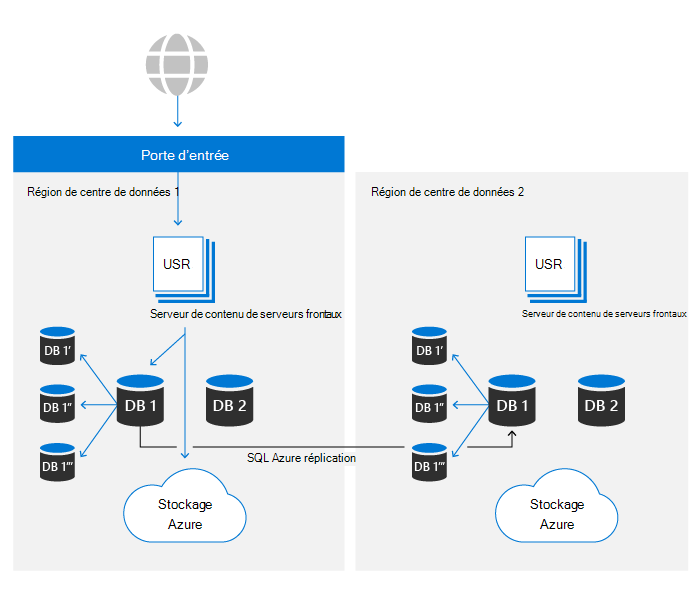
SharePoint utilise le système de sauvegarde d’Azure SQL pour activer les restaurations à un point dans le temps (PITR) pendant 14 jours maximum.
Basculement automatisé
SharePoint utilise un basculement automatisé personnalisé pour réduire l’impact sur l’expérience client lorsqu’un événement spécifique à un emplacement se produit. L’automatisation pilotée par la surveillance qui détecte une défaillance à composant unique ou multicomposant au-delà de certains seuils entraîne une redirection automatisée de l’activité de tous les utilisateurs hors de l’environnement problématique et vers une base secondaire chaude. Un basculement entraîne la prise en charge des métadonnées et du stockage de calcul en dehors du nouveau centre de données. Comme le stockage d’objets blob s’exécute toujours entièrement actif/actif, aucune modification n’est nécessaire pour un basculement. Le niveau de calcul préfère le conteneur d’objets blob le plus proche, mais utilise les emplacements de stockage d’objets blob locaux et distants à tout moment pour garantir la disponibilité.
SharePoint utilise le service Azure Front Door pour fournir un routage interne au réseau Microsoft. Cette configuration permet la redirection de basculement indépendamment du DNS et réduit l’effet de la mise en cache de l’ordinateur local. La plupart des opérations de basculement sont transparentes pour les utilisateurs finaux. En cas de basculement, les clients n’ont pas besoin d’apporter de modifications pour conserver l’accès au service.
Gestion des versions et restauration des fichiers
Pour les bibliothèques de documents nouvellement créées, SharePoint utilise par défaut 500 versions sur chaque fichier et peut être configuré pour conserver d’autres versions si vous le souhaitez. L’interface utilisateur n’autorise pas la définition d’une valeur inférieure à 100 versions, mais il est possible de définir le système pour stocker moins de versions à l’aide d’API publiques. Pour la fiabilité, toute valeur inférieure à 100 n’est pas recommandée et peut entraîner une perte de données accidentelle par l’utilisateur.
Pour plus d’informations sur le contrôle de version, voir Contrôle de version dans SharePoint.
La restauration de fichiers permet de revenir en arrière sur n’importe quelle bibliothèque de documents dans SharePoint à n’importe quelle seconde au cours des 30 derniers jours. Ce processus peut être utilisé pour récupérer des rançongiciels, des suppressions massives, des altérations ou tout autre événement. Cette fonctionnalité utilise des versions de fichiers afin de réduire les versions par défaut peut réduire l’efficacité de cette restauration.
La fonctionnalité Restauration de fichiers est documentée pour OneDrive et SharePoint.
Suppression, sauvegarde et restauration à un point dans le temps
Le contenu utilisateur supprimé de SharePoint passe par le flux de suppression suivant.
Les éléments supprimés sont conservés dans les corbeilles pendant une certaine période. Pour SharePoint, la durée de rétention est de 93 jours. Elle commence lorsque vous supprimez l’élément de son emplacement d’origine. Lorsque vous supprimez l’élément de la corbeille du site, il est placé dans la corbeille de la collection de sites. Il y reste pendant le reste des 93 jours, puis est définitivement supprimé. Pour plus d’informations sur l’utilisation de la Corbeille, consultez les liens suivants :
- Restaurer des éléments dans la Corbeille
- Restaurez les éléments supprimés de la Corbeille de la collection de sites.
Ce processus est le flux de suppression par défaut et ne prend pas en compte les stratégies de rétention ou les étiquettes. Pour plus d’informations, voir En savoir plus sur la rétention pour SharePoint et OneDrive.
Une fois le pipeline de recyclage de 93 jours terminé, la suppression a lieu indépendamment pour les métadonnées et pour le stockage Blob. Les métadonnées sont immédiatement supprimées de la base de données, ce qui rend le contenu illisible, sauf si les métadonnées sont restaurées à partir de la sauvegarde. SharePoint conserve 14 jours de sauvegardes de métadonnées. Ces sauvegardes sont effectuées localement en quasi-temps réel, puis envoyées au stockage dans des conteneurs de stockage Azure redondants sur, selon la documentation au moment de cette publication, une planification de 5 à 10 minutes.
En outre, les clients ont également la possibilité d’utiliser sauvegarde Microsoft 365 pour la récupération de données. Sauvegarde Microsoft 365 offre un temps de protection plus long et fournit une récupération unique et rapide à partir de scénarios courants de continuité d’activité et de récupération d’urgence (BCDR) tels que le rançongiciel ou le remplacement/suppression de contenu d’employé accidentel/malveillant. Des protections de scénario BCDR supplémentaires sont également intégrées directement au service, offrant un niveau amélioré de protection des données.
Lorsque le contenu du Stockage Blob est supprimé, SharePoint utilise la fonctionnalité de suppression réversible pour stockage Blob Azure afin de vous protéger contre les suppressions accidentelles ou malveillantes. Avec cette fonctionnalité, il y a un total de 14 jours pour restaurer le contenu avant sa suppression définitive. En outre, étant donné que les objets blob sont immuables, Microsoft peut toujours restaurer l’état d’un fichier pendant une période de 14 jours.
Remarque
Bien que les applications Microsoft envoient du contenu à la corbeille pour le processus standard, SharePoint fournit des API qui permettent d’ignorer la corbeille et de forcer une suppression immédiate. Passez en revue vos applications pour vous assurer que cela n’est fait que lorsque cela est nécessaire pour des raisons de conformité.
Vérifications de l’intégrité
SharePoint utilise différentes méthodes pour garantir l’intégrité des objets blob et des métadonnées à toutes les étapes du cycle de vie des données :
- Hachage de fichier stocké dans les métadonnées : le hachage du fichier entier est stocké avec les métadonnées de fichier pour garantir que l’intégrité des données au niveau du document est conservée pendant toutes les opérations
- Hachage d’objet blob stocké dans les métadonnées : chaque élément d’objet blob stocke un hachage du contenu chiffré pour vous protéger contre toute altération dans le stockage Azure sous-jacent.
- Travail d’intégrité des données : tous les 14 jours, l’intégrité de chaque site est analysée en répertoriant les éléments de la base de données et en les faisant correspondre aux objets blob répertoriés dans le stockage Azure. Le travail signale les références d’objets blob manquants et peut récupérer ces objets blob via la fonctionnalité de suppression réversible du stockage Azure si nécessaire.