Gérer les bibliothèques Apache Spark dans Microsoft Fabric
Une bibliothèque est une collection de codes pré-écrits que les développeurs peuvent importer pour fournir une fonctionnalité. L'utilisation de bibliothèques permet de gagner du temps et de réduire les efforts en évitant d'écrire du code à partir de zéro pour effectuer des tâches courantes. En revanche, il convient d'importer la bibliothèque et d'utiliser ses fonctions et ses classes pour atteindre la fonctionnalité souhaitée. Microsoft Fabric fournit plusieurs mécanismes pour vous aider à gérer et à utiliser les bibliothèques.
- Bibliothèques intégrées : chaque runtime Fabric Spark fournit un ensemble complet de bibliothèques préinstallées populaires. Vous trouverez la liste complète des bibliothèques prédéfinies dans Fabric Spark Runtime.
- Bibliothèques publiques : les bibliothèques publiques proviennent de dépôts tels que PyPI et Conda, actuellement pris en charge.
- Bibliothèques personnalisées : les bibliothèques personnalisées font référence au code que vous ou votre organisation créez. Fabric les prend en charge dans les formats .whl, .jar et .tar.gz. Fabric prend en charge .tar.gz uniquement pour le langage R. Pour les bibliothèques personnalisées Python, utilisez le format .whl.
Récapitulatif des bonnes pratiques de gestion des bibliothèques
Les scénarios suivants décrivent les meilleures pratiques lors de l’utilisation de bibliothèques dans Microsoft Fabric.
Scénario 1 : l'administrateur définit les bibliothèques par défaut pour l'espace de travail
Pour définir les bibliothèques par défaut, vous devez être l'administrateur de l'espace de travail. En tant qu'administrateur, vous pouvez effectuer les tâches suivantes :
- Créer un environnement
- Installer les bibliothèques requises dans l'environnement
- Définir cet environnement comme espace de travail par défaut
Lorsque vos notebooks et définitions de tâches Spark sont attachés aux paramètres Workspace, ils démarrent des sessions avec les bibliothèques installées dans l'environnement par défaut de l'espace de travail.
Scénario 2 : conserver des spécifications de bibliothèque pour un ou plusieurs articles de code
Si vous avez des bibliothèques communes pour différents éléments de code et que vous n’avez pas besoin d’une mise à jour régulière, installer les bibliothèques dans un environnement et les attacher aux éléments de code est un bon choix.
Quelques minutes sont requises pour que les bibliothèques installées dans les environnements deviennent opérationnelles au moment de la publication. Normalement, ce processus prend de 5 à 15 minutes, en fonction de la complexité des bibliothèques. Pendant ce processus, le système permet de résoudre les conflits potentiels et de télécharger les dépendances requises.
L’un des avantages de cette approche est que les bibliothèques correctement installées sont garanties d’être disponibles lorsque la session Spark est démarrée avec l’environnement attaché. Il réduit l'effort nécessaire pour maintenir des bibliothèques communes pour vos projets.
Il est vivement recommandé pour les scénarios de pipeline en raison de sa stabilité.
Scénario 3 : installation incluse dans une exécution interactive
Si vous utilisez les notebooks pour écrire du code de manière interactive, l’utilisation de l’installation inline pour ajouter de nouvelles bibliothèques PyPI/conda ou valider vos bibliothèques personnalisées pour une utilisation unique est la meilleure pratique. Les commandes incluses de Fabric vous permettent de faire fonctionner la bibliothèque dans la session Spark du Notebook en cours. Cette solution permet une installation rapide, mais la bibliothèque installée ne persiste pas entre les différentes sessions.
Étant donné %pip install génère de temps en temps des arborescences de dépendances différentes, pouvant conduire à des conflits de bibliothèques, les commandes en ligne sont désactivées par défaut dans l’exécution des pipelines et il n’est PAS recommandé de les utiliser dans vos pipelines.
Récapitulatif des types de bibliothèque pris en charge
| Type de la bibliothèque | Gestion des bibliothèques d’environnement | Installation incluse |
|---|---|---|
| Python Public (PyPI & Conda) | Prise en charge | Prise en charge |
| Python personnalisé (.whl) | Prise en charge | Prise en charge |
| R Public (CRAN) | Non pris en charge | Prise en charge |
| R personnalisé (.tar.gz) | Pris en charge en tant que bibliothèque personnalisée | Prise en charge |
| Jar | Pris en charge en tant que bibliothèque personnalisée | Prise en charge |
Installation incluse
Les commandes inline prennent en charge la gestion des bibliothèques dans chaque session de notebook.
Installation incluse dans Python
Le système redémarre l’interpréteur Python pour appliquer la modification des bibliothèques. Toutes les variables définies avant l'exécution de la cellule de commande sont perdues. Nous vous recommandons vivement de placer toutes les commandes d’ajout, de suppression ou de mise à jour des packages Python au début de votre notebook.
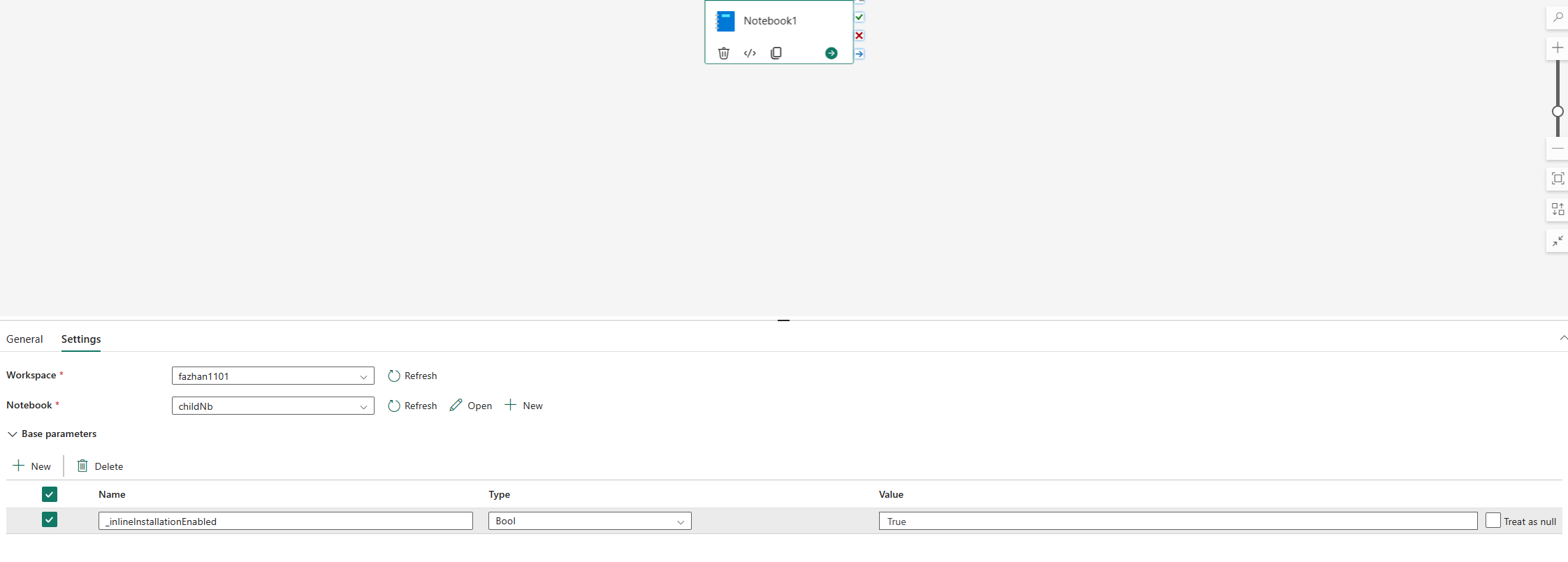
Les commandes en ligne pour la gestion des bibliothèques Python sont désactivées par défaut dans l'exécution du pipeline notebook. Si vous souhaitez activer %pip install pour le pipeline, ajoutez "_inlineInstallationEnabled" en tant que paramètre bool égal à True dans les paramètres de l'activité du notebook.
Remarque
Le %pip install peut parfois donner des résultats incohérents. Il est recommandé d'installer la bibliothèque dans un environnement et de l'utiliser dans le pipeline.
Dans les exécutions de référence des notebooks, les commandes inline pour la gestion des bibliothèques Python ne sont pas prises en charge. Pour garantir l’exactitude de l’exécution, il est recommandé de supprimer ces commandes inline du notebook référencé.
Nous vous recommandons %pip à la place de !pip. !pip est une commande shell prédéfinie dans IPython, qui présente les limitations suivantes :
!pipn'installe de package que sur le nœud du gestionnaire, et non sur les nœuds de l'Exécuteur.- Les packages qui s'installent via
!pipn'affectent pas les conflits avec les packages prédéfinis. De même, les packages qui sont déjà importés dans un Notebook ne sont pas affectés.
Toutefois, %pip gère ces scénarios. Les bibliothèques installées via %pip sont disponibles à la fois sur les nœuds du gestionnaire et de l'Exécuteur. Elles sont toujours actives même si la bibliothèque est déjà importée.
Conseil
La commande %conda install prend généralement plus de temps que la commande %pip install pour installer de nouvelles bibliothèques Python. Elle vérifie l'ensemble des dépendances et résout les conflits.
Vous pouvez utiliser %conda install pour augmenter la fiabilité et la stabilité. Vous pouvez utiliser %pip install si vous êtes sûr que la bibliothèque que vous souhaitez installer est compatible avec les bibliothèques préinstallées dans l'environnement runtime.
Pour toutes les commandes incluses et disponibles dans Python et toutes les précisions nécessaires, consultez Commandes %pip et Commandes %conda.
Gérer les bibliothèques publiques Python via l'installation incluse
Dans cet exemple, nous verrons comment utiliser les commandes incluses pour gérer les bibliothèques. Supposons que vous souhaitiez utiliser altair, une bibliothèque de visualisation puissante pour Python, pour une exploration de données ponctuelle. Supposons que la bibliothèque n'est pas installée dans votre espace de travail. L'exemple suivant utilise les commandes conda pour illustrer les étapes.
Vous pouvez utiliser des commandes incluses pour activer altair sur votre session de Notebook sans affecter les autres sessions du Notebook ou d'autres articles.
Exécutez les commandes suivantes dans une cellule de code du Notebook. La première commande installe la bibliothèque altair. Installez également vega_datasets, qui contient un modèle sémantique que vous pouvez utiliser pour visualiser.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandLa production de la cellule indique le résultat de l'installation.
Importez le package et le modèle sémantique en exécutant le code suivant dans une autre cellule du Notebook.
import altair as alt from vega_datasets import dataVous pouvez à présent reproduire la bibliothèque altair à l'échelle de la session.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Gérer les bibliothèques personnalisées Python grâce à l'installation incluse
Vous pouvez charger vos bibliothèques personnalisées Python dans le dossier ressources de votre notebook ou de l’environnement attaché. Les dossiers de ressources sont le système de fichiers intégré fourni par chaque notebook et chaque environnement. Pour plus de détails, consultez les Ressources du notebook. Une fois le téléchargement effectué, vous pouvez glisser-déplacer la bibliothèque personnalisée dans une cellule de code, la commande inline requise pour l’installation de la bibliothèque est automatiquement générée. Vous pouvez également utiliser la commande suivante pour l’installation.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
Installation incluse R
Pour gérer les bibliothèques R, Fabric prend en charge les commandes install.packages(), remove.packages() et devtools::. Pour toutes les commandes incluses R disponibles et toutes les précisions nécessaires, consultez la commande install.packages et la commande remove.package.
Gérer les bibliothèques publiques R grâce à l'installation incluse
Suivez cet exemple pour découvrir les étapes de l'installation d'une bibliothèque publique R.
Pour installer une bibliothèque de flux R :
Changez la langue de travail en SparkR (R) dans le ruban du Notebook.
Installez la bibliothèque caesar en exécutant la commande suivante dans une cellule de Notebook.
install.packages("caesar")Vous pouvez maintenant vous familiariser avec la bibliothèque caesar limitée à la session à l’aide d’un travail Spark.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Gérer les bibliothèques Jar via l'installation incluse
Les fichiers .jar sont pris en charge au niveau des sessions de notebook avec la commande suivante.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
La cellule de code utilise le stockage de Lakehouse comme exemple. Dans l'explorateur de Notebook, vous pouvez copier le chemin d'accès complet du fichier ABFS et le remplacer dans le code.
