Utiliser l’API de données du secteur comme moteur d’extraction, de transformation et de chargement (ETL) (préversion)
Importante
Les API sous la version /beta dans Microsoft Graph sont susceptibles d’être modifiées. L’utilisation de ces API dans des applications de production n’est pas prise en charge. Pour déterminer si une API est disponible dans v1.0, utilisez le sélecteur Version .
L’API de données sectorielles est une plateforme ETL (Extract-Transform-Load) axée sur le secteur de l’éducation qui combine les données de plusieurs sources dans un seul magasin de données Azure Data Lake, normalise les données et les exporte dans des flux sortants. L’API fournit des ressources que vous pouvez utiliser pour obtenir des statistiques après le traitement des données et faciliter la surveillance et la résolution des problèmes.
L’API de données sectorielles est définie dans le sous-espace microsoft.graph.industryDatade nom OData .
API de données sectorielles et éducation
L’API de données du secteur alimente la plateforme SDS (Microsoft School Data Sync ) pour automatiser le processus d’importation de données et de synchronisation des organisations, des associations d’utilisateurs et d’utilisateurs et des groupes avec l’ID Microsoft Entra et Microsoft 365 à partir de systèmes d’information sur les étudiants (SIS) et de systèmes de gestion des étudiants (SMS). Après la normalisation des données, l’API utilise les données via plusieurs flux d’approvisionnement sortants pour gérer les utilisateurs, les groupes de classes, les unités administratives et les groupes de sécurité.
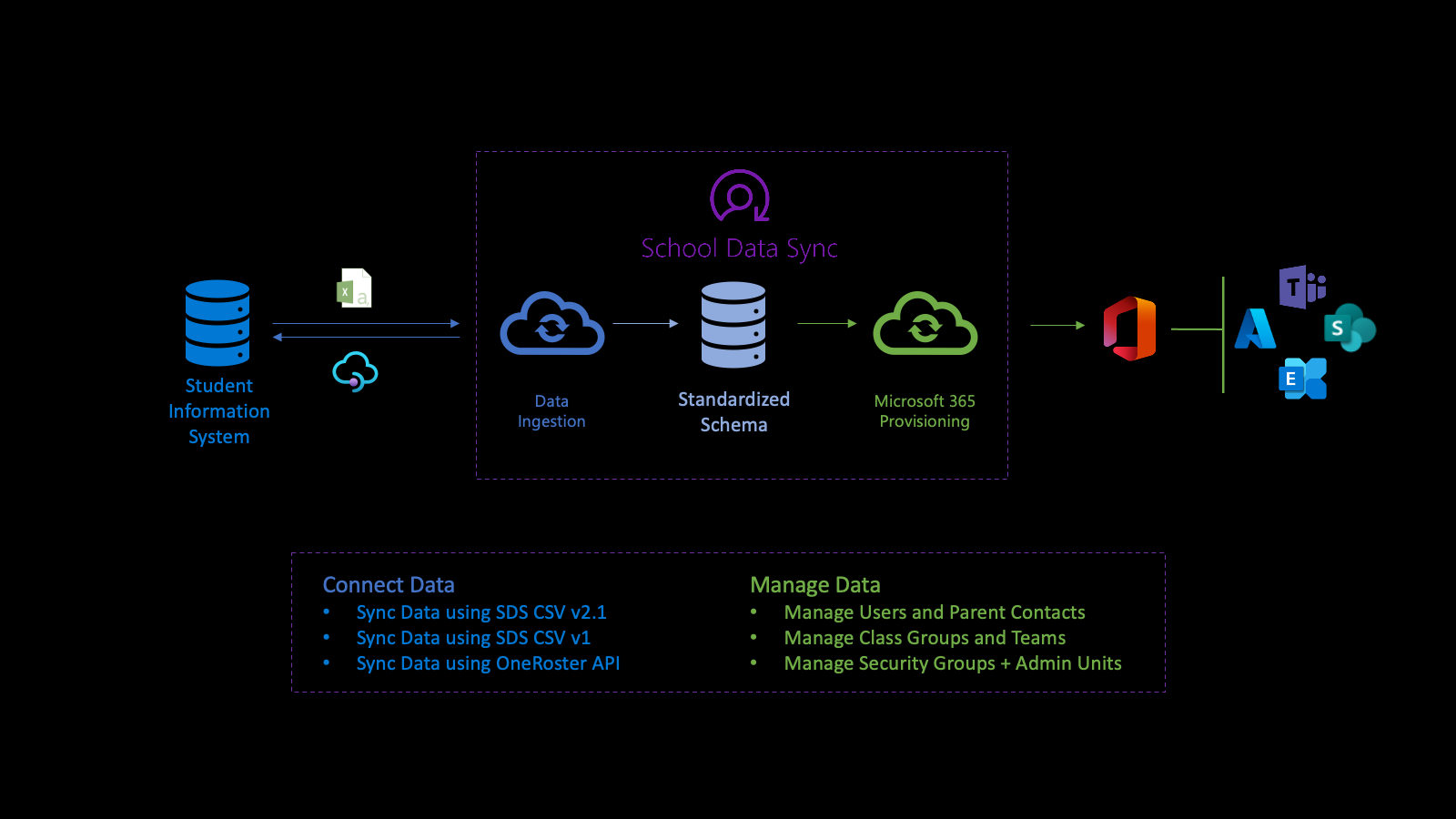
Tout d’abord, vous vous connectez aux données de votre établissement. Pour définir un flux entrant, créez une sourceSystemDefinition, dataConnector et yearTimePeriodDefinition. Par défaut, le flux entrant s’active deux fois (2 fois) par jour (exécution).
Lorsque l’exécution démarre, elle se connecte à la sourceSystemDefinition et à dataConnector du flux entrant et effectue la validation de base. La validation de base garantit que la connexion est correcte, lorsque l’API OneRoster est la source, ou que les noms de fichiers et les en-têtes sont corrects, lorsqu’un CSV est la source.
Ensuite, le système transforme les données à importer en vue d’une validation avancée. Dans le cadre de la transformation des données, les données sont associées en fonction de la valeur yearTimePeriodDefinition configurée.
Le système stocke la dernière copie de l’ID Microsoft Entra du locataire dans Azure Data Lake. La copie de Microsoft Entra permet de faire correspondre l’utilisateur entre la sourceSystemDefinition et l’objet utilisateur Microsoft Entra. À ce stade, le lien de correspondance est écrit uniquement dans Azure Data Lake.
Ensuite, le flux entrant effectue une validation avancée pour déterminer l’intégrité des données. La validation se concentre sur l’identification des erreurs et des avertissements pour s’assurer que les bonnes données arrivent et que les données incorrectes restent en attente. Les erreurs indiquent qu’un enregistrement n’a pas réussi la validation et a été supprimé d’un traitement ultérieur. Les avertissements indiquent que la valeur d’un champ facultatif d’un enregistrement n’a pas réussi. La valeur est supprimée de l’enregistrement, mais l’enregistrement est inclus pour un traitement ultérieur.
Les erreurs et les avertissements vous aident à mieux comprendre l’intégrité des données.
Pour les données qui ont passé la validation, le processus utilise la valeur yearTimePeriodDefinition configurée pour déterminer son association pour le stockage longitudinal, comme suit :
- Comme les données sont stockées la représentation interne dans le lac de données Azure du locataire, elles identifient quand elles ont été vues pour la première fois par les données du secteur.
- Pour les données liées à une organisation d’utilisateur, à une association de rôles et à une association de groupe, il identifie également les données comme actives dans la session en fonction de l’argument yearTimePeriodDefinition.
- Dans les exécutions ultérieures, pour les mêmes flux entrants, sourceSystemDefinition et yearTimePeriodDefinition, les données sectorielles indiquent si l’enregistrement est toujours visible.
- En fonction de la présence ou de l’absence d’enregistrement, l’enregistrement est maintenu actif ou marqué comme n’étant plus actif dans la session pour la configuration de yearTimePeriodDefinition. Ce processus détermine la nature historique et longitudinale des données entre les jours, les mois et les années.
À la fin de chaque exécution, industryDataRunStatistics est disponible pour déterminer l’intégrité des données.
Les erreurs et avertissements liés à industryDataRunStatistics sont générés pour aider à fournir une compréhension initiale de l’intégrité des données. Lorsque vous examinez l’intégrité des données, les données sectorielles permettent de télécharger un fichier journal qui contient des informations basées sur les erreurs et les avertissements détectés pour commencer le processus d’investigation des données afin de corriger les données dans le système source.
Après avoir examiné et corrigé les erreurs ou avertissements liés aux données, lorsque vous êtes à l’aise avec l’état actuel de l’intégrité des données, vous pouvez activer les scénarios avec les données. Lorsque vous autorisez un scénario à utiliser ces données, le scénario crée un flux d’approvisionnement sortant.
La gestion des données par le biais de flux d’approvisionnement sortants simplifie la gestion des utilisateurs et des classes. Seuls les utilisateurs actifs et correspondants sont inclus dans les données utilisées pour écrire le lien vers l’objet utilisateur Microsoft Entra. Ce lien facilite l’intégration entre les SIS/SMS et leurs sections pour les groupes et les salles de classe Microsoft Teams.
Pour plus d’informations, consultez les sections School Data Sync, Prérequis SDS et Concepts de base de school Data Sync de la vue d’ensemble de School Data Sync.
Inscription, autorisations et autorisation
Vous pouvez intégrer des API de données industrielles à des applications tierces. Pour plus d’informations sur la procédure à suivre, consultez les articles suivants :
- Principes de base de l’authentification et de l’autorisation.
- Inscrire une application auprès de la plateforme d’identités Microsoft.
- Obtenir l’accès au nom d’un utilisateur.
- Informations de référence sur les autorisations Microsoft Graph.
- Résoudre les erreurs d’autorisation Microsoft Graph.
Cas d’utilisation courants
| Cas d’utilisation | Ressource REST | Voir aussi |
|---|---|---|
| Créer une activité pour importer un jeu de données délimité | inboundFileFlow | méthodes inboundFileFlow |
| Définir une source de données entrantes | sourceSystemDefinition | méthodes sourceSystemDefinition |
| Créer un connecteur pour publier des données dans azure Data Lake (si CSV) | azureDataLakeConnector | Méthodes azureDataLakeConnector |
Domaine de données
La propriété dataDomain définit le type de données importées et détermine le format de modèle de données commun dans lequel elles doivent être stockées. Actuellement, le seul dataDomain pris en charge est educationRostering.
Définitions de référence
Une valeur referenceDefinition représente une valeur énumérée. Chaque domaine d’activité pris en charge reçoit une collection distincte de définitions. Les ressources referenceDefinition sont largement utilisées dans tout le système, à la fois pour la configuration et la transformation, où les valeurs potentielles sont spécifiques à un secteur donné. Chaque referenceDefinition utilise un identificateur composite de {referenceType}-{code} pour fournir une expérience cohérente entre les locataires clients.
Valeurs de référence
Les types basés sur referenceValue fournissent une expérience de développement simplifiée pour la liaison des ressources referenceDefinition . Chaque type referenceValue est lié à un type référence unique, ce qui permet aux développeurs de fournir uniquement la partie de code de la définition de référencement sous forme de chaîne simple et d’éliminer toute confusion potentielle quant au type de referenceDefinition auquel une propriété donnée est attendue.
Exemple
La propriété userMatchingSettings.sourceIdentifier accepte un type identifierTypeReferenceValue qui est lié au RefIdentifierTypereferenceType.
"sourceIdentifier": {
"code": "username"
},
Une valeur referenceDefinition peut également être liée directement à l’aide de la propriété value .
"sourceIdentifier": {
"value@odata.bind": "external/industryData/referenceDefinitions/RefIdentifierType-username"
},
Groupes de rôles
La transformation des données est souvent mise en forme par le rôle de chaque utilisateur individuel au sein d’une organisation. Ces rôles sont définis en tant que définitions de référence. Étant donné le nombre de rôles potentiels, la liaison de chaque rôle individuel entraînerait une expérience utilisateur fastidieuse.
Les groupes de rôles sont une collection de RefRole codes.
{
"@odata.type": "#microsoft.graph.industryDataRoleGroup",
"id": "37a9781b-db61-4a3c-a3c1-8cba92c9998e",
"displayName": "Staff",
"roles": [
{ "code": "adjunct" },
{ "code": "administrator" },
{ "code": "advisor" },
{ "code": "affiliate" },
{ "code": "aide" },
{ "code": "alumni" },
{ "code": "assistant" }
]
}
Connecteurs de données du secteur
Un industryDataConnector agit comme un pont entre une sourceSystemDefinition et un inboundFlow. Il est responsable de l’acquisition de données à partir d’une source externe et de la fourniture des données aux flux de données entrants.
Charger et valider des données CSV
Pour plus d’informations sur les données CSV, consultez :
Voici les conditions requises pour le fichier CSV :
- Les noms de fichiers et les en-têtes de colonne respectent la casse.
- Les fichiers CSV doivent être au format UTF-8.
- Les données entrantes ne doivent pas avoir de sauts de ligne.
Pour consulter et télécharger l’exemple d’ensemble de fichiers CSV SDS V2.1, consultez le référentiel GitHub SDS.
Importante
IndustryDataConnector n’accepte pas les modifications delta, donc chaque session de chargement doit contenir le jeu de données complet. Le fait de fournir uniquement des données partielles ou delta entraîne la transition des enregistrements manquants vers un état inactif.
Demander une session de chargement
AzureDataLakeConnector utilise des fichiers CSV chargés dans un conteneur sécurisé. Ce conteneur se trouve dans le contexte d’un fichier FileUploadSession unique et est automatiquement détruit après la validation des données ou l’expiration de la session de chargement de fichiers.
La session de chargement de fichiers actuelle est récupérée à partir d’un azureDataLakeConnector via la getUploadSession qui retourne l’URL SAS pour charger les fichiers CSV.
Valider les fichiers chargés
Les fichiers de données chargés doivent être validés avant qu’un flux entrant puisse traiter les données. Le processus de validation finalise le fichier actuelUploadSession et vérifie que tous les fichiers requis sont présents et correctement mis en forme. La validation est lancée en appelant l’action de validation industryDataConnector : de la ressource azureDataLakeConnector .
L’action de validation crée un fichier de longue duréeValidateOperation. L’URI de fileValidateOperation est fourni dans l’en-tête Location de la réponse. Vous pouvez utiliser cet URI pour suivre l’état de l’opération de longue durée, ainsi que les erreurs ou avertissements créés lors de la validation.
Étapes suivantes
Utilisez les API de données du secteur Microsoft Graph en tant que moteur d’extraction, de transformation et de chargement (ETL). Pour en savoir plus :
- Explorez les ressources et les méthodes les plus utiles à votre scénario.
- Essayez l’API dans l’Afficheur Graph.
Contenu connexe
Vue d’ensemble de l’API de données du secteur dans Microsoft Graph