Architecture de la solution décisionnelle dans le centre d’excellence
Cet article s’adresse aux professionnels de l’informatique et aux responsables informatiques. Il aborde l’architecture de la solution décisionnelle dans le centre d’excellence et les différentes technologies utilisées, notamment Azure, Power BI et Excel. Ensemble, ces technologies permettent de mettre en place une plateforme décisionnelle scalable et pilotée par les données dans le cloud.
La conception d’une plateforme décisionnelle fiable s’apparente à la construction d’un pont, celui-ci reliant des données source transformées et enrichies à des consommateurs de données. La conception d’une structure de cette complexité exige des compétences d’ingénieur, mais l’aspect créatif de cette architecture informatique peut se révéler des plus gratifiant. Dans une grande organisation, une architecture de solution décisionnelle peut être constituée des éléments suivants :
- Sources de données
- Ingestion de données
- Préparation des données/Big Data
- Entrepôt de données
- Modèles sémantiques BI
- Rapports
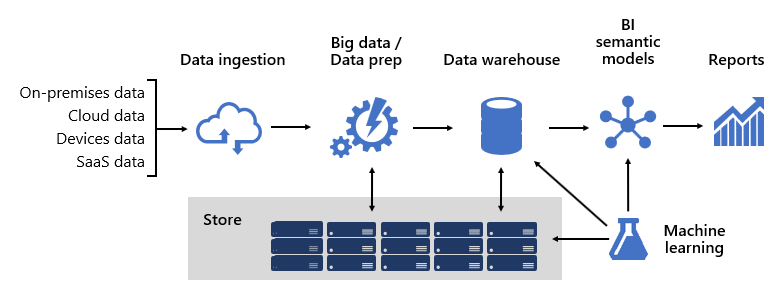
La plateforme doit prendre en charge des demandes spécifiques. Plus précisément, elle doit pouvoir être mise à l’échelle et exécutée pour répondre aux attentes des services métier et des consommateurs de données. Elle doit également être entièrement sécurisée. Enfin, elle doit être suffisamment résiliente pour s’adapter aux changements puisqu’il est certain que nouvelles données et de nouveaux domaines seront mis en ligne à l’avenir.
Frameworks
Chez Microsoft, nous avons adopté dès le départ une approche systémique en investissant dans le développement de frameworks. La création de frameworks pour les processus techniques et métier favorise la réutilisation des conceptions et de la logique tout en garantissant des résultats cohérents. Du fait qu’ils exploitent de nombreuses technologies, ils offrent également une grande flexibilité sur le plan architectural. Enfin, ils contribuent à rationaliser et à réduire les frais d’ingénierie grâce à la mise en place de processus reproductibles.
Nous savons que des frameworks bien conçus augmentent la visibilité de la traçabilité des données, de l’analyse d’impact, de la maintenance de la logique métier, de la gestion de la taxonomie et de la rationalisation de la gouvernance. Nous avons également accéléré le développement et amélioré la réactivité et l’efficacité de la collaboration entre grandes équipes.
Nous allons vous présenter plusieurs de nos frameworks dans cet article.
Modèles de données
Les modèles de données vous permettent de contrôler la structure et l’accessibilité des données. Pour les services métier et les consommateurs de données, les modèles de données servent d’interface avec la plateforme décisionnelle.
Une plateforme décisionnelle peut fournir trois types différents de modèles :
- Modèles d’entreprise
- Modèles sémantiques BI
- Modèles Machine Learning (ML)
Modèles d’entreprise
Les modèles d’entreprise sont générés et gérés par les architectes informatiques. Ils sont parfois appelés modèles dimensionnels ou datamarts. En général, les données sont stockées dans un format relationnel sous la forme de tables de dimension et de faits. Ces tableaux stockent des données nettoyées et enrichies qui sont consolidées à partir de nombreux systèmes. Ils représentent une source faisant autorité pour la création de rapports et l’analytique.
Les modèles d’entreprise offrent une source de données cohérente et unique pour la création de rapports et le décisionnel. Ils sont générés une fois pour toutes et partagés en tant que norme d’entreprise. Les stratégies de gouvernance garantissent la sécurité des données. De ce fait, l’accès aux jeux de données sensibles, notamment les informations sur les clients ou les finances, est limité selon les besoins. Les modèles d’entreprise adoptent des conventions de nommage garantissant la cohérence, renforçant ainsi la crédibilité des données et la qualité.
Dans une plateforme décisionnelle cloud, les modèles d’entreprise peuvent être déployés sur un pool SQL Synapse dans Azure Synapse. Le pool SQL Synapse devient alors la source unique de vérité sur laquelle l’organisation peut compter pour obtenir des insights rapides et fiables.
Modèles sémantiques BI
Les modèles sémantiques BI sont une couche sémantique résidant sur les modèles métier. Ils sont créés et gérés par les développeurs en décisionnel et les utilisateurs métier. Les développeurs en décisionnel créent des modèles sémantiques BI de base qui utilisent les données des modèles métier. Les utilisateurs professionnels peuvent créer des modèles indépendants à plus petite échelle ou étendre les modèles sémantiques BI de base avec des sources externes ou propres à un service. Les modèles sémantiques BI portent généralement sur un seul domaine et sont souvent largement partagés.
Les fonctionnalités métier ne sont pas activées uniquement par les données, mais par les modèles sémantiques BI qui décrivent les concepts, les relations, les règles et les standards. De cette façon, ils représentent des structures intuitives et faciles à comprendre qui définissent les relations entre les données et encapsulent les règles métier sous forme de calculs. Ils peuvent également appliquer des autorisations précises pour l’accès aux données, garantissant ainsi que les bonnes personnes ont accès aux bonnes données. Plus important encore, ils améliorent les performances des requêtes en fournissant une analytique interactive extrêmement réactive, même sur plusieurs téraoctets de données. Au même titre que les modèles métier, les modèles sémantiques BI adoptent des conventions de nommage qui garantissent la cohérence.
Dans une plateforme cloud BI, les développeurs décisionnels peuvent déployer des modèles sémantiques BI sur Azure Analysis Services, capacités Power BI Premium des capacités Microsoft Fabric.
Important
Cet article fait parfois référence à Power BI Premium ou à ses abonnements de capacité (références SKU P). Sachez que Microsoft regroupe actuellement des options d’achat et met hors service les références SKU Power BI Premium par capacité. Les clients nouveaux et existants doivent plutôt envisager l’achat d’abonnements de capacité Fabric (références SKU F).
Pour plus d’informations, consultez Importante mise à jour à venir des licences Power BI Premium et FAQ sur Power BI Premium.
Nous vous recommandons de déployer sur Power BI si vous vous en servez comme couche de création de rapports et d’analytique. Ces produits prennent en charge différents modes de stockage, ce qui permet aux tables de modèle de données de mettre en cache leurs données ou d’utiliser DirectQuery, une technologie qui transmet les requêtes à la source de données sous-jacente. DirectQuery est le mode de stockage idéal quand les tables de modèle contiennent des volumes de données importants ou quand vous devez fournir des résultats en quasi-temps réel. Vous pouvez par ailleurs combiner ces deux modes de stockage : les modèles composites combinent des tables qui utilisent différents modes de stockage en un seul modèle.
Pour les modèles faisant l’objet d’un grand nombre de requêtes, vous pouvez utiliser Azure Load Balancer pour répartir uniformément la charge des requêtes entre les réplicas de modèle. Il vous permet également de mettre à l’échelle vos applications et de créer des modèles sémantiques BI hautement disponibles.
Modèles Machine Learning
Les modèles Machine Learning (ML) sont générés et gérés par des scientifiques des données. Ils sont principalement développés à partir de sources brutes dans le lac de données.
Les modèles ML entraînés peuvent révéler des modèles dans vos données. Dans de nombreuses circonstances, ces modèles peuvent être utilisés pour faire des prédictions qui peuvent servir à enrichir les données. Par exemple, vous pouvez utiliser le comportement d’achat pour prédire l’attrition clients ou segmenter les clients. Les résultats des prédictions peuvent être ajoutés aux modèles d’entreprise pour permettre l’analyse par segment de clientèle.
Dans une plateforme décisionnelle cloud, vous pouvez utiliser Azure Machine Learning pour entraîner, déployer, automatiser, gérer et suivre les modèles ML.
Entrepôt de données
L’entrepôt de données, qui héberge vos modèles d’entreprise, est au cœur d’une plateforme décisionnelle. Cette source de données sanctionnées, qui fait office de système d’enregistrement et de hub, est au service des modèles d’entreprise pour la création de rapports, le décisionnel et la science des données.
De nombreux services métier, notamment les applications cœur de métier, utilisent l’entrepôt de données comme une source gérée et faisant autorité des connaissances de l’entreprise.
Chez Microsoft, notre entrepôt de données est hébergé sur Azure Data Lake Storage Gen2 (ADLS Gen2) et Azure Synapse Analytics.
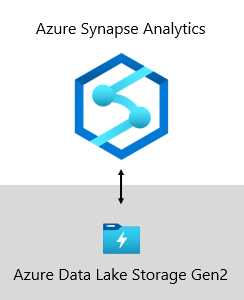
- ADLS Gen2 fait du stockage Azure la base pour créer des dépôts lacs de données d’entreprise sur Azure. Il est conçu pour traiter plusieurs pétaoctets d’informations tout en maintenant des centaines de gigabits de débit. Il offre également une capacité de stockage et des transactions à bas coût. Il prend aussi en charge l’accès compatible Hadoop, ce qui vous permet de gérer les données et d’y accéder comme vous le feriez avec un système de fichiers HDFS (Hadoop Distributed File System). En fait, Azure HDInsight, Azure Databricks et Azure Synapse Analytics peuvent tous accéder aux données stockées dans ADLS Gen2. Ainsi, dans une plateforme décisionnelle, il est recommandé de stocker les données sources brutes, les données semi-traitées ou de préproduction ainsi que les données prêtes pour la production. Nous l’utilisons pour stocker toutes nos données métier.
- Azure Synapse Analytics est un service d’analytique qui regroupe l’entreposage des données d’entreprise et l’analytique de Big Data. Il vous donne la possibilité d’interroger les données avec votre propre vocabulaire, en utilisant des ressources serverless à la demande ou des ressources provisionnées, le tout à grande échelle. Synapse SQL, un composant d’Azure Synapse Analytics, prend en charge l’analytique basée entièrement sur T-SQL. Il est donc idéal pour héberger des modèles d’entreprise comprenant vos tables de dimension et de faits. Vous pouvez charger efficacement des tables à partir d’ADLS Gen2 à l’aide de simples requêtes Polybase T-SQL. Vous disposez alors de la puissance de MPP pour exécuter une analytique hautes performances.
Framework pour le moteur de règles métier
Nous avons développé un framework pour le moteur de règles métier (BRE, Business Rules Engine) pour cataloguer toute logique métier pouvant être implémentée dans la couche de l’entrepôt de données. Un BRE peut signifier plusieurs choses, mais dans le contexte d’un entrepôt de données, il sert à créer des colonnes calculées dans des tables relationnelles. Ces colonnes calculées sont généralement représentées sous forme de calculs mathématiques ou d’expressions avec des instructions conditionnelles.
L’objectif est de séparer la logique métier du code décisionnel de base. Traditionnellement, les règles métier sont codées en dur dans des procédures stockées SQL. Leur maintenance nécessite donc des efforts importants lorsque les besoins de l’entreprise évoluent. Dans un BRE, les règles sont définies une fois pour toutes et peuvent être appliquées à différentes entités d’entrepôt de données. Si la logique de calcul doit être modifiée, vous devez uniquement la mettre à jour dans un seul endroit (et non dans plusieurs procédures stockées). Il en découle un autre avantage : un framework BRE améliore la transparence et la visibilité de la logique métier implémentée qui peut être exposée au moyen d’un ensemble de rapports formant une documentation à mise à jour automatique.
Sources de données
Un entrepôt de données peut consolider des données de pratiquement n’importe quelle source de données. Il est principalement basé sur des sources de données métier, en général des bases de données relationnelles qui stockent des données spécifiques à un domaine pour les ventes, le marketing, la finance, etc. Ces bases de données peuvent être hébergées dans le cloud ou résider au niveau local. D’autres sources de données peuvent être basées sur des fichiers, en particulier les journaux web ou les données IOT provenant d’appareils. De plus, les données peuvent provenir de fournisseurs SaaS (Software-as-a-service).
Chez Microsoft, certains de nos systèmes internes envoient des données opérationnelles directement à ADLS Gen2 sous la forme de fichiers bruts. En plus de notre lac de données, d’autres systèmes sources comprennent des applications cœur de métier relationnelles, des classeurs Excel, d’autres sources basées sur des fichiers ainsi que des référentiels de données personnalisés et MDM (Gestion des données de référence). Les référentiels MDM nous permettent de gérer nos données de référence pour garantir des versions de données faisant autorité, normalisées et validées.
Ingestion de données
De façon périodique et selon les rythmes de l’entreprise, des données sont ingérées à partir de systèmes sources et chargées dans l’entrepôt de données. Cela peut se produire une fois par jour ou à des intervalles plus fréquents. L’ingestion des données implique l’extraction, la transformation et le chargement de données. Mais vous pouvez aussi effectuer l’extraction, le chargement, puis la transformation des données. La différence tient à la place de la transformation dans la procédure. Des transformations sont appliquées pour nettoyer, harmoniser, intégrer et normaliser les données. Pour plus d’informations, consultez Extraire, transformer et charger (ETL).
L’objectif final est de charger les bonnes données dans votre modèle d’entreprise aussi rapidement et efficacement que possible.
Chez Microsoft, nous utilisons Azure Data Factory (ADF). Ce service nous permet de planifier et d’orchestrer les validations, transformations et chargements en masse des données à partir de systèmes sources externes vers notre lac de données. Il est géré par des frameworks personnalisés pour traiter les données en parallèle et à grande échelle. En outre, une journalisation complète est effectuée pour non seulement prendre en charge la résolution des problèmes et la supervision des performances, mais aussi pour déclencher des alertes quand des conditions spécifiques sont remplies.
Pendant ce temps, Azure Databricks, une plateforme analytique basée sur Apache Spark et optimisée pour la plateforme Azure Cloud Services, effectue des transformations spécifiquement pour la science des données. Azure Databricks génère et exécute également des modèles ML à l’aide de notebooks Python. Les scores de ces modèles ML sont chargés dans l’entrepôt de données pour intégrer des prédictions aux applications et aux rapports de l’entreprise. Dans la mesure où Azure Databricks accède directement aux fichiers du lac de données, il élimine ou réduit la nécessité de copier ou d’acquérir des données.
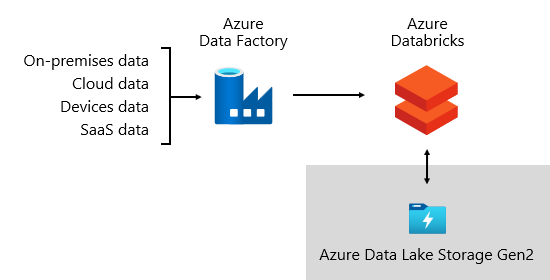
Framework d’ingestion
Nous avons développé un framework d’ingestion sous la forme d’un ensemble de tables et de procédures de configuration. Il prend en charge une approche pilotée par les données pour acquérir des volumes importants de données à grande vitesse et avec un minimum de code. En bref, ce framework simplifie le processus d’acquisition des données pour charger l’entrepôt de données.
Le framework dépend des tables de configuration qui stockent les informations relatives à la source et à la destination des données, notamment en ce qui concerne le type de source, le serveur, la base de données, le schéma et la table. Cette approche de conception signifie que nous n’avons pas besoin de développer des pipelines ADF ni des packages SQL Server Integration Services (SSIS) spécifiques. Au lieu de cela, les procédures sont écrites dans le langage de notre choix pour créer des pipelines ADF qui sont générés dynamiquement et exécutés au moment de l’exécution. L’acquisition de données devient donc un exercice de configuration facile à opérationnaliser. Par le passé, des ressources de développement étendues étaient nécessaires pour créer des packages ADF ou SSIS codés en dur.
Le framework d’ingestion a également été conçu pour simplifier le processus de traitement des changements liés au schéma source en amont. Quand des changements de schéma sont détectés, nous pouvons facilement mettre à jour les données de configuration, manuellement ou automatiquement, pour acquérir les nouveaux attributs ajoutés dans le système source.
Framework d’orchestration
Nous avons développé un framework d’orchestration pour opérationnaliser et orchestrer nos pipelines de données. Il repose sur une conception pilotée par les données qui dépend d’un ensemble de tables de configuration. Ces tables stockent des métadonnées qui décrivent les dépendances des pipelines et expliquent comment mapper les données sources aux structures de données cibles. Les investissements réalisés dans le développement de ce framework adaptatif ont depuis été amortis puisqu’il n’est plus nécessaire de coder en dur chaque mouvement de données.
Stockage de données
Un lac de données peut stocker, outre des volumes importants de données brutes en vue d’une utilisation ultérieure, les transformations des données de préproduction.
Chez Microsoft, nous utilisons ADLS Gen2 comme source unique de vérité. Il stocke les données brutes aux côtés des données de préproduction et des données prêtes pour la production. Il fournit une solution de lac de données économique et hautement scalable pour l’analytique des Big Data. Combinant la puissance d’un système de fichiers à hautes performances et à grande échelle, elle est optimisée pour les charges de travail d’analytique de données et réduit les délais nécessaires à l’obtention d’insights.
ADLS Gen2 offre le meilleur des deux mondes : d’une part, un stockage d’objets blob et, d’autre part, un espace de noms de système de fichiers hautes performances que nous configurons avec des autorisations d’accès précises.
Les données affinées sont ensuite stockées dans une base de données relationnelle qui constitue un magasin de données hautes performances et hautement scalable pour les modèles d’entreprise, le tout dans un souci de sécurité, de gouvernance et de facilité de gestion. Les datamarts spécifiques à un domaine sont stockés dans Azure Synapse Analytics et chargés par des requêtes T-SQL Polybase ou Azure Databricks.
Consommation des données
Au niveau de la couche de rapports, les services métier consomment des données d’entreprise provenant de l’entrepôt de données. Ils accèdent également aux données directement dans le lac de données pour les tâches d’analyse ad hoc ou de science des données.
Des autorisations précises sont appliquées à toutes les couches : dans le lac de données, les modèles métier et les modèles sémantiques BI. Les autorisations garantissent que les consommateurs de données ne peuvent voir que les données auxquelles ils ont le droit d’accéder.
Chez Microsoft, nous utilisons des rapports et des tableaux de bord Power BI et des rapports paginés Power BI. Certaines tâches de création de rapports et d’analyse ad hoc sont effectuées dans Excel, en particulier pour les rapports financiers.
Nous publions des dictionnaires de données qui fournissent des informations de référence sur nos modèles de données. Ils sont mis à la disposition de nos utilisateurs pour qu’ils puissent découvrir des informations sur notre plateforme décisionnelle. Les dictionnaires documentent les conceptions des modèles et décrivent les entités, les formats, la structure, la traçabilité des données, les relations et les calculs. Nous utilisons Azure Data Catalog pour rendre nos sources de données facilement détectables et compréhensibles.
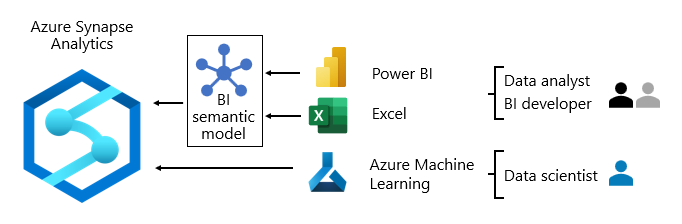
En général, les modèles de consommation des données varient en fonction du rôle :
- Les analystes de données se connectent directement aux modèles sémantiques BI de base. Quand ils disposent de tels modèles contenant toutes les données et la logique dont ils ont besoin, ils utilisent des connexions actives pour créer des rapports et des tableaux de bord Power BI. Pour étendre ces modèles avec les données de services, ils créent des modèles composites Power BI. S’ils ont besoin de rapports de type feuille de calcul, ils utilisent Excel pour produire des rapports basés sur des modèles sémantiques BI de base ou des modèles sémantiques BI de service.
- Les développeurs en décisionnel et les auteurs de rapports opérationnels se connectent directement aux modèles d’entreprise. Ils utilisent Power BI Desktop pour créer des rapports d’analytique associés à une connexion active. Ils peuvent également créer des rapports décisionnels axés sur les opérations sous la forme de rapports paginés Power BI, en écrivant des requêtes SQL natives pour accéder aux données des modèles d’entreprise Azure Synapse Analytics avec T-SQL ou des modèles sémantiques Power BI avec DAX ou MDX.
- Les scientifiques des données se connectent directement aux données dans le lac de données. Ils utilisent Azure Databricks et des notebooks Python pour développer des modèles ML, qui sont souvent expérimentaux et qui nécessitent des compétences spéciales pour une utilisation en production.
Contenu connexe
Pour plus d’informations sur cet article, consultez les ressources suivantes :
- Feuille de route sur l’adoption de Fabric : Centre d’excellence
- Décisionnel d’entreprise dans Azure avec Azure Synapse Analytics
- Vous avez des questions ? Essayez d’interroger la communauté Power BI
- Vous avez des suggestions ? Envoyez-nous vos idées pour améliorer Power BI
Services professionnels
Les partenaires Power BI certifiés sont là pour aider votre organisation à mener à bien la mise en place d’un centre d’excellence. Ils peuvent vous fournir une formation peu onéreuse ou encore un audit de vos données. Pour contacter un partenaire Power BI, accédez au portail des partenaires Power BI.
Vous pouvez également prendre contact avec des conseillers partenaires expérimentés. Ces derniers vous aideront à évaluer, mesurer ou implémenter Power BI.