Considérations relatives au mappage de champs pour les flux de données standard
Lors du chargement de données dans des tables Dataverse, vous devez mapper les colonnes de la requête source dans l’expérience de modification du flux de données aux colonnes de la table Dataverse de destination. Au-delà du mappage des données, il existe d’autres considérations et bonnes pratiques à prendre en compte. Dans cet article, nous abordons les différents paramètres de flux de données qui contrôlent le comportement de l’actualisation du flux de données et, par conséquent, les données de la table de destination.
Contrôler si les flux de données créent ou font des upsert des enregistrements à chaque actualisation
Chaque fois que vous actualisez un flux de données, il récupère les enregistrements de la source et les charge dans Dataverse. Si vous exécutez le flux de données plusieurs fois, selon la façon dont vous configurez le flux de données, vous pouvez :
- Créez de nouveaux enregistrements pour chaque actualisation du flux de données, même si ces enregistrements existent déjà dans la table de destination.
- Créez de nouveaux enregistrements s’ils n’existent pas déjà dans la table, ou mettez à jour les enregistrements existants s’ils existent déjà dans la table. Ce comportement est appelé faire un upsert.
L’utilisation d’une colonne clé indique au flux de données de faire des upsert des enregistrements dans la table de destination, tandis que la non-sélection d’une clé indique au flux de données de créer de nouveaux enregistrements dans la table de destination.
Une colonne clé est une colonne unique et déterministe d’une ligne de données de la table. Par exemple, dans une table Commandes, si l’ID de commande est une colonne clé, vous ne devez pas avoir deux lignes avec le même ID de commande. En outre, un ID de commande (disons une commande avec l’ID 345) ne doit représenter qu’une seule ligne de la table. Pour choisir la colonne clé de la table dans Dataverse à partir du flux de données, vous devez définir le champ clé dans l’expérience Tables de mappage.
Choix d’un nom principal et d’un champ de clé lors de la création d’une table
L’image suivante montre comment choisir la colonne clé à remplir à partir de la source lorsque vous créez une table dans le flux de données.
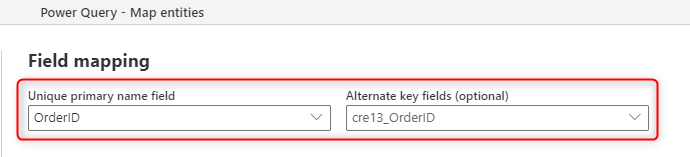
Le champ Nom principal que vous voyez dans le mappage de champs est destiné à un champ d’étiquette. Il n’est pas nécessaire que ce champ soit unique. Le champ utilisé dans le tableau pour vérifier la duplication sera le champ que vous avez défini dans le champ Autre clé.
Le fait d’avoir une clé primaire dans la table garantit que même si vous avez des données dupliquées dans le champ mappé à la clé primaire, les entrées en double ne seront pas chargées dans la table. Ce comportement conserve une haute qualité des données dans la table. Des données de haute qualité de données sont essentielles pour créer des solutions de reporting basées sur la table.
Champ Nom principal
Le champ Nom principal est un champ d’affichage utilisé dans Dataverse. Ce champ est utilisé dans les vues par défaut pour afficher le contenu de la table dans d’autres applications. Ce champ n’est pas le champ de la clé primaire et ne doit pas être considéré comme tel. Ce champ peut avoir des valeurs dupliquées, car il s’agit d’un champ d’affichage. Toutefois, il est recommandé d’utiliser un champ concaténé à mapper au champ de nom principal, pour que le nom soit parfaitement explicite.
Le champ de clé secondaire est utilisé comme clé primaire.
Choix d’un champ de clé lors du chargement dans une table existante
Lors du mappage d’une requête de flux de données à une table Dataverse existante, vous pouvez choisir si et quelle clé doit être utilisée lors du chargement de données dans la table de destination.
L’image suivante montre comment choisir la colonne clé à utiliser lorsque des upsert d’enregistrements sont faits dans une table Dataverse existante :

Définition de la colonne ID unique d’une table et son utilisation en tant que champ clé pour faire des upsert d'enregistrements dans des tables Dataverse existantes
Toutes les lignes de table Microsoft Dataverse possèdent des identificateurs uniques définis comme GUID. Ces GUID constituent la clé primaire de chaque table. Par défaut, la clé primaire d’une table ne peut pas être définie par des flux de données, et est générée automatiquement par Dataverse lorsqu’un enregistrement est créé. Il existe des cas d’usage avancés où l’utilisation de la clé primaire d’une table est souhaitable, par exemple, l’intégration de données à des sources externes tout en conservant les mêmes valeurs de clé primaire dans la table externe et la table Dataverse.
Remarque
- Cette fonctionnalité est disponible uniquement lors du chargement de données dans des tables existantes.
- Le champ d’identificateur unique accepte uniquement une chaîne contenant des valeurs GUID, tout autre type de données ou valeur entraîne l’échec de la création d’enregistrements.
Pour tirer parti du champ d’identificateur unique d’une table, sélectionnez Charger sur une table existante dans la page Tables de mappage lors de la création d’un flux de données. Dans l’exemple présenté dans l’image suivante, il charge les données dans la table CustomerTransactions et utilise la colonne TransactionID de la source de données comme identificateur unique de la table.
Remarquez que dans la liste déroulante Sélectionner une clé, l’identificateur unique, qui est toujours nommé « tablename + id », de la table peut être sélectionné. Étant donné que le nom de la table est « CustomerTransactions », le champ d’identificateur unique est nommé « CustomerTransactionId ».

Une fois sélectionnée, la section mappage de colonnes est mise à jour pour inclure l’identificateur unique en tant que colonne de destination. Vous pouvez ensuite mapper la colonne source représentant l’identificateur unique de chaque enregistrement.

Quels sont les bons candidats pour le champ de clé ?
Le champ clé est une valeur unique représentant une ligne unique de la table. Il est important d’avoir ce champ, car il vous permet d’éviter d’avoir des enregistrements en double dans la table. Ce champ peut provenir de trois sources :
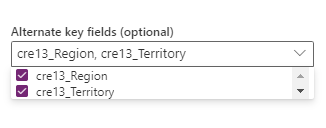
La clé primaire dans le système source (OrderID dans l’exemple précédent). champ concaténé créé par les transformations Power Query dans le flux de données.
Combinaison de champs à sélectionner dans l’option Clé secondaire. Une combinaison de champs utilisée comme champ de clé est également appelée clé composite.
Supprimer des lignes qui n’existent plus
Si vous souhaitez que les données de votre table soient toujours synchronisées avec les données du système source, choisissez l’option Supprimer les lignes qui n’existent plus dans la sortie de requête. Toutefois, cette option ralentit le flux de données, car elle nécessite d’effectuer une comparaison de lignes par rapport à la clé primaire (clé secondaire dans le mappage de champ du flux de données) pour que cette action se produise.
L’option signifie que, si une ligne de données dans la table n’existe pas dans la sortie de requête de la prochaine actualisation du flux de données, cette ligne est supprimée de la table.

Remarque
Les flux de données Standard V2 s’appuient sur les champs createdon et modifiedon afin de supprimer les lignes qui n’existent pas dans la sortie des flux de données, à partir de la table de destination. Si ces colonnes n’existent pas dans la table de destination, les enregistrements ne sont pas supprimés.
Limitations connues
- Le mappage vers les champs de recherche polymorphe n’est pas pris en charge.
- Le mappage vers un champ de recherche multiniveau (c’est-à-dire une recherche qui pointe vers le champ de recherche d’une autre table) n’est pas pris en charge.
- Le mappage vers les champs Statut et Raison du statut n’est actuellement pas pris en charge.
- Le mappage de données en texte à plusieurs lignes qui inclut des caractères de saut de ligne n’est pas pris en charge et les sauts de ligne sont supprimés. Au lieu de cela, vous pouvez utiliser la balise de saut de ligne
<br>pour charger et conserver le texte à plusieurs lignes. - Le mappage aux champs Choix configurés avec l’option sélection multiple activée est pris en charge uniquement dans certaines conditions. Le flux de données charge uniquement les données dans les champs Choix avec l’option sélection multiple activée, et une liste de valeurs séparées par des virgules (entiers) des étiquettes est utilisée. Par exemple, si les étiquettes sont « Choice1, Choice2, Choice3 » avec les valeurs entières correspondantes de « 1, 2, 3 », les valeurs de colonne doivent être « 1,3 » pour sélectionner les premiers et derniers choix.
- Les flux de données Standard V2 s’appuient sur les champs
createdonetmodifiedonafin de supprimer les lignes qui n’existent pas dans la sortie des flux de données, à partir de la table de destination. Si ces colonnes n’existent pas dans la table de destination, les enregistrements ne sont pas supprimés. - Le mappage vers les champs dont la propriété IsValidForCreate est définie sur
falsen’est pas pris en charge (par exemple, le champ Compte de l’entité Contact).