Vue d’ensemble de l’évaluation et du pliage de requête dans Power Query
Cet article fournit une vue d’ensemble de base de la façon dont les requêtes M sont traitées et transformées en demandes de source de données.
Script M Power Query
Toute requête, qu’elle soit créée par Power Query, écrite manuellement par vous dans l’éditeur avancé ou entrée à l’aide d’un document vide, est constituée de fonctions et d’une syntaxe du langage de formules M Power Query. Cette requête est interprétée et évaluée par le moteur Power Query pour générer ses résultats. Le script M fait office d’ensemble d’instructions nécessaires pour évaluer la requête.
Conseil
Vous pouvez considérer le script M comme une recette décrivant comment préparer vos données.
La manière la plus courante de créer un script M consiste à utiliser l’éditeur Power Query. Par exemple, lorsque vous vous connectez à une source de données, telle qu’une base de données SQL Server, notez sur le côté droit de votre écran qu’il existe une section appelée étapes appliquées. Cette section affiche l’ensemble des étapes ou transformations utilisées dans votre requête. En ce sens, l’éditeur Power Query fait office d’interface pour vous aider à créer le script M approprié pour les transformations que vous visez, et garantit que le code que vous utilisez est valide.
Remarque
Le script M est utilisé dans l’éditeur Power Query pour :
- Afficher la requête comme une série d’étapes, et autoriser la création ou la modification de nouvelles étapes.
- Afficher une vue de diagramme.

L’image précédente met l’accent sur la section étapes appliquées, qui contient les étapes suivantes :
- Source : établit la connexion à la source de données. Dans ce cas, il s’agit d’une connexion à une base de données SQL Server.
- Navigation : accède à une table spécifique dans la base de données.
- Autres colonnes supprimées : sélectionne les colonnes de la table à conserver.
- Lignes triées : trie la table à l’aide d’une ou plusieurs colonnes.
- Lignes supérieures conservées : filtre le tableau pour ne conserver que certaines lignes du haut du tableau.
Cet ensemble de noms d’étapes est un moyen convivial d’afficher le script M que Power Query a créé pour vous. Il existe plusieurs façons d’afficher le script M complet. Dans Power Query, vous pouvez sélectionner Éditeur avancé sous l’onglet Affichage. Vous pouvez aussi sélectionner Éditeur avancé dans le groupe Requête sous l’onglet Accueil. Dans certaines versions de Power Query, vous pouvez également modifier l’affichage de la barre de formule pour afficher le script de requête en accédant à l’onglet Affichage, puis, à partir du groupe Disposition, sélectionner Mode script>Script de requête.

La plupart des noms figurant dans le volet Étapes appliquées sont également utilisés tels quels dans le script M. Les étapes d’une requête sont nommées à l’aide de quelque chose appelé identificateurs en langage M. Parfois, des caractères supplémentaires enveloppent les noms d’étapes dans M, mais ces caractères n’apparaissent pas dans les étapes appliquées. Par exemple, #"Kept top rows" est classé comme identificateur entre guillemets en raison de ces caractères supplémentaires. Vous pouvez utiliser un identificateur entre guillemets pour autoriser l’utilisation de n’importe quelle séquence de zéro ou plusieurs caractères Unicode comme identificateur, notamment des mots clés, des espaces blancs, des commentaires, des opérateurs et des signes de ponctuation. Pour en savoir plus sur les identificateurs en langage M, consultez Structure lexicale.
Toutes les modifications apportées à votre requête via l’éditeur Power Query mettent automatiquement à jour le script M de votre requête. Par exemple, en utilisant l’image précédente comme point de départ, si vous modifiez le nom de l’étape Des lignes supérieures conservées en 20 premières lignes, cette modification est automatiquement mise à jour dans la vue de script.

Bien que nous recommandions de recourir à l’éditeur Power Query pour créer la totalité ou la majeure partie du script M à votre place, vous pouvez ajouter ou modifier manuellement des éléments de votre script M. Pour en savoir plus sur le langage M, visitez le site officiel de documentation pour le langage M.
Remarque
Le script M, également appelé code M, est un terme utilisé pour tout code qui utilise le langage Power Query M. Dans le contexte de cet article, script M fait également référence au code à l’intérieur d’une requête Power Query, accessible via la fenêtre de l’éditeur avancé ou le mode script dans la barre de formule.
Évaluation de requête dans Power Query
Le diagramme suivant explore le processus qui se produit lors de l’évaluation d’une requête dans Power Query.
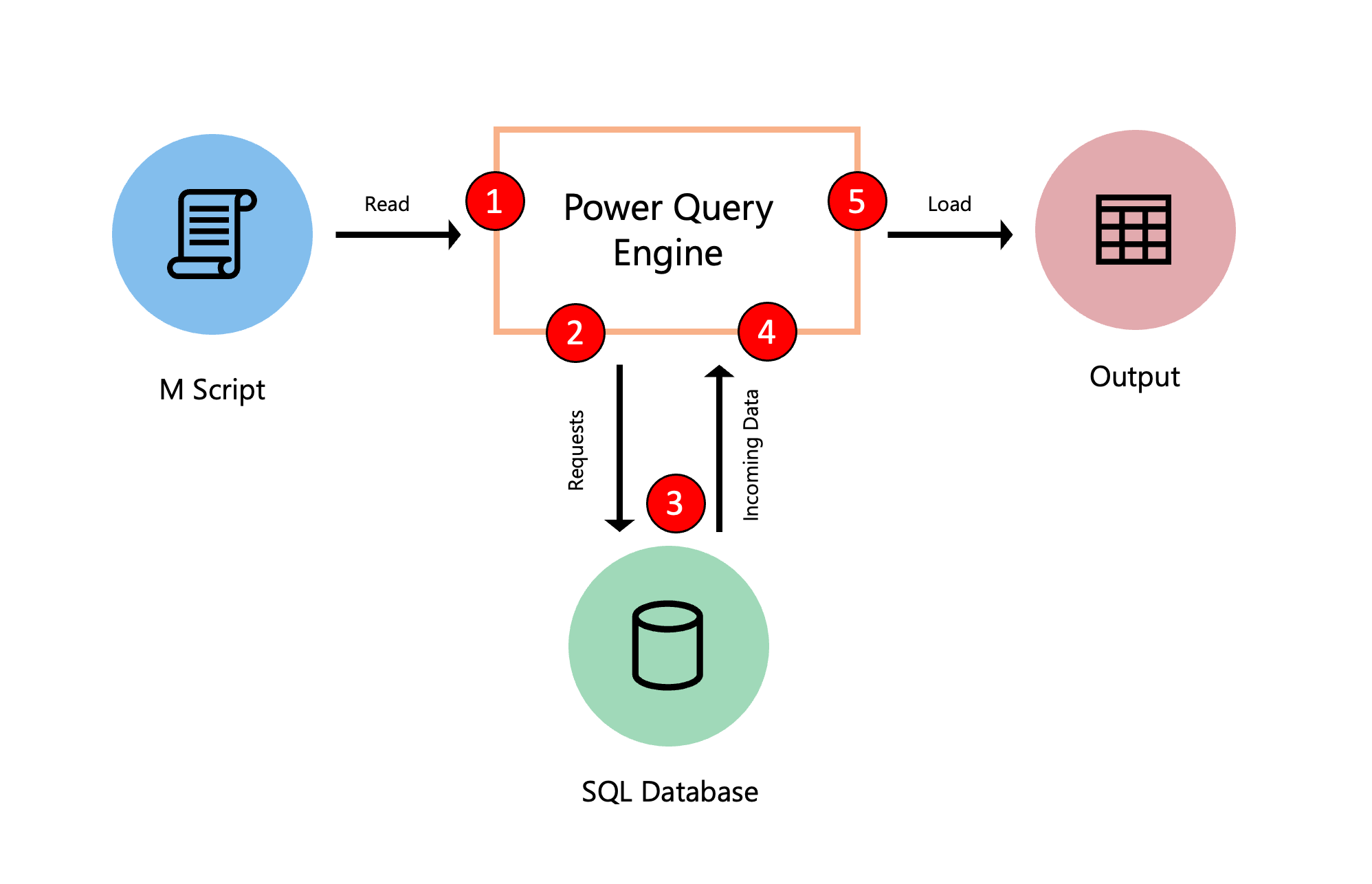
- Le script M dans l’éditeur avancé est soumis au moteur Power Query. D’autres informations importantes sont également incluses, telles que les informations d’identification et les niveaux de confidentialité de la source de données.
- Power Query détermine les données à extraire de la source de données, et envoie une demande à celle-ci.
- La source de données répond à la demande de Power Query en lui transférant les données demandées.
- Power Query reçoit les données de la source et opère toutes les transformations à l’aide du moteur Power Query si nécessaire.
- Les résultats dérivés du point précédent sont chargés dans une destination.
Remarque
Bien que cet exemple présente une requête avec une base de données SQL comme source de données, le concept s’applique aux requêtes avec ou sans source de données.
Quand Power Query lit votre script M, il l’exécute via un processus d’optimisation afin d’évaluer plus efficacement votre requête. Dans ce processus, il détermine les étapes (transformations) de votre requête qui peuvent être délestées vers votre source de données. Il détermine également les autres étapes à évaluer à l’aide du moteur Power Query. Dans ce processus d’optimisation appelé pliage de requête, Power Query tente d’envoyer (push) autant d’exécution que possible à la source de données pour optimiser l’exécution de votre requête.
Important
Toutes les règles du langage de formules M de Power Query (également appelé langage M) sont respectées. Plus particulièrement, l’évaluation différée joue un rôle important pendant le processus d’optimisation. Dans ce processus, Power Query comprend quelles transformations spécifiques de votre requête doivent être évaluées. Power Query comprend également quelles autres transformations n’ont pas besoin d’évaluation parce qu’elles ne sont pas nécessaires dans le résultat de votre requête.
En outre, quand plusieurs sources sont impliquées, le niveau de confidentialité des données de chaque source de données est pris en compte lors de l’évaluation de la requête. Informations supplémentaires : En arrière-plan du pare-feu de confidentialité des données
Le diagramme suivant illustre les étapes de ce processus d’optimisation.
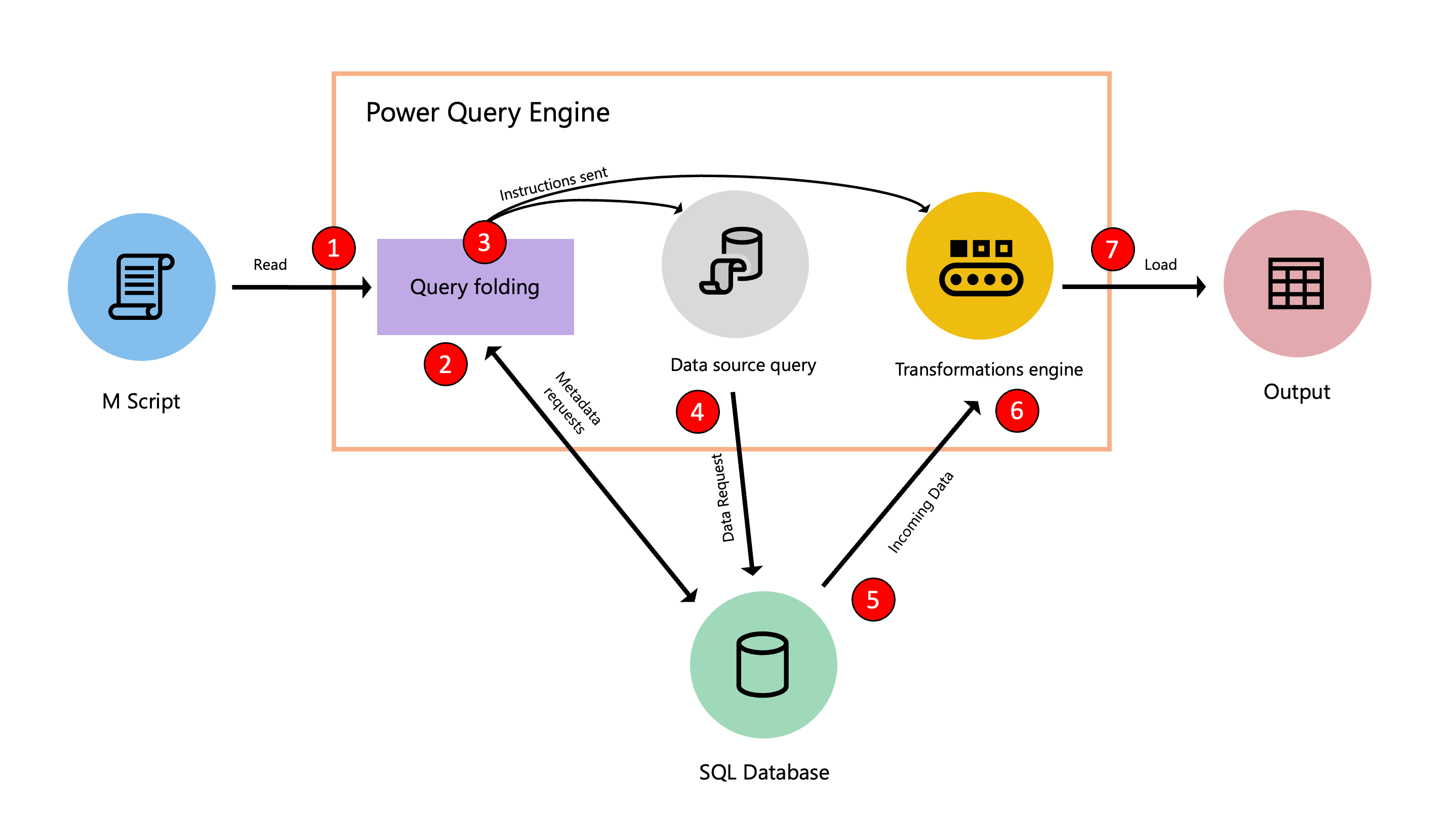
- Le script M dans l’éditeur avancé est soumis au moteur Power Query. D’autres informations importantes sont également fournies, telles que les informations d’identification et les niveaux de confidentialité de la source de données.
- Le mécanisme de pliage de requête envoie des demandes de métadonnées à la source de données pour déterminer les capacités de la source de données, les schémas de table, les relations entre les différentes tables de la source de données, et plus encore.
- Sur la base des métadonnées reçues, le mécanisme de pliage de requête détermine les informations à extraire de la source de données et l’ensemble des transformations qui doivent intervenir à l’intérieur du moteur Power Query. Il envoie les instructions à deux autres composants qui s’occupent de récupérer les données à partir de la source, et de transformer les données entrantes dans le moteur Power Query si nécessaire.
- Une fois que les composants internes de Power Query reçoivent les instructions, Power Query envoie une demande à la source de données à l’aide d’une requête de source de données.
- La source de données reçoit la demande de Power Query et transfère les données au moteur Power Query.
- Une fois les données à l’intérieur de Power Query, le moteur de transformation de Power Query (également appelé moteur mashup) opère les transformations qui n’ont pas pu être repliées ou délestées vers la source de données.
- Les résultats dérivés du point précédent sont chargés dans une destination.
Remarque
Selon les transformations et la source de données utilisées dans le script M, Power Query détermine s’il diffuse ou met en mémoire tampon les données entrantes.
Vue d’ensemble du pliage de requête
L’objectif du pliage de requête est de délester ou d’envoyer (push) une partie de l’évaluation d’une requête vers une source de données qui peut calculer les transformations de votre requête.
Le mécanisme de pliage de requête atteint cet objectif en traduisant votre script M dans un langage que votre source de données peut interpréter et exécuter. Il envoie (push) ensuite l’évaluation à votre source de données et renvoie le résultat de cette évaluation à Power Query.
Cette opération fournit souvent une exécution de requête plus rapide que l’extraction de toutes les données requises à partir de votre source de données et l’exécution de toutes les transformations requises dans le moteur Power Query.
Lorsque vous utilisez ’expérience d’obtention de donnée, Power Query vous guide dans le processus qui vous permet finalement de vous connecter à votre source de données. Dans ce contexte, Power Query utilise une série de fonctions en langage M, classées comme fonctions d’accès aux données. Ces fonctions spécifiques recourent à divers mécanismes et protocoles pour se connecter à votre source de données, en utilisant un langage que celle-ci peut comprendre.
Toutefois, les étapes qui suivent dans votre requête sont les étapes ou transformations que le mécanisme de pliage de requête tente d’optimiser. Celui-ci vérifie ensuite si ces opérations peuvent être délestées vers votre source de données au lieu d’être traitées à l’aide du moteur Power Query.
Important
Toutes les fonctions de source de données, généralement présentées comme l’étape Source d’une requête, interrogent les données à la source dans le langage natif de celle-ci. Le mécanisme de pliage de requête est utilisé sur toutes les transformations appliquées à votre requête après votre fonction de source de données, afin qu’elles puissent être traduites et combinées en une seule requête de source de données ou en autant de transformations qu’il est possible de délester vers la source de données.
Selon la structure de la requête, le mécanisme de pliage de requête peut produire trois résultats :
- Pliage de requête complet : quand toutes vos transformations de requêtes sont renvoyées (push) à la source de données et qu’un traitement minimal se produit au niveau du moteur Power Query.
- Pliage de requête partiel : quand seules quelques transformations dans votre requête peuvent être renvoyées à la source de données. Dans ce cas, seul un sous-ensemble de vos transformations sont effectuées au niveau de votre source de données, et les transformations de requêtes restantes se produisent dans le moteur Power Query.
- Aucun pliage de requête : quand la requête contient des transformations qui ne peuvent pas être traduites dans le langage de requête natif de votre source de données, soit parce que les transformations ne sont pas prises en charge, soit parce que le connecteur ne prend pas en charge le pliage de requête. Dans ce cas, Power Query reçoit les données brutes de votre source de données, et utilise le moteur Power Query pour obtenir le résultat souhaité en traitant les transformations requises au niveau du moteur Power Query.
Remarque
Le mécanisme de pliage de requête est principalement disponible dans des connecteurs pour des sources de données structurées telles que Microsoft SQL Server et Flux OData. Pendant la phase d’optimisation, il peut arriver que le moteur réorganise les étapes dans la requête.
L’utilisation d’une source de données disposant de davantage de ressources de traitement ainsi que de fonctionnalités de pliage de requête peut accélérer les temps de chargement de votre requête, car le traitement se produit à la source de données et non au niveau du moteur Power Query.
Contenu connexe
Pour des exemples détaillés des trois résultats possibles du mécanisme de pliage de requête, consultez Exemples de pliage de requête.
Pour plus d’informations sur les indicateurs de pliage de requête figurant dans le volet Étapes appliquées, consultez Indicateurs de pliage de requête.