Options de Big Data sur la plateforme Microsoft SQL Server
S’applique à : ![]() SQL Server 2019 (15.x) et versions ultérieures
SQL Server 2019 (15.x) et versions ultérieures
Microsoft SQL Server 2019 Big Clusters est un module complémentaire pour la plateforme SQL Server qui vous permet de déployer des clusters évolutifs de conteneurs SQL Server, Spark et HDFS exécutés sur Kubernetes. Ces composants sont exécutés côte à côte pour que vous puissiez lire, écrire et traiter du Big Data à l’aide de bibliothèques Transact-SQL ou Spark, afin de pouvoir combiner et analyser facilement vos données relationnelles de grande valeur avec du Big Data volumineux non relationnel. Les clusters Big Data vous permettent également de virtualiser les données avec PolyBase, de sorte que vous pouvez interroger des données à partir de sources de données externes SQL Server, Oracle, Teradata, MongoDB et autres en utilisant des tables externes. Le module complémentaire Microsoft SQL Server 2019 Big Clusters assure la haute disponibilité de l'instance principale SQL Server et de toutes les bases de données en utilisant la technologie de groupe de disponibilité Always On.
Le module complémentaire SQL Server 2019 pour clusters Big Data fonctionne en local et dans le cloud à l'aide de la plateforme Kubernetes, pour tout déploiement standard de Kubernetes. En outre, le module complémentaire SQL Server 2019 pour clusters Big Data s'intègre à Active Directory et inclut un contrôle d'accès en fonction du rôle pour répondre aux besoins de sécurité et de conformité de votre entreprise.
Mise hors service du module complémentaire SQL Server 2019 pour clusters Big Data
Le 28 février 2025, nous allons mettre hors service les clusters Big Data SQL Server 2019. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet sur le blog d’annonce.
Modifications apportées à la prise en charge de PolyBase dans SQL Server
La mise hors service SQL Server 2019 pour clusters Big Data est liée à certaines fonctionnalités liées à la mise à l’échelle des requêtes.
La fonctionnalité des groupes de scale-out PolyBase de Microsoft SQL Server a été supprimée. La fonctionnalité de groupe de scale-out est supprimée du produit dans SQL Server 2022 (16.x). Les versions SQL Server 2019, SQL Server 2017 et SQL Server 2016 sur le marché continuent de prendre en charge la fonctionnalité jusqu’à la fin de vie de ces produits. La virtualisation des données PolyBase continue d’être entièrement prise en charge en tant que fonctionnalité de scale-up dans SQL Server.
Les sources de données externes Hadoop Cloudera (CDP) et Hortonworks (HDP) seront également mises hors service pour toutes les versions de SQL Server sur le marché et ne sont pas incluses dans SQL Server 2022. La prise en charge de sources de données externes est limitée aux versions de produit prises en charge de manière standard par leur fournisseur respectif. Nous vous conseillons d'utiliser la nouvelle intégration de stockage d’objets disponible dans SQL Server 2022 (16.x).
Dans SQL Server 2022 (16.x) et versions ultérieures, les utilisateurs doivent configurer leurs sources de données externes pour utiliser les nouveaux connecteurs lors de la connexion à Stockage Azure. Le tableau suivant récapitule les changements :
| Source de données externe | Du | À |
|---|---|---|
| Stockage Blob Azure | wasb[s] |
abs |
| ADLS Gen 2 | abfs[s] |
adls |
Notes
Le Stockage Blob Azure (abs) nécessite l’utilisation de la signature d’accès partagé (SAS) pour le SECRET dans les informations d’identification limitées à la base de données. Dans SQL Server 2019 ou antérieur, le connecteur wasb[s] utilisait une clé de compte de stockage avec des informations d’identification délimitées à la base de données lors de l’authentification auprès du compte de stockage Azure.
Comprendre l’architecture des clusters Big Data pour les options de remplacement et de migration
Pour créer votre solution de remplacement pour un système de stockage et de traitement de Big Data, il est important de comprendre ce qu'offre SQL Server 2019 pour clusters Big Data, et son architecture peut vous aider à faire vos choix. L’architecture d’un cluster Big Data est la suivante :

Cette architecture précise le mappage de fonctionnalités suivant :
| Composant | Avantage |
|---|---|
| Kubernetes | Orchestrateur open source pour le déploiement et la gestion d'applications en conteneurs à grande échelle. Fournit une méthode déclarative pour créer et contrôler la résilience, la redondance et la portabilité pour l'ensemble de l'environnement avec une mise à l'échelle élastique. |
| Contrôleur de clusters Big Data | Assure la gestion et la sécurité du cluster. Il contient le service de contrôle, le magasin de configuration et d’autres services de niveau cluster tels que Kibana, Grafana et ElasticSearch. |
| Pool de calcul | Fournit des ressources de calcul au cluster. Il contient des nœuds exécutant des pods SQL Server sur Linux. Les pods du pool de calcul sont divisés en instances de calcul SQL pour des tâches de traitement spécifiques. Ce composant fournit également une virtualisation de données en utilisant PolyBase pour interroger des sources de données externes sans déplacer ou copier les données. |
| Pool de données | Fournit la persistance des données pour le cluster. Le pool de données est constitué d’un ou plusieurs pods exécutant SQL Server sur Linux. Il est utilisé pour l’ingestion des données à partir de requêtes SQL ou de travaux Spark. |
| Pool de stockage | Le pool de stockage est composé de pods de pool de stockage constitués de SQL Server sur Linux, Spark et HDFS. Tous les nœuds de stockage d’un cluster Big Data sont membres d’un cluster HDFS. |
| Pool d’applications | Permet le déploiement d’applications sur un cluster Big Data au moyen d’interfaces conçues pour créer, gérer et exécuter des applications. |
Pour plus d’informations sur ces fonction, consultez Présentation des clusters Big Data SQL Server.
Options de remplacement des fonctionnalités pour Big Data et SQL Server
La fonction de données opérationnelle offerte par SQL Server dans les clusters Big Data peut être remplacée par SQL Server localement dans une configuration hybride ou à l’aide de la plateforme Microsoft Azure. Microsoft Azure offre un choix de bases de données relationnelles, NoSQL et en mémoire entièrement gérées, couvrant les moteurs propriétaires et open source, pour répondre aux besoins des développeurs d'applications modernes. La gestion de l'infrastructure, qui inclut l'évolutivité, la disponibilité et la sécurité, est automatisée, ce qui vous fait gagner du temps et de l'argent et vous permet de vous concentrer sur la création d'applications. Les bases de données gérées par Azure vous simplifient la tâche en vous offrant un aperçu des performances grâce à l'intelligence intégrée, avec une mise à l’échelle sans limites et une gestion des menaces de sécurité. Pour plus d’informations, consultez Bases de données Azure.
Le point de décision suivant est l'emplacement du calcul et du stockage des données pour analyse. Les deux choix d'architecture sont les déploiements dans le cloud et hybrides. La plupart des charges de travail analytiques peuvent être migrées vers la plateforme Microsoft Azure. Les données « nées dans le cloud » (provenant d'applications basées sur le cloud) sont des candidats de choix pour ces technologies, et les services de déplacement des données peuvent migrer les données locales à grande échelle de manière sûre et rapide. Pour en savoir plus sur les options de déplacement des données, consultez Solutions de transfert de données.
Microsoft Azure dispose de systèmes et de certifications permettant de sécuriser les données et leur traitement dans divers outils. Pour plus d'informations sur ces certifications, consultez le Centre de gestion de la confidentialité.
Notes
La plateforme Microsoft Azure offre un très haut niveau de sécurité, de multiples certifications pour divers secteurs et garantit la souveraineté des données pour les exigences gouvernementales. Microsoft Azure propose également une plateforme dans le cloud dédiée aux charges de travail gouvernementales. La sécurité seule ne doit pas être le premier critère de décision pour les systèmes locaux. Vous devez évaluer soigneusement le niveau de sécurité offert par Microsoft Azure avant de décider de conserver vos solutions de Big Data localement.
Dans l'option d’architecture dans le cloud, tous les composants résident dans Microsoft Azure. Votre responsabilité réside dans les données et le code que vous créez pour le stockage et le traitement de vos charges de travail. Ces options sont traitées plus en détail dans cet article.
- Cette option est idéale pour de nombreux composants de stockage et de traitement des données, et quand vous souhaitez vous concentrer sur les constructions de données et de traitement plutôt que sur l’infrastructure.
Dans les options d’architecture hybride, certains composants sont conservés sur place et d'autres sont placés chez un fournisseur de services dans le cloud. La connectivité entre ces deux environnements est conçue pour garantir la meilleure sélection élective de traitement des données.
- Cette option est recommandée quand vous avez effectué d’importants investissements dans des technologies et des architectures locales, mais que vous souhaitez utiliser des offres Microsoft Azure, ou lorsque vous disposez de cibles de traitement et d’application locales ou destinées à un public international.
Pour plus d'informations sur la construction d'architectures évolutives, consultez Construire un système évolutif pour les données massives.
Dans le cloud
Azure SQL avec Synapse
Vous pouvez remplacer la fonctionnalité de SQL Server Big Data Clusters en utilisant une ou plusieurs options de base de données Azure SQL pour les données opérationnelles, et Microsoft Azure Synapse pour vos charges de travail analytiques.
Microsoft Azure Synapse est un service d'analyse d'entreprise qui accélère l’accès aux insights via les entrepôts de données et les systèmes de Big Data, en utilisant le traitement distribué et les constructions de données. Azure Synapse combine les technologies SQL utilisées dans l’entreposage des données d’entreprise, les technologies Spark utilisées pour le Big Data et les pipelines pour l’intégration des données et l’ETL/ELT. Il offre également un haut degré d’intégration à d’autres services Azure tels que Power BI, Cosmos DB et Azure Machine Learning.
Utilisez Microsoft Azure Synapse comme remplacement de SQL Server 2019 pour clusters Big Data lorsque vous devez :
- Utiliser à la fois des modèles de ressources serverless et dédiés. Pour bénéficier de performances et de coûts prévisibles, créez des pools SQL dédiés afin de réserver de la puissance de traitement aux données stockées dans les tables SQL.
- Traiter des charges de travail non planifiées ou « en rafale» , avec un accès à un point de terminaison SQL serverless toujours disponible.
- Utilisez les fonctionnalités de streaming intégrées pour placer des données de sources de données cloud dans des tables SQL.
- Intégrez l’IA à SQL en utilisant des modèles Machine Learning pour effectuer le scoring des données avec la fonction T-SQL PREDICT.
- Utilisez des modèles ML avec des algorithmes SparkML et l’intégration d’Azure Machine Learning pour Apache Spark 2.4 prise en charge pour Linux Foundation Delta Lake.
- Utilise un modèle de ressource simplifié qui vous évite d’avoir à vous soucier de la gestion des clusters.
- Traiter des données nécessitant un démarrage rapide de Spark et une mise à l'échelle automatique agressive.
- Traiter des données à l’aide de .NET pour Spark, ce qui vous permet de mettre à profit votre expertise en C# et votre code .NET existant au sein d’une application Spark.
- Utiliser des tables définies sur les fichiers du lac de données de manière transparente par Spark ou Hive.
- Utiliser SQL avec Spark pour explorer et analyser directement des fichiers Parquet, CSV, TSV et JSON stockés dans un lac de données.
- Charger des données de manière rapide et évolutive entre les bases de données SQL et Spark.
- Ingérer des données depuis plus de 90 sources de données.
- Activer ETL « sans code » avec les activités de flux de données.
- Orchestrer des notebooks, des travaux Spark, des procédures stockées, des scripts SQL, etc.
- Superviser les ressources, l’utilisation et les utilisateurs dans SQL et Spark.
- Utiliser le contrôle d’accès en fonction du rôle pour simplifier l’accès aux ressources d’analytique.
- Écrire du code SQL ou Spark et l’intégrer aux processus CI/CD d’entreprise.
L’architecture de Microsoft Azure Synapse est la suivante :

Pour plus d'informations sur Microsoft Azure Synapse, consultez Qu'est-ce qu'Azure Synapse Analytics ?
Azure SQL et Azure Machine Learning
Vous pouvez remplacer la fonctionnalité de SQL Server Big Data Clusters en utilisant une ou plusieurs options de base de données Azure SQL pour les données opérationnelles, et Microsoft Azure Machine Learning pour vos charges de travail prédictives.
Azure Machine Learning est un service cloud qui peut être utilisé pour tout type de machine learning, du ML classique au deep learning et à l’apprentissage supervisé et non supervisé. Que vous préfériez écrire du code Python ou R avec le SDK ou utiliser des options sans code/peu de code dans le studio, vous pouvez créer, entraîner et gérer des modèles Machine Learning et Deep Learning dans un espace de travail Azure Machine Learning. Avec Azure Machine Learning, vous pouvez commencer l’entraînement sur votre ordinateur local, puis effectuer un scale-out sur le cloud. Le service interagit également avec les outils open source populaires d’apprentissage profond et d’apprentissage par renforcement tels que PyTorch, TensorFlow, scikit-Learn et Ray RLlib.
Utilisez Microsoft Azure Machine Learning comme remplacement de SQL Server 2019 pour clusters Big Data lorsque vous avez besoin :
- D’un environnement web basé sur un concepteur pour Machine Learning : faites un glisser-déposer des modules pour générer vos expériences, puis déployez des pipelines dans un environnement avec peu de code.
- Notebooks Jupyter : utilisez nos exemples de notebooks ou créez vos propres notebooks pour utiliser nos exemples de kits SDK Python pour votre Machine Learning.
- Utilisez des scripts R ou des notebooks dans lesquels vous utilisez le Kit de développement logiciel (SDK) pour R pour écrire votre propre code, ou utilisez les modules R dans le concepteur.
- L’accélérateur de solution de nombreux modèles s’appuie sur Azure Machine Learning, permet d’entraîner, d’utiliser et de gérer des centaines, voire des milliers de modèles Machine Learning.
- Les extensions Machine Learning pour Visual Studio Code (préversion) vous fournissent un environnement de développement complet pour la génération et la gestion de vos projets Machine Learning.
- Une interface de ligne de commande (CLI) Machine Learning, Azure Machine Learning inclut une extension Azure CLI qui fournit des commandes pour gérer les ressources Azure Machine Learning à partir de la ligne de commande.
- Intégration à des frameworks open source comme PyTorch, TensorFlow, scikit-learn et bien d’autres pour l’entraînement, le déploiement et la gestion du processus de machine learning de bout en bout.
- Apprentissage par renforcement avec Ray RLlib.
- MLflow pour effectuer le suivi des métriques et déployer des modèles ou kubeflow pour créer des pipelines de flux de travail de bout en bout.
L'architecture d'un déploiement Microsoft Azure Machine Learning est la suivante :

Pour plus d'informations sur Microsoft Azure Machine Learning, consultez Fonctionnement d’Azure Machine Learning.
Azure SQL à partir de Databricks
Vous pouvez remplacer la fonctionnalité de SQL Server Big Data Clusters en utilisant une ou plusieurs options de base de données Azure SQL pour les données opérationnelles, et Microsoft Azure Databricks pour vos charges de travail analytiques.
Azure Databricks est une plateforme d’analytique données optimisée pour la plateforme de services cloud Microsoft Azure. Azure Databricks offre deux environnements pour développer des applications gourmandes en données : Azure Databricks SQL Analytics et Azure Databricks Workspace.
Azure Databricks SQL Analytics fournit une plateforme facile à utiliser pour les analystes qui souhaitent exécuter des requêtes SQL sur leur lac de données, créer plusieurs types de visualisations pour explorer les résultats des requêtes à partir de différentes perspectives, et créer et partager des tableaux de bord.
Azure Databricks Workspace fournit un espace de travail interactif qui permet la collaboration entre les ingénieurs de données, les scientifiques des données et les ingénieurs de machine learning. Pour un pipeline de Big Data, les données (brutes ou structurées) sont ingérées en lots dans Azure par le biais d’Azure Data Factory ou envoyées en streaming en quasi-temps réel avec Apache Kafka, Event Hubs ou IoT Hub. Elles aboutissent dans un lac de données en vue d’un stockage persistant à long terme, dans le Stockage Blob Azure ou Azure Data Lake Storage. Dans le cadre de votre workflow d’analytique, utilisez Azure Databricks pour lire les données à partir de plusieurs sources de données et les convertir en informations capitales avec Spark.
Utilisez Microsoft Azure Databricks comme remplacement de SQL Server 2019 pour clusters Big Data lorsque vous avez besoin de :
- Clusters Spark entièrement gérés avec Spark SQL et DataFrames.
- Streaming pour le traitement et l'analyse des données en temps réel pour les applications analytiques et interactives, Intégration à HDFS, Flume et Kafka.
- Accès à la bibliothèque MLlib constituée d’utilitaires et d’algorithmes d’apprentissage courants, notamment la classification, la régression, le clustering, le filtrage collaboratif, la réduction de la dimensionnalité, ainsi que les primitives d’optimisation sous-jacentes.
- Documentation de votre progression dans des notebooks en R, Python, Scala ou SQL.
- Visualisation des données en quelques étapes à l'aide d'outils familiers comme Matplotlib, ggplot ou d3.
- Tableaux de bord interactifs pour créer des rapports dynamiques.
- GraphX pour graphes et calcul de graphes pour des cas d’usage très divers qui vont de l’analytique cognitive à l’exploration de données.
- Création de clusters en quelques secondes, avec mise à l'échelle automatique dynamique des clusters, et partage entre les équipes.
- Accès par programmation au cluster à l’aide d’API REST.
- Accès immédiat aux dernières fonctionnalités d’Apache Spark avec chaque version.
- Une API Spark Core : inclut la prise en charge de R, SQL, Python, Scala et Java.
- Un espace de travail interactif pour l’exploration et la visualisation.
- Points de terminaison SQL complètement managés dans le cloud.
- Requêtes SQL qui s’exécutent sur des points de terminaison SQL complètement managés, dimensionnés en fonction de la latence des requêtes et du nombre d’utilisateurs simultanés.
- Intégration avec Microsoft Entra ID (anciennement Azure Active Directory).
- L’accès basé sur les rôles permet d’obtenir des autorisations d’utilisateur fines pour les blocs-notes, les clusters, les travaux et les données.
- Contrats SLA de niveau entreprise.
- Des tableaux de bord pour partager des insights, combinant des visualisations et du texte pour partager des insights à de vos requêtes.
- Les alertes facilitent la surveillance et l’intégration, ainsi que la notification lorsqu'un champ retourné par une requête atteint un seuil. Utilisez les alertes pour superviser votre activité ou intégrez-les à des outils pour démarrer des workflows comme l’intégration d’utilisateurs ou les tickets de support.
- Sécurité de niveau entreprise, notamment l’intégration de Microsoft Entra ID, des contrôles basés sur les rôles et des SLA qui protègent vos données et votre entreprise.
- Intégration aux services Azure et aux bases de données et magasins Azure, y compris Synapse Analytics, Cosmos DB, Data Lake Store et Stockage Blob.
- Intégration à Power BI et d'autres outils BI, notamment Tableau Software.
L’architecture d’un déploiement Microsoft Azure Databricks est la suivante :
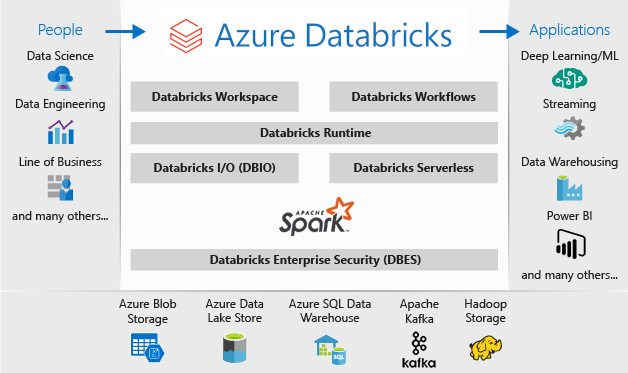
Pour plus d'informations sur Microsoft Azure Databricks, consultez Présentation de Databricks Data Science & Engineering
Hybride
Base de données mise en miroir Fabric
En tant qu’expérience de réplication de données, la mise en miroir de bases de données dans Fabric est une solution à faible coût et à faible latence qui permet de rassembler les données de différents systèmes dans une seule plateforme d’analyse. Vous pouvez répliquer en continu votre patrimoine de données existant directement dans OneLake de Fabric, y compris les données de Azure SQL Database, Snowflake et Cosmos DB.
Avec les données les plus à jour dans un format interrogeable dans OneLake, vous pouvez désormais utiliser tous les différents services de Fabric, tels que l’exécution d’analyses avec Spark, l’exécution de notebooks, l’ingénierie des données, la visualisation par le biais de rapports Power BI, etc.
La mise en miroir dans Fabric offre une expérience simple pour accélérer la durée de vie des insights et des décisions, et pour décomposer les silos de données entre les solutions technologiques, sans développer de processus d’extraction, de transformation et de chargement (ETL) coûteux pour déplacer des données.
Avec la mise en miroir dans Fabric, vous n’avez pas besoin de regrouper différents services à partir de plusieurs fournisseurs. Au lieu de cela, vous pouvez profiter d'un produit hautement intégré, complet et simple d'utilisation, conçu pour simplifier vos besoins en matière d'analyse et pour favoriser l'ouverture et la collaboration entre les solutions technologiques capables de lire le format de table Delta Lake open source.
Pour plus d’informations, consultez l’article suivant :
- Bases de données en miroir Microsoft Fabric
- Surveillance des bases de données mise en miroir Microsoft Fabric
- Explorer les données de votre base de données mise en miroir à l’aide de Microsoft Fabric
- Présentation de Microsoft Fabric
- Données de modèle dans le modèle sémantique Power BI par défaut dans Microsoft Fabric
- Quel est le point de terminaison d’analytique SQL d’un Lakehouse ?
- Direct Lake
Utiliser SQL Server 2022 avec Azure Synapse Link pour SQL
SQL Server 2022 (16.x) contient une nouvelle fonctionnalité qui permet la connectivité entre les tables SQL Server et la plateforme Microsoft Azure Synapse, appelée Azure Synapse Link pour SQL. Azure Synapse Link pour SQL Server 2022 (16.x) fournit des flux de modifications automatiques qui capturent les modifications dans SQL Server et les chargent dans Azure Synapse Analytics. Elle permet une analyse en quasi-temps réel et un traitement hybride transactionnel et analytique avec un impact minimal sur les systèmes opérationnels. Une fois les données dans Synapse, vous pouvez les combiner avec de nombreuses sources de données différentes, quels que soient leur taille, leur échelle ou leur format, et exécuter des analyses puissantes sur l'ensemble de ces données à l'aide d’Azure Machine Learning, Spark ou Power BI. Comme les flux de modifications automatisés envoient uniquement ce qui est nouveau ou différent, le transfert des données est beaucoup plus rapide et permet désormais d'obtenir des informations en quasi-temps réel, avec un impact minimal sur les performances de la base de données source dans SQL Server 2022 (16.x).
Pour vos charges de travail opérationnelles et même une grande partie de vos charges de travail analytiques, SQL Server peut gérer des tailles de bases de données massives. Pour plus d'informations sur les spécifications de capacité maximale pour SQL Server, consultez Limites de capacité de calcul des éditions SQL Server. L'utilisation de plusieurs instances de SQL Server sur des machines distinctes avec des requêtes T-SQL partitionnées permet un environnement scale-out pour les applications.
PolyBase permet à votre instance de SQL Server d’interroger des données avec T-SQL directement à partir de clusters SQL Server, Oracle, Teradata, MongoDB et Cosmos DB sans qu’il soit nécessaire d’installer séparément des logiciels de connexion client. Vous pouvez également utiliser le connecteur ODBC générique sur une instance Microsoft Windows pour vous connecter à des fournisseurs supplémentaires à l’aide de pilotes ODBC tiers. PolyBase permet aux requêtes T-SQL de joindre les données de sources externes à des tables relationnelles dans une instance de SQL Server. Cela permet aux données de conserver leur emplacement et leur format d’origine. Vous pouvez virtualiser les données externes à travers l’instance de SQL Server, ce qui vous permet de les interroger sur place comme n’importe quelle autre table dans SQL Server. SQL Server 2022 (16.x) permet également des requêtes ad hoc et la sauvegarde/restauration sur des options de stockage matériel ou logiciel de type Object-Store (à l’aide de l’API S3).
Deux architectures de référence générales utilisent SQL Server sur un serveur autonome pour les requêtes de données structurées et une installation distincte d'un système non relationnel de type scale-out (par exemple Apache Hadoop ou Apache Spark) pour le lien local vers Synapse. L'autre option consiste à utiliser un ensemble de conteneurs dans un cluster Kubernetes avec tous les composants de votre solution.
Microsoft SQL Server sur Windows, Apache Spark et stockage d’objets en local
Vous pouvez installer SQL Server sur Windows ou Linux, et effectuer un scale-up de l’architecture matérielle, grâce à la capacité d’interrogation du stockage d’objets de SQL Server 2022 (16.x) et la fonction PolyBase afin d’interroger l’ensemble des données de votre système.
L'installation et la configuration d'une plateforme de scale-out comme Apache Hadoop ou Apache Spark permet d'interroger des données non relationnelles à grande échelle. L'utilisation d'un ensemble central de systèmes de stockage d'objets prenant en charge l'interface S3-API permet à SQL Server 2022 (16.x) et à Spark d'accéder au même ensemble de données dans tous les systèmes.
Le connecteur Microsoft Apache Spark pour SQL Server et Azure SQL possède également des éléments qui vous permettent d'interroger des données directement à partir de SQL Server à l'aide de Jobs Spark. Pour plus d'informations sur le connecteur Apache Spark pour SQL Server et Azure SQL, consultez Connecteur Apache Spark : SQL Server et Azure SQL.
Vous pouvez également utiliser le système d'orchestration de conteneurs Kubernetes pour votre déploiement. Cela permet une architecture déclarative capable de fonctionner localement ou dans n'importe quel cloud prenant en charge Kubernetes ou la plateforme Red Hat OpenShift. Pour en savoir plus sur le déploiement de SQL Server dans un environnement Kubernetes, consultez Déployer un cluster de conteneurs SQL Server sur Azure ou regardez Déployer SQL Server 2019 dans Kubernetes.
Utilisez SQL Server et Hadoop/Spark en local en remplacement de SQL Server 2019 pour clusters Big Data lorsque vous en devez :
- Conserver l'ensemble de la solution en local
- Utiliser un matériel dédié pour toutes les parties de la solution
- Accéder aux données relationnelles et non relationnelles à partir de la même architecture, dans les deux sens
- Partager un ensemble unique de données non relationnelles entre SQL Server et le système non relationnel avec scale-out
Effectuer la migration
Une fois que vous avez choisi un emplacement (dans le cloud ou hybride) pour votre migration, vous devez évaluer les vecteurs de temps d’arrêt et de coûts pour déterminer si vous souhaitez exécuter un nouveau système et déplacer les données du système précédent vers le nouveau en temps réel (migration côte à côte) ou une sauvegarde et une restauration, ou un nouveau démarrage du système à partir des sources de données existantes (migration sur place).
La décision suivante consiste soit à réécrire la fonctionnalité actuelle de votre système en utilisant le nouveau choix d'architecture, soit à transférer la plus grande partie possible du code vers le nouveau système. La première option peut prendre plus de temps. Cependant, elle permet d’utiliser de nouvelles méthodes et des nouveaux concepts, ainsi que les avantages de la nouvelle architecture. Dans ce cas, les mappages d'accès aux données et de fonctionnalité constituent les principales tâches de planification sur lesquelles vous devez vous concentrer.
Si vous comptez migrer le système actuel avec le moins de modifications de code possible, la compatibilité du langage est votre principale priorité pour la planification.
Migration de code
L'étape suivante consiste à vérifier le code utilisé par le système actuel et les modifications à apporter afin qu'il puisse fonctionner dans le nouvel environnement.
Il existe deux vecteurs principaux pour la migration du code :
- Sources et récepteurs
- Migration de fonctionnalité
Sources et récepteurs
La première tâche de la migration du code consiste à identifier les méthodes de connexion de la source de données, les chaînes ou les API que le code utilise pour accéder aux données importées, leur chemin et leur destination finale. Documentez ces sources et créez un mappage aux emplacements de la nouvelle architecture.
- Si la solution actuelle utilise un système de pipeline pour déplacer les données dans le système, mappez les sources, les étapes et les récepteurs de la nouvelle architecture aux composants du pipeline.
- Si la nouvelle solution remplace également l'architecture pipeline, traitez le système comme une nouvelle installation à des fins de planification, même si vous réutilisez le matériel ou la plateforme cloud en remplacement.
Migration de fonctionnalité
La tâche la plus complexe nécessaire lors d'une migration consiste à référencer, mettre à jour ou créer la documentation de la fonctionnalité du système actuel. Si vous prévoyez une mise à niveau sur place et essayez de réduire au minimum la quantité de code à réécrire, cette étape est la plus longue.
Mais la migration d'une technologie antérieure est souvent le moment idéal pour intégrer les dernières avancées de la technologie et tirer parti des constructions qu'elle offre. Souvent, une réécriture de votre système actuel vous permet de gagner en sécurité, en performances, en choix de fonctionnalités et même en optimisation des coûts.
Dans un cas comme dans l'autre, deux principaux facteurs interviennent dans la migration : le code et les langages pris en charge par le nouveau système, et les choix relatifs au déplacement des données. En général, vous devez être en mesure de modifier les chaînes de connexion en basculant du cluster Big Data actuel vers l’instance SQL et l’environnement Spark. Toute information relative à la connexion des données et au basculement du code doit être minimale.
Si vous prévoyez de réécrire votre fonctionnalité actuelle, mappez les bibliothèques, paquets et DLL nouveaux à l’architecture que vous avez choisie pour votre migration. Vous trouverez une liste de toutes les bibliothèques, de tous les langages et de toutes les fonctions que propose chaque solution dans les références documentaires présentées dans les sections précédentes. Mappez les langages suspects ou non pris en charge, puis planifiez le remplacement avec l’architecture choisie.
Options de migration de données
Il existe deux approches courantes pour le déplacement des données dans un système analytique à grande échelle. La première consiste à créer un processus de « basculement » dans lequel le système d'origine continue à traiter les données, et ces données sont regroupées dans un ensemble plus petit de sources de rapports et de données agrégées. Le nouveau système démarre alors avec des données fraîches et sera utilisé à partir de la date de migration.
Dans certains cas, toutes les données doivent être transférées du système hérité au nouveau système. Dans ce cas, vous pouvez monter les magasins de fichiers d'origine à partir de clusters Big Data SQL Server si le nouveau système les prend en charge, puis copier les données par morceaux sur le nouveau système, ou vous pouvez créer un déplacement physique.
Migrer vos données actuelles de SQL Server 2019 pour clusters Big Data vers un autre système dépend en grande partie de deux facteurs : l'emplacement de vos données actuelles et le fait que la destination soit locale ou dans le cloud.
Migration de données locale
Pour les migrations « local à local », vous pouvez migrer les données SQL Server avec une stratégie de sauvegarde et de restauration, ou configurer la réplication pour déplacer une partie ou la totalité de vos données relationnelles. Les services d'intégration SQL Server peuvent également être utilisés pour copier les données de SQL Server vers un autre emplacement. Pour plus d'informations sur le déplacement de données avec SSIS, consultez SQL Server Integration Services.
Pour les données HDFS dans votre environnement actuel de cluster Big Data SQL Server, l'approche standard consiste à monter les données sur un cluster Spark autonome, puis soit à utiliser le processus de stockage d'objets pour déplacer les données afin qu'une instance de SQL Server 2022 (16.x) puisse y accéder, soit de les laisser telles quelles et de continuer à les traiter avec des tâches Spark.
Migration de données dans le cloud
Pour les données situées dans un stockage dans le cloud ou localement, vous pouvez utiliser Azure Data Factory, qui dispose de plus de 90 connecteurs pour un pipeline complet de transfert, avec des services de planification, de surveillance, d'alerte, entres autres. Pour plus d'informations sur Azure Data Factory, consultez Qu'est-ce qu'Azure Data Factory ?
Si vous souhaitez déplacer rapidement et en toute sécurité de grandes quantités de données de votre domaine de données local vers Microsoft Azure, vous pouvez utiliser le service Azure Import/Export. Le service Azure Import/Export est utilisé pour importer de manière sécurisée des volumes importants de données dans Stockage Blob Azure et Azure Files en expédiant des lecteurs de disque vers un centre de données Azure. Vous pouvez également utiliser ce service pour transférer des données de Stockage Blob Azure vers des lecteurs de disque et les expédier vers vos sites locaux. Les données d’un ou plusieurs lecteurs de disque peuvent être importées dans le Stockage Blob Azure ou Azure Files. Pour les très grandes quantités de données, l'utilisation de ce service peut être la solution la plus rapide.
Si vous souhaitez transférer des données à l’aide des lecteurs de disque fournis par Microsoft, vous pouvez utiliser un disque Azure Data Box pour importer des données dans Azure. Pour plus d’informations, consultez Qu’est-ce que le service Azure Import/Export ?
Pour plus d'informations sur ces choix et les décisions qui les accompagnent, consultez Utilisation d’Azure Data Lake Storage Gen1 pour le Big Data.