Présentation du pool de stockage dans les Clusters Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Cet article décrit le rôle du pool de stockage SQL Server dans un cluster Big Data SQL Server. Les sections suivantes décrivent l’architecture et les fonctionnalités d’un pool de stockage.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Architecture du pool de stockage
Le pool de stockage est le cluster HDFS (Hadoop) local d’un cluster Big Data SQL Server. Il fournit un stockage persistant pour les données non structurées et semi-structurées. Les fichiers de données, comme les fichiers Parquet ou de texte délimité, peuvent être stockés dans le pool de stockage. Pour rendre le stockage persistant, chaque pod du pool est attaché à un volume persistant. Les fichiers de pool de stockage sont accessibles via PolyBase par le biais de SQL Server ou directement à l’aide d’une passerelle Apache Knox.
Une configuration HDFS classique se compose d’un ensemble d’ordinateurs matériels auxquels du stockage est attaché. Les données sont réparties en blocs entre les différents nœuds pour la tolérance de panne et l’exploitation du traitement parallèle. L’un des nœuds du cluster fonctionne comme le nœud de nom et contient les informations de métadonnées relatives aux fichiers se trouvant dans les nœuds de données.
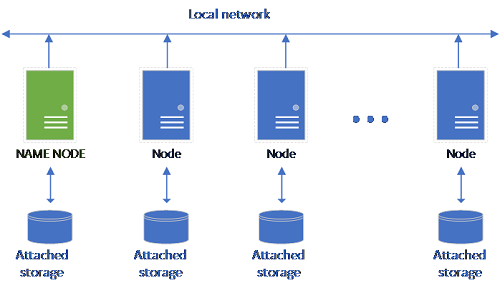
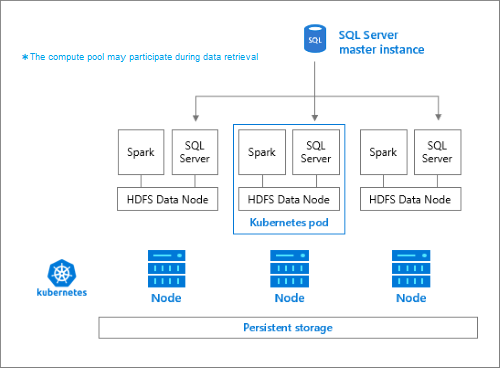
Le pool de stockage est constitué de nœuds de stockage qui sont membres d’un cluster HDFS. Il exécute un ou plusieurs pods Kubernetes avec chaque pod hébergeant les conteneurs suivants :
- Un conteneur Hadoop lié à un volume persistant (stockage). Tous les conteneurs de ce type forment ensemble le cluster Hadoop. Dans le conteneur Hadoop se trouve un processus de gestionnaire de nœuds YARN qui peut créer des processus Worker Apache Spark à la demande. Le nœud principal Spark héberge le metastore Hive, l’historique Spark et les conteneurs de l’historique des travaux YARN.
- Une instance SQL Server pour lire des données à partir de HDFS à l’aide de la technologie OpenRowSet.
collectdpour la collecte de données de métriques.fluentbitpour la collecte de données de journal.
Responsabilités
Les nœuds de stockage sont responsables des opérations suivantes :
- Ingestion de données par le biais d’Apache Spark.
- Stockage des données dans HDFS (format Parquet et texte délimité). HDFS assure également la persistance des données, car les données HDFS sont réparties sur tous les nœuds de stockage du cluster Big Data (BDC) SQL.
- Accès aux données par le biais des points de terminaison HDFS et SQL Server.
Accès aux données
Les principales méthodes permettant d’accéder aux données dans le pool de stockage sont les suivantes :
- Travaux Spark.
- L’utilisation de tables externes SQL Server pour permettre l’interrogation des données à l’aide des nœuds de calcul PolyBase et des instances SQL Server en cours d’exécution dans les nœuds HDFS.
Vous pouvez également interagir avec HDFS à l’aide des éléments suivants :
- Azure Data Studio.
- Azure Data CLI (
azdata). - kubectl pour émettre des commandes vers le conteneur Hadoop.
- Passerelle HTTP HDFS.
Étapes suivantes
Pour en savoir plus sur les Clusters Big Data SQL Server, consultez les ressources suivantes :